







目录
准备 redis-trib.rb 工具 5版本之后就不需要了 (略)
消息队列
- 消息队列: 把要传输的数据放在队列中,从而实现应用之间的数据交换
- 常用功能: 可以实现多个应用系统之间的解耦,异步,削峰/限流等
- 常用的消息队列应用: Kafka,RabbitMQ,Redis
- 简单来讲A把数据发给B,由于数据过多B没有办法一次性接收,于是在缓存区暂缓接收

消息队列分为两种
- 生产者/消费者模式: Producer/Consumer
- 发布者/订阅者模式: Publisher/Subscriber
2 生产者消费者模式
生产者消费者模式下,多个消费者同时监听一个频道(redis用队列实现),但是生产者产生的一个消息只能被最先抢到消息的一个消费者消费一次,队列中的消息由可以多个生产者写入,也可以有不同的消费者取出进行消费处理.此模式应用广泛
生产者生成消息
[root@redis ~]# redis-cli
127.0.0.1:6379> AUTH 123456
OK
127.0.0.1:6379> LPUSH channel1 message1 #从管道的左侧写入
(integer) 1
127.0.0.1:6379> LPUSH channel1 message2
(integer) 2
127.0.0.1:6379> LPUSH channel1 message3
(integer) 3
127.0.0.1:6379> LPUSH channel1 message4
(integer) 4
127.0.0.1:6379> LPUSH channel1 message5
(integer) 5获取所有消息
127.0.0.1:6379> LRANGE channel1 0 -1
1) "message5"
2) "message4"
3) "message3"
4) "message2"
5) "message1"消费者消费消息
127.0.0.1:6379> RPOP channel1 #基于实现消息队列的先进先出原则,从管道的右侧消费
"message1"
127.0.0.1:6379> RPOP channel1
"message2"
127.0.0.1:6379> RPOP channel1
"message3"
127.0.0.1:6379> RPOP channel1
"message4"
127.0.0.1:6379> RPOP channel1
"message5"
127.0.0.1:6379> RPOP channel1
(nil)
验证队列消息消费完成
127.0.0.1:6379> LRANGE channel1 0 -1
(empty list or set) #验证队列中的消息全部消费完成3 发布者订阅模式
在发布者订阅者Publisher/Subscriber模式下,发布者Publisher将消息发布到指定的频道channel,事先监听此channel的一个或多个订阅者Subscriber都会收到相同的消息。即一个消息可以由多个订阅者获取到. 对于社交应用中的群聊、群发、群公告等场景适用于此模式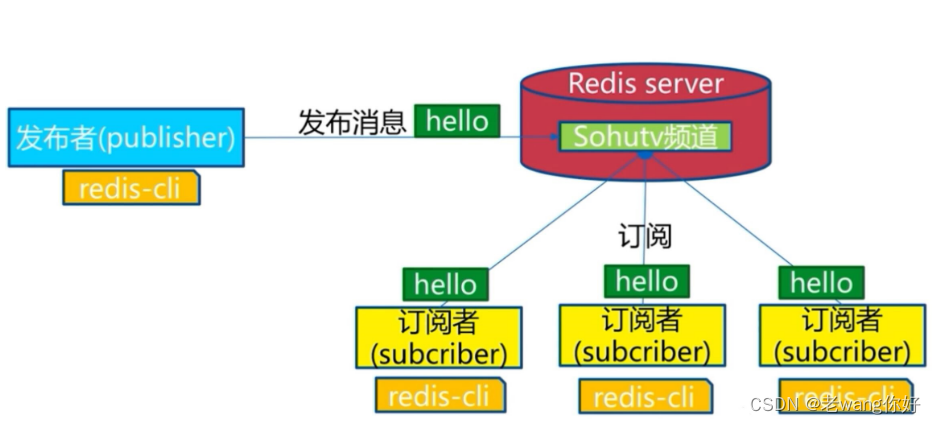
订阅者订阅频道
[root@redis ~]# redis-cli
127.0.0.1:6379> AUTH 123456
OK
127.0.0.1:6379> SUBSCRIBE channel01 #订阅者事先订阅指定的频道,之后发布的消
息才能收到
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel01"
3) (integer) 1发布者发布消息
127.0.0.1:6379> PUBLISH channel01 message1 #发布者发布信息到指定频道
(integer) 2 #订阅者个数
127.0.0.1:6379> PUBLISH channel01 message2
(integer) 2订阅多个频道
#订阅指定的多个频道
127.0.0.1:6379> SUBSCRIBE channel01 channel02订阅所有频道
127.0.0.1:6379> PSUBSCRIBE * #支持通配符*订阅匹配的频道
127.0.0.1:6379> PSUBSCRIBE chann* #匹配订阅多个频道取消订阅频道
127.0.0.1:6379> unsubscribe channel01
1) "unsubscribe"
2) "channel01"
3) (integer) 0Redis 集群与高可用
Redis单机服务存在数据和服务的单点问题,而且单机性能也存在着上限,可以利用Redis的集群相关技术来解决这些问题. #redis数据是放开放,如果挂一个数据就会丢失,所以需要备份
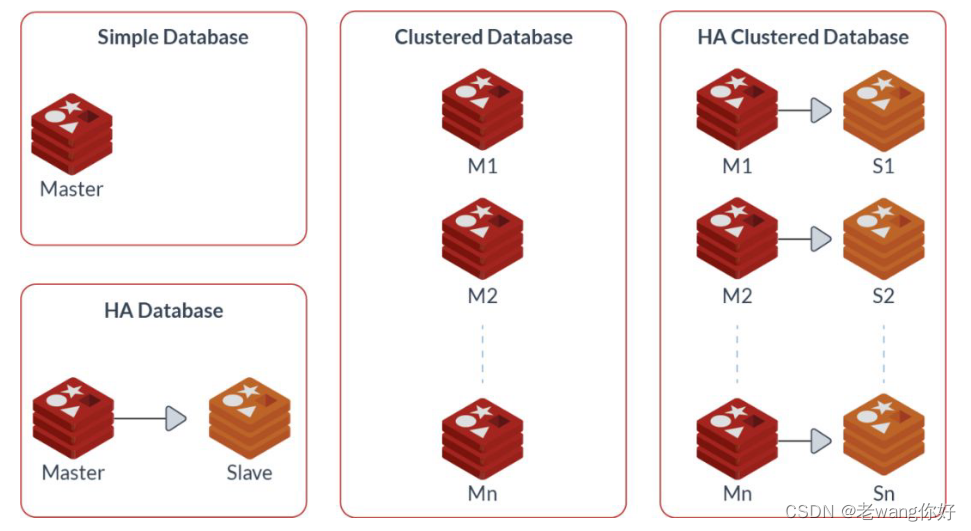
Redis 主从复制

Redis 主从复制架构
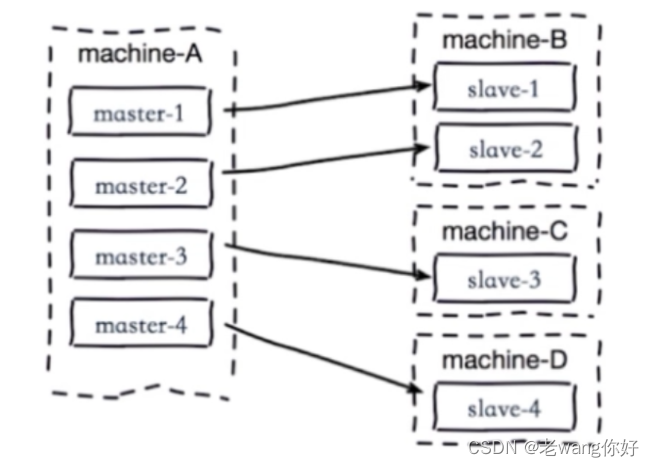
主从模式(master/slave),和MySQL的主从模式类似,可以实现Redis数据的跨主机的远程备份。
常见客户端连接主从的架构:程序APP先连接到高可用性 LB 集群提供的虚拟IP,再由LB调度将用户的请求至后端Redis 服务器来真正提供服务、#辅只能读,不能写

主从复制特点
- 一个master可以有多个 slave
- 一个slave只能有一个master
- 数据流向是从master到slave单向的
- master 可读可写
- slave 只读
当master出现故障后,可以会提升一个slave节点变成新的Mster,因此Redis Slave 需要设置和master相同的连接密码,此外当一个Slave提升为新的master 通过持久化实现数据的恢复 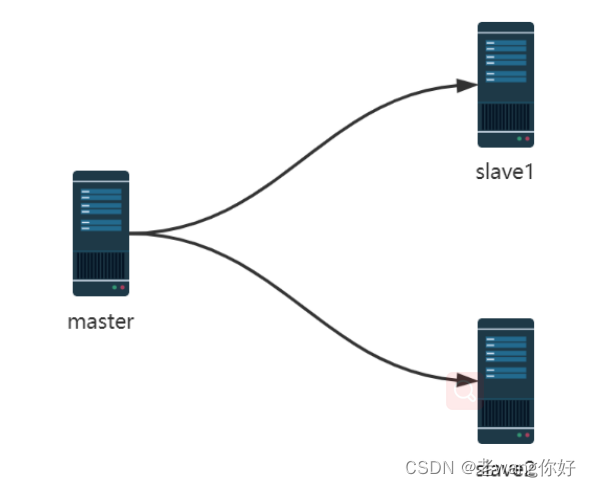
当配置Redis复制功能时,强烈建议打开主服务器的持久化功能。否则的话,由于延迟等问题,部署的主节点Redis服务应该要避免自动启动。
参考案例: 导致主从服务器数据全部丢失
1.假设节点A为主服务器,并且关闭了持久化。并且节点B和节点C从节点A复制数据
2.节点A崩溃,然后由自动拉起服务重启了节点A.由于节点A的持久化被关闭了,所以重启之后没有任何数据
