







在本章中,我们将探讨并发(concurrency)的含义及其与并行(parallelism)的区别。我们将深入了解进程和线程背后的基础理论。接着,我们将研究C++内存模型的变化,这些变化在语言中支持了原生的并发。我们还将了解什么是竞态条件(race condition),它是如何导致数据竞争(data race),以及如何防止数据竞争。接下来,我们将熟悉C++20中的std::jthread基元,它支持多线程。我们将学习std::jthread类的具体细节,以及如何使用std::stop_source基元停止已经运行的std::jthread实例。最后,我们将学习如何同步并发代码的执行,以及如何从执行的任务中报告计算结果。我们将学习如何使用C++同步基元,例如屏障(barriers)和门闩(latches),来同步并发任务的执行,并如何使用承诺(promises)和未来(futures)正确报告这些任务的结果。
总结一下,本章我们将讨论以下主题:
- 什么是并发?
- 线程与进程
- C++中的并发
- 揭开竞态条件和数据竞争的神秘面纱
- 实用的多线程
- 并行执行期间的数据共享
那么,让我们开始吧!
技术要求
本章中的所有示例均在以下配置环境中测试过:
- Linux Mint 21 Cinnamon版
- 使用编译器标志的GCC 12.2 -
-``std=c++20 -pthread - 稳定的互联网连接
- 请确保您的环境至少是这么新的。对于所有示例,您也可以选择使用https://godbolt.org/。
什么是并发?
现代汽车已成为高度复杂的机器,不仅提供交通工具,还提供各种其他功能。这些功能包括信息娱乐系统,它允许用户播放音乐和视频,以及暖气和空调系统,用于调节乘客的温度。想象一下,如果这些功能不能同时工作的场景。在这种情况下,司机必须选择驾驶汽车、听音乐或保持舒适的气候之间进行选择。这不是我们对汽车的期望,对吧?我们期望所有这些功能同时可用,增强我们的驾驶体验,并提供舒适的旅程。为了实现这一点,这些功能必须并行运行。
但它们真的是并行运行的,还是只是并发运行的?二者有什么区别?
在计算机系统中,并发和并行在某些方面相似,但并不相同。想象一下,你有一些工作要做,但这些工作可以分成几个较小的部分。并发是指多个工作块在重叠的时间间隔内开始、执行和完成,没有执行的特定顺序保证。另一方面,并行是一种执行策略,这些工作块在拥有多个计算资源的硬件上同时执行,如多核处理器。
当多个我们称之为任务的工作块在某段时间内以未指定的顺序执行时,就发生了并发。操作系统可能会运行其中一些任务,而迫使其他任务等待。在并发执行中,任务不断地争取执行时间槽,因为操作系统不保证它们会一次性全部执行。此外,当任务正在执行时,它很可能突然被挂起,另一个任务开始执行。这被称为抢占。显然,在并发任务执行中,任务的执行顺序是不保证的。
让我们回到我们的汽车示例。在现代汽车中,信息娱乐系统负责同时执行许多活动。例如,它可以在让你听音乐的同时运行导航部分。这是因为系统并发运行这些任务。它在处理音乐内容的同时运行与路线计算相关的任务。如果硬件系统只有一个核心,那么这些任务应该并发运行:
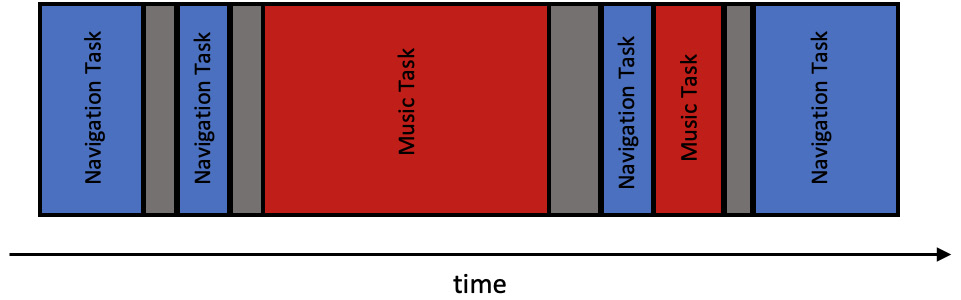
图6.1 - 并发任务执行
