









0x00 前言
最近在使用IDA时,发现有些字符串的标记是text不是db,并且undefine之后,按’A’键转换不成text格式的字符串,甚至根本不是完整的字符串。这个text到底是什么,改如何转换此类字符串呢?
0x01 unicode编码类型
其实很容易想到,字符串有ascii码格式的,必然有unicode编码格式的。我们看下unicode编码格式。

可以看到UTF-16有一个00字节,如果是一个单词"sun",他的UTF-16编码
>>> import binary
>>> binascii.hexlify('sun'.decode().encode('utf-16'))
'fffe730075006e00'
"sun"的UTF8编码为
>>> binascii.hexlify(u'sunon')
'73756e6f6e'
0x02 IDA中unicode编码
我们在看下IDA中的unicode字符串
.rodata:0000000000879575 aABEHMSZY db '%a %b %e %H:%M:%S %Z %Y',0
.rodata:000000000087958D db 0
.rodata:000000000087958E db 0
.rodata:000000000087958F db 0
.rodata:0000000000879590 db 53h ; S
.rodata:0000000000879591 db 0
.rodata:0000000000879592 db 0
.rodata:0000000000879593 db 0
.rodata:0000000000879594 db 75h ; u
.rodata:0000000000879595 db 0
.rodata:0000000000879596 db 0
.rodata:0000000000879597 db 0
.rodata:0000000000879598 db 6Eh ; n
.rodata:0000000000879599 db 0
.rodata:000000000087959A db 0
.rodata:000000000087959B db 0
.rodata:000000000087959C db 0
.rodata:000000000087959D db 0
.rodata:000000000087959E db 0
.rodata:000000000087959F db 0
明显sun中间有3个\0,也就是1个字符占用了4个字节,UTF-16使用2个字节编码,故UTF-32是4个字节。验证下猜想。在IDA界面中找到“Options”菜单,点击“string literals…”选项,或者使用快捷键“ALT+A”打开字符串类型设置。
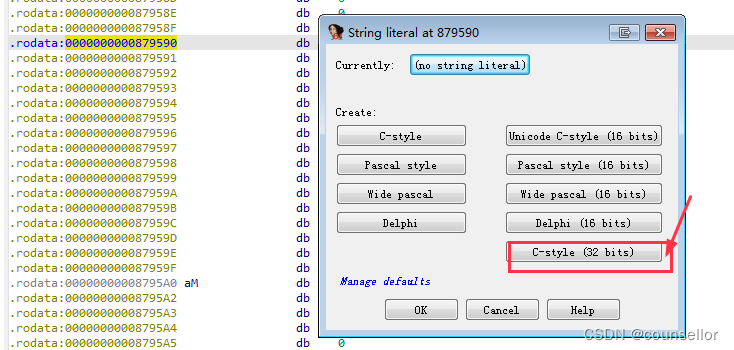
点击32bits选项,并确认。字符串此时显示正常。说明转换是对的。
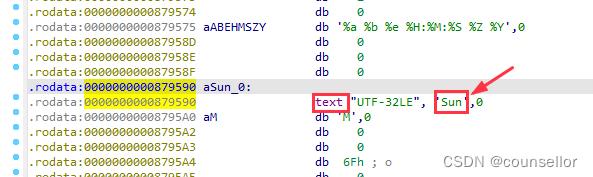
通过“string literals…”选项可以设置其他字符串编码类型。当然,还能转换成中文字符串。
0x03 新增编码类型
首先要将自定义编码添加到IDA默认的列表中,在“Options”菜单中选中“String literals…” 或者按“ALT+A”快捷键。打开之后在“Currently”选中“no string literal”,会弹出Encodings窗口。
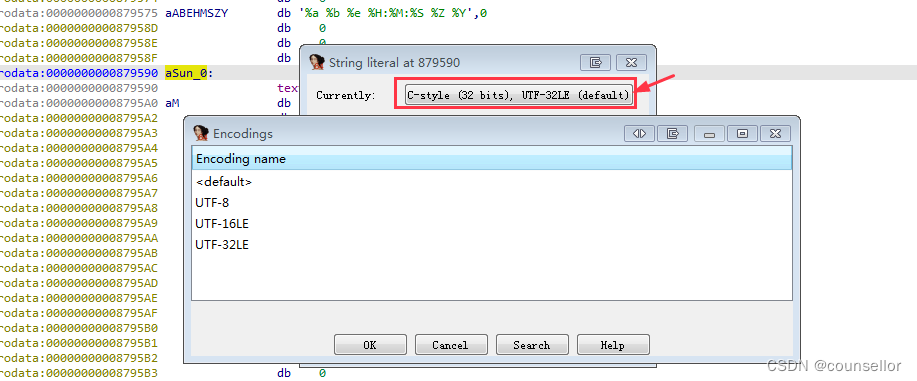
在Encodings窗口的空白处右键点击“Insert”选项,输入指定的编码名称即可。
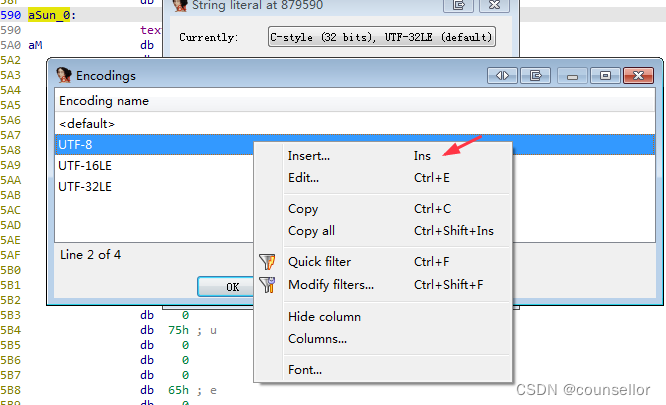
支持的编码有
- Windows codepages (e.g. 866, CP932, windows-1251)
- Well-known charset names (e.g. Shift-JIS, UTF-8, Big5)
0x04 参考文献
https://hex-rays.com/blog/igor-tip-of-the-week-13-string-literals-and-custom-encodings/

















 2648
2648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