3.节点B和节点C将从节点A复制数据,但是A的数据是空的,于是就把自身保存的数据副本删除。
主从命令配置
启用主从同步
Redis Server 默认为 master节点,如果要配置为从节点,需要指定master服务器的IP,端口及连接密码在从节点执行 REPLICAOF MASTER_IP PORT 指令可以启用主从同步复制功能,早期版本使用 SLAVEOF指令
127.0.0.1:6379> REPLICAOF MASTER_IP PORT #新版推荐使用
127.0.0.1:6379> SLAVEOF MasterIP Port #旧版使用,将被淘汰
127.0.0.1:6379> CONFIG SET masterauth <masterpass>
#在mater上设置key1
redis-cli -a 123456
127.0.0.1:6379> set class m50
OK
127.0.0.1:6379> get class
"m50"
127.0.0.1:6379> INFO Replication
# Replication
role:master #主从信息
connected_slaves:0 #连接数
master_failover_state:no-failover
master_replid:51406f7eadf81bafbd422fb26f11aafb4920f00e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> set class m50
#以下都在slave上执行,登录
redis-cli -a 123456
127.0.0.1:6379> set class m51
OK
127.0.0.1:6379> get class
"m51"
#在slave上设置master的IP和端口,4.0版之前的指令为slaveof
127.0.0.1:6379> REPLICAOF 10.0.0.8 6379 #仍可使用SLAVEOF MasterIP Port
OK
#在slave上设置master的密码,才可以同步
127.0.0.1:6379> CONFIG SET masterauth 123456
OK
127.0.0.1:6379> INFO replication
# Replication #角色变为slave
role:slave
master_host:10.0.0.100 #指向master
master_port:6379
master_link_status:up
master_last_io_seconds_ago:3 #和主节每十秒做一次IO通信
master_sync_in_progress:0 # 0同步已完成,非零正在进项
slave_read_repl_offset:378
slave_repl_offset:378
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:f2c3a0f544807e69b8fc821f8abc7df4c5556e2c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:378
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:15
repl_backlog_histlen:364
#查看已经同步成功
127.0.0.1:6379> get class
"m50"
上述主从是一次性的持久化保存还是需要写进文件
自己的密码最好和主节点一直。万一主节点挂了好替换,建议用域名以后方便改
vim /apps/redis/etc/redis.conf
# replicaof <masterip> <masterport>
replicaof 10.0.0.100 6379
# masterauth <master-password>
masterauth 123456
requirepass 123456 #自己密码
[root@ubuntu2004 ~]#systemctl restart redis.service 删除主从同步
在从节点执行 REPLICAOF NO ONE 指令可以取消主从复制 #一次性
#取消复制,在slave上执行REPLICAOF NO ONE,会断开和master的连接不再主从复制, 但不会清除slave上已有的数据
127.0.0.1:6379> REPLICAOF no one
实现 Redis 的级联复制
即实现基于Slave节点的Slave

master和slave1节点无需修改,只需要修改slave2及slave3指向slave1做为mater即可
和上面操作一样就是1指向master,slave2 3指向一
在中间那个slave1查看状态 127.0.0.1:6379> INFO replication # Replication role:slave master_host:10.0.0.100 master_port:6379 master_link_status:up master_last_io_seconds_ago:8 #最近一次与master通信已经过去多少秒。 master_sync_in_progress:0 #是否正在与master通信。 slave_repl_offset:4312 #当前同步的偏移量 slave_priority:100 #slave优先级,master故障后值越小越优先同步。 slave_read_only:1 connected_slaves:1 slave0:ip=10.0.0.28,port=6379,state=online,offset=4312,lag=0 #slave的slave节点 master_replid:8e8279e461fdf0f1a3464ef768675149ad4b54a3 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:4312 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:4312
主从复制优化
第一次需要全量复制,之后的都是增量复制
主从复制过程
Redis主从复制分为全量同步和增量同步
Redis 的主从同步是非阻塞的,即同步过程不会影响主服务器的正常访问.
