






基本介绍
\\Apache Arrow是一种基于内存的列式数据结构,正像上面这张图的箭头,它的出现就是为了解决系统到系统之间的数据传输问题,2016年2月Arrow被提升为Apache的顶级项目。
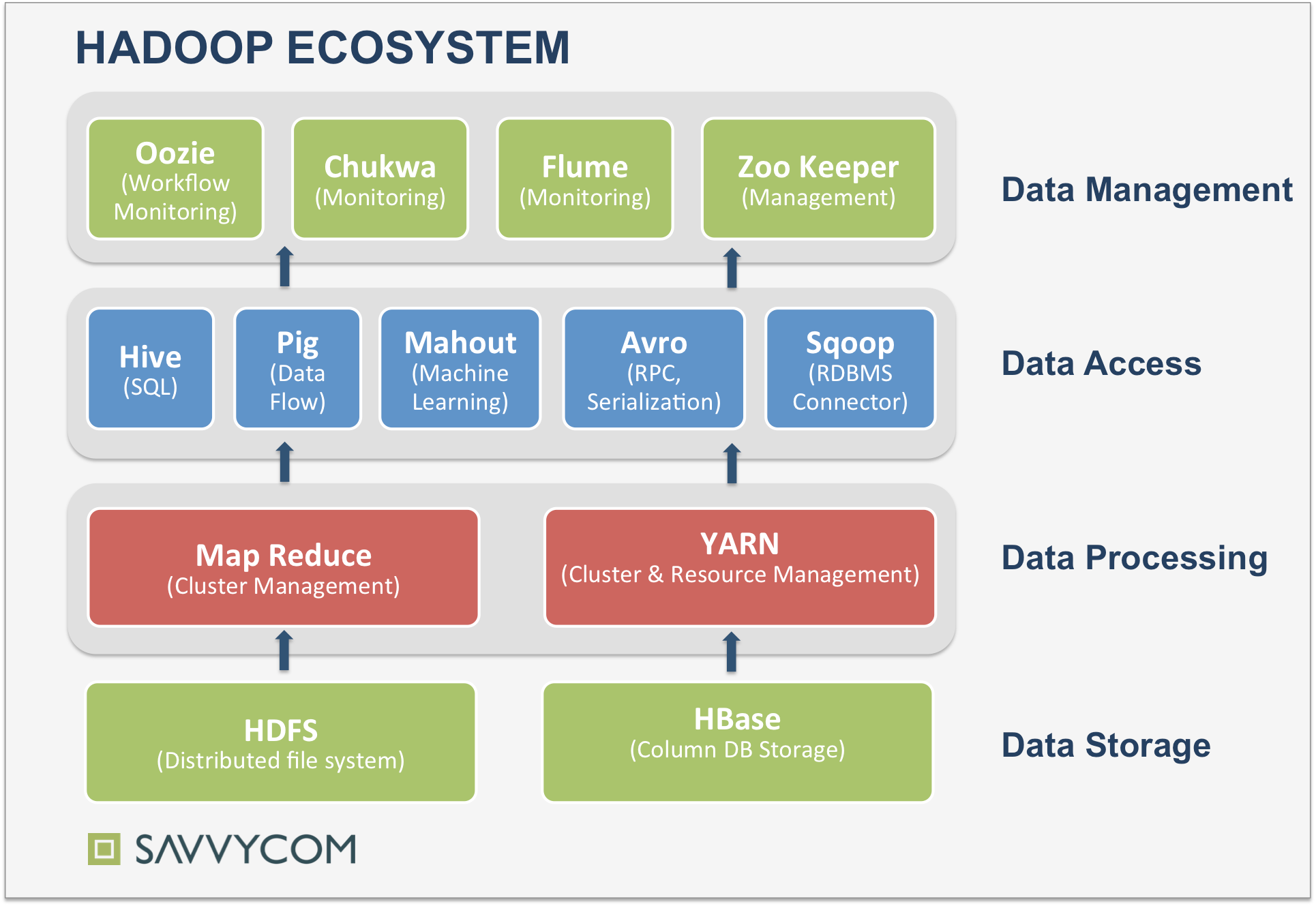
\\在分布式系统内部,每个系统都有自己的内存格式,大量的CPU资源被消耗在序列化和反序列化过程中,并且由于每个项目都有自己的实现,没有一个明确的标准,造成各个系统都在重复着复制、转换工作,这种问题在微服务系统架构出现之后更加明显,Arrow的出现就是为了解决这一问题。作为一个跨平台的数据层,我们可以使用Arrow加快大数据分析项目的运行速度。下面这张图概括了Hadoop生态系统,本身就分为4层,每层又有若干组件,而且还在不断扩大系统范围,如果各个系统之间都需要进行序列化和反序列化,消耗巨大。
\\
相关技术
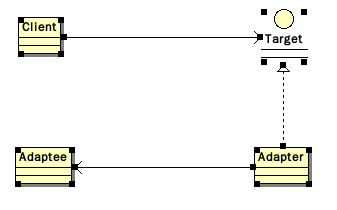
\\- 适配器模式\
适配器模式是经典的23种设计模式之一,它的主要作用是在新接口和老接口之间进行适配,可以让客户方便使用,不需要改造自身的产品,如下图所示。
\\
虽然Apache Arrow的实现细节远不止适配器模式,但是它从功能设计思路来看,还是有点像的,有了Arrow之后,它的一部分功能就相当于所有系统的适配器了。
\\
- 列式存储\
我们假设数据表有session_id、timestamp、source_ip等三个字段,在行式存储的时候,按照每一行形式包含3个字段,而多行之间是互相分开的,没有关联,而到了列式存储概念,我们按照每一列对数据进行聚集,例如session_id包含了“1331246660”等4个值。
\\
从上面这张摘录自Arrow官网的图可以看出,传统的内存数据格式以每一行作为各个字段的分布,相同字段没有被集中在一起,造成了计算时的不必要浪费。通过列式存储格式约束,可以将相同字段集中排列在一起。而官网也给出了一条SQL语句,代表使用SQL语句很容易查询得到数据。
\\- SIMD指令\
