







本章是继[第8章]讨论的延续,我们在那里讨论了一些多进程和多线程技术;本章将增强它们的使用。我们将引导你了解各种技术,同时聚焦于本章的主要内容——C++内存模型。但为了讨论这一点,你首先将简要检视通过智能指针和可选对象实现的内存鲁棒性。我们稍后将使用它们来实现懒惰初始化和安全地处理共享内存区域。接下来是对高缓存友好性代码的改进内存访问分析。你将了解何时以及为什么使用多线程执行可能是一个陷阱,即使你在软件设计中做得一切都是正确的。
本章为你提供了拓宽对同步原语理解的机会。在学习条件变量时,你还将理解读写锁的好处。我们将使用C++20中的范围来以不同的方式可视化相同的共享数据。将这些机制一个接一个地结合起来,我们将以最大的话题——指令排序结束我们的分析。通过C++的内存排序,你将了解正确原子例程设置的重要性。自旋锁的实现将被用来在最后总结所有技术。
在本章中,我们将涵盖以下主要话题:
- 了解C++中的智能指针和可选项
- 学习C++中的条件变量、读写锁和范围
- 讨论多处理器系统——缓存局部性和缓存友好性
- 通过自旋锁实现重新审视C++内存模型中的共享资源
技术要求
为了运行代码示例,读者必须准备以下内容:
-
能够编译和执行C++20的基于Linux的系统(例如,Linux Mint 21)
-
GCC12.2编译器:
https://gcc.gnu.org/git/gcc.git gcc-source
- 使用
-std=c++2a、-lpthread和-lrt标志
- 使用
-
对于所有示例,你也可以选择使用https://godbolt.org/。
了解C++中的智能指针和可选项
在[第4章]中,我们回顾了C++基础,以便在讨论语言时处于同一页面。被认为是必须的一个工具就是智能指针。通过这些,我们能够提高程序的安全性,并更有效地管理我们的资源。正如前几章所讨论的,这是我们作为系统程序员的主要目标之一。还记得RAII原则吗?智能指针基于此,帮助C++开发人员减少甚至消除内存泄漏。它们还可以帮助你稍后在本章中看到的共享内存管理。
内存泄漏出现在我们分配内存但未能释放它时。这不仅可能是因为我们忘记调用对象的析构函数,还可能是因为我们丢失了指向该内存地址的指针。除此之外,还有野指针和悬挂指针需要考虑。前者发生在指针存在于栈上,但从未与真实对象(或地址)关联。后者发生在我们释放了对象所使用的内存,但指针的值仍然悬挂在那里,我们引用了已被删除的对象。总的来说,这些错误不仅可能导致内存碎片,还可能导致缓冲区溢出漏洞。
这些问题很难捕捉和复现,尤其是在大型系统上。系统程序员和软件集成工程师使用诸如地址消毒器、静态和动态代码分析器以及分析器等工具,依靠它们来预测未来的缺陷。但这些工具昂贵且消耗大量计算能力,因此我们不能一直依靠它们来提高代码质量。那么,我们能做什么呢?答案很简单——使用智能指针。
注
你可以在标准中阅读更多关于智能指针的主题,或参考https://en.cppreference.com/w/cpp/memory。
通过智能指针回顾RAII
即使是经验丰富的C++开发者在内存释放的正确时机上也会犯错误。其他语言使用垃圾收集技术来处理内存管理,但重要的是要提到那里也会发生内存泄漏。为检测代码中这些情况实现了多种算法,但并不总是成功。例如,对象之间的循环依赖有时难以解决——应该删除相互指向的两个对象,还是应该保留它们分配?如果它们保持分配,这是否构成泄漏?因此,我们有责任谨慎地使用内存。此外,垃圾收集器工作以释放内存,但不管理打开的文件、网络连接、锁等。为此,C++实现了自己的控制工具——包装类覆盖指针,帮助我们在正确的时间释放内存,通常是对象超出范围时(对象生命周期已在[第4章]中讨论)。智能指针在内存和性能方面都是高效的,意味着它们的成本(多)不超过原始指针。同时,它们在内存管理方面给我们带来了鲁棒性。C++标准中有三种智能指针:
unique_ptr:这是只允许一个所有者的指针。它不能被复制或共享,但所有权可以被转移。它的大小是一个原始指针。当它超出范围时,它会被销毁,对象被释放。shared_ptr:这可以有多个所有者,并在所有所有者放弃所有权或全部超出范围时被销毁。它使用一个引用计数器来指向对象的指针。它的大小是两个原始指针 - 一个用于分配的对象,一个用于包含引用计数的共享控制块。weak_ptr:这为一个或多个共享指针拥有的对象提供访问,但不计数引用。它用于观察对象,而不是管理其生命周期。它由两个指针组成 - 一个用于控制块,一个用于指向它构造的共享指针。通过weak_ptr,你可以了解底层的shared_ptr是否仍然有效 - 只需调用expired()方法
struct Book {
string_view title;
Book(string_view p_title) : title(p_title) {
cout << "Constructor for: " << title << endl; }
~Book() {cout << "Destructor for: " << title << endl;}};
int main() {
unique_ptr<Book> book1 =
make_unique<Book>("Jaws");
unique_ptr<Book> book1_new;
book1_new = move(book1); // {1}
cout << book1_new->title << endl;
shared_ptr<Book> book2 =
make_unique<Book>("Dune");
shared_ptr<Book> book2_new;
book2_new = book2; // {2}
cout << book2->title <<" "<< book2_new->title << endl;
cout << book2.use_count() << endl;
可以看到,在创建Book对象时,我们使用了堆,因为调用了new。但由于智能指针处理了内存管理,我们不需要显式地调用析构函数:
Constructor for: Jaws
Jaws
Constructor for: Dune
Dune Dune
2
Destructor for: Dune
Destructor for: Jaws
首先,我们将book1对象的所有权移动到另一个unique_ptr —— book1_new(标记{1})。通过第二个unique_ptr打印出其title,因为第一个已经失效。对于另一个Book对象,我们执行了同样的操作,但是通过shared_ptr(标记{2})。这次,title变量可以通过两个指针访问。我们还打印了引用计数,并发现该对象有两个引用。
weak_ptr在系统编程中也有其有用的优势。你可以使用weak_ptr来检查指针的有效性。weak_ptr也能解决对象间循环依赖的问题。让我们考虑一个双向链表的列表节点的例子。接下来的例子说明了weak_ptr的好处。这是一个提醒你不要自己实现这样的数据结构,尤其是当它们已经是C++标准的一部分时。