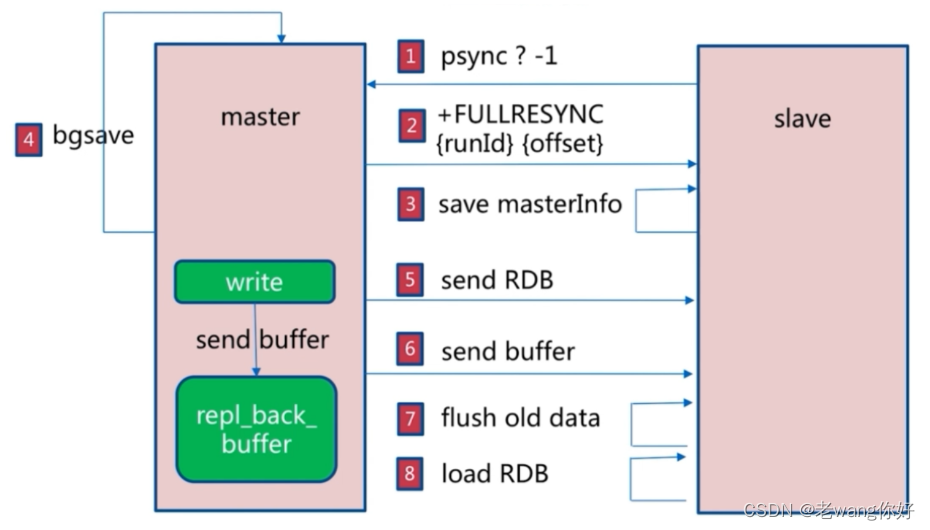
- 主从节点建立连接,验证身份后,从节点向主节点发送PSYNC(2.8版本之前是SYNC)命令
- 主节点向从节点发送FULLRESYNC命令,包括runID和offset
- 从节点保存主节点信息
- 主节点执行BGSAVE保存RDB文件,同时记录新的记录到buffer中
- 主节点发送RDB文件给从节点
- 主节点将新收到buffer中的记录发送至从节点
- 从节点删除本机的旧数据
- 从节点加载RDB
- 从节点同步主节点的buffer信息
增量复制过程

在主从复制首次完成全量同步之后再次需要同步时,从服务器只要发送当前的offset位置(类似于MySQL的binlog的位置)给主服务器,然后主服务器根据相应的位置将之后的数据(包括写在缓冲区的积压数据)发送给从服务器,再次将其保存到从节点内存即可。
即首次全量复制,之后的复制基本增量复制实现
复制缓冲区(环形队列)配置参数:
如果缓冲区里(环形队列)的数据大于指定值1md的话,后续写入覆盖之前内容,就会触发全量复制, #如果断开一个小时(3600)后也会触发全量复制,避免只能修改参数
#master的写入数据缓冲区,用于记录自上一次同步后到下一次同步过程中间的写入命令,计算公式:repl-backlog-size = 允许从节点最大中断时长 * 主实例offset每秒写入量,比如:master每秒最大写入64mb,最大允许60秒,那么就要设置为64mb*60秒=3840MB(3.8G),建议此值是设置的足够大
repl-backlog-size 1mb
#如果一段时间后没有slave连接到master,则backlog size的内存将会被释放。如果值为0则表示永远不释放这部份内存。
repl-backlog-ttl 3600
 避免全量复制
避免全量复制
- 第一次全量复制不可避免,后续的全量复制可以利用小主节点(内存小),业务低峰时进行全量
- 节点运行ID不匹配:主节点重启会导致RUNID变化,可能会触发全量复制,可以利用故障转移,例如哨兵或集群,而从节点重启动,不会导致全量复制
- 复制积压缓冲区不足: 当主节点生成的新数据大于缓冲区大小,从节点恢复和主节点连接后,会导致全量复制.解决方法将repl-backlog-size 调大
避免复制风暴
- 单主节点复制风暴
- 当主节点重启,多从节点复制
- 解决方法:更换复制拓扑
-
 单机器多实例复制风暴
单机器多实例复制风暴 - 机器宕机后,大量全量复制
- 解决方法:主节点分散多机器
主从同步优化配置 ! ! ! !
Redis在2.8版本之前没有提供增量部分复制的功能,当网络闪断或者slave Redis重启之后会导致主从之间的全量同步,即从2.8版本开始增加了部分复制的功能。
性能相关配置
repl-diskless-sync no # 是否使用无盘方式进行同步RDB文件,默认为no,no表示不使用无盘,需要将
RDB文件保存到磁盘后再发送给slave,yes表示使用无盘,即RDB文件不需要保存至本地磁盘,而且直接通过
网络发送给slave
repl-diskless-sync-delay 5 #无盘时复制的服务器等待的延迟时间
repl-ping-slave-period 10 #slave向master发送ping指令的时间间隔,默认为10s
repl-timeout 60 #指定ping连接超时时间,超过此值无法连接,master_link_status显示为down状态,
并记录错误日志
repl-disable-tcp-nodelay no #是否启用TCP_NODELAY
#设置成yes,则redis会合并多个小的TCP包成一个大包再发送,此方式可以节省带宽,但会造成同步延迟时
长的增加,导致master与slave数据短期内不一致
#设置成no,则master会立即同步数据
repl-backlog-size 1mb #master的写入数据缓冲区,用于记录自上一次同步后到下一次同步前期间的写
入命令,计算公式:repl-backlog-size = 允许slave最大中断时长 * master节点offset每秒写入
量,如:master每秒最大写入量为32MB,最长允许中断60秒,就要至少设置为32*60=1920MB,建议此值是设
置的足够大,如果此值太小,会造成全量复制
repl-backlog-ttl 3600 #指定多长时间后如果没有slave连接到master,则backlog的内存数据将会过
期。如果值为0表示永远不过期。
slave-priority 100 #slave参与选举新的master的优先级,此整数值越小则优先级越高。当master故
障时将会按照优先级来选择slave端进行选举新的master,如果值设置为0,则表示该slave节点永远不会被
选为master节点。
min-replicas-to-write 1 #指定master的可用slave不能少于个数,如果少于此值,master将无法执
行写操作,默认为0,生产建议设为1,
min-slaves-max-lag 20 #指定至少有min-replicas-to-write数量的slave延迟时间都大于此秒数
时,master将不能执行写操作常见主从复制故障
主从硬件和软件配置不一致
主从节点的maxmemory不一致,主节点内存大于从节点内存,主从复制可能丢失数据
rename-command 命令不一致,如在主节点启用flushdb,从节点禁用此命令,结果在master节点执行
flushdb后,导致slave节点不同步' #A设置内存16 ,8设置为8这当然不行了
#在从节点定义rename-command flushall "",但是在主节点没有此配置,则当在主节点执行flushall
时,会在从节点提示下面同步错误
10822:S 16 Oct 2020 20:03:45.291 # == CRITICAL == This replica is sending an
error to its master: 'unknown command `flushall`, with args beginning with: '
after processing the command '<unknown>'
#master有一个rename-command flushdb "wang",而slave没有这个配置,则同步时从节点可以看到以
下同步错误
3181:S 21 Oct 2020 17:34:50.581 # == CRITICAL == This replica is sending an
error to its master: 'unknown command `wang`, with args beginning with: ' after
processing the command '<unknown>'master密码错误
如果slave节点配置的master密码错误,导致验证不通过,自然将无法建立主从同步关系。
#tail -f /var/log/redis/redis.log
24930:S 20 Feb 2020 13:53:57.029 * Connecting to MASTER 10.0.0.8:6379
24930:S 20 Feb 2020 13:53:57.030 * MASTER <-> REPLICA sync started
24930:S 20 Feb 2020 13:53:57.030 * Non blocking connect for SYNC fired the
event.
24930:S 20 Feb 2020 13:53:57.030 * Master replied to PING, replication can
continue...