即单指令流多数据流(SingleInstruction Multiple Data),是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元。
\\技术深入
\\需要明确的是,Apache Arrow不是一个引擎,也不是一个存储系统,它是用来处理分层的列式内存数据的一系列格式和算法。它不是一个独立的软件,而是系统中用来加速数据分析的一个组件。很多开源项目都已经支持了Arrow,而且其他商业化的项目也有这个趋势。对于已经支持Arrow的项目来说,这些项目不再需要序列化和反序列化各种数据,从而以极小的成本来共享数据资源,对于同一集群下的系统则完全不需要进行任何的数据格式转换。
\\对于Apache Arrow的期望:
\\- 列式存储:大数据系统几乎都是列式存储的,类似于Apache Parquet这样的列式数据存储技术自从诞生起就是大家的期望。\\t
- 内存式:SAP HANA是第一个利用内存加速分析流程的组件,随着Apache Spark的出现,进一步提升了利用内存加速流程的技术可能性落地。\\t
- 复杂数据和动态模式:当我们通过继承和内部数据结构呈现数据的时候,一开始有点麻烦,后来就有了JSON和基于文档的数据库。\
Arrow的列式存储有着O(1)的随机访问速度,并且可以进行高效的Cache,同时还允许SIMD指令的优化。由于很多大数据系统都是在JVM上运行的,Arrow对于Python和R的社区来说显得格外重要。
\\Apache Arrow是基于Apache Drill中的Value Vector来实现的,而使用Value Vector可以减少运算时重复访问数据带来的成本。
\\举个例子,有一个people数组:
\\\people=[\{\ name:’mary’,age:30,\ placed_lived:[\ {city:’Akron’,state:’OH’},\ {city:’Bath’,state:’OH’}\ ]\},\{\ name:’mary’,age:31,\ placed_lived:[\ {city:’Lodi’,state:’OH’},\ {city:’Ada’,state:’OH’}\{city:’Akron’,state:’OH’}\ ]\}\]\\\