现在,让我们使用Book对象作为ListNode结构的内容:
struct ListNode {
Book data;
ListNode(string_view p_title) {
data.title = p_title;
cout << "Node created: " << data.title << endl;
}
我们还为前一个和后一个节点添加了两个成员变量,但其中一个将是weak_ptr。需要注意的是,在shared_ptr的控制块中不将weak_ptr引用计为引用。现在,我们既可以访问对象,也可以在每次释放时将引用计数到零:
~ListNode() {
cout << "Node destroyed: " << data.title
<< endl;
}
shared_ptr<ListNode> next;
weak_ptr<ListNode> prev;
};
int main() {
shared_ptr<ListNode> head =
make_shared<ListNode>("Dune");
head->next = make_shared<ListNode>("Jaws");
if (!head->next->prev.expired())
head->next->prev = head;
从输出中可以清楚地看到,所有对象都被成功移除:
Node created: Dune
Node created: Jaws
Node destroyed: Dune
Node destroyed: Jaws
weak_ptr在缓存实现中也很有用。想象一下 - 如果你失去了对一个对象的所有引用,你就会失去该对象;但使用智能指针时,它肯定会被销毁。所以,想象一下,最近访问的对象或更重要的对象通过shared_ptr在当前代码范围内保持。但是weak_ptr允许我们在同一范围内保留对一个对象的引用,以便稍后在同一范围内引用该对象。在这种情况下,我们会创建一个指向它的weak_ptr对象。但想象一下,与此同时,一些其他的代码范围通过shared_ptr持有对该对象的引用,从而保持它被分配。换句话说,我们知道这个对象,但不需要关心它的管理。因此,如果稍后仍然需要该对象,它是可访问的,但在不再需要时会被移除。下面的图表展示了左侧不正确使用shared_ptr的方式,以及右侧刚刚描述的实现方式:
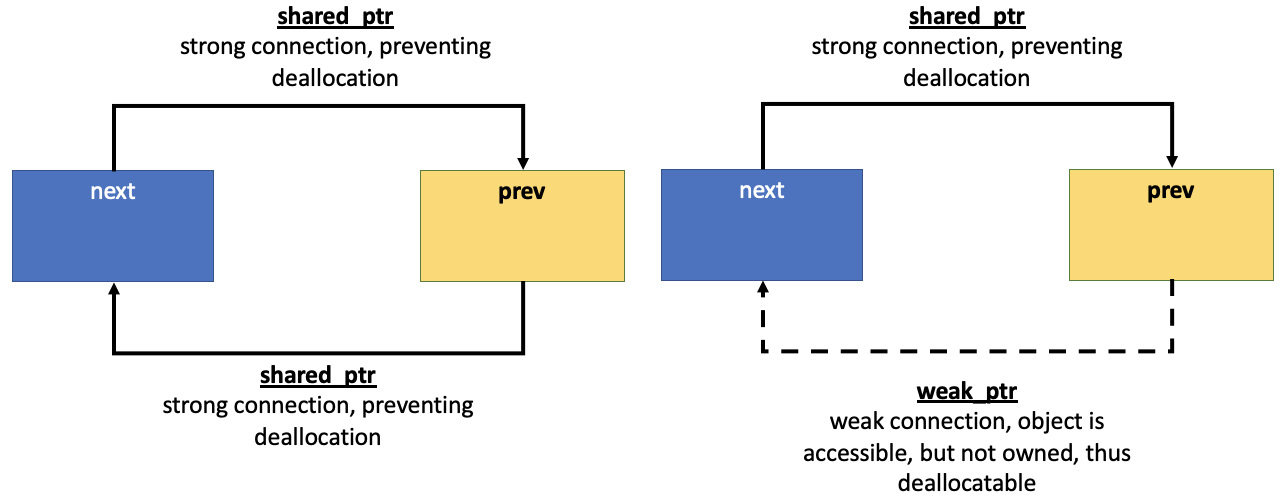
图9.1 - 通过shared_ptr产生循环依赖和通过weak_ptr解决循环依赖
在本节中,我们不会深入探讨其他设计解决方案,其中智能指针可能派上用场,但我们将在本章后面的系统编程领域回归这些内容。在下一节中,我们将讨论与weak_ptr相反的技术,即在内存中还未创建对象时保持对该对象的认识。
在C++中实现延迟初始化
你玩电子游戏吗?你有没有在玩游戏时在图形中的某处看到缺失的纹理?当你的角色靠近某个地方时,图形资源突然出现了吗?你在其他UI中也观察到过这种行为吗?如果你的答案大多是肯定的,那么你可能已经遇到了延迟初始化。不难理解,其目的是推迟对象的构建,直到真正需要它的时候。通过这样做,我们允许系统只分配所需的资源。我们还使用它来加速我们的代码,特别是在CPU负载高的时候运行,例如在系统启动时。我们避免了浪费CPU周期去创建直到(很久之后)才会用到的大型对象,而是释放CPU来处理其他请求。负面方面是,我们可能最终无法及时加载对象,正如你在视频游戏中可能观察到的。正如我们在[第2章]中讨论的那样,当程序加载时,内核以延迟方式分配虚拟内存——直到引用时才加载可执行代码的页面。
就像其他模式一样,延迟初始化不能解决所有问题。因此,系统程序员必须选择是否应用于给定应用程序的功能。通常,图形和网络存储资源的部分保持延迟初始化是首选,因为它们无论如何都是按需加载的。换句话说,用户不总是看到整个UI。因此,无需预先在内存中存储它。C++具有允许我们轻松实现这种方法的功能。我们在以下示例中呈现延迟初始化:
#include <iostream>
#include <chrono>
#include <optional>
#include <string_view>
#include <thread>
using namespace std;
using namespace std::literals::chrono_literals;
struct Settings {
Settings(string_view fileName) {
cout << "Loading settings: " << fileName << endl;
}
~Settings() {
cout << "Removing settings" << endl;
}
我们提出了一个Settings类,帮助我们模拟从磁盘加载和更新设置列表。注意我们是按值传递而不是按引用传递:
void setSetting(string_view setting,
string_view value) {
cout << "Set setting: " << setting
<< " to: " << value << endl;
}
};
这种技术由于减少了内存加载而节省了时间。在C++中,按值传递(或按复制传递)是默认的参数传递技术,数组除外。对于小类型(如int)来说,它是廉价和最优的。按引用传递是按值传递的替代方案,string_view对象的处理方式与int相同,使用比其他标准对象(如string)更廉价的复制构造函数。回到我们的例子,我们正在创建一个配置对象Config,它将包含设置文件(在现实世界场景中可能不止一个文件),并允许在该配置中更改设置。我们的main()方法模拟了应用程序的启动。Config对象将被构造,但设置文件只有在启动完成后、进程资源可用时才会加载:
struct Config {
optional<Settings> settings{};
Config() {
cout << "Config loaded..." << endl;
}
void changeSetting(string_view setting,
string_view value) {
if (!settings)
settings.emplace("settings.cfg");
settings->setSetting(setting, value);
}
};
int main() {
Config cfg;
cout << "Application startup..." << endl;
this_thread::sleep_for(10s);
cfg.changeSetting("Drive mode", "Sport");
cfg.changeSetting("Gear label", "PRNDL");
我们观察到文件在启动完成后加载,正如我们预期的:
Config loaded...
Application startup...