24930:S 20 Feb 2020 13:53:57.031 # Unable to AUTH to MASTER: -ERR invalid
passwordRedis版本不一致
不同的redis 版本之间尤其是大版本间可能会存在兼容性问题,如:Redis 3,4,5,6之间
因此主从复制的所有节点应该使用相同的版本
安全模式下无法远程连接
如果开启了安全模式,并且没有设置bind地址和密码,会导致无法远程连接
[root@centos8 ~]#vim /etc/redis.conf
#bind 127.0.0.1 #将此行注释
[root@centos8 ~]#systemctl restart redis
[root@centos8 ~]#ss -ntl
#可以本机登录
[root@centos8 ~]#redis-cli
127.0.0.1:6379> KEYS *
(empty list or set)Redis 哨兵 Sentinel

Redis 集群介绍
主从架构和MySQL的主从复制一样,无法实现master和slave角色的自动切换,即当master出现故障时,不能实现自动的将一个slave 节点提升为新的master节点,即主从复制无法实现自动的故障转移功能,如果想实现转移,则需要手动修改配置,才能将 slave 服务器提升新的master节点.此外只有一个主节点支持写操作,所以业务量很大时会导致Redis服务性能达到瓶颈
需要解决的主从复制以下存在的问题:
- master和slave角色的自动切换,且不能影响业务
- 提升Redis服务整体性能,支持更高并发访问
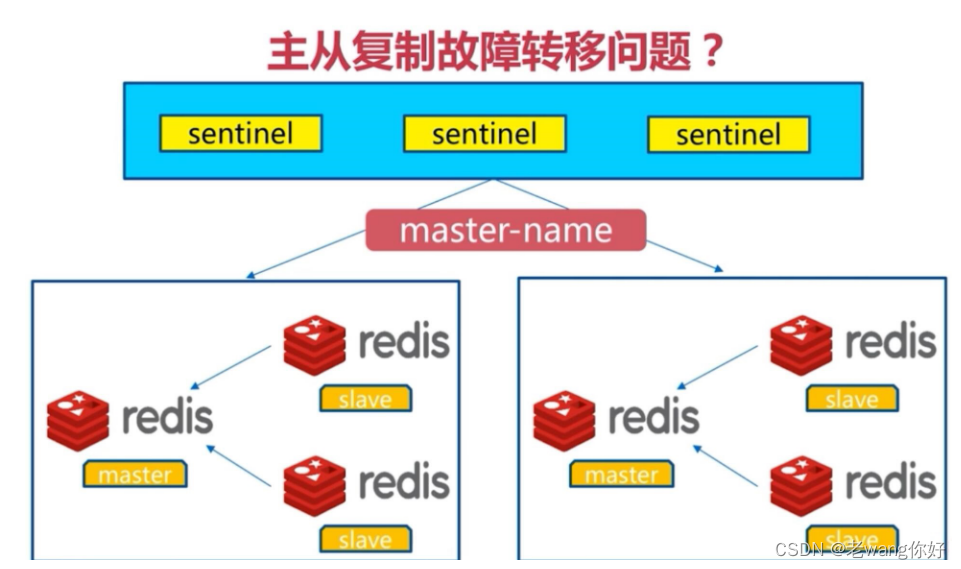
Sentinel 架构和故障转移机制
会链接sentinel来进行判断是否故障转移 (需要改程序)
 投票机制,多数认为挂了才是挂了 奇数行
投票机制,多数认为挂了才是挂了 奇数行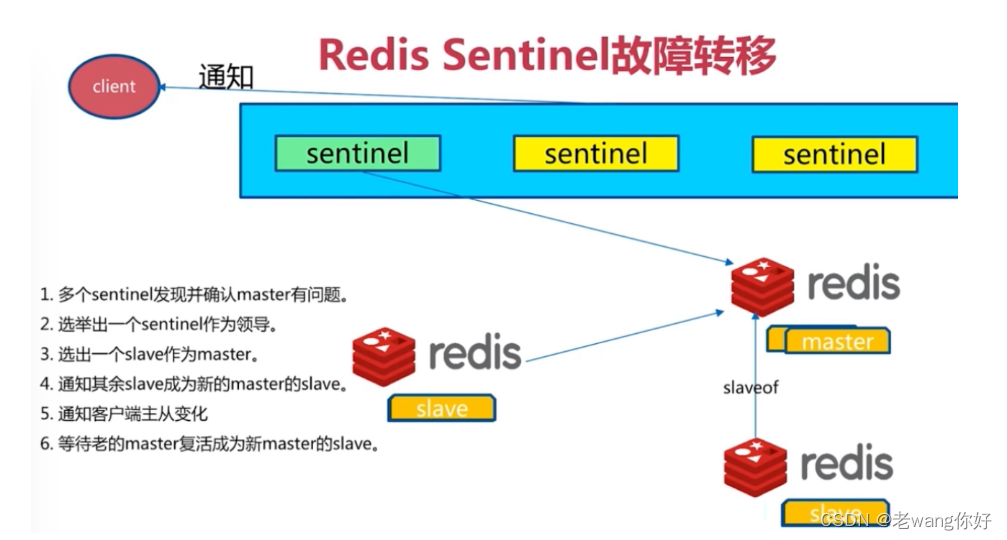
专门的Sentinel 服务进程是用于监控redis集群中Master工作的状态,当Master主服务器发生故障的时候,可以实现Master和Slave的角色的自动切换,从而实现系统的高可用性
Sentinel是一个分布式系统,即需要在多个节点上各自同时运行一个sentinel进程,Sentienl 进程通过流言协议(gossip protocols)来接收关于Master是否下线状态,并使用投票协议(Agreement Protocols)来
决定是否执行自动故障转移,并选择合适的Slave作为新的Master
每个Sentinel进程会向其它Sentinel、Master、Slave定时发送消息,来确认对方是否存活,如果发现某个节点在指定配置时间内未得到响应,则会认为此节点已离线,即为主观宕机Subjective Down,简称为 SDOWN如果哨兵集群中的多数Sentinel进程认为Master存在SDOWN,共同利用 is-master-down-by-addr 命令互相通知后,则认为客观宕机Objectively Down, 简称 ODOWN
接下来利用投票算法,从所有slave节点中,选一台合适的slave将之提升为新Master节点,然后自动修改其它slave相关配置,指向新的master节点,最终实现故障转移failover
Redis Sentinel中的Sentinel节点个数应该为大于等于3且最好为奇数
客户端初始化时连接的是Sentinel节点集合,不再是具体的Redis节点,即 Sentinel只是配置中心不是代理。
Redis Sentinel 节点与普通 Redis 没有区别,要实现读写分离依赖于客户端程序
Sentinel 机制类似于MySQL中的MHA功能,只解决master和slave角色的自动故障转移问题,但单个Master 的性能瓶颈问题并没有解决
Redis 3.0 之前版本中,生产环境一般使用哨兵模式较多,Redis 3.0后推出Redis cluster功能,可以支持更大规模的高并发环境
Sentinel中的三个定时任务
- 每10 秒每个sentinel 对master和slave执行info 发现slave节点 确认主从关系
- 每2秒每个sentinel通过master节点的channel交换信息(pub/sub) 通过sentinel__:hello频道交 交互对节点的“看法”和自身信息
- 每1秒每个sentinel对其他sentinel和redis执行ping
实现哨兵架构
以下案例实现一主两从的基于哨兵的高可用Redis架构
主要是懒得开机器
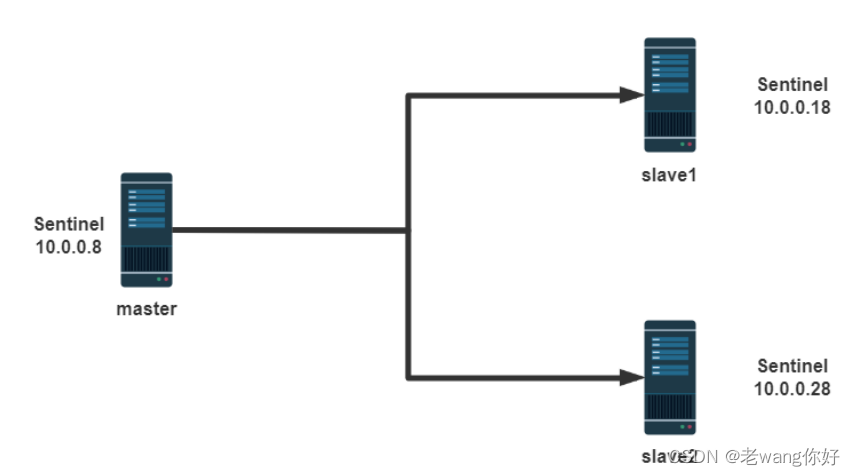
哨兵需要先实现主从复制
哨兵的前提是已经实现了Redis的主从复制
注意: master 的配置文件中masterauth 和slave 都必须相同
所有主从节点的 redis.conf 中关健配置
范例: 准备主从环境配置 #我的脚本编译安装已经有了这一步
#在所有主从节点执行
#基于包安装
[root@centos8 ~]#yum -y install redis
[root@ubuntu2004 ~]#apt -y install redis redis-sentinel···
编辑哨兵配置
Sentinel实际上是一个特殊的redis服务器,有些redis指令支持,但很多指令并不支持.默认监听在
26379/tcp端口.
