






Redis的基础数据类型有那些?
String(字符串),Hsah(哈希), List(列表), Set(集合), Zset(有序集合)
Geospatial(地理空间)Hyperloglog(近似的统计数据)Bitmap(位图)
缓存穿透?
首先缓存穿透是客户端访问不存在的key,缓存命中失败后,查询数据库,当有大量这种请求的时候,导致数据库崩溃。
解决办法:
- 给不存在的key设置为null(缓存命中失败后,先去查询数据库,查询失败,给key赋值为null,下一次查询直接返回null)
优点:实现逻辑简单
缺点:占用内存,而且可能会导致一些数据不一致(当数据库中填加了值后,缓存仍然为空)
- 设置布隆过滤器
布隆过滤器就是用一个长的位数组,01分别标识存在与否,将数据库中的值,利用hash算法,再和位数组上的一一对应,然后进行判断的时候,将查询到的key先进行运算后得出在数组中的位置,再与位数组进行比较,如果为空则不放行,如果存在才放行。但是因为存在hash碰撞的可能,所以即使布隆过滤器判断成功存在
优点:内存占用少
缺点:逻辑复杂,而且添加之后,不好删除,因为存在hash碰撞,数组上的一位可能代表了存在不止有一个。
缓存雪崩?
大量key失效,redis宕机,导致服务器崩溃
解决办法:
- 分散key的过期时间
- 部署redis集群,挂了一个也没事
缓存击穿?
热点key失效,导致服务器崩溃。
解决办法:
- 使用互斥锁,就是当有多个线程去查询缓存失败的时候,回去竞争去数据库查询的机会,只有一个能去数据库更改,剩下获取失败的阻塞等待,然后重试获取缓存,直到第一个竞争成功的查询完数据库,并写入缓存后,其他的才能获取成功。
优点:没有额外的内存消耗;保证一致性;实现简单
缺点:线程需要等待,性能受影响;可能有死锁风险
- 逻辑删除:设置逻辑过期,如果逻辑过期了,当前线程就直接返回旧值,然后去开启新线程更改数据库,并将更新redis。后面同时来的也是同样的,但是也会去尝试获取锁,获取失败代表当前有人在更改,直接返回旧值。
优点:线程无需等待,性能较好
缺点:线程无需等待,性能较好
Redis持久化机制
主要有两种RBD,AOF
1. RBD
RBD是以快照的形式,将某一刻的内存信息保存到磁盘,他记录的是数据,
RBD的触发机制:
手动触发,(save 同步,会阻塞线程,bgsave 异步 redis会fork一个子进程去创建RBD文件)
自动触发 (save m n m秒内修改n次就会触发保存)
RDB的优点:内存紧凑,节省空间,与AOF相比,恢复大数据集的时候会更快,它适合大规模的数据恢复场景,如备份,全量复制等
缺点:容易丢失数据(快照之间的数据),没办法做到实时持久化/秒级持久化。
2.AOF
AOF是以日志的方式记录每一个写操作,然后只需要执行AOF文件就可以恢复内存信息,随着操作的增加,文件会越来越大,AOF会优化存储的操作命令,也就是重写机制,他会把那些无效的过期的命令合并到最新的上面。
AOF的写回机制(将AOF文件写到磁盘):(三种)
Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
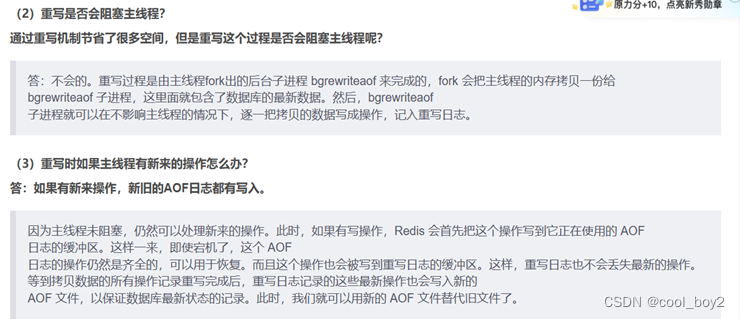
AOF会创建一个子进程将数据写入新的AOF文件,如果同时有新的修改操作,会将它放入缓存中记录,等修改完新的AOF文件后再追加进去。
优点:
- 数据的一致性和完整性更高,
- 具有可读性,因为存的是日志,可以直接看命令。
- 灵活性,可以根据不同的业务要求选取不同的重写机制
缺点; 相同的数据集,AOF文件体积大于RDB文件。数据恢复也比较慢















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