从上图中,你可以看到每个任务都在不可预测的顺序中获得了非确定性的执行时间。此外,没有保证你的任务会在下一个任务开始之前完成。这就是抢占发生的地方。当你的任务正在运行时,它可能突然被挂起,另一个任务被安排执行。请记住,任务切换并不是一个廉价的过程。系统消耗处理器的计算资源来执行这一动作——进行上下文切换。结论应该是以下内容:我们必须设计我们的系统以尊重这些限制。
另一方面,并行是并发的一种形式,涉及在单独的处理单元上同时执行多个操作。例如,一台配有多个CPU的计算机可以并行执行多个任务,这可以带来显著的性能提升。你不必担心上下文切换和抢占。然而,它也有自己的缺点,我们将会彻底讨论这些缺点。
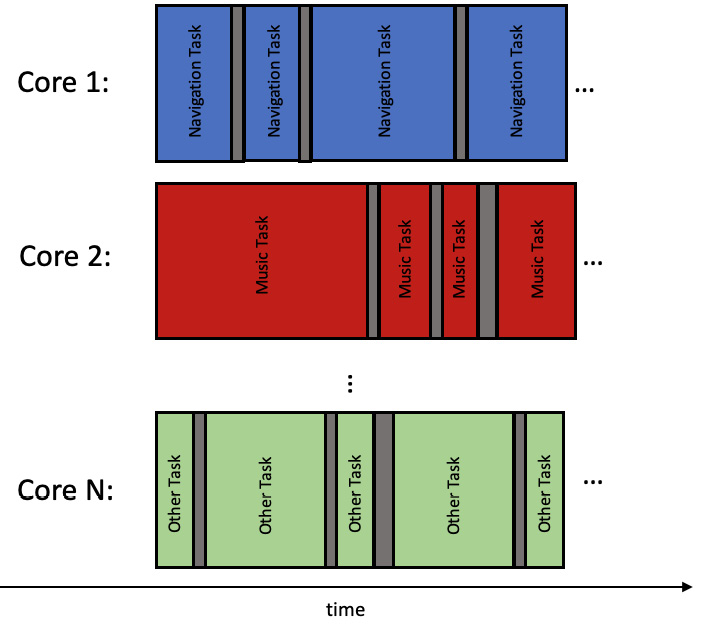
图6.2 - 并行任务执行
回到我们的汽车示例,如果信息娱乐系统的CPU是多核的,那么与导航系统相关的任务可以在一个核心上执行,而音乐处理的任务可以在其他一些核心上执行。因此,你不需要采取任何行动来设计你的代码以支持抢占。当然,这只有在你确信你的代码将在这样的环境中执行时才成立。
并发与并行之间的基本联系在于,并行可以应用于并发计算,而不影响结果的准确性,但仅并发的存在并不保证并行。
总之,并发是计算中的一个重要概念,它允许多个任务同时执行,尽管这并不是保证的。这可能导致性能提升和有效的资源利用,但代价是更复杂的代码,尊重并发带来的陷阱。另一方面,从软件角度看,真正的并行代码执行更容易处理,但必须由底层系统支持。
在下一节中,我们将熟悉Linux中执行线程和进程之间的区别。
线程与进程
在Linux中,进程是执行中程序的一个实例。一个进程可以有一个或多个执行线程。线程是可以独立于同一进程内的其他线程进行的指令序列。
每个进程都有自己的内存空间、系统资源和执行上下文。进程彼此隔离,不共享内存。它们只能通过文件和进程间通信(IPC)机制进行通信,如管道、队列、套接字、共享内存等。
另一方面,线程是进程内的轻量级执行单元。将指令从非易失性内存加载到RAM甚至缓存的开销已经由创建线程的进程——父进程支付。每个线程都有自己的堆栈和寄存器值,但共享父进程的内存空间和系统资源。因为线程在进程内共享内存,它们可以轻松地相互通信并同步自己的执行。一般来说,这使它们比进程更高效地用于并发执行。
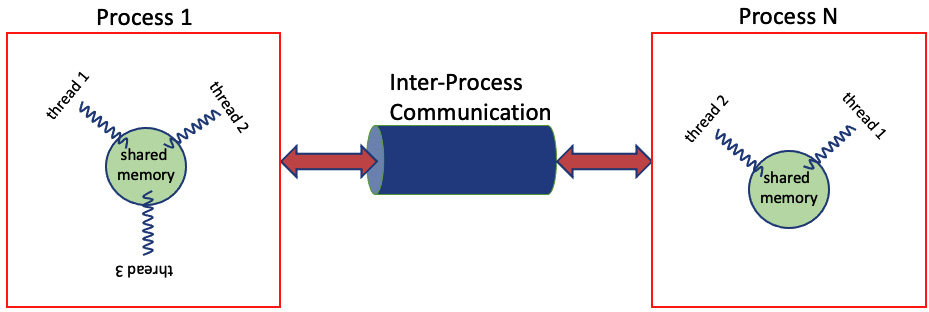
图6.3 - 进程间通信(IPC)
进程和线程之间的主要区别如下:
- 资源分配:进程是独立的实体,拥有自己的内存空间、系统资源和调度优先级。另一方面,线程共享它们所属进程的内存空间和系统资源。
- 创建和销毁:进程由操作系统创建和销毁,而线程由它们所属的进程创建和管理。
- 上下文切换:当发生上下文切换时,操作系统会切换整个进程上下文,包括所有线程。相比之下,线程上下文切换只需要切换当前线程的状态,一般来说,这更快速且消耗的资源更少。
- 通信和同步:使用管道、队列、套接字和共享内存等IPC机制实现进程间的通信。另一方面,线程可以通过在同一进程内共享内存直接进行通信。这还使线程之间的有效同步成为可能,因为它们可以使用锁和其他同步原语来协调对共享资源的访问。
重要说明
Linux在内核中调度任务,这些任务可以是线程也可以是单线程进程。每个任务通过一个内核线程表示;因此,调度程序不区分线程和进程。
进程和线程在现实生活中也有类似之处。假设你和一群人一起在一个项目上工作,项目被分成了不同的任务。每个任务代表需要完成的一项工作单位。你可以把项目想象成一个进程,每个任务想象成一个线程。
在这个类比中,进程(项目)是需要完成以实现共同目标的相关任务的集合。每个任务(线程)是可以分配给特定人员完成的独立的工作单位。
