







1.引入
(1)Filter的限制
作为Servlet的补充,Filter也是很有用的,但是filter并没有被设计用来完成一切事情。事实上,filter具有下面的使用限制
1)filter可以访问和修改数据,但是它之恩能够访问和修改HttpServletRequest、HttpServletResponse、ServletContext等容器级的对象,而不能访问应用程序中的状态,所以filter无法实现和应用逻辑密切相关的功能
2)filter可以影响执行流程。但是不嗯能够改变filter chain的结构和顺序。Filter chain的结构和顺序是由web.xml中定义的。filter得到控制权之后,它只能选择执行下去或者立即结束,而没法进行循环、分支、条件判断等更复杂的控制。因此,filter只能用来实现粗粒度的流程控制。
3)filter与其他filter和servlet之间,除了Request和response对象之外,无法共享其他状态
(2)Webx对Filter的补充
一个filter常常做的两件事就是:
1)改变request/response对象(通过HttpServletRequestWrapper、HttpServletResponseWrapper)
2)改变应用执行的流程其实,大部分filter只做其中一件事情。例如
1)页面压缩filter仅仅改变response,并不改变流程
2)页面授权filter根据当前请求用户的身份,判定他是否有权限访问当前页面,这个filter会影响流程,但是不会去改变request和response
Webx框架提供了2个服务,正好吻合了上面两个最常用的filter功能
1>Request Contexts服务 该服务负责访问和修改request和response,但不负责改变应用执行的流程
2>Pipeline服务 提供应用执行的流程,但是不关心request和response
2.Request Contexts服务
(1)工作原理
Request Context,顾名思义,就是一个请求上下文。事实上,可以吧Request Context看做是HttpServletRequest和HttpServletResponse这两个对象的综合。除此之外,多个Request Context可以被串接起来,被称为Request Context Chain,类似于Filter Chain
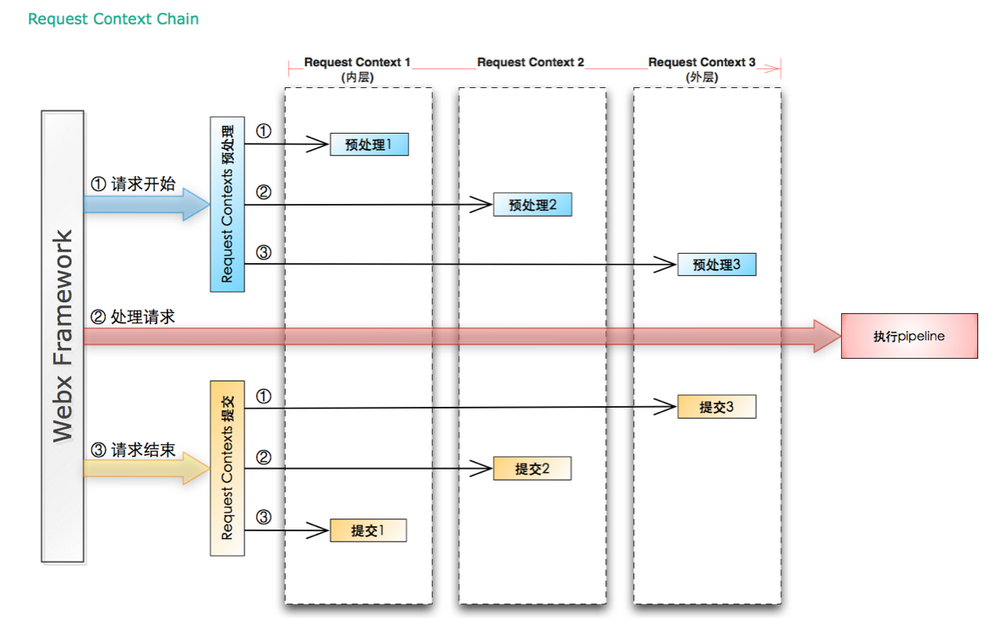
如图所示,每一个Request Context都可以包括两个基本的操作:预处理和提交
1)在一个请求开始的时候,每个Request Context的预处理过程被一次调用。最内层的(即最先的)Request Context最先被调用,最外层的(即最后的)Request Context被最后调用
2)在一个请求结束的时候,每个Request Context的提交过程被依次调用。和预处理相反,最外层的Request Context最先被调用,最内层的最后被调用
Request Context在预处理的时候,可以利用HttpServletRequestWrapper和HttpServletResponseWrapper来包装盒修改request和response。这一点和filter相同,每层Request Context都会增加一个新的特性。
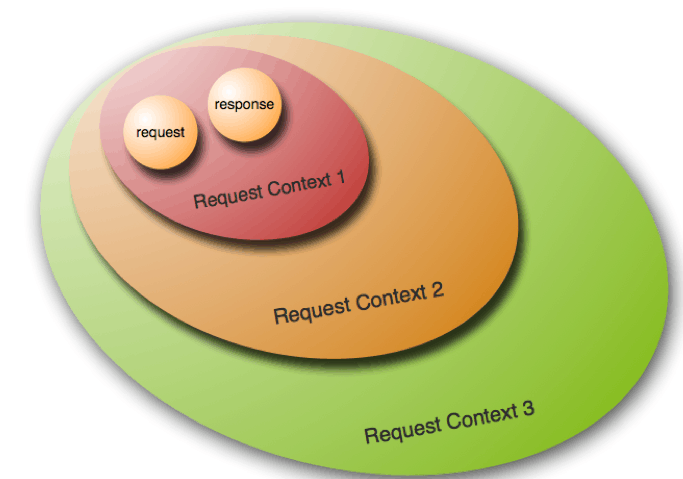
(2)用途
Webx提供了以下几种Request Context的实现,每个都有独特的功能(注意,一个标签代表一个Request Contexts)

