







grep 命令主要对文本的(正则表达式)行基于模式进行过滤
说白了,可以把grep理解成字符查找工具。
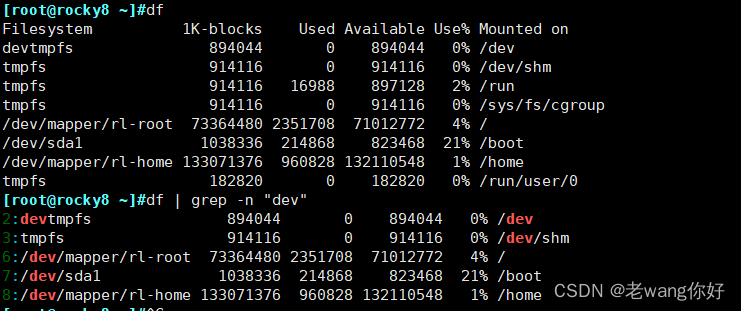
--color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写
-n 显示匹配的行号 # df | grep -n "dev" |grep "root" /etc/passwd
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行 # cat /etc/passwd |grep root -B 2
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-P 支持Perl格式的正则表达式
-f 匹配出两个文件一样的内容 # grep -f 1.txt 2.txt
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接三剑客之sed 文本编辑工具
可以对文本文件进行增、删、改、查等操作,支持按行、按字段、按正则匹配文本内容
命令—-
p 打印当前模式空间内容,追加到默认输出之后 一般和-n组合 seq 1 10|sed -n '1~2p'
Ip 忽略大小写输出
d 删除模式空间匹配的行,并立即启用下一轮循环 sed '2d' data.txt
a [\]text 在指定行后面追加文本,支持使用\n实现多行追加 sed '2awei' data.txt wei2行后
i [\]text 在行前面插入文本 上一
c [\]text 替换行为单行或多行文本 上一
w file 保存模式匹配的行至指定文件
r file 读取指定文件的文本至模式空间中匹配到的行后
= 为模式空间中的行打印行号
! 模式空间中匹配行取反处理
q 结束或退出sed常用
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑
-f FILE 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式
-i.bak 备份文件并原处编辑
-s 将多个文件视为独立文件,而不是单个连续的长文件流 列:sep s/r..t/&er/ s@@@,s###
#说明:
-ir 不支持
-i -r 支持
-ri 支持
-ni 危险选项,会清空文件
'地址格式‘
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行
. 地址范围:
#,# #从#行到第#行,3,6 从第3行到第6行
#,+# #从#行到+#行,3,+4 表示从3行到第7行
/pat1/,/pat2/
#,/pat/
/pat/,#
4. 步进:~
1~2 奇数行
2~2 偶数行查找替代
[root@rocky8 ~]#seq 1 10|sed -n '2~2p'
2
4
6
8
10
[root@rocky8 ~]#seq 1 10|sed -n '1~2p'
1
3
5
7
9
[root@rocky8 ~]#lsmem
RANGE SIZE STATE REMOVABLE BLOCK
0x0000000000000000-0x000000007fffffff 2G online yes 0-15
Memory block size: 128M
Total online memory: 2G
Total offline memory: 0B
[root@rocky8 ~]#lsmem | sed -n "5p" #取第五行
Total online memory: 2G
出指定文件外其余的都删除 一般是没办法传递给rm 加上xargs就可以
ls | sed -n '/[^357].txt/p'|xargs rm
sed '/123/ahello' 1.txt #向内容123后面添加hello,如果文件中有多行包括123,则每一行后面都会添加
sed '$ahello' 1.txt #在最后一行添加hello
sed '1chello' 1.txt #将文件1.txt的第一行替换为hello
sed '1~2d' 1.txt #从第一行开始删除,每隔2行就删掉一行,即删除奇数行
sed '1,2d' 1.txt #删除1~2行
sed '1,3{/123/d}'1.txt #删除1~3行中,匹配内容123的行,1,3表示匹配1~3行,{/123/d}表示删除匹配123的行
sed 's/^#.*//' 1.txt #将1.txt文件中以#开头的行替换为空行,即注释的行 ( ^#)表示匹配以#开头,(.*)代表所有内容
sed 's/^#.*//;/^$/d' 1.txt #先替换1.txt文件中所有注释的#行为空行,然后删除空行,
sed 's/^[0-9]/(&)/' 1.txt #将每一行中行首的数字加上一个小括号 (^[0-9])表示行首是数字,&符号代表匹配的内容
sed -n '/error/=' 1.txt #打印匹配error的行的行号
sed -n '/error/{=;p}' 1.txt #打印匹配error的行的行号和内容(可用于查看日志中有error的行及其内容)
sed 'r 2.txt' 1.txt #将文件2.txt中的内容,读入1.txt中,会在1.txt中的每一行后都读入2.txt的内容
sed '$r 2.txt' 1.txt #在1.txt的最后一行插入2.txt的内容
sed -n 'w 2.txt' 1.txt #将1.txt文件的内容写入2.txt文件,如果2.txt文件不存在则创建,如果2.txt存在则覆盖之前的内容
sed '$r 2.txt' 1.txt #在1.txt的最后一行插入2.txt的内容实例1:替换文件中的内容
#!/bin/bash
if [ $# -ne 3 ];then #判断参数个数
echo "Usage: $0 old-part new-part filename" #输出脚本用法
exit
fi
sed -i "s#$1#$2#" $3 #将 旧内容进行替换,当$1和$2中包含"/"时,替换指令中的定界符需要更换为其他符号
[root@rocky8 ~]#. were qwer 22342 2.txt
[root@rocky8 ~]#cat 2.txt
22342
22342
命令—-
p 打印当前模式空间内容,追加到默认输出之后
Ip 忽略大小写输出
d 删除模式空间匹配的行,并立即启用下一轮循环
a [\]text 在指定行后面追加文本,支持使用\n实现多行追加