Loading settings: settings.cfg
Set setting: Drive mode to: Sport
Set setting: Gear label to: PRNDL
Removing settings
optional类模板设计用于在函数失败时返回无,在成功时返回有效结果。我们也可以使用它来处理构建成本高的对象。它还管理着一个可能在给定时间存在或不存在的值。它也是可读的,其意图清晰。如果一个optional对象包含一个值,该值保证作为optional对象的一部分分配,不会发生动态内存分配。因此,optional对象模型是对对象的预留,而不是指针。这是optional和智能指针之间的关键区别。虽然使用智能指针来处理大型和复杂的对象可能是一个更好的主意,但optional为你提供了在所有参数已知时在稍后时间点构造对象的机会,如果这些参数之前在执行中未知。它们两者都可以在实现延迟初始化时表现良好——这取决于你的偏好。
在本章后面,我们将回到智能指针及其在管理共享内存方面的可用性。但首先,我们将在下一节中介绍一些同步的有用机制。
Learning about condition variables, read-write locks, and ranges in C++
现在让我们开始讨论同步原语,其中一个基本的是条件变量。其目的是允许多个线程保持阻塞,直到发生事件(即满足条件)。条件变量的实现需要一个额外的布尔变量来指示条件是否满足,一个互斥锁来序列化对布尔变量的访问,以及条件变量本身。
POSIX为多种用例提供了接口。还记得[第7章]中的生产者-消费者示例使用共享内存吗?因此,pthread_cond_timedwait()用于阻塞线程一段给定的时间。或者通过pthread_cond_wait()等待条件,并通过pthread_cond_signal()向一个线程发出信号,或者通过pthread_cond_broadcast()向所有线程发出信号。通常,在互斥锁的范围内定期检查条件:
...
pthread_cond_t condition_variable;
pthread_mutex_t condition_lock;
...
pthread_cond_init(&condition_variable, NULL);
...
void consume() {
pthread_mutex_lock(&condition_lock);
while (shared_res == 0)
pthread_cond_wait(&condition_variable,
&condition_lock);
// Consume from shared_res;
pthread_mutex_unlock(&condition_lock);
}
void produce() {
pthread_mutex_lock(&condition_lock);
if (shared_res == 0)
pthread_cond_signal(&condition_variable);
// Produce for shared_res;
pthread_mutex_unlock(&condition_lock);
}
pthread_mutex_unlock(&condition_lock);
...
pthread_cond_destroy(&condition_variable);
...
如果我们提升抽象级别,就像我们在[第7章]中所做的那样,C++为我们提供了相同技术的访问,但更简单、更安全地使用——我们受到RAII原则的保护。让我们检查以下C++代码片段:
...
#include <condition_variable>
mutex cv_mutex;
condition_variable cond_var;
...
void waiting() {
cout << "Waiting for work..." << endl;
unique_lock<mutex> lock(cv_mutex);
cond_var.wait(lock);
processing();
cout << "Work done." << endl;
}
void done() {
cout << "Shared resource ready." << endl;
cond_var.notify_one();
}
int main () {
jthread t1(waiting); jthread t2(done);
t1.join(); t2.join();
return 0;
}
输出如下:
Waiting for work...
Shared resource ready.
Processing shared resource.
Work done.
以这种形式,代码是不正确的。没有要检查的条件,共享资源本身也缺失。我们只是为接下来的示例设置舞台,这是[第7章]所涵盖内容的延续。但请观察一个线程使用条件变量通知另一个线程资源已准备好被消费(标记{4}),而第一个线程正在等待(标记{2})。正如你所看到的,我们依赖互斥锁来锁定范围内的共享资源(标记{1}),并通过它触发条件变量以继续工作(标记{2}和{3})。因此,CPU不会忙于等待,因为没有无休止的循环来等待条件,释放CPU让其他进程和线程访问。但是线程保持阻塞,因为条件变量的wait()方法解锁了互斥锁,并且线程原子地被置于休眠状态。当线程被信号唤醒时,它将恢复并重新获得互斥锁。这并不总是有用的,正如你将在下一节中看到的。
通过条件变量实现协作取消
一个重要的备注是,条件变量应该只在有条件并通过谓词的情况下等待。如果不是这样,等待它的线程将保持阻塞。还记得[第6章]中的线程取消示例吗?我们使用了jthread并通过stop_token类和stop_requested方法在线程之间发送停止通知。这种机制被称为协作取消。jthread技术被认为是安全且易于应用的,但它可能不适合您的软件设计,或者可能不够。取消线程可能直接与等待事件相关。在这种情况下,条件变量可能派上用场,因为不需要无休止的循环或轮询。重访[第6章]中的线程取消示例,我们有以下内容:
while (!token.stop_requested())
我们在进行轮询,因为线程工作人员定期检查是否已发送取消,同时进行其他事情。但如果取消是我们唯一关心的事情,那么我们可以简单地订阅取消事件,使用stop_requested函数,而不是轮询。C++20允许我们定义一个stop_callback函数,因此结合条件变量和get_stop_token(),我们可以在没有无休止循环的情况下进行协作取消:
#include <condition_variable>
#include <iostream>
#include <mutex>
#include <thread>
#include <syncstream>
using namespace std;
int main() {
osyncstream{cout} << "Main thread id: "
<< this_thread::get_id()
<< endl;
那么,让我们完成上一节示例中的工作,并在工作线程中为条件变量添加谓词:
jthread worker{[](stop_token token) {
mutex mutex;
unique_lock lock(mutex);
condition_variable_any().wait(lock, token,
[&token] { return token.stop_requested(); });
osyncstream{cout} << "Thread with id "
<< this_thread::get_id()
<< " is currently working."
<< endl;
}};
stop_callback callback(worker.get_stop_token(), [] {
osyncstream{cout} <<"Stop callback executed by thread:"
<< this_thread::get_id()
<< endl;
});
auto stopper_func = [&worker] {
if (worker.request_stop())
osyncstream{cout} << "Stop request executed by
thread: "
<< this_thread::get_id()
<< endl;
};
jthread stopper(stopper_func);
stopper.join(); }
输出如下:
Main thread id: 140323902175040
Stop callback executed by thread: 140323893778176
Stop request executed by thread: 140323893778176
Thread with id 140323902170880 is currently working.
现在,让我们看看如何将智能指针、条件变量和共享内存结合起来。
结合智能指针、条件变量和共享内存
我们已经在[第7章]中探索了共享内存的概念。让我们利用本章前面部分的知识,通过一些C++技术来增强代码的安全性。我们将场景简化了一点。
我们使用unique_ptr参数来提供特定的回收器:
template<typename T>
struct mmap_deallocator {
size_t m_size;
mmap_deallocator(size_t size) : m_size{size} {}
void operator()(T *ptr) const {
munmap(ptr, m_size);
}
};
我们依赖以下内容:
unique_ptr<T, mmap_deallocator<T>>(obj, del);
正如你看到的,我们也使用模板以提供在共享内存中存储任何类型对象的可能性。在堆中保持具有大型层次结构和成员的复杂对象很容易,但存储和访问它们的数据并不简单。多个进程将能够访问共享内存中的这些对象,但这些进程能够引用指针后面的内存吗?如果被引用的内存不在那里或不在共享的虚拟地址空间中,则会抛出内存访问违规异常。因此,要小心处理这个问题。
我们继续下一个示例。使用了已知的条件变量技术,但这次我们添加了一个真正的谓词来等待:
mutex cv_mutex;
condition_variable cond_var;
bool work_done = false;
我们的producer()方法以熟悉的方式创建和映射共享内存。但这次,代替执行系统调用来写入,共享资源直接在共享内存中创建(标记{1})。这种技术被称为就地构造。内存预先分配,然后在该内存中构造对象。标准的new操作符将这两个操作结合在一起。此外,对象本身被unique_ptr对象包装,且有相应的回收器。一旦离开作用域,该内存部分将通过munmap()方法被重置。条件变量用于向消费者发信号,表明数据已准备好:
template<typename T, typename N>
auto producer(T buffer, N size) {
unique_lock<mutex> lock(cv_mutex);
cond_var.wait(lock, [] { return work_done == false; });
if (int fd =
shm_open(SHM_ID, O_CREAT | O_RDWR, 0644);
fd != -1) {
ftruncate(fd, size);
shm区域被创建并设置大小。现在,让我们使用它来存储数据:
if (auto ptr =
mmap(0, size,
PROT_RW, MAP_SHARED,
fd, 0); ptr != MAP_FAILED) {
auto obj = new (ptr) T(buffer);
auto del = mmap_deallocator<T>(size);
work_done = true;
lock.unlock();
cond_var.notify_one();
return unique_ptr<T,
mmap_deallocator<T>>(obj, del);
}
else {
const auto ecode{ make_error_code(errc{errno}) };
…
}
}
else {
const auto ecode{ make_error_code(errc{errno}) };
...
