







(1)涉及编码的请求流程
用户在发出一个http请求 的时候,涉及编码的有:url、cookie、http header、http body。
服务器端接受到http请求后要进行解析,其中url、cookie和post表单数据需要解码,这些可能会存在编码问题。

(2)编码解码
1.url
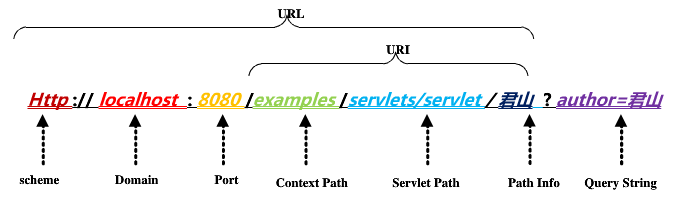
(1)乱码产生原因
uri中可能涉及到中文的servlet;
使用get方式发送请求,参数可能是中文
(2)使用的编码
对于url,不同浏览器使用的编码可能不一样,而且编码策略也有可能不一样
(3)uri编解码(不包含参数)
显然uri传输过来是以byte[]的形式,tomcat对uri解码的编码如下:
protected void convertURI(MessageBytes uri, Request request)
throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
String enc = connector.getURIEncoding(); //获取URI解码集
if (enc != null) {
B2CConverter conv = request.getURIConverter();
try {
if (conv == null) {
conv = new B2CConverter(enc);
request.setURIConverter(conv);
}
} catch (IOException e) {...}
if (conv != null) {
try {
conv.convert(bc, cc, cc.getBuffer().length - cc.getEnd());
uri.setChars(cc.getBuffer(), cc.getStart(), cc.getLength());
return;
} catch (IOException e) {...}
}
}
// Default encoding: fast conversion
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}<Connector URIEncoding="utf-8" /> (4)url中参数编码
这些参数都保存在Parameters中,对他们的解码都是在getParameter中进行的,过程如下:
//获取编码
String enc = getCharacterEncoding();
//获取ContentType 中定义的 Charset
boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI();
if (enc != null) { //如果设置编码不为空,则设置编码为enc
parameters.setEncoding(enc);
if (useBodyEncodingForURI) { //如果设置了Chartset,则设置queryString的解码为ChartSet
parameters.setQueryStringEncoding(enc);
}
} else { //设置默认解码方式
parameters.setEncoding(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
}
}可以看出,如果在Connector中配置了useBodyEncoding,那么就使用ContentType中的编码
<Connector URIEncoding="UTF-8" useBodyEncodingForURI="true"/> 3.Http Header
(1)乱码产生原因
Http Header中存储了cookie、redirectPath等信息,这些信息我们可以设置,那么就会存在编码问题
而Tomcat中是使用ISO-8859-1进行编码的,且我们无法改变编码格式,所以如果其中含有中文,必然就会出现乱码
(2)注意
我们设置cookie、redirectPath等Http Header中的信息时,一定不能使用中文
如果一定要使用,可以使用URLEncoder进行编码,使用的时候再进行解码即可
4.Http Body
(1)发送请求
Http Body中的的数据,都是通过ContentType中的Charset来进行的编码的。
服务器端也是使用ContentType中定义的Charset来进行解码的
(2)返回响应
浏览器是根据HTML中的<meta HTTP-equiv=“Content-Type” content=”text/html; charset=GBK”>中的charset来进行解码的,如果没有定义,浏览器就会使用自己默认的编码
(3)编码解码具体处理方式
1.get
如果是以get方式提交的请求,那么参数就会放在url中根据前面的描述,这种参数首先会根据contentType中定义的编码集来进行解码,然后发送请求,接着服务器会看是否设置了useBodyEncodingForURI=true,如果设置了则会从ContentType中取出字符集,如果没有设置,就使用ISO-8859-1进行解码。
如果我们的页面的contentType=utf-8,又没有设置服务器设置使用contentType进行解码,那么直接使用就会出现乱码
所以我们需要先对参数进行ISO-8859-1编码,然后再用utf-8解码即可,具体如下:
String zhongwen = request.getParameter("zhongwen");
zhongwen = new String(zhongwen.getBytes("iso8859-1"),"UTF-8");所以get方式出现乱码解决步骤:
1)检查页面head的编码设置
2)检查服务器的解码设置
3)检查是否进行了先编码再解码的过程
2.post
如果是以post方式提交的请求,其编码也是由contentType决定的,而服务器解码就是使用这个contenttype,所以一般不会有问题。而这个我们也可以进行设置:
request.setCharacterEncoding(charset)所以post方式出现乱码解决步骤:
1)检查页面head的编码设置
2)在servlet中检查编码 request.getCharacterEncoding(),如果不是可以通过request.setCharacterEncoding(charset)进行设置
eg:可以使用filter,对编码进行设置
过滤器代码:
package filter;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import wrapper.GetHttpServletRequestWrapper;
public class ContentTypeFilter implements Filter {
private String charset = "UTF-8";
private FilterConfig config;
public void destroy() {
System.out.println(config.getFilterName()+"被销毁");
charset = null;
config = null;
}
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
//设置请求响应字符编码
request.setCharacterEncoding(charset);
response.setCharacterEncoding(charset);
HttpServletRequest req = (HttpServletRequest)request;
System.out.println("----请求被"+config.getFilterName()+"过滤");
//执行下一个过滤器(如果有的话,否则执行目标servlet)
chain.doFilter(req, response);
System.out.println("----响应被"+config.getFilterName()+"过滤");
}
public void init(FilterConfig config) throws ServletException {
this.config = config;
String charset = config.getServletContext().getInitParameter("charset");
if( charset != null && charset.trim().length() != 0)
{
this.charset = charset;
}
}
} <!--将采用的字符编码配置成应用初始化参数而不是过滤器私有的初始化参数是因为在JSP和其他地方也可能需要使用-->
<context-param>
<param-name>charset</param-name>
<param-value>UTF-8</param-value>
</context-param>
<filter>
<filter-name>ContentTypeFilter</filter-name>
<filter-class>filter.ContentTypeFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>ContentTypeFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>














 1228
1228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