当你将一个任务分配给某人时,你就在项目(进程)中创建了一个新线程。被分配任务(线程)的人可以独立工作,不会干扰其他人的工作。他们还可以与其他团队成员(线程)沟通,以协调他们的工作,就像进程中的线程可以相互沟通一样。他们还需要使用公共项目资源来完成任务。
相比之下,如果你将项目划分为不同的项目,你就创建了多个进程。每个进程都有自己的资源、团队成员和目标。确保两个进程共享项目完成所需的资源会更困难。
因此,计算中的进程和线程就像现实生活中的项目和任务。进程代表需要完成以实现共同目标的相关任务的集合,而线程是可以分配给特定人员完成的独立的工作单位。
在Linux中,进程是带有自己的内存和资源的程序的单独实例,而线程是进程内共享相同内存和资源的轻量级执行单元。线程可以更有效地通信,并且更适合需要并行执行的任务,而进程则提供更好的隔离和容错能力。
牢记这些,让我们看看如何在C++中编写并发代码。
C++中的并发
自C++11起,C++语言就内置了管理和执行并发线程的支持。但它没有任何原生支持管理并发进程。C++标准库提供了各种用于线程管理、线程间的同步和通信、保护共享数据、原子操作和并行算法的类。C++内存模型也设计了线程意识。这使得它成为开发并发应用程序的绝佳选择。
C++的多线程能力是指在单个程序内并发运行多个执行线程的能力。这允许程序利用多个CPU核心并行执行任务,从而加快任务完成速度并提高整体性能。
C++标准库引入了std::thread线程管理类。一旦实例化,就由用户负责处理线程的目标。用户必须选择加入(join)线程或将其从父线程中分离(detach)。如果他们不处理它,程序就会终止。
随着C++20的发布,引入了一个全新的线程管理类std::jthread。它使创建和管理线程变得相对容易。要创建一个新线程,可以创建std::jthread类的实例,传递你想要作为单独线程运行的函数或可调用对象。与std::thread相比,std::jthread的一个关键优势是你不必明确担心加入它。它将在std::jthread销毁期间自动完成。在本章后面,我们将更深入地了解std::jthread及其使用方法。
请记住,多线程也会使程序更加复杂,因为它需要仔细管理共享资源和同步线程。如果没有正确管理,多线程可能会导致诸如死锁和竞态条件等问题,这可能导致程序挂起或产生意外结果。
此外,多线程要求开发人员确保代码是线程安全的,这可能是一项具有挑战性的任务。并非所有任务都适合多线程;如果尝试并行化,某些任务实际上可能会运行得更慢。
总的来说,C++的多线程可以在性能和资源利用方面提供显著的好处,但也需要仔细考虑潜在的挑战和陷阱。
现在,让我们熟悉编写并发代码的最常见陷阱。
揭示竞态条件和数据竞争
在C++中,多线程支持最初是在C++11语言版本中引入的。C++11标准提供的关键元素之一是内存模型,它有助于促进多线程。内存模型处理两个问题:对象在内存中的布局和这些对象的并发访问。在C++中,所有数据都由对象表示,对象是具有类型、大小、对齐、生命周期、值和可选名称等多种属性的内存块。每个对象在内存中存在特定时间段,并根据其是否为简单标量对象或更复杂类型而存储在一个或多个内存位置中。
在C++的多线程编程上下文中,考虑如何处理多个线程对共享对象的并发访问至关重要。如果两个或更多线程尝试访问不同的内存位置,通常没有问题。然而,当线程同时尝试在同一内存位置写入时,可能导致数据竞争,从而导致程序中出现意外行为和错误。
重要说明
