







1.分布式数据方案提供的功能
(1)提供分库规则和路由规则
(2)引入集群概念,保证数据的高可用性
(3)引入负载均衡策略
(4)引入集群节点的可用性探测机制,对单点机器的可用性进行定时的侦测,以保证负载均衡策略的正确实施,以确保系统的高度稳定性
(5)引入读写分离,提高数据的查询速度
2.集群与读写分离
(1)引入
仅仅是分库分表的数据层设计也是不够完善的,当某个节点上的DB宕机了,会是什么样子呢?我们采用了数据库切分方案,也就是说有N台机器组成了完整的DB,如果有一台机器宕机了,实际上也就是一个DB的N分之一的数据不能访问了而已,一般应用中这是可以接受的,但是如果是像淘宝这样的高并发网站呢?单点机器宕机带来的经济损失是非常严重的。这里我们就可以引入集群这个概念来解决这个问题。
(2)集群
1>概念
集群也成为Group,也就是每一个分库的节点我们引入多台机器,每台机器保存的数据是一样的,一般情况下这多台机器分摊负载,在出现宕机情况时,负载均衡器将不会分配负载给这台宕机的机器,这样一来就解决了容错性问题。
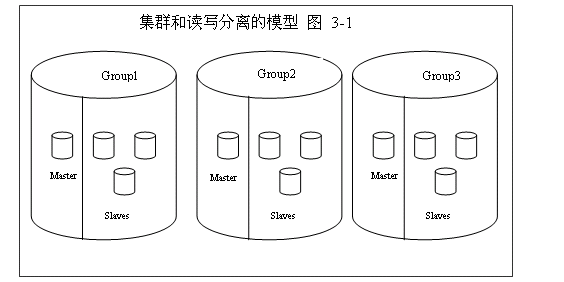
如图所示,整个数据层有Group1,Group2,Group3三个集群,这三个集群就是数据水平切分的结果,当然这三个集群也就组成了一个包含完整数据的DB。
每一个集群包括一个Master(当然可以有多个Master),N个slave,这些master和slave的数据是一致的。比如Group1中的一个slave发生了宕机,那么还有两个slave是可以用的。这样的模型总是不会造成某部分的数据不能访问的问题,除非整个Group里面的机器全部宕机,但是发生这种事情的概率非常小。
2>集群路由
在没有引入集群以前,我们一次查询的过程大致如下:请求数据层,并传递必要的分库字段(比如user_id),数据层会根据该字段路由到具体的DB,在这个DB进行查询操作。这是没有引入集群的情况,那么我们引入集群之后是什么样子呢?看图可知,我们的路由规则实际上只能定位到具体的Group,但是这个Group并不是某个特定的物理服务器。接下来的工作就是要找到具体的物理DB服务器。基于这样的需求,我们引入了负载均衡器。负载均衡器的职责就是定位到一台具体的DB服务器。具体的规则就是:负载均衡器会分析当前sql的读写特性,如果是写操作或者是要求实时性很强的操作的话,直接将查询负载分到master,如果是一般的读操作,则通过负载均衡器策略分配到一个slave。
负载均衡策略:
一:随机负载均衡
也就是从N个slave中随机选取一个slave,这样的随机负载均衡是不考虑机器性能的,它默认每台机器的性能都是一样的。
但是实际情况显然不会是这样,每个slave的机器物理性能和配置不一样,如果再使用随机负载均衡而不考虑性能,是非常不合理的,这样一来会给性能差的机器带来不必要的高负载,甚至带来宕机的危险,同时高性能的机器也不能充分发挥其物理性能。基于此考虑,我们引入了甲醛负载均衡
二:加权负载均衡
也就是说我们可以根据机器的性能,对每一台机器进行加权处理计算出一个权值,在运行时LB根据权值在集群中的比重,分配一定比例的负载给指定的DB服务器。当然这样无疑增大了系统的复杂性和可维护性,但是有得必有失,也没有办法避免。
(3)集群节点可用性
1)引入
有了分库,有了集群,有了负载均衡器,是不是就万事大吉了呢?虽然有了这些东西,基本上能保证我们的数据层可以承受很大的压力,但是这样的设计并不能完全规避数据库宕机的危害。假如Group1中的slave2宕机了,那么系统的LB并不能得知,这样的话是很危险的,因为LB不知道,它还会以为slave2为可用状态,所以还是会给slave2分配负载。这样一来,问题就出来了,客户端很自然的就会发生数据操作失败的异常,这样是很不友好的,怎么解决这样的问题呢?
2)集群节点的可用性探测机制
也就是我们的数据层客户端,不定时对集群中各个数据库进行可用性的探测,实现原理就是尝试性链接,或者数据库端口的尝试性访问,当然也可以使用jdbc的尝试性连接,利用java的exception进行可用性判断
3)集群节点的可用性数据推送机制
一般情况下DB宕机的话DBA肯定是知道的,这个时候DBA手动将数据库的当前状态通过程序的方式推送到客户端,也就是分布式数据层的应用端,这个时候再更新一个本地的DB状态的列表,并且告诉LB,这个数据库节点不能使用,请不要给他分配负载,
(4)集群读写分离
一般情况下,一个Group由1个master和n个slave组成,为什么这么做呢?
其中的master负责写操作的负载,也就是说一切的写操作都在master上进行,而读操作则分摊到slave上进行,这样一来可以大大提高读取的效率。
一般互联网应用中,读写的比例大概在10:1,也就是说大量的数据库操作集中在读操作上,这也就是我们为什么会有多个slave的原因。
为什么要进行读写分离呢?因为写操作设计到锁的问题,不管是行锁还是表锁还是块锁,都是比较降低系统执行效率的事情,我们这样的分离是把写操作集中在一个节点上,而读操作在其他N个节点上进行,从另一个方面提高了读的效率。但是读写分离也会导致新的问题:比如我们的master上的数据怎样和集群中其他slave中的数据保持一致呢?这点其实不用担心,mysql的proxy机制可以帮助我们做到这点。

















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