i [\]text 在行前面插入文本
c [\]text 替换行为单行或多行文本
w file 保存模式匹配的行至指定文件
r file 读取指定文件的文本至模式空间中匹配到的行后
= 为模式空间中的行打印行号
! 模式空间中匹配行取反处理
q 结束或退出sed
查找替换
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g 行内全局替换
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写
三剑客之awk文本编辑工具
BEGIN 执行前里面有BEGIN,先执行BEGIL
1 [root@rocky81 ~]# seq 10 | awk '{print "hello,awk"}'
hello,awk
hello,awk
hello,awk
hello,awk
hello,awk
hello,awk
hello,awk
hello,awk
hello,awk2 [root@centos8 ~]#seq 3 | awk '{print 2*3}' 支持乘法
3 grep "^UUID" /etc/fstab |awk {'print $2,$3'} 默认以空格为分隔符(压缩)取2,3
4 awk '{print $1}' /etc/passwd|sort | uniq -c |sort -nr|head -3 取出网站访问量最大的前3个IP
5 df | awk -F"[[:space:]]+|%" '{print $5}' -F指定空|%分隔符,输出第五行6 ifconfig eth0|sed -n '2p' |awk '{print $2}'|cat -A 输出2行,取2列,显示换行符
FS:输入字段分隔符,默认为空白字符,功能相当于 -F
awk -v FS=':' '{print $1,FS,$3}' /etc/passwd -v正则,指定:分割,取1(显示分割)3行
S=:;awk -v FS=$S '{print $1FS$3}' /etc/passwd
#-F 和 FS变量功能一样,同时使用会 -F 优先级高
OFS:输出字段分隔符,默认为空白字符 两个字符之间默认有空格
awk -v FS=':' -v OFS='+' '{print $1,$3$7}' /etc/passwd|head -n1 需定两次,空白定义+
RS:输入记录record分隔符,指定输入时的换行符
echo "a,s,d;q,w,e;1,2,3" | awk -v RS=";" -F "," '{print $1}' -F取第一列
a,s,d
q,w,e
1,2,3
[root@rocky81 ~]# echo "a,s,d;q,w,e;1,2,3" | awk -v RS=";" '{print $1}' RS指定列换行符
a,s,d
q,w,e
1,2,3
ORS:输出记录分隔符,输出时用指定符号代替换行符awk -v RS=' ' -v ORS='###' '{print $0}' /etc/passwd 换行符换成别的
awk '{print NR,$0}' /etc/passwd NP行号显示 FNR 两个文件输出事分别编号 FNR, FIENAME显示文件名一起用
cat /etc/passwd |awk 'NR==2' 打印第行2printf
必须指定FORMAT
不会自动换行,需要显式给出换行控制符 \n
FORMAT中需要分别为后面每个item指定格式符%s:显示字符串
%d, %i:显示十进制整数
%f:显示为浮点数
%e, %E:显示科学计数法数值
%c:显示字符的ASCII码
%g, %G:以科学计数法或浮点形式显示数值
%u:无符号整数
%%:显示%自身算术操作符:x+y, x-y, x*y, x/y, x^y, x%y :
-x:转换为负数
+x:将字符串转换为数值赋值操作符:=, +=, -=, *=, /=, %=, ^=,++, --
比较操作符:==, !=, >, >=, <, <=
模式匹配符:~ 左边是否和右边匹配,包含关系
!~ 是否不匹配与:&&,并且关系
或:||,或者关系
非:!,取反awk -F: '{printf "%s\n",$1}' /etc/passwd
awk -F: '{printf "%20s\n",$1}' /etc/passwd 右对齐20
root
bin
daemon
adm
awk -F: '{printf "%-20s%d\n",$1,$3}' /etc/passwd -20左对齐 %d指定整数\n换行
root 0
bin 1
daemon 2
adm 3
lp 4
awk -F: '{$3>=1000?usertype="Common User":usertype="SysUser";printf"%-20s:%12s\n",$1,usertype}' /etc/passwdroot : SysUser 判断3行是否大于1000 是咋,不是咋
bin : SysUserrelational expression: 关系表达式,结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0值[root@centos8 ~]#seq 10 | awk '0'
[root@centos8 ~]#seq 10 | awk '"false"'
1
2
3
4
5条件判断 if-else
awk -F: '{if($3>=1000)print $1,$3}' /etc/passwd 满足条件判断
nobody 65534
caocao 1000条件判断 switch 循环 while
awk -v i=1 -v sum=0 'BEGIN{while(i<=100){sum+=i;i++};print sum}'
5050内置函数length()返回字符数,而非字节数
awk 'BEGIN{print length("hello")}'
5循环 do-while
awk 'BEGIN{ total=0;i=1;do{ total+=i;i++;}while(i<=100);print total}'
5050循环 for
awk 'BEGIN{sum=0;for(i=1;i<=100;i++){sum+=i};print sum}'
5050
continue 中断本次循环
break 中断整个循环next 可以提前结束对本行处理而直接进入下一行处理(awk自身循环)















 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