当多个线程尝试访问数据并且至少有一个尝试修改它时,如果没有采取措施同步内存访问,则会发生数据竞争。数据竞争可能导致程序中的未定义行为,并是麻烦的根源。
但是你的程序如何陷入数据竞争?这发生在未正确处理竞态条件时。让我们来看看数据竞争和竞态条件之间的区别:
- 竞态条件:代码的正确性取决于特定的时间或严格的操作顺序的情况
- 数据竞争:当两个或更多线程访问一个对象并且至少有一个线程修改它时
根据这些定义,我们可以推断,程序中发生的每一次数据竞争都是由于未正确处理竞态条件的结果。但相反并不总是成立:并非每个竞态条件都导致数据竞争。
理解竞态条件和数据竞争的最佳方式是看一个例子。让我们想象一个原始的银行系统,真的很原始,我们希望它在任何地方都不存在。
Bill和John在一家银行有账户。Bill的账户里有100美元,John的账户里有50美元。Bill欠John总共30美元。为了偿还债务,Bill决定向John的账户转账两次。第一次是10美元,第二次是20美元。事实上,Bill将偿还John。两次转账完成后,Bill的账户将剩余70美元,而John的账户总计将累积到80美元。
让我们定义一个Account结构,包含账户所有者的姓名以及在某一时刻的账户余额:
struct Account {
Account(std::string_view the_owner, unsigned
the_amount) noexcept :
balance{the_amount}, owner{the_owner} {}
std::string GetBalance() const {
return "Current account balance of " + owner +
" is " + std::to_string(balance) + '\n';
}
private:
unsigned balance;
std::string owner;
};
在Account结构中,我们还将添加重载的+=和-=运算符方法。这些方法分别负责向对应账户存入或取出特定金额的钱。在每次操作前后,都会打印账户的当前余额。以下是这些运算符的定义,它们是Account结构的一部分:
Account& operator+=(unsigned amount) noexcept {
Print(" balance before depositing: ", balance,
owner);
auto temp{balance}; // {1}
std::this_thread::sleep_for(1ms);
balance = temp + amount; // {2}
Print(" balance after depositing: ", balance,
owner);
return *this;
}
Account& operator-=(unsigned amount) noexcept {
Print(" balance before withdrawing: ", balance,
owner);
auto temp{balance}; // {1}
balance = temp - amount; // {2}
Print(" balance after withdrawing: ", balance,
owner);
return *this;
}
查看运算符函数的实现显示,它们首先读取账户的当前余额,然后将其存储在局部对象中(标记{1}),最后使用局部对象的值增加或减少指定金额。
就这么简单!