哨兵服务可以和Redis服务器分开部署在不同主机,但为了节约成本一般会部署在一起,所有redis节点使用相同的以下示例的配置文件
本案例实在主从同步完成之后才实行的
#如果是编译安装,在源码目录有sentinel.conf,复制到安装目录即可,
如:/apps/redis/etc/sentinel.conf
[root@centos8 ~]#cp redis-6.2.5/sentinel.conf /apps/redis/etc/sentinel.conf
[root@centos8 ~]#chown redis.redis /apps/redis/etc/sentinel.conf
[root@centos8 ~]#vim /etc/redis-sentinel.conf
pidfile /apps/redis/run/redis-sentinel.pid #自定义文件
logfile "/apps/redis/log/redis-sentinel.log" #日志文件
sentinel monitor mymaster 10.0.0.100 6379 2 #监控几组 名字可以变
#mymaster是集群的名称,此行指定当前mymaster集群中master服务器的地址和端口
#2为法定人数限制(quorum),即有几个sentinel认为master down了就进行故障转移,一般此值是所有
sentinel节点(一般总数是>=3的 奇数,如:3,5,7等)的一半以上的整数值,比如,总数是3,即3/2=1.5,
取整为2,是master的ODOWN客观下线的依据
sentinel auth-pass mymaster 123456 #密码
#mymaster集群中master的密码,注意此行要在上面行的下面
sentinel down-after-milliseconds mymaster 3000
#判断mymaster集群中所有节点的主观下线(SDOWN)的时间,单位:毫秒,建议3000
sentinel parallel-syncs mymaster 1
这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
sentinel failover-timeout mymaster 180000
#所有slaves指向新的master所需的超时时间,单位:毫秒
sentinel deny-scripts-reconfig yes #禁止修改脚本[root@ubuntu2004 ~]#cd /apps/redis/etc/
[root@ubuntu2004 etc]#chown redis.redis *
#如果是编译安装,可以在所有节点生成新的service文件
[Unit]
Description=Redis Sentinel
After=network.target
[Service]
ExecStart=/apps/redis/bin/redis-sentinel /apps/redis/etc/sentinel.conf --supervised systemd
ExecStop=/bin/kill -s QUIT $MAINPID
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
[root@ubuntu2004 etc]#systemctl daemon-reload
[root@ubuntu2004 etc]#systemctl restart redis.service
#注意所有节点的目录权限,否则无法启动服务
[root@redis-master ~]#chown -R redis.redis /apps/redis/#把配置及文件传到slave1 和2上 注意如果主节点已启动会在最下面生成配置文件,建议在save上启动之前把他删除,不然会起冲突
[root@ubuntu2004 etc]#pwd
/apps/redis/etc
[root@ubuntu2004 etc]# scp -p sentinel.conf 10.0.0.101:/apps/redis/etc/
[root@ubuntu2004 etc]# scp -p sentinel.conf 10.0.0.102:/apps/redis/etc/哨兵 新的service文件
scp /lib/systemd/system/sentinel.service 10.0.0.101:/lib/systemd/system/sentinel.service
scp /lib/systemd/system/sentinel.service 10.0.0.102:/lib/systemd/system/sentinel.service
验证哨兵服务
ss -ntl 是否开启26379
tail -f /var/log/redis/sentinel.log #查看日志是否链接
[root@ubuntu2004 ~]#vim /etc/redis.conf
replica-priority 10 #指定优先级,值越小sentinel会优先将之选为新的master,默为值为100
[root@centos8 ~]#systemctl restart redis]#redis-cli -h 10.0.0.100 -p 26379 #拿一台不相关的机器连下
10.0.0.100:26379> INFO# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_tilt_since_seconds:-1
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=10.0.0.100:6379,slaves=2,sentinels=3
#两个slave,三个sentinel服务器,如果sentinels值不符合,检查myid可能冲突 ,有就欧克了
主断了,又恢复了,不抢走
常用·命令·
127.0.0.1:6379> ROLE #查看机器上的所有主从节点
Sentinel 运维
手动让主节点下线
27.0.0.1:26379> sentinel failover <master Name>
范例: 手动故障转移
[root@ubuntu2004 ~]#vim /etc/redis.conf
replica-priority 10 #指定优先级,值越小sentinel会优先将之选为新的master,默为值为100
[root@ubuntu2004 ~]#systemctl restart redis或者动态修改
[root@centos8 ~]#redis-cli -a 123456
127.0.0.1:6379> CONFIG GET replica-priority
1) "replica-priority"
2) "100"
127.0.0.1:6379> CONFIG SET replica-priority 99
OK