(3)使用
1)配置除了下面的一段配置之外,不需要太多的事就可以使用Request Contexts。
<?xml version="1.0" encoding="UTF-8" ?>
<beans:beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:services="http://www.alibaba.com/schema/services"
xmlns:request-contexts="http://www.alibaba.com/schema/services/request-contexts"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="
http://www.alibaba.com/schema/services
http://localhost:8080/schema/services.xsd
http://www.alibaba.com/schema/services/request-contexts
http://localhost:8080/schema/services-request-contexts.xsd
http://www.springframework.org/schema/beans
http://localhost:8080/schema/www.springframework.org/schema/beans/spring-beans.xsd
">
...
<services:request-contexts xmlns="http://www.alibaba.com/schema/services/request-contexts">
<basic />
<buffered />
<lazy-commit />
<parser />
<set-locale defaultLocale="zh_CN" defaultCharset="UTF-8" />
<!-- Optional -
<session />
<rewrite />
-->
</services:request-contexts>
<services:upload sizeMax="5M" />
</beans:beans> 2)排序
Request Contexts之间有时候会有依赖关系,Request Contexts出现的先后顺序是非常重要的。例如:
<session>提供了基于cookie的session支持。然而cookie属于response header,一旦response提交,header就无法再修改了。因此<session>依赖于<lazy-commit>,以阻止response过早提交,也就是说,<lazy-commit>必须排在<session>之前。
如果把Request Contexts的顺序排错,可能会导致某项功能错误,好在webx提供了一个机制,可以根据预定义的约束条件,对所有的Request Contexts进行自动排序。和filter不同,开发者不需要在意Request Contexts在配置文件中的排列顺序,就可以保证所有的Request Contexts能够正常工作。