账户新余额的结果值被写回Account结构的balance成员中(标记{2})。
我们还需要定义一个方法,负责实际的资金转移:
void TransferMoney(unsigned amount, Account& from, Account& to) {
from -= amount; // {1}
to += amount; // {2}
}
它所做的唯一事情是从一个账户中取出所需金额(标记{1}),然后存入另一个账户(标记{2}),这正是我们成功转移账户间资金所需的。
现在,让我们看看我们的main程序方法,它将执行我们的示例:
int main() {
Account bill_account{"Bill", 100}; // {1}
Account john_account{"John", 50}; // {2}
std::jthread first_transfer{[&](){ TransferMoney(10,
bill_account, john_account); }}; // {3}
std::jthread second_transfer{[&](){ TransferMoney(20,
bill_account, john_account); }}; // {4}
std::this_thread::sleep_for(100ms); // {5}
std::cout << bill_account.GetBalance(); // {6}
std::cout << john_account.GetBalance(); // {7}
return 0;
}
首先,我们需要为Bill和John创建账户,并分别存入100美元和70美元(标记{1}和{2})。然后,我们必须进行实际的资金转移:一次10美元和一次20美元的转账(标记{3}和{4})。我知道这段代码可能对你来说看起来不熟悉,但别担心,我们将在本章稍后深入了解std::jthread。
到目前为止,你只需要知道的重要细节是,我们试图借助C++多线程库同时进行两次转账。在过程结束时,我们留出一些时间让两个执行线程完成资金转移(标记{5}),然后打印结果(标记{6}和{7})。正如我们已经讨论过的,转账完成后,Bill的账户应该有70美元,而John的账户应该有80美元。
让我们看看程序的输出:
140278035490560 Bill balance before withdrawing: 100
140278027097856 Bill balance before withdrawing: 100
140278027097856 Bill balance after withdrawing: 80
140278035490560 Bill balance after withdrawing: 90
140278027097856 John balance before depositing: 50
140278035490560 John balance before depositing: 50
140278027097856 John balance after depositing: 70
140278035490560 John balance after depositing: 60
Current account balance of Bill is 80
Current account balance of John is 60
等等,什么?Bill有80美元而John只有60美元!这怎么可能?
这是可能的,因为我们造成了一个竞态条件,导致了数据竞争!让我们来解释。仔细查看operator+=方法的实现就能发现问题所在。顺便说一下,另一个运算符方法的情况也是一样的:
Account& operator+=(unsigned amount) noexcept {
Print(" balance before withdrawing: ", balance, owner);
auto temp{balance}; // {1}
std::this_thread::sleep_for(1ms); // {2}
balance = temp + amount; // {3}
Print(" balance after withdrawing: ", balance, owner);
return *this;
}
在标记{1}处,我们将账户当前余额缓存到栈上的一个局部对象中。
重要说明
C++内存模型保证每个线程都有其自动存储期对象的自己的副本——即栈对象。
接下来,我们让当前执行线程休息至少1ms(标记{2})。通过这条语句,我们让我们的线程休眠,允许其他线程(如果有的话)占用处理器时间并开始执行。到目前为止,没有什么好担心的,对吧?一旦线程恢复执行,它就使用其缓存的账户余额值,并将其增加新的金额。最后,它将新计算的值存储回Account结构的balance成员中。
我们仔细观察程序的输出,可以看到以下情况:
140278035490560 Bill balance before withdrawing: 100
140278027097856 Bill balance before withdrawing: 100
140278027097856 Bill balance after withdrawing: 80
140278035490560 Bill balance after withdrawing: 90
第一次转账开始执行。它作为一个线程的一部分运行,其标识符为140278035490560。我们看到,在提款完成之前,第二次转账也开始了。它的标识符是140278027097856。第二次转账首先完成提款,使Bill的银行账户余额变为80美元。然后,第一次提款重新开始执行。但接下来会发生什么呢?它没有从Bill的账户中再取10美元,而是实际上退回了10美元!这是因为当第一个线程已经缓存了初始账户余额100美元时,它被挂起了。一个竞态条件被创建了。与此同时,第二次转账改变了账户余额,现在,当第一次转账恢复执行时,它已经在使用过时的缓存值了。这导致盲目地用过时的值覆盖了更新的账户余额。发生了数据竞争。
我们如何避免它们?
幸运的是,C++编程语言提供了各种并发控制机制来应对这些挑战,如原子操作、锁、信号量、条件变量、屏障等。这些机制有助于确保以可预测和安全的方式访问共享资源,并有效地协调线程以避免数据竞争。在接下来的章节中,我们将深入了解其中一些同步原语。
实用的多线程
在计算机科学中,执行线程是一系列可以由操作系统的调度器独立管理的代码指令。在Linux系统上,线程总是进程的一部分。C++线程可以通过标准提供的多线程能力并发执行。在执行期间,线程共享公共内存空间,不像进程那样,每个进程都有自己的内存。具体来说,一个进程的线程共享它的可执行代码、动态分配和全局分配的对象,这些对象没有定义为thread_local。
你好,C++ jthread
每个C++程序至少包含一个线程,这是运行int main()方法的线程。多线程程序在主线程执行的某个时刻启动了额外的线程。让我们看一个简单的C++程序,它使用多个线程打印标准输出:
#include <iostream>
#include <thread>
#include <syncstream>
#include <array>
int main() {
std::array<std::jthread, 5> my_threads; // Just an
array of 5 jthread objects which do nothing.