throw exception;
}
// Some shm function failed.
throw bad_alloc();
}
消费者的实现类似,只是等待以下内容:
cond_var.wait(lock, []{ return work_done == true; });
最后,启动并加入了两个线程作为生产者和消费者,提供以下输出:
Sending: This is a testing message!
Receiving: This is a testing message!
当然,示例可以更加复杂,增加周期性生产和消费。我们鼓励你尝试它,只是使用另一种类型的缓冲区——正如你可能记得的,string_view对象是常量。确保正确实现并调用回收器。它用于使代码更安全,并排除内存泄漏的可能性。
正如你可能在本书的工作中观察到的,我们经常想要访问一个对象只是为了读取它,而不修改其数据。在这种情况下,我们不需要全面锁定,而是需要某种能够区分仅读取数据或修改数据的技术。这种技术是读写锁,我们将在下一节中介绍。
使用C++实现读写锁和范围
POSIX直接提供了读写锁机制,而C++则在不同的名称下隐藏了它 —— shared_mutex 和 shared_timed_mutex。让我们看看它在POSIX中的传统工作方式。我们有一个带有预期的POSIX接口的读写锁对象(rwlock),其中一个线程可以在其上持有多个并发的读锁。目标是允许多个读者访问数据,直到一个线程决定修改它。该线程通过写锁锁定资源。大多数实现更倾向于写锁而不是读锁,以避免写饥饿。在涉及数据竞争的情况下,这种行为并不必要,但它确实会造成最小的应用执行瓶颈。
尤其是在处理大规模系统的数据读取器时,例如,多个只读UI。C++的功能再次为我们提供了一个简单而强大的工具来完成这项任务。因此,我们不会花时间研究POSIX的示例。如果你感兴趣,建议你自己去看看,从https://linux.die.net/man/3/pthread_rwlock_rdlock开始。
继续C++示例,让我们考虑以下场景 —— 少数线程想要修改共享资源 —— 一个数字向量 —— 而更多的线程想要可视化数据。我们想要使用的是shared_timed_mutex。它允许两个访问级别:独占,只有一个线程可以拥有互斥锁;和共享,多个线程共享互斥锁的所有权。
重要提示
请记住,shared_timed_mutex和shared_mutex类型比简单的mutex更重,尽管在某些平台上,shared_mutex被认为比shared_timed_mutex更高效。当你的读操作真的非常耗资源、慢且频繁时,你才会期望使用它们。对于短暂操作突发,最好还是坚持使用互斥锁。你需要针对你的系统具体测量资源使用情况,以决定选择哪一个。
下面的示例展示了shared_mutex的使用。我们还将利用这个机会来介绍C++中的ranges库。这个功能随C++20一起出现,并与string_views一起提供了一种敏捷的方式来可视化、过滤、转换和切片C++容器等。通过这个例子,你将学习一些与ranges库相关的有用技术,这些技术将与代码一起解释。
让我们有一个带有共享资源的Book结构 —— vector的书。我们将使用shared_mutex来处理读写锁定:
struct Book {
string_view title;
string_view author;
uint32_t year;
};
shared_mutex shresMutex;
vector<Book> shared_data = {{"Harry Potter", ...
我们实现了将书添加到共享资源中的方法,并在方法名前加上wr_前缀,以区分其角色与其他方法的不同。我们还在资源上执行写锁(标记{1}):
void wr_addNewBook(string_view title,
string_view author,
uint32_t year) {
lock_guard<shared_mutex> writerLock(shresMutex); // {1}
osyncstream{cout} << "Add new book: " << title << endl;
shared_data.emplace_back(Book {title, author, year});
this_thread::sleep_for(500ms);
}
现在,我们开始实现多个读取例程的实现。它们以rd_前缀标记,每个都执行一个读锁,意味着资源将同时可用于多个读者:
void rd_applyYearFilter(uint32_t yearKey) {
auto year_filter =
[yearKey](const auto& book)
{ return book.year < yearKey; };
shared_lock<shared_mutex> readerLock(shresMutex);
osyncstream{cout}
<< "Apply year filter: " << endl; // {2}
for (const auto &book : shared_data |
views::filter(year_filter))
osyncstream{cout} << book.title << endl;
}
观察标记{2}后的for循环。它不仅遍历共享资源,而且通过管道(|)字符筛选它的一部分,这类似于在[第3章]中介绍的管道和grep,只是这里不是管道。我们通过管道操作符创建了一个范围视图,从而为迭代提供额外的逻辑。换句话说,我们操纵了对容器的视图。这种方法不仅适用于vectors,还适用于其他C++可迭代对象。为什么?范围用于扩展和泛化带有迭代器的算法,使代码变得更紧凑且更不易出错。
这里的范围意图也很容易看出来。此外,范围视图是一个轻量级对象,类似于string_view。它代表一个可迭代序列 —— 范围本身,在容器的迭代器之上创建。它基于好奇重复模板模式。通过范围接口,我们可以改变容器的呈现方式,以给定方式呈现其值,过滤值,拆分和组合序列,呈现唯一元素,洗牌元素,通过值滑动窗口等等。所有这些都是通过已经实现的范围适配器的简单语法完成的。在我们的示例中,rd_applyYearFilter有一个for循环,其中过滤掉早于yearKey的书籍。我们还可以以相反顺序打印共享资源的元素:
void rd_Reversed() {
for (const auto &book : views::reverse(shared_data))
osyncstream{cout} << book.title << endl; ...
