前置
启动zookeeper、kafka
zkServer.sh start
[root@cp145 data]# nohup kafka-server-start.sh /opt/soft/kafka212/config/server.properties &
创建输入输出队列
[root@cp145 eventdata]# kafka-topics.sh --create --zookeeper 192.168.153.145:2181 --topic mystreamin --partitions 1 --replication-factor 1
[root@cp145 eventdata]# kafka-topics.sh --create --zookeeper 192.168.153.145:2181 --topic mystreamout --partitions 1 --replication-factor 1
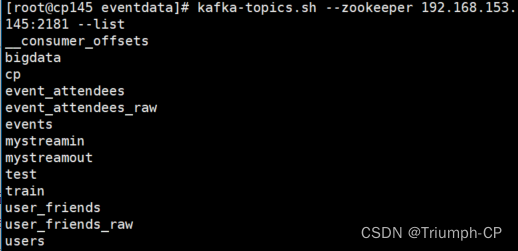
[root@cp145 eventdata]# kafka-topics.sh --zookeeper 192.168.153.145:2181 --list
idea再引入一个依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.8.0</version>
</dependency>
public class MyStreamDemo {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"mystream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.153.145:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
builder.stream("mystreamin").to("mystreamout");
Topology topo = builder.build();
KafkaStreams kafkaStreams = new KafkaStreams(topo, prop);
kafkaStreams.start();
}
}
操作
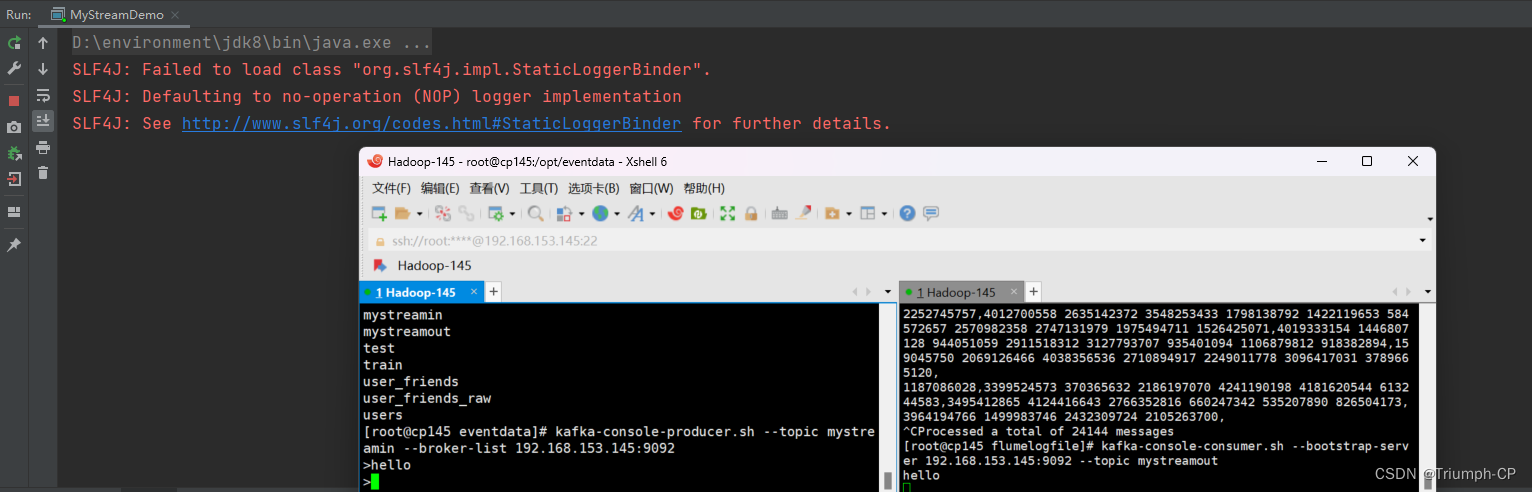
打开生产者mystreamin、打开消费者mystreamout(起两个窗口)
[root@cp145 eventdata]# kafka-console-producer.sh --topic mystreamin --broker-list 192.168.153.145:9092
[root@cp145 flumelogfile]# kafka-console-consumer.sh --bootstrap-server 192.168.153.145:9092 --topic mystreamout
public class MyStreamDemo {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"mystream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.153.145:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<Object, Object> mystreamin = builder.stream("mystreamin");
mystreamin.to("mystreamout");
Topology topo = builder.build();
KafkaStreams kafkaStreams = new KafkaStreams(topo, prop);
kafkaStreams.start();
}
}
 KafkaStream数据流处理:从入门到实践,
KafkaStream数据流处理:从入门到实践,





 本文介绍了如何使用KafkaStream处理数据流。首先启动Zookeeper和Kafka服务,然后创建输入输出队列mystreamin和mystreamout。接着在IDEA中添加Kafka-Streams依赖,构建处理流程,将mystreamin的数据流处理后转发至mystreamout。最后分别启动生产者和消费者进行交互测试。
本文介绍了如何使用KafkaStream处理数据流。首先启动Zookeeper和Kafka服务,然后创建输入输出队列mystreamin和mystreamout。接着在IDEA中添加Kafka-Streams依赖,构建处理流程,将mystreamin的数据流处理后转发至mystreamout。最后分别启动生产者和消费者进行交互测试。


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







