







本系列将对《机器学习实战》([美] Peter Harrington著,李锐等译)一书的算法进行总结,并使用Matlab对算法进行实现。
这篇文章首先介绍k-近邻算法。
k-近邻算法的核心思想为,采用测量不同特征值之间距离的方法进行分类。其优点在于,算法精度较高,对异常值不敏感,无数据输入的假定。但缺点在于计算的时间复杂度和空间复杂度均较高,这一点在特征数目较多以及样本集数目较多的时候,比较明显。k-近邻算法适用于数值型和标称型的数据。
k-近邻算法使用前提:
存在训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据的所属分类。当输入没有标签的新数据后,可将新数据每个特征与样本集中数据的对应特征进行比较,然后算法提取样本集中特征最相似(最近邻)的分类标签。一般选取样本数据集中前k个最相似数据,所以称为k-近邻。最后,选择k个最相似数据中出现次数最多的标签作为新数据的标签。
k-近邻算法的流程包括:
- 准备数据,即将数据处理为样本集矩阵、样本集标签和新数据
- 处理数据,如归一化等
- 测试算法,采用测试集数据进行算法测试,计算错误率。后面会讲到测试集数据的选取
- 使用算法
算法的伪代码如下:
- 计算样本集数据中每个点与新数据之间的距离
- 按照距离递增次序排序
- 选取与新数据点距离最小的k个点
- 统计前k个点所在类别的出现频率
- 返回出现频率最高的类别作为新数据的标签
以电影分类为例,假设电影可分为爱情片和动作片(即两种分类标签),而电影的分类可以通过电影中出现的打斗镜头数和接吻镜头数(即两个特征)。对于一个未知类型的电影,我们可以通过获取其出现的打斗和接吻镜头数(新数据的特征),计算其与已知类别电影样本(样本集)的距离,获知其分类。
分类函数使用Matlab实现,如下
function label = classify0(inX, dataSet,labels,k)
[dataSetRow,dataSetCol] = size(dataSet);
diffMat = zeros(dataSetRow,dataSetCol);
for i = 1:dataSetRow
for j = 1:dataSetCol
diffMat(i,j) = (dataSet(i,j)-inX(1,j))^2; %求差再平方
end
end
dist = sqrt(sum(diffMat,2)); %求欧式距离
[sX,index] = sort(dist); %排序并保留原来的序号
for i=1:k
klabels(i) = labels(index(i));
end
sortedClass = tabulate(klabels');
label = sortedClass{1};算法的测试以及对新数据的分类代码如下
%原始数据:
group = [0.9,0;1,0.1;0,1.1;0.2,1];
inX = [1,0.2];
labels = ['A';'A';'B';'B'];
%分类
label = classify0(inX,group,labels,3);
%绘图
figure;
%scatter(group(:,1),group(:,2));
for i = 1:length(group)
if labels(i) == 'A'
scatter(group(i,1),group(i,2),'ro');
hold on;
elseif labels(i) == 'B'
scatter(group(i,1),group(i,2),'b.');
hold on;
end
text(group(i,1)+0.02,group(i,2),labels(i));
end
scatter(inX(1,1),inX(1,2),'g');
text(inX(1,1)+0.02,inX(1,2),label);
axis([-0.2 1.2 -0.2 1.2]);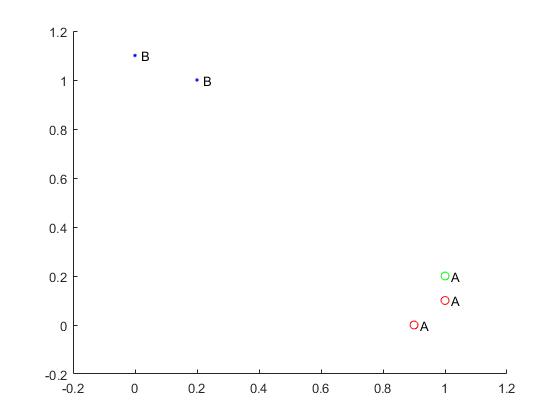















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