我们甚至可以组合视图,如下所示:
for (const auto &book :
views::reverse(shared_data) |
views::filter([nameSizeKey](Book book)
{return book.author.size() < nameSizeKey;}))}
上一个片段通过相反的顺序迭代元素,但它还过滤掉那些作者名字长度超过给定值的书籍。接下来的片段展示了如何简单地在迭代期间放弃容器的一部分:
for (const auto &book :
ranges::drop_view(shared_data, dropKey))
osyncstream{cout} << book.title << endl;
如果这太泛化了,你可以改为使用特定的子范围,它将创建一个range对象。range对象可以像任何其他对象一样使用,如下所示:
auto const sub_res =
ranges::subrange(shared_data.begin(),
shared_data.begin()+5);
for (const auto& book: sub_res){
osyncstream{cout}
<< book.title << " " << book.author
<< " " << book.year << endl;
在完成所有这些后,我们创建线程以并发方式执行所有这些操作,并观察读写锁如何管理它们。运行示例将根据线程的调度产生不同的输出顺序:
thread yearFilter1(
[]{ rd_applyYearFilter(1990); });
thread reversed(
[]{ rd_Reversed(); });
thread reversed_and_filtered(
[]{ rd_ReversedFilteredByAuthorNameSize(8); });
thread addBook1(
[]{ wr_addNewBook("Dune", "Herbert", 1965); });
thread dropFirstElements(
[]{ rd_dropFirstN(1); });
thread addBook2(
[]{ wr_addNewBook("Jaws", "Benchley", 1974); });
thread yearFilter2(
[]{ rd_applyYearFilter(1970); });
输出与描述的范围视图相关(以下内容已稍作调整,以便更易阅读):
Apply reversed order:
It
East of Eden
Harry Potter
Drop first N elements:
East of Eden
It
Apply reversed order and filter by author name size:
It
Harry Potter
Apply year filter:
East of Eden
It
Add new book: Dune
Apply year filter:
East of Eden
Dune
Add new book: Jaws
Print subranged books in main thread:
East of Eden Steinbeck 1952
It King 1986
现在,你已学习了另一种技术组合,可以用它来扩展一个系统,让多个线程处理展示任务。现在让我们退后一步,讨论由并发执行引起的可能陷阱,这些陷阱与数据竞争直接相关。我们继续讨论对缓存友好的代码。
讨论多处理器系统 - C++中的缓存局部性和缓存友好性
你可能还记得[第2章],我们讨论了多线程和多核处理器。相应的计算单元被视为处理器。我们还解释了从NVM(硬盘)到处理器的指令传输,通过这个过程,我们解释了进程和软件线程的创建。
我们希望我们的代码表现得尽可能高效。让代码高效运行的最重要方面是选择合适的算法和数据结构。稍加思考,你就可以尽可能多地利用每一个CPU周期。算法误用的最常见例子之一是使用冒泡排序对大型无序数组进行排序。因此,确保了解你的算法和数据结构 - 结合本节及以后的知识,这将使你成为一个非常强大的开发者。
正如你已经知道的,我们离RAM越远,越接近处理器寄存器,操作就越快,内存容量就越小。每次处理器从RAM加载数据到缓存时,它要么就坐等数据出现,要么执行其他无关任务。因此,从当前任务的角度来看,CPU周期被浪费了。当然,达到100%的CPU利用率可能是不可能的,但我们至少应该意识到它何时在做无谓的工作。所有这些在目前看来可能毫无意义,但如果我们不小心,并发系统将会受到影响。
C++语言提供了访问多种工具的能力,以进一步提高性能,包括通过硬件指令的预取机制和分支预测优化。即使不做任何特别的事情,现代编译器和CPU在这些技术上也做得很好。但是,通过提供正确的提示、选项和指令,我们可以进一步提高这些性能。了解缓存中的数据也是个好主意,以帮助减少访问它时所需的时间。请记住,缓存只是一种用于数据和指令的快速临时存储。所以,当我们以良好的方式对待缓存时,我们可以利用C++的特性,这被称为对缓存友好的代码。需要注意的一个重要事项是,这个陈述的反面——误用C++特性将导致缓存性能不佳,或至少不是最佳性能。你可能已经猜到,这与系统的规模和对快速数据访问的需求有关。让我们在下一节进一步讨论这个问题。
通过对缓存友好的代码考虑缓存局部性
我们已经提到了对缓存友好的代码,但这到底意味着什么?首先,你需要意识到缓存局部性。这意味着我们的第一个目标是使频繁使用的数据易于访问,从而使过程运行得更快。第二个目标是只在内存中存储我们需要存储的东西。让我们保持分配的规模小。例如,如果你需要存储一些骰子的值(1-6),你不需要无符号的长长整型。这些值可以适合无符号的int或甚至无符号的char。
结果,缓存已成为几乎每个系统的一个主要方面。早些时候在书中我们提到,较慢的硬件,例如硬盘,有时会有自己的缓存内存,以减少访问频繁打开的文件所需的时间。操作系统可以缓存频繁使用的数据,例如文件,作为虚拟地址空间的块,从而进一步提高性能。这也被称为时间局部性。
考虑以下场景:第一次在缓存中找不到数据时,这被称为缓存未命中。然后它在RAM中被查找,被找到,并作为一个或多个缓存块或缓存行加载到缓存中。之后,如果这些数据随后多次被请求并且仍在缓存中被找到,被称为缓存命中,它将保留在缓存中并保证更快的访问,至少比第一次缓存未命中更快。你可以在下面的图表中观察到这一点:
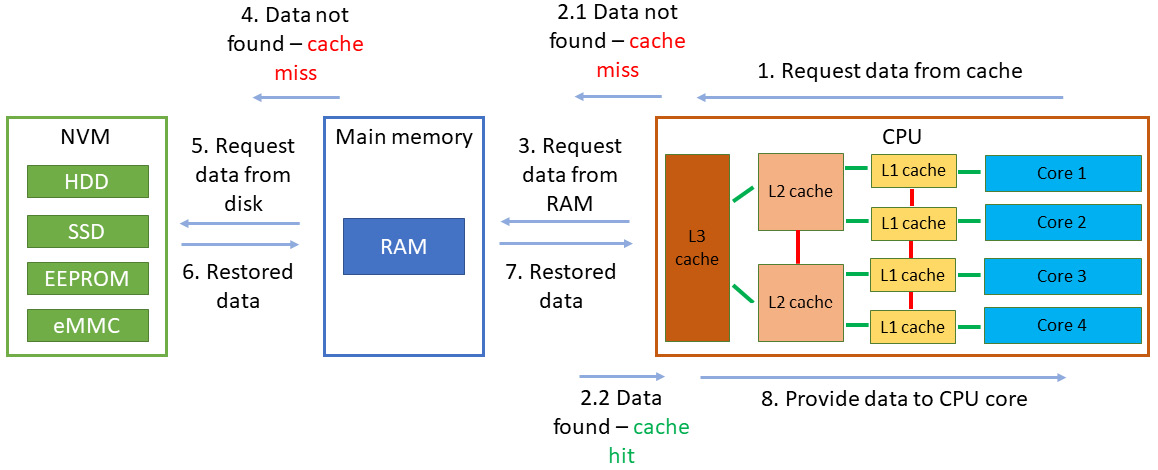
图9.2 - 硬件层面上时间局部性的表示
正如我们之前提到的预取机制,一个已知事实是,一个对象有多次缓存命中意味着其周围的数据可能也会很快被引用。这导致处理器请求或预取来自RAM的附加附近数据,并预先加载它,所以当最终需要时,它将在缓存中。这就导致了空间局部性,意味着访问附近的内存,并从缓存是按块进行的这一事实中受益,这些块被称为缓存行,因此为单次传输付费并使用几个字节的内存。预取技术假设代码已经具有空间局部性以提高性能。