其中,对于people.places_lived.city,在Arrow中是这样存储的:
\\
这种存储方式有O(1)的访问速度,可以有效地缓存,而且,在Value Vector中的信息可以直接在不同的项目之间传递,不依赖于所使用的编程语言。
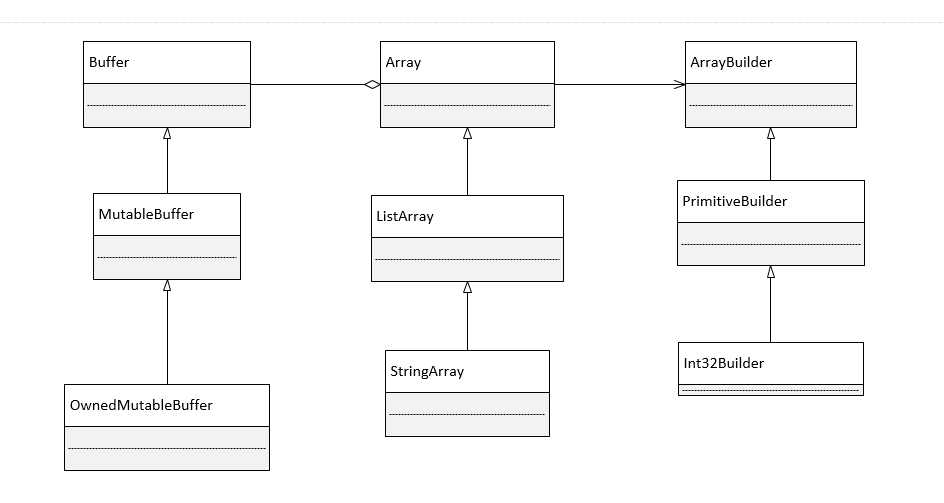
\\而从代码层面分析,Apache Arrow类的设计采用了设计模式里的建造者模式,封装了基础类Array、Buffer以及ArrayBuilder,具体类图如下图所示:
\\
从GC的角度来看,Arrow基于一种有规划的内存使用理念。传统的GC面对的程序数据是很多细粒度的、频繁诞生与消亡的对象。而Arrow的内存使用体现了基于较粗粒度的按需分配,有良好的线性关系,要处理的数据都是大块的,本身不具高频新生与删除的数据。(而这种数据特性刚好很切合我们的内存表所要处理的数据。)由于数据本身块头大,变化频率低,为进一步规划更稳健和高效的内存分配策略提供了可能。系统启动时需要预锁定一片区域;当删除数据时,瞬时归还系统,但会留存一块;几乎没有内存碎片。
\\总结
\\Apache Arrow之所以会流行,是因为它不针对特定产品,而是可以为大数据整个生态系统带来便利。有了Arrow作为标准数据交换格式,各个数据分析系统和应用之间的交互性有了全新的方式,我们不再需要把CPU资源花费在数据的序列化和反序列化上了,实现了不同系统之间数据的无缝连接,官网发表的文章显示,它的目标是提升数据之间的100倍交换速度,这样才能真正对数据分析流程进行加速。
\\作者介绍:周明耀,2004年毕业于浙江大学,工学硕士。13年软件研发经验,近10年技术团队管理经验,4年分布式计算、大数据技术经验。著有《大话Java性能优化》、《深入理解JVM\u0026amp;G1 GC》、《技术领导力-码农如何才能带团队》。个人微信号michael_tec,个人公众号“麦克叔叔每晚10点说”。
\\感谢蔡芳芳对本文的审校。















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