const auto worker{[]{
const auto thread_id = std::
this_thread::get_id(); // 3
std::osyncstream sync_cout{std::cout};
sync_cout << "Hello from new jthread with id:"
<< thread_id << '\n';
}};
for (auto& thread : my_threads) {
thread = std::jthread{worker}; // This moves the
new jthread on the place of the placeholder
}
std::osyncstream{std::cout} << "Hello Main program
thread with id:" << std::this_thread::get_id() <<
'\n';
return 0; // jthread dtors join them here.
}
程序开始时,进入int main()方法。到目前为止,没有什么意外。在执行开始时,我们在方法栈上创建了一个名为my_threads的变量。它是std::array类型的,其中包含五个元素。std::array类型代表标准库中的容器,封装了C风格的固定大小数组。它具有标准容器的优点,如自知其大小,支持赋值,随机访问迭代器等。与C++中的任何其他数组类型一样,我们需要指定它包含的元素类型。在我们的示例中,my_threads包含五个std::jthread对象。std::jthread类是在C++20标准发布时引入C++标准库的。它代表单个执行线程,就像在C++11发布时引入的std::thread一样。std::jthread相比于std::thread的一些优势是,它在销毁时会自动重新加入,并且在某些特定情况下可以被取消或停止。它定义在<thread>头文件中;因此,我们必须包含它以成功编译。
是的,你问的问题很对!如果我们已经定义了一个jthread对象数组,它们真的执行什么工作呢?期望是每个线程都与需要完成的某项工作相关联。但这里,简单的答案是什么都没有。我们的数组包含五个jthread对象,它们实际上并不代表执行线程。它们更像是占位符,因为当std::array被实例化时,如果没有传递其他参数,它还会使用它们的默认构造函数创建它包含的对象。
现在,让我们定义一些我们的线程可以关联的工作。std::jthread类接受任何可调用类型作为工作。这些类型提供了一个可以调用的单一操作。这些类型的广为人知的示例是函数对象和lambda表达式,我们已经在[第4章]中详细介绍过。在我们的示例中,我们将使用lambda表达式,因为它们提供了创建匿名函数对象(函数对象)的方式,可以在线使用或作为参数传递。C++11中lambda表达式的引入简化了创建匿名函数对象的过程,使其更加高效和直接。以下代码展示了我们的工作方法定义为lambda表达式:
const auto worker{[]{
const auto thread_id = std::this_thread::get_id();
std::osyncstream sync_cout{std::cout};
sync_cout << "Hello from new jthread with id:" <<
thread_id << '\n';
}};
定义的lambda表达式const auto worker{…};非常简单。它在函数栈上实例化。它没有输入参数,也不捕获外部的任何状态。它唯一的工作是打印jthread对象的ID到标准输出。C++中由标准并发支持库提供的每个线程都有一个与之相关的唯一标识符。std::this_thread::get_id()方法返回在其中调用它的特定线程的ID。这意味着如果这个lambda表达式被传递给几个不同的线程,它应该打印不同的线程ID。
由许多并发线程打印到std::cout可能会带来令人惊讶的结果。std::cout对象被定义为一个全局的、线程安全的对象,它确保写入它的每个字符都是原子性完成的。然而,不保证字符序列,如字符串的连续性,而且当多个线程并发地向std::cout写入字符串时,输出很可能是这些字符串的混合。嗯,这不是我们在这里真正想要的。我们期望每个线程都能完整地打印其消息。因此,我们需要一个同步机制,确保向std::cout写入字符串是完全原子的。幸运的是,C++20在<syncstream>标准库头文件中引入了一整套新的类模板,为向同一个流写入的线程提供了同步机制。其中之一是std::osyncstream。你可以像使用普通流一样使用它。只需创建一个实例,并将std::cout作为参数传递。然后,借助其std::basic_ostream& operator<<(...)类方法,您可以插入数据,就像普通流一样。保证所有插入的数据将在std::osyncstream对象超出作用域并被销毁时原子性地刷新到输出中。在我们的示例中,当lambda即将完成执行并离开其作用域时,sync_cout对象将被销毁。这正是我们想要的行为。
最后,我们准备好让我们的线程做一些工作了。这意味着我们需要将工作lambda与my_threads数组中的五个线程关联起来。但是std::jthread类型只支持在其构造过程中添加工作方法。这就是为什么我们需要创建其他jthread对象,并将它们替换到my_threads数组中的占位符:
for (auto& thread : my_threads) {
thread = jthread{worker}; // This moves the new jthread