以上两种配置是等效的。
3.Pipeline服务
(1)工作原理
Pipeline意思是管道,管道中有许多阀门(Valve),阀门可以控制水流的走向。在Webx中,Pipeline的作用就是控制应用程序流程的走向
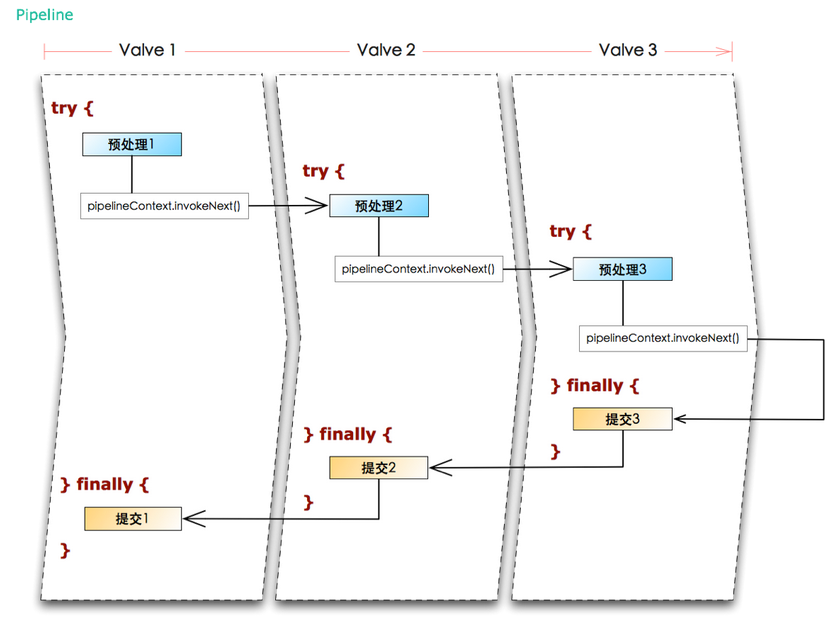
Pipeline的设计和filter非常类似,也是击鼓传花的流程控制,但是有以下几点不同
1)Pipeline只能控制流程,不能改变Request和Response
2)Pipeline支持更复杂的流程结构,如分之条件、循环等
(2)用途
利用Pipeline,可以定制一个请求处理过程的每一步<?xml version="1.0" encoding="UTF-8" ?>
<beans:beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:services="http://www.alibaba.com/schema/services"
xmlns:pl-conditions="http://www.alibaba.com/schema/services/pipeline/conditions"
xmlns:pl-valves="http://www.alibaba.com/schema/services/pipeline/valves"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="
http://www.alibaba.com/schema/services
http://localhost:8080/schema/services.xsd
http://www.alibaba.com/schema/services/pipeline/conditions
http://localhost:8080/schema/services-pipeline-conditions.xsd
http://www.alibaba.com/schema/services/pipeline/valves
http://localhost:8080/schema/services-pipeline-valves.xsd
http://www.springframework.org/schema/beans
http://localhost:8080/schema/www.springframework.org/schema/beans/spring-beans.xsd
">
<services:pipeline xmlns="http://www.alibaba.com/schema/services/pipeline/valves">
<!-- 初始化turbine rundata,并在pipelineContext中设置可能会用到的对象(如rundata、utils),以便valve取得。 -->
<prepareForTurbine />
<!-- 设置日志系统的上下文,支持把当前请求的详情打印在日志中。 -->
<setLoggingContext />
<!-- 分析URL,取得target。 -->
<analyzeURL homepage="homepage" />
<!-- 检查csrf token,防止csrf攻击和重复提交。 -->
<checkCsrfToken />
<loop>
<choose>
<when>
<!-- 执行带模板的screen,默认有layout。 -->
<pl-conditions:target-extension-condition extension="null, vm, jsp" />
<performAction />
<performTemplateScreen />
<renderTemplate />
</when>
<when>
<!-- 执行不带模板的screen,默认无layout。 -->
<pl-conditions:target-extension-condition extension="do" />
<performAction />
<performScreen />
</when>
<otherwise>
<!-- 将控制交还给servlet engine。 -->
<exit />
</otherwise>
</choose>
<!-- 假如rundata.setRedirectTarget()被设置,则循环,否则退出循环。 -->
<breakUnlessTargetRedirected />
</loop>
</services:pipeline>
</beans:beans>2)<analyzeURL>
分析URL,目的是为了得到target。
由于用户访问的url中没有提供path信息,通常被理解为用户想要访问主页。analyzeURL valve提供了一个可选的参数homepage,即在这种情况下起作用:http://localhost:8081/对应的target为homepage。
3)<choose>
多重分支。
显然homepage满足了第一个<when>所附带的条件
<pl-conditions:target-extension-condition extension="null, vm, jsp, jspx" />4)<performAction>
执行Action。webx这里的action是用来处理用户提交的表单的。
因为本次请求没有提供action参数,所以跳过该步骤。
一般在表单中都有这一句:
<input type="hidden" name="action" value="LoginAction"/>实际上在Webx2中是这样写的
<valve class="com.alibaba.turbine.pipeline.PerformActionValve" actionParam="action">5)<performTemplateScreen>
查找并执行screen。这里需要用到target映射成screen module类名的规则:
假设target为xxx/yyy/zzz,那么Webx会依次查找下面的screen模块

本次请求的target为homepage,因此它会尝试查找screen.Homepage和screen.Default这两个类。
如果找到screen类,Webx就会执行它。Screen类的功能,通常是读取数据库,把模板需要的对象放到context中
如果找不到,也没有关系--这就是页面优先:像homepage这样的主页,通常没有业务逻辑,因此不需要Screen类,只要有模板就可以了
6)<renderTemplate>
渲染模板。
这里用到了2个规则:target映射成screen template,以及target映射成layout template
假设target为xxx/yyy/zzz,那么Webx会查找下面的的screen模板/templates/screen/xxx/yyy/zzz。如果未找到,就会报404错误,找到之后,Webx还会尝试查找下面的layout模板

layout模板如果找不到,就直接渲染screen模板,如果存在,则把渲染screen模板后的结果嵌入到layout模板中。
7)<breakUnlessTargetRedirected>
在screen和action中,可以进行内部重定向。内部重定向实质就是由<breakUnlessTargetRedirected>实施的--如果没有重定向标记,就退出;否则循环到<loop>标签。
和外部重定向不同,外部重定向是向浏览器返回一个302或303 response,其中包含Location header,浏览器看到这样的response以后,就会发出第二个请求。而内部重定向发生在pipeline内部,浏览器并不了解内部重定向。















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