这两个局部性原则都是基于假设的。但代码分支需要良好的设计。分支树越简单,就越容易预测。再次强调,你需要仔细考虑将要使用的数据结构和算法。你还需要瞄准连续的内存访问,并将代码简化为简单的循环和小函数;例如,从使用链表切换到数组或矩阵。对于小型对象,std::vector容器仍然是最佳选择。此外,我们理想地寻求一个可以适合一个缓存行的数据结构对象 - 但有时这是不可能的,因为应用程序的要求。
我们的过程应该访问连续的数据块,其中每个块的大小为一个缓存行(通常为64字节,但取决于系统)。但如果我们想进行并行评估,那么最好是每个CPU核心(处理器)处理与其他核心数据不同的缓存行中的数据。如果不这样做,缓存硬件将不得不在核心之间来回移动数据,CPU将再次浪费时间在无意义的工作上,性能将变差,而不是改善。这个术语被称为错误共享,我们现在将在下一节中看看它。
错误共享初探
通常,小块数据会被放在一个缓存行中,除非程序员另有指示,正如我们将在接下来的例子中看到的。这是处理器为了保持低延迟而采取的方式——它们一次为每个核心处理一个缓存行。即使它没有满,缓存行的大小也会被分配为CPU能够处理的最小可能块。正如之前提到的,如果该缓存行中的数据被两个或更多线程独立请求,那么这将减慢多线程执行的速度。
处理错误共享的影响意味着获得可预测性。就像代码分支可以预测一样,系统程序员也可以预测一个对象是否为缓存行大小,因此每个独立的对象都可以驻留在自己的内存块中。此外,所有计算都可以在本地范围内发生,共享数据的修改发生在给定程序的末尾。当然,这种活动将在某个时候导致资源的浪费,但这是一个设计和偏好的问题。如今,我们也可以使用编译器优化来改善这种可预测性和性能,但我们不应该总是依赖这一点。让我们首先检查我们的缓存行大小:
#include <iostream>
#include <new>
using std::hardware_destructive_interference_size;
int main() {
std::cout << "L1 Cache Line size: "
<< hardware_destructive_interference_size
<< " bytes";
return 0;
}
预期的输出如下:
L1 Cache Line size: 64 bytes
现在我们知道如何获取缓存行的大小,我们可以调整我们的对象,使其不发生错误共享。在[第7章]中,我们使用了std::atomic来保证对共享资源的单一修改,但我们也强调这不是完整的情况。让我们用三个原子变量丰富前面的示例:
cout << "L1 Cache Line size: "
<< hardware_constructive_interference_size
<< " bytes" << endl;
atomic<uint32_t> a_var1;
atomic<uint32_t> a_var2;
atomic<uint32_t> a_var3;
打印出地址得到以下结果:
cout << "The atomic var size is: " << sizeof(a_var1)
<< " and its address are: \n"
<< &a_var1 << endl
<< &a_var2 << endl
<< &a_var3 << endl;
...
输出结果如下:
L1 Cache Line size: 64 bytes
The atomic var size is: 4 and the addresses are:
0x7ffeb0a11c7c
0x7ffeb0a11c78
0x7ffeb0a11c74
这意味着即使我们有原子变量,它们也可以高概率地适合单个缓存行,尽管这取决于系统。所以,即使它们负责处理不同的共享资源,硬件线程(或核心)也无法由于缓存硬件中的来回活动而并行写入。为了保持缓存一致,CPU实现了不同的缓存一致性协议,包括MESI、MESIF和MOESI。不过,它们都不允许多个核心并行修改一个缓存行。缓存行只能被一个核心占用。幸运的是,C++20提供了atomic_ref<T>::required_alignment,允许程序员根据当前缓存行大小对原子进行对齐,从而将它们保持在适当的距离。让我们将其应用于所有原子,如下所示:
alignas(hardware_destructive_interference_size)
atomic<uint32_t> a_var1;
输出结果如下:
L1 Cache Line size: 64 bytes
The atomic var size is: 4 and the addresses are:
0x7ffc3ac0af40
0x7ffc3ac0af00
0x7ffc3ac0aec0
在前面的片段中,你可以看到地址的差异符合预期,变量对齐得很好,这一直是系统程序员的责任。现在,让我们应用你可能还记得的[第7章]中的increment()方法:
void increment(std::atomic<uint32_t>& shared_res) {
for(int I = 0; i < 100000; ++i) {shared_res++;}
}
我们增加了一个原子资源,正如[第8章]中所述,我们知道如何测量程序的持续时间。因此,我们可以分析以下四种情况的性能。一个备注——如果你愿意,你可以玩弄编译器的优化级别来发现以下值的差异,因为我们没有使用任何优化标志。我们的情况如下:
- 单线程应用程序,调用
increment()3次,对原子变量进行300,000次增量,耗时2,744微秒 - 直接共享一个原子变量,由3个线程并行增量100,000次,耗时5,796微秒
- 三个未对齐的原子变量的错误共享,由3个线程并行增量100,000次,耗时3,545微秒
- 三个对齐的原子变量的无共享,由3个线程并行增量100,000次,耗时1,044微秒
由于我们没有使用基准测试工具,我们无法测量缓存未命中或命中的次数。我们只是这样做:
...
auto start = chrono::steady_clock::now();
alignas(hardware_destructive_interference_size)
atomic<uint32_t> a_var1 = 0;
alignas(hardware_destructive_interference_size)
atomic<uint32_t> a_var2 = 0;
alignas(hardware_destructive_interference_size)
atomic<uint32_t> a_var3 = 0;
jthread t1([&]() {increment(a_var1);});
jthread t2([&]() {increment(a_var2);});
jthread t3([&]() {increment(a_var3);});
t1.join();
t2.join();
t3.join();
auto end = chrono::steady_clock::now();
...