127.0.0.1:6379> CONFIG GET replica-priority
1) "replica-priority"
2) "99"
Redis cluster 架构
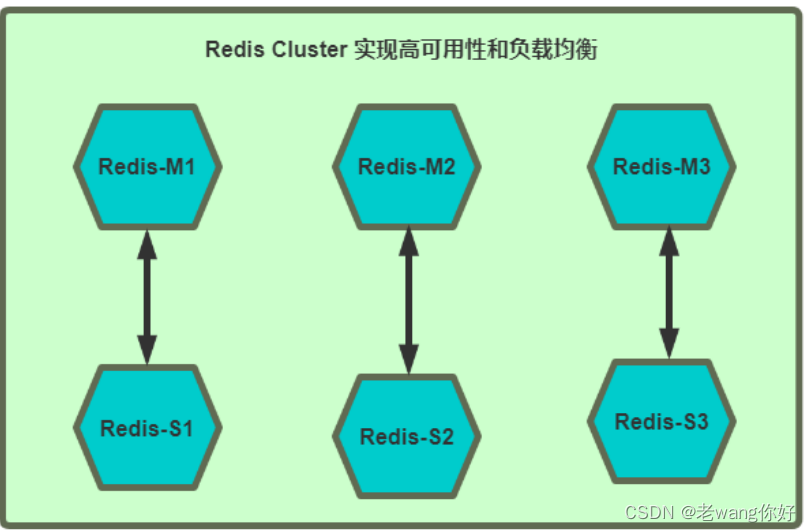
Redis cluster 需要至少 3个master节点才能实现,slave节点数量不限,当然一般每个master都至少对应的有一个slave节点
如果有三个主节点采用哈希槽 hash slot 的方式来分配16384个槽位 slot
此三个节点分别承担的slot 区间可以是如以下方式分配
节点M1 0-5460
节点M2 5461-10922
节点M3 10923-16383

虚拟槽分区 又CRC16算法主导
redis cluster设置有0~16383的槽,每个槽映射一个数据子集,通过hash函数,将数据存放在不同的槽位中,每个集群的节点保存一部分的槽。
每个key存储时,先经过哈希函数CRC16(key)得到一个整数,然后整数与16384取余,得到槽的数值,然后找到对应的节点,将数据存放入对应的槽中。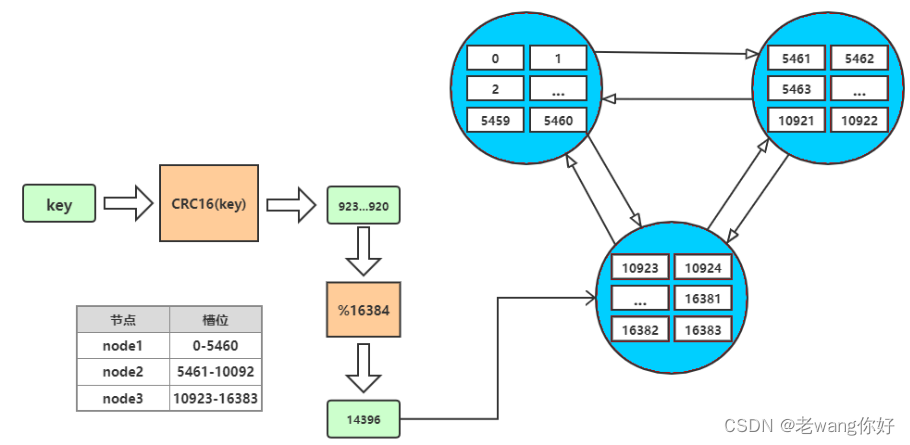
集群通信
但是寻找槽的过程并不是一次就命中的,比如上图key将要存放在14396槽中,但是并不是一下就锁定了
node3节点,可能先去询问node1,然后才访问node3。
而集群中节点之间的通信,保证了最多两次就能命中对应槽所在的节点。因为在每个节点中,都保存了其他节点的信息,知道哪个槽由哪个节点负责。这样即使第一次访问没有命中槽,但是会通知客户端,该槽在哪个节点,这样访问对应节点就能精准命中。
两次命令,他们互相介绍一下就好了
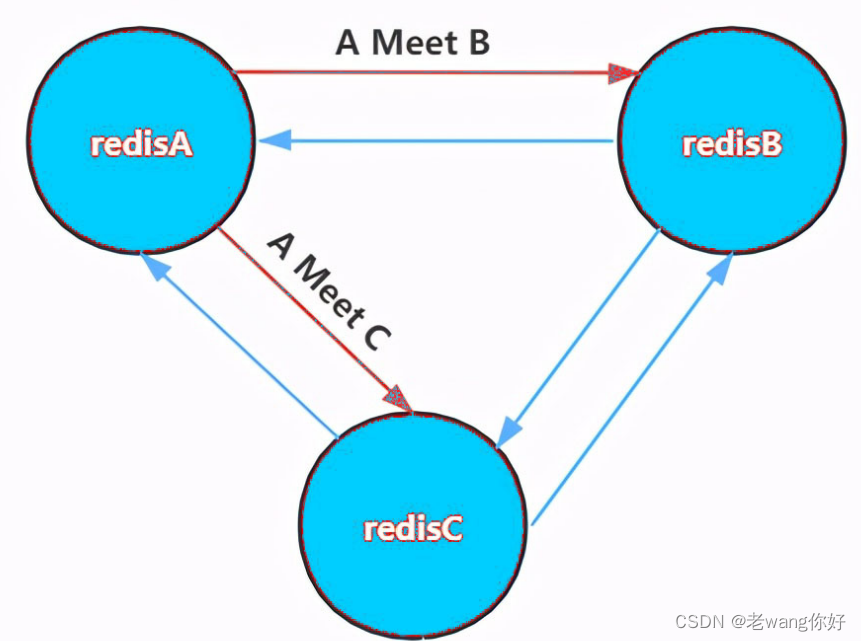
1. 节点A对节点B发送一个meet操作,B返回后表示A和B之间能够进行沟通。
2. 节点A对节点C发送meet操作,C返回后,A和C之间也能进行沟通。
3. 然后B根据对A的了解,就能找到C,B和C之间也建立了联系。
4. 直到所有节点都能建立联系。这样每个节点都能互相知道对方负责哪些槽。
集群伸缩 (介绍)
集群并不是建立之后,节点数就固定不变的,也会有新的节点加入集群或者集群中的节点下线,这就是集群的扩容和缩容。但是由于集群节点和槽息息相关,所以集群的伸缩也对应了槽和数据的迁移 
集群扩容
当有新的节点准备好加入集群时,这个新的节点还是孤立节点,加入有两种方式。一个是通过集群节点
执行命令来和孤立节点握手,另一个则是使用脚本来添加节点。
1. cluster_node_ip:port: cluster meet ip port new_node_ip:port
2. redis-trib.rb add-node new_node_ip:port cluster_node_ip:port
通常这个新的节点有两种身份,要么作为主节点,要么作为从节点:
- 主节点:分摊槽和数据
- 从节点:作故障转移备份

集群缩容

下线节点的流程如下:(介绍)
- 判断该节点是否持有槽,如果未持有槽就跳转到下一步,持有槽则先迁移槽到其他节点
- 通知其他节点(cluster forget)忘记该下线节点
- 关闭下线节点的服务
需要注意的是如果先下线主节点,再下线从节点,会进行故障转移,所以要先下线从节点。
故障转移
除了手动下线节点外,也会面对突发故障。下面提到的主要是主节点的故障,因为从节点的故障并不影响主节点工作,对应的主节点只会记住自己哪个从节点下线了,并将信息发送给其他节点。故障的从节点重连后,继续官复原职,复制主节点的数据。
只有主节点才需要进行故障转移。在之前学习主从复制时,我们需要使用redis sentinel来实现故障转移。而redis cluster则不需要redis sentinel,其自身就具备了故障转移功能。
根据前面我们了解到,节点之间是会进行通信的,节点之间通过ping/pong交互消息,所以借此就能发现故障。集群节点发现故障同样是有主观下线和客观下线的
主观下线

对于每个节点有一个故障列表,故障列表维护了当前节点接收到的其他所有节点的信息。当半数以上的持有槽的主节点都标记某个节点主观下线,就会尝试客观下线
客观下线
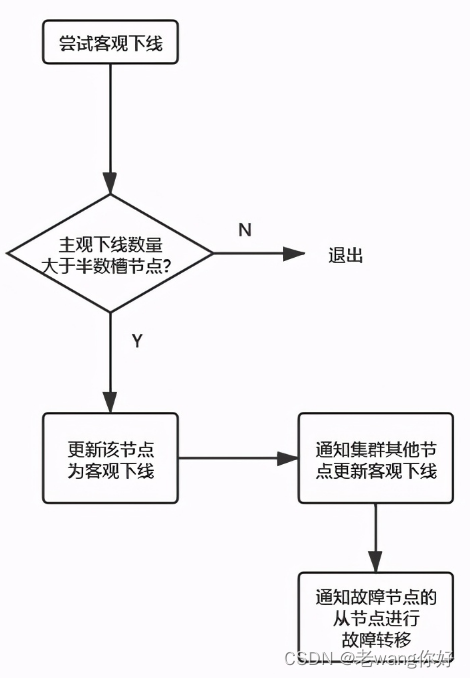
故障转移
集群同样具备了自动转移故障的功能,和哨兵有些类似,在进行客观下线之后,就开始准备让故障节点的从节点“上任”了。
首先是进行资格检查,只有具备资格的从节点才能参加选举:
- 故障节点的所有从节点检查和故障主节点之间的断线时间
- 超过cluster-node-timeout * cluster-slave-validati-factor(默认10)则取消选举资格
然后是准备选举顺序,不同偏移量的节点,参与选举的顺位不同。offset最大的slave节点,选举顺位最高,最优先选举。而offset较低的slave节点,要延迟选举
当有从节点参加选举后,主节点收到信息就开始投票。偏移量最大的节点,优先参与选举就更大可能获得最多的票数,称为主节点。
当从节点走马上任变成主节点之后,就要开始进行替换主节点:
1. 让该slave节点执行slaveof no one变为master节点
2. 将故障节点负责的槽分配给该节点
3. 向集群中其他节点广播Pong消息,表明已完成故障转移
4. 故障节点重启后,会成为new_master的slave节点
启用 redis cluster 配置 (测试)
所有6台主机都执行以下配置
apt -y install redis
- 每个节点修改redis配置,必须开启cluster功能的参数 及一件修改sed
#手动修改配置文件
[root@redis-node1 ~]vim /etc/redis.conf
bind 0.0.0.0
masterauth 123456 #建议配置,否则后期的master和slave主从复制无法成功,还需再配置
requirepass 123456
cluster-enabled yes #取消此行注释,必须开启集群,开启后 redis 进程会有cluster标识
cluster-config-file nodes-6379.conf #取消此行注释,此为集群状态数据文件,记录主从关系
及slot范围信息,由redis cluster 集群自动创建和维护
cluster-require-full-coverage no #默认值为yes,设为no可以防止一个节点不可用导致整
个cluster不可用
#或者执行下面命令,批量修改
[root@redis-node1 ~]#sed -i.bak -e 's/bind 127.0.0.1/bind 0.0.0.0/' -e '/masterauth/a masterauth 123456' -e '/# requirepass/a requirepass 123456' -e '/# cluster-enabled yes/a cluster-enabled yes' -e '/# cluster-config-file nodes-6379.conf/a cluster-config-file nodes-6379.conf' -e '/cluster-require-full-coverage yes/c cluster-require-full-coverage no' /etc/redis.conf