on the place of the placeholder
}
作为标准容器,std::array天然支持基于范围的for循环。因此,我们可以轻松地迭代my_threads中的所有元素,并用已经关联了工作者的新jthread对象替换它们。首先,我们使用自动存储期创建新的jthread对象,并为它们分配工作对象。在我们的案例中,对于每个新创建的线程,我们分配了同一个工作对象。这是可能的,因为在当前情况下,jthread类在jthread对象中复制了工作实例的副本,因此,每个jthread对象都得到了工作lambda的自己的副本。在构造这些对象时,过程是在调用者的上下文中进行的。这意味着在评估和复制或移动参数期间发生的任何异常都将在当前的main线程中抛出。
一个重要的细节是,新创建的jthread对象不是复制到数组的现有元素中,而是移动过去的。因此,std::jthread类隐式删除了其复制构造函数和赋值运算符,因为将线程复制到已经存在的线程中没有多大意义。在我们的案例中,新创建的jthread对象将在现有数组元素的存储中创建。
当构造jthread对象时,相关联的线程会立即开始执行,尽管可能由于Linux调度的特点而存在一些延迟。线程从构造函数参数指定的函数开始执行。在我们的示例中,这就是与每个线程关联的工作lambda。如果工作函数返回结果,它将被忽略,如果以抛出异常结束,则会执行std::terminate函数。因此,我们需要确保我们的工作代码不会抛出异常,或者我们能捕获所有可能抛出的异常。
当线程开始时,它开始执行它的专用工作函数。每个线程都有自己的函数栈空间,这保证了在工作函数中定义的任何局部变量都将在每个线程中有一个独立的实例。因此,工作函数中的const auto thread_id将根据运行它的线程而初始化为不同的ID。我们不需要采取任何措施来确保存储在thread_id中的数据是一致的。标准保证了具有自动存储周期的数据不会在线程之间共享。
一旦所有的jthread对象都创建完毕,主线程就会与其他线程一起并发地打印其ID。每个线程的执行顺序没有保证,并且可能会被另一个线程中断。因此,确保代码能够处理潜在的抢占并在所有情况下保持稳健是非常重要的:
std::osyncstream{std::cout} << "Hello Main program thread
with id:" << std::this_thread::get_id() << '\n';
现在所有线程都在与主线程并发运行。我们需要确保主线程也以线程安全的方式向标准输出打印。我们再次使用std::osyncstream的实例,但这次我们没有创建一个命名变量,而是创建了一个临时变量。这种方法由于使用方便而受到青睐,类似于使用std::cout对象。标准保证在每个语句的末尾都会刷新输出,因为临时变量会持续到语句的末尾并且其析构函数被调用,从而导致输出的刷新。
以下是程序的示例输出:
Hello from new jthread with id:1567180544
Hello from new jthread with id:1476392704
Hello from new jthread with id:1468000000
Hello Main program thread with id:1567184704
Hello from new jthread with id:1558787840
Hello from new jthread with id:1459607296
std::jthread的名称指的是加入线程。与std::thread不同,std::jthread还具有自动加入其启动的线程的能力。std::thread的行为有时可能令人困惑。如果std::thread没有被加入或分离,并且仍被认为是可加入的,那么在其销毁时将调用std::terminate函数。线程被认为是可加入的,是指没有调用join()或detach()方法。在我们的示例中,所有的jthread对象在销毁时会自动加入,不会导致程序终止。
在C++ 20发布之前,停止线程并不真正可能。std::thread能否被停止并没有保证,因为没有标准的实用工具来中止线程的执行。相反,通常使用不同的机制。停止std::thread需要main线程和工作线程之间的合作,通常使用标志、原子变量或某种消息系统。
随着C++20的发布,现在有了一种标准化的实用工具,用于请求std::jthread对象停止执行。停止标记来帮助实现这一点。查看关于std::jthread定义的C++标准参考页面(https://en.cppreference.com/w/cpp/thread/jthread),我们可以找到以下内容:
“类jthread代表单个执行线程。它具有与std::thread相同的一般行为,除了jthread在销毁时会自动重新加入,并且在某些情况下可以被取消/停止。”
我们已经看到jthread对象在销毁时会自动加入,但取消/停止是什么意思,而且“某些情况”是指什么?让我们更深入地了解这个问题。
首先,不要期望std::jthread暴露出一些神奇的机制,一些按下就能停止运行线程的红色按钮。这始终是一个实现问题,你的工作函数到底是如何实现的。如果你希望你的线程可以被取消,你必须确保你以正确的方式实现了它,以便允许取消:
#include <iostream>
#include <syncstream>
#include <thread>
#include <array>
using namespace std::literals::chrono_literals;
int main() {
const auto worker{[](std::stop_token token, int num){// {1}