无共享工作在以下图表中展示:
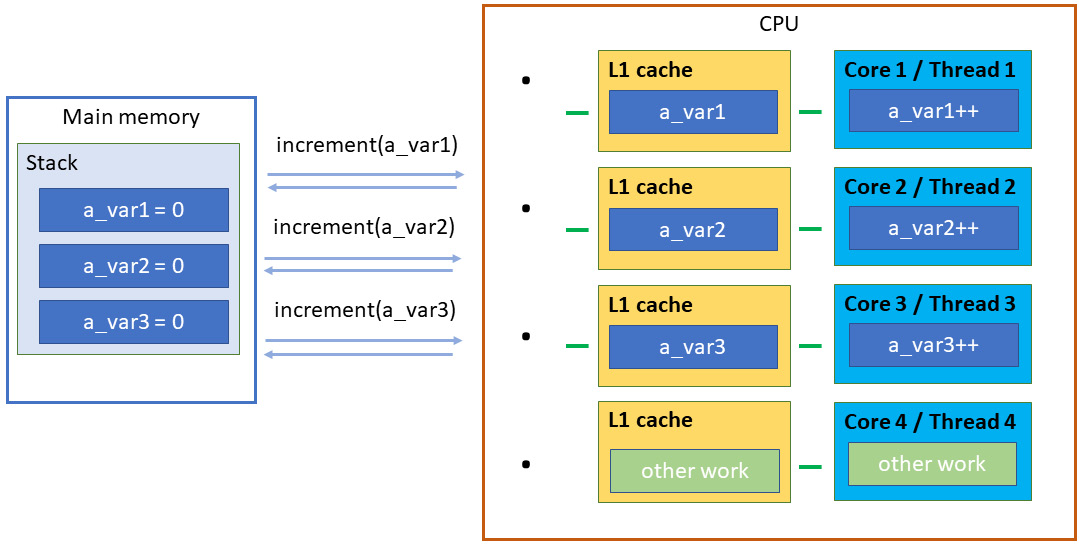
图9.3 - 多核/线程上数据的无共享(正确共享)表示
重要提示
显然,我们要么在并行修改原子资源之前对其进行对齐,要么对小程序使用单线程应用程序。时间度量可能因系统和编译器优化标志而异。请记住,当你充分利用硬件时,这些速度提升是很棒的,但过分深入细节可能也会导致代码复杂、调试困难并浪费维护时间。这是一种平衡行为。
在多线程中发生错误共享,可以通过将共享对象适应到一个缓存行中来修复。但如果对象的大小超过一个缓存行会发生什么呢?
C++中大于缓存行的资源共享
这里的分析相对简单,因为它不太依赖于语言。表示大型数据结构的大型对象只是……大。它们不适合单个缓存行,因此本质上不是缓存友好的。数据导向设计处理了这个问题。例如,你可以考虑使用更小的对象或仅共享它们的小部分进行并行工作。此外,考虑算法优化也是有益的。使它们线性化导致更好的分支预测。这意味着让条件语句依赖于可预测的数据,而不是随机数据。复杂的条件语句可以用算术解决方案和模板替换,或者以不同的方式链接,使得CPU更容易预测哪个分支出现的概率更高。这样的操作,再次,可能导致代码难以阅读和复杂的调试,所以只有在代码不够快以满足你的要求时才继续进行。
由于分支错误预测可能代价昂贵且难以发现,另一个建议是所谓的条件移动。它不是基于预测,而是基于数据。数据依赖包括条件为真和条件为假的情况。在条件性地将数据从一个寄存器移动到另一个寄存器的指令之后,第二个寄存器的内容依赖于它们之前的值和来自第一个寄存器的值。正如所提到的,良好设计的分支允许更好的性能。但数据依赖需要一个或两个CPU周期到达,有时使它们成为更安全的选择。一个可能的陷阱是当条件是这样的,从内存中取出的值没有分配给寄存器——那就只是无意义的等待。幸运的是,对于系统程序员来说,指令集中的条件移动指令通常在寄存器方面非常接近。
缓存不友好是在使用过于复杂的对象设计或将数据分散到内存中的设计模式时必须考虑的。这并不意味着你不应该考虑改进。如果你依赖C++,最简单、最有用的快速应用是在代码中使用连续容器,如std::array和std::vector。是的,向量可以被调整大小,但它仍然是缓存友好的,因为元素在内存中彼此相邻。当然,如果你不得不因为不断调整大小而重新分配向量,那么可能它不是你需要的数据结构。你可以考虑使用std::deque容器,它适用于在集合中间进行修改,或std::list作为替代品,这是一个链表,根本不是缓存友好的。
重要提示
根据系统的不同,连续内存块的多次重新分配(构建和销毁)可能导致内存碎片化。这可能是由于内存管理的软件算法、语言标准、操作系统、驱动程序、设备等原因造成的。直到发生之前很难预测它。内存分配开始失败可能需要相当长的不间断执行时间。在RAM中的自由内存块总和中可能有足够的空间,但没有一个单独的块足够大以容纳当前重新分配或创建的连续块。过度的碎片化可能导致性能差和甚至服务拒绝。
关于这个主题的最后一点是,有许多文章讨论了如何高效使用C++的算法和容器的最佳方法。它值得单独写一本书,大多数时候是非常特定于CPU的 - 至少当你达到绝对性能时。例如,条件移动直接导致汇编代码,我们在这里没有机会探索。话虽如此,当涉及到算法和数据结构时,对不同实际问题的解决方案的多样性是巨大的。
通过C++内存模型重新审视共享资源——通过自旋锁实现
我们在[第8章]中学习了原子操作。在本章中,你了解到原子变量在缓存中的放置同样至关重要。最初,原子和锁是因为多个线程想要进入同一个关键部分时的正确性而引入的。现在,我们的调查将继续深入一点。原子操作的最后一块拼图在这里。检查以下代码片段:
Thread 1: shrd_res++; T1: load value
T1: add 1
Thread 2: shrd_res++; T2: load value
T2: add 1
T2: store value
T1: store value
这是一个非原子操作的例子。即使我们使它成为原子的,我们仍然没有关于指令顺序的说明。到目前为止,我们使用同步原语指示CPU哪部分指令必须作为单元上下文处理。我们现在需要的是指导处理器关于这些指令的顺序。我们通过C++的memory_order来实现,这是C++标准内存模型的一部分。
在C++中引入memory_order类型
使用memory_order类型,我们指定原子和非原子内存访问如何在原子操作周围排序。上一节中片段的原子实现和本章早期使用读写锁的示例可能都会遇到同样的问题:两个原子操作作为一个整体并不是原子的。原子范围内的指令顺序将被保持,但在其周围则不会。这通常在CPU和编译器的优化技术后完成。所以,如果有许多读取线程,我们(和线程)期望观察到的变化顺序可能会有所不同。即使在单线程执行期间也可能出现这种效果,因为编译器可能会根据内存模型的允许重新排列指令。
注
我们鼓励你查看有关memory_order的完整信息:https://en.cppreference.com/w/cpp/atomic/memory_order。
重要备注是,C++中所有原子操作的默认行为应用顺序一致性排序。C++20中定义的内存顺序如下:
-
放松排序,标记如下:
memory_order_relaxed = memory_order::relaxed;这是最低限度的排序。它是最便宜的选择,除了当前操作的原子性外,不提供任何保证。这种操作的一个例子是
shared_ptr引用计数器的递增,因为它需要是原子的,但不需要排序。 -
发布-获取排序,标记如下:
memory_order_acquire = memory_order::acquire; memory_order_release = memory_order::release; memory_order_acq_rel = memory_order::acq_rel;在释放操作生效时,读写操作被阻止在原子区域之后重新排序。
acquire操作类似,但在原子区域之前禁止重新排序。第三种模型acq_rel是两者的结合。这种模型确实有助于创建读写锁,除了没有锁定。shared_ptr引用计数的递减通过这种技术完成,因为它需要与析构函数同步。 -
发布-消费排序,标记如下:
memory_order_consume = memory_order::consume;consume操作的要求至今仍在修订中。它的设计是像acquire操作一样工作,但只针对特定数据。这样,编译器在优化代码方面比acquire操作更灵活。显然,正确处理数据依赖关系会使代码更复杂,因此这种模型并不广泛使用。你可以在访问不常写入的并发数据结构时看到它——配置和设置、安全策略、防火墙规则或通过指针介导的发布-订阅应用;生产者通过指针发布,消费者可以通过该指针访问信息。 -
顺序一致性排序,标记如下:
memory_order_seq_cst = memory_order::seq_cst;这与放松顺序完全相反。原子区域内外的所有操作都遵循严格的顺序。没有指令可以越过原子操作强加的屏障。它被认为是最昂贵的模型,因为所有优化机会都丧失了。顺序一致性排序对于多生产者-多消费者应用程序非常有用,其中所有消费者必须按确切顺序观察所有生产者的行为。
自旋锁机制直接从内存顺序中受益的一个著名例子。我们将在下一节继续检查这一点。
在C++中为多处理器系统设计自旋锁
操作系统经常使用这种技术,因为它对于短期操作非常有效,包括能够避免重新调度和上下文切换。但对于持续时间较长的锁,有被操作系统调度程序中断的风险。自旋锁意味着给定线程要么获得锁,要么在循环中等待旋转——检查锁的可用性。我们在本章早些时候讨论了类似的忙等待示例,当我们介绍协作取消时。这里的风险是,长时间占用锁将使系统进入活锁状态,如[第2章]所述。持有锁的线程不会通过释放它来进一步发展,而其他线程在尝试获得锁时将保持旋转。C++非常适合实现自旋锁,因为可以详细配置原子操作。在低级编程中,这种方法也被称为测试并设置。以下是一个示例:
struct SpinLock {
atomic_bool state = false;
void lock() {
while (state.exchange(true,
std::memory_order_acquire){
while (state.load(std::memory_order_relaxed))
// Consider this_thread::yield()
// for excessive iterations, which
// go over a given threshold.