#如果是编译安装可以执行下面操作
[root@redis-node1 ~]#sed -i.bak -e '/masterauth/a masterauth 123456' -e '/# cluster-enabled yes/a cluster-enabled yes' -e '/# cluster-config-file nodes-6379.conf/a cluster-config-file nodes-6379.conf' -e '/cluster-require-full-coverage yes/c cluster-require-full-coverage no' /apps/redis/etc/redis.conf查看是否进去集群模式,进去才能往下做 ,在集群模式下不支持多数据库只支持一数据库


准备 redis-trib.rb 工具 5版本之后就不需要了 (略)
Redis 3和 4版本需要使用到Redis官方推出的管理redis集群的专用工具redis-trib.rb,redis-trib.rb基于ruby开发,所以需要安装ruby的redis 环境模块,但是如果使用CentOS 7系统yum中的ruby版本太低,不支持Redis-trib.rb工具
创建 redis cluster 集群 必须干净!!
#命令redis-cli的选项 --cluster-replicas 1 表示每个master对应一个slave节点
[root@redis-node1 ~]#redis-cli -a 123456 --cluster create 10.0.0.101:6379 10.0.0.102:6379 10.0.0.103:6379 10.0.0.104:6379 10.0.0.105:6379 10.0.0.106:6379 --cluster-replicas 1 #只要是相关节点上就可以执行
M: cb028b83f9dc463d732f6e76ca6bbcd469d948a7 10.0.0.8:6379 #带M的为master
slots:[0-5460] (5461 slots) master #当前master的槽位起始
和结束位
M: 99720241248ff0e4c6fa65c2385e92468b3b5993 10.0.0.18:6379
slots:[5461-10922] (5462 slots) master
M: d34da8666a6f587283a1c2fca5d13691407f9462 10.0.0.28:6379
slots:[10923-16383] (5461 slots) master
S: f9adcfb8f5a037b257af35fa548a26ffbadc852d 10.0.0.38:6379 #带S的slave
replicates cb028b83f9dc463d732f6e76ca6bbcd469d948a7
S: d04e524daec4d8e22bdada7f21a9487c2d3e1057 10.0.0.48:6379
replicates 99720241248ff0e4c6fa65c2385e92468b3b5993
S: 9875b50925b4e4f29598e6072e5937f90df9fc71 10.0.0.58:6379
replicates d34da8666a6f587283a1c2fca5d13691407f9462
Can I set the above configuration? (type 'yes' to accept): yes #输入yes自动创建集群
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
....
>>> Performing Cluster Check (using node 10.0.0.8:6379)
M: cb028b83f9dc463d732f6e76ca6bbcd469d948a7 10.0.0.8:6379
slots:[0-5460] (5461 slots) master #已经分配的槽位
1 additional replica(s) #分配了一个slave
S: 9875b50925b4e4f29598e6072e5937f90df9fc71 10.0.0.58:6379
slots: (0 slots) slave #slave没有分配槽位
replicates d34da8666a6f587283a1c2fca5d13691407f9462 #对应的master的10.0.0.28的
ID
S: f9adcfb8f5a037b257af35fa548a26ffbadc852d 10.0.0.38:6379
slots: (0 slots) slave
replicates cb028b83f9dc463d732f6e76ca6bbcd469d948a7 #对应的master的10.0.0.8的ID
S: d04e524daec4d8e22bdada7f21a9487c2d3e1057 10.0.0.48:6379
slots: (0 slots) slave
replicates 99720241248ff0e4c6fa65c2385e92468b3b5993 #对应的master的10.0.0.18的
ID
M: 99720241248ff0e4c6fa65c2385e92468b3b5993 10.0.0.18:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: d34da8666a6f587283a1c2fca5d13691407f9462 10.0.0.28:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration. #所有节点槽位分配完成
>>> Check for open slots... #检查打开的槽位
>>> Check slots coverage... #检查插槽覆盖范围
[OK] All 16384 slots covered. #所有槽位(16384个)分配完成
#如果节点少于3个会出下面提示错误
[root@node1 ~]#redis-cli -a 123456 --cluster create 10.0.0.8:6379
10.0.0.18:6379
Warning: Using a password with '-a' or '-u' option on the command line interface
may not be safe.