}
void unlock() noexcept {
state.store(false, std::memory_order_release); };
你可能想知道为什么我们不使用已知的同步技术。好吧,要记住的是,这里所有的内存顺序设置仅需一个CPU指令。它们既快速又简单,无论是软件还是硬件上。不过,你应该将它们的使用限制在非常短的时间内,因为这会阻止CPU为其他进程执行有用的工作。
原子布尔类型用于标记SpinLock的状态是锁定还是解锁。unlock()方法很简单——当关键部分被释放时,通过释放顺序将state成员设置(store()是原子的)为false值。所有后续的读/写操作必须以原子方式进行排序。lock()方法首先运行一个循环,尝试访问关键部分。exchange()方法将state设置为true,并返回之前的值false,从而中断循环。逻辑上,这与信号量的P(S)和V(S)功能非常相似。内部循环将执行繁忙等待场景,无顺序限制,且不产生缓存未命中。
重要提示
store()、load()和exchange()操作有memory_order要求和支持的顺序列表。使用额外和意外的顺序会导致未定义行为,并使CPU忙碌而不执行有用的工作。
自旋锁的高级版本是票据锁算法。与队列相同,以FIFO方式为线程提供票据。这样,它们进入关键部分的顺序被公平管理。与自旋锁相比,这里避免了饥饿。然而,这种机制不易扩展。首先,读取、测试和获取锁的指令数量更多,因为有更多管理顺序的指令。其次,一旦关键部分可以自由访问,所有线程必须将它们的上下文加载到缓存中,以确定它们是否被允许获取锁并进入关键部分。
C++在这里有优势,得益于其低延迟。
首先,我们实现TicketLock机制,提供必要的lock()和unlock()方法。我们使用两个辅助成员变量,serving和next。如你所见,它们被对齐以位于不同的缓存行中,以避免错误共享。lock()和unlock()方法的实现与SpinLock示例中的实现相同。此外,通过fetch_add()完成原子增量,允许锁生成票据。围绕它没有读/写操作,因此它以放松的顺序执行。与SpinLock只是将变量设置为false不同,unlock()方法以放松的方式加载票据号值,并将其存储为当前服务的线程:
struct TicketLock {
alignas(hardware_destructive_interference_size)
atomic_size_t serving;
alignas(hardware_destructive_interference_size)
atomic_size_t next;
TicketLock算法的锁定和解锁方法如下:
void lock() {
const auto ticket = next.fetch_add(1,
memory_order_relaxed);
while (serving.load(memory_order_acquire) !=
ticket);
}
void unlock() {
serving.fetch_add(1, memory_order_release);
}
};
现在,创建了一个类型为TicketLock的全局spinlock对象。我们还创建了一个vector,作为共享资源的角色。producer()和consumer()例程如预期——前者将创建数据,后者将消费数据,包括清除共享资源。由于两个操作将并行执行,它们的执行顺序是随机的。如果你想为此创建类似乒乓球的行为,条件变量或信号量可以用作信号机制。当前实现仅限于票据锁的目的:
TicketLock spinlock = {0};
vector<string> shared_res {};
void producer() {
for(int i = 0; i < 100; i ++) {
osyncstream{cout} << "Producing: " << endl;
spinlock.lock();
shared_res.emplace_back("test1");
shared_res.emplace_back("test2");
for (const auto& el : shared_res)
osyncstream{cout} << "p:" << el << endl;
spinlock.unlock();
this_thread::sleep_for(100ms);
}
}
消费者与你已经学到的类似:
void consumer() {
for (int i = 0; i < 100; i ++) {
this_thread::sleep_for(100ms);
osyncstream{cout} << "Consuming: " << endl;
spinlock.lock();
for (const auto& el : shared_res)
osyncstream{cout} << "c:" << el << endl;
清除向量的内容:
shared_res.clear();
spinlock.unlock();
if (shared_res.empty())
osyncstream{cout} << "Consumed" << endl;
}
}
输出如下:
Producing:
p:test1
p:test2
Consuming:
c:test1
c:test2
...
输出显示,尽管它们不是等量调用的,但生产和消费例程被视为一个整体,这是预期的。如前所述,代替让线程暂停100ms,你也可以通过添加条件变量修改代码:
void producer() {
for(int i = 0; i < 100; i ++) {
cout <<"Producing:" << endl;
unique_lock<mutex> mtx(cv_mutex);
cond_var.wait(mtx, []{ return work_done ==
!work_done; });
继续预期的关键部分:
spinlock.lock();
shared_res.emplace_back"test1");
shared_res.emplace_back"test2");
for (const auto& el : shared_res)
cout <<"p" << el << endl;
spinlock.unlock();
work_done = !work_done;
}
}
通过结合这些技术——内存鲁棒性、同步原语、缓存友好性和指令排序意识——你拥有了真正提升代码性能并针对特定系统获得最佳性能的工具。我们想借此机会提醒你,这种详细的优化可能导致代码难以阅读和调试困难,因此仅在需要时使用它们。
总结
在本章中,我们汇集了使用C++实现最佳代码性能所需的全部工具集。你学习了许多不同系统和软件层面上的技术,如果你现在想休息一下,这是可以理解的。确实,我们所涵盖的一些内容,例如分支预测和缓存友好性,或通过条件变量和内存顺序实现更多算法,值得花费更多时间。我们强烈鼓励你将本章作为改进系统和更有效工作方向的一步。
下一章将致力于C++特性的另一个重大改进——协程。你将看到,对于这里讨论的一些机制,如事件等待,它们更为可取,而且更轻量。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