*** ERROR: Invalid configuration for cluster creation.
*** Redis Cluster requires at least 3 master nodes.
节点相关信息文件,及简单信息
[root@node2 ~]#cat /apps/redis/data/nodes-6379.conf 
ROLE 查看谁是我的从
redis-cli -a 123456 -c #加上-c就会自动跳转了,查看和访问了
不支持跨槽位查看(不能一次看多个,查看多个)
[root@node2 ~]#redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> set K2 2
(error) MOVED 1831 10.0.0.101:6379 #他有哈希,所以会指定你去哈希过后的地址写入和写出
127.0.0.1:6379>
[root@node2 ~]#redis-cli -a 123456 -c #加上-c就会自动跳转了,查看和访问了
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> set K2 2
-> Redirected to slot [1831] located at 10.0.0.101:6379
OK
10.0.0.101:6379>
他这个只能在主上读写,不能再从上,从的作用就是主死了我替他,然后没了
他的性能并不是之前的3倍,因为他有CRC校验
Redis 5 以上版本的添加命令: 必须清空数据
主
将一台新的主机10.0.0.107加入集群,以下示例中10.0.0.102可以是任意存在的集群节点
redis-cli -a 123456 --cluster add-node 10.0.0.107:6379 10.0.0.102:6379
····················································
[OK] All 16384 slots covered.
>>> Getting functions from cluster
>>> Send FUNCTION LIST to 10.0.0.107:6379 to verify there is no functions in it
>>> Send FUNCTION RESTORE to 10.0.0.107:6379
>>> Send CLUSTER MEET to node 10.0.0.107:6379 to make it join the cluster.
[OK] New node added correctly.
观察到该节点已经加入成功,但此节点上没有slot位,也无从节点,而且新的节点是master
[root@ubuntu2004 ~]#redis-cli -a 123456 --cluster reshard 10.0.0.105:6379
redis-cli -a 123456 --cluster info 10.0.0.105:6379
How many slots do you want to move (from 1 to 16384)?4096 #新分配多少个槽位=16384/master个数
What is the receiving node ID? d6e2eca6b338b717923f64866bd31d42e52edc98 #新的master的ID
Source node #1: all #输入all,将哪些源主机的槽位分配给新的节点,all是自动在所有的redis
node选择划分,如果是从redis cluster删除某个主机可以使用此方式将指定主机上的槽位全部移动到别的
redis主机
Do you want to proceed with the proposed reshard plan (yes/no)? yes 从
查看当前集群节点,找到目标master 的ID 随便在哪台执行都行
redis-cli -a 123456 --cluster add-node 10.0.0.108:6379 10.0.0.103:6379 --cluster-slave --cluster-master-id 7939186faa260d057a3f3b7168ac92cf81d5b3d9
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 10.0.0.108:6379 to make it join the cluster.
Waiting for the cluster to join
>>> Configure node as replica of 10.0.0.107:6379.
[OK] New node added correctly.
ok了
集群缩容
缩容适用场景:
随着业务萎缩用户量下降明显,和领导商量决定将现有Redis集群的8台主机中下线两台主机挪做它用,缩容后性能仍能满足当前业务需求
删除节点过程:
扩容时是先添加node到集群,然后再分配槽位,而缩容时的操作相反,是先将被要删除的node上的槽位迁移到集群中的其他node上,然后 才能再将其从集群中删除,如果一个node上的槽位没有被完全迁移空,删除该node时也会提示有数据出错导致无法删除。
迁移要删除的master节点上面的槽位到其它master
注意: 被迁移Redis master源服务器必须保证没有数据,否则迁移报错并会被强制中断。
如此重复直至还完,还多少是自己分配的自己算 槽位干净后自动沦为从节点
[root@ubuntu2004 ~]#redis-cli -a 123456 --cluster reshard 10.0.0.105:6379
··························
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365 #分配多少
What is the receiving node ID? 51c482fd6103c5a5cd70a071986db0308dd9741 #分配到谁
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 7939186faa260d057a3f3b7168ac92cf81d5b3d9 #从谁哪里减去
Source node #2: done #支持多个 done结束
从集群中删除服务器 5以上
上面步骤完成后,槽位已经迁移走,但是节点仍然还属于集群成员,因此还需从集群删除该节点
注意: 删除服务器前,必须清除主机上面的槽位,否则会删除主机失败
redis-cli -a 123456 --cluster del-node 10.0.0.104:6379 7939186faa260d057a3f3b7168ac92cf81d5b3d9 #是删除节点的ID导入现有Redis数据至集群
6.2.4有问题
官方提供了迁移单个Redis节点数据到集群的工具,有些公司开发了离线迁移工具
- 官方工具: redis-cli --cluster import
- 第三方在线迁移工具: 模拟slave 节点实现, 比如: 唯品会 redis-migrate-tool , 豌豆荚 redis-port
基础环境准备
因为导入时不能指定验证密码,所以导入数据之前需要关闭所有Redis 节点的密码。
#新版在所有节点需要关闭protected-mode
[root@ubuntu2204 ~]#sed -i '/^protected-mode/c protected-mode no'
/apps/redis/etc/redis.conf;systemctl restart redis#在所有节点包括master和slave节点上关闭各Redis密码认证
[root@redis ~]# redis-cli -h 10.0.0.18 -p 6379 -a 123456 --no-auth-warning
CONFIG SET requirepass ""
OK
#取消需要导入的主机的密码 在所有的机器上都执行发一遍
[root@centos8 ~]#redis-cli -h 127.0.0.1 -p 6379 -a 123456 --no-auth-warning CONFIG SET requirepass ""
redis-cli -h 127.0.0.1 -p 6379 -a 123456 --no-auth-warning CONFIG SET requirepass ""
OK
#导入数据至集群
#注意: Redis6.2.4版本在cluster集群的任意节点或非集群节点执行下面操作导入大量数据时都会出
现"Segmentation fault"的错误
#Redis6.2.4版本的集群导入大量数据时,如果是在非集群的外部节点Redis5执行下面操作却可以成功
#在CentOS8上的Redis5版本集群则没有此问题
redis-cli --cluster import 10.0.0.101:6379 --cluster-from 10.0.0.200:6379 --cluster-copy --cluster-replace
#如果有保护模式需要全部退出保护模式 全部! 先执行这步,重启后会重新加载密码,还需要重新禁用
[root@node4 ~]#sed -i '/^protected-mode/c protected-mode on' /apps/redis/etc/redis.conf
[root@node4 ~]#systemctl restart redis.service集群偏斜
redis cluster 多个节点运行一段时间后,可能会出现倾斜现象,某个节点数据偏多,内存消耗更大,或者接受用户请求访问更多 发生倾斜的原因可能如下:
- 节点和槽分配不均
- 不同槽对应键值数量差异较大
- 包含bigkey,建议少用
- 内存相关配置不一致
- 热点数据不均衡 : 一致性不高时,可以使用本缓存和MQ
获取指定槽位中对应键key值的个数
#redis-cli cluster countkeysinslot {slot的值}
范例: 获取指定slot对应的key个数
[root@node4 ~]#redis-cli -a 123456 cluster countkeysinslot 1
(integer) 0
[root@node4 ~]#redis-cli -a 123456 cluster countkeysinslot 2
(integer) 0
[root@node4 ~]#redis-cli -a 123456 cluster countkeysinslot 3
(integer) 1
执行自动的槽位重新平衡分布,但会影响客户端的访问,此方法慎用
#redis-cli --cluster rebalance <集群节点IP:PORT>
获取bigkey ,建议在slave节点执行 #查看大K
#redis-cli --bigkeys















 172
172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