while (!token.stop_requested()) { // {2}
std::osyncstream{std::cout} << "Thread with id
" << num << " is currently working.\n";
std::this_thread::sleep_for(200ms);
}
std::osyncstream{std::cout} << "Thread with id " <<
num << " is now stopped!\n";
}};
std::array<std::jthread, 3> my_threads{
std::jthread{worker, 0},
std::jthread{worker, 1},
std::jthread{worker, 2}
};
// Give some time to the other threads to start
executing …
std::this_thread::sleep_for(1s);
// 'Let's stop them
for (auto& thread : my_threads) {
thread.request_stop(); // {3} - this is not a
blocking call, it is just a request.
}
std::osyncstream{std::cout} < "Main thread just
requested stop!\n";
return 0; // jthread dtors join them here.
}
查看我们的工作lambda函数的定义,我们观察到它现在有所改动(标记{1})。它接受两个新参数 - std::stop_token token和int num。停止标记反映了jthread对象具有的共享停止状态。如果工作方法接受许多参数,则停止标记必须始终是传递的第一个参数。
确保工作方法被设计为能够处理取消是必要的。这就是停止标记用途所在。我们的逻辑应该以这样的方式实现:定期检查是否收到了停止请求。这是通过调用std::stop_token对象的stop_requested()方法来完成的。每个特定的实现决定何时何地进行这些检查。如果代码不尊重停止标记状态,那么线程就不能优雅地被取消。所以,正确设计你的代码取决于你。
幸运的是,我们的工作lambda尊重线程的停止标记状态。它不断检查是否请求停止(标记{2})。如果没有,它就打印线程的ID,并休眠200ms。这个循环持续进行,直到父线程决定向其工作线程发送停止请求(标记{3})。这是通过调用std::jthread对象的request_stop()方法来实现的。
这是程序的输出:
Thread with id 0 is currently working.
Thread with id 1 is currently working.
Thread with id 2 is currently working.
Thread with id 1 is currently working.
Thread with id 2 is currently working.
Thread with id 0 is currently working.
Thread with id 1 is currently working.
Thread with id 2 is currently working.
Thread with id 0 is currently working.
Thread with id 2 is currently working.
Thread with id 1 is currently working.
Thread with id 0 is currently working.
Thread with id 1 is currently working.
Thread with id 0 is currently working.
Thread with id 2 is currently working.
Main thread just requested stop!
Thread with id 1 is now stopped!
Thread with id 0 is now stopped!
Thread with id 2 is now stopped!
现在我们知道了如何使用std::stop_token停止特定std::jthread的执行,让我们看看如何使用单一停止源来停止多个std::jthread对象的执行。
std::stop_source
std::stop_source类允许你为std::jthread发出取消请求信号。当通过stop_source对象发出停止请求时,它将对与同一停止状态相关联的所有其他stop_source和std::stop_token对象可见。你只需发出信号,任何消费它的线程工作函数都会被通知。
通过使用std::stop_token和std::stop_source,线程可以异步地发出或检查停止执行的请求。停止请求是通过std::stop_source发出的,它会影响所有相关的std::stop_token对象。这些令牌可以传递给工作函数,并用于监控停止请求。std::stop_source和std::stop_token都共享对停止状态的所有权。std::stop_source类的方法request_stop()以及std::stop_token中的方法stop_requested()和stop_possible()都是原子操作,以确保不会发生数据竞争。
让我们看看如何用停止标记重新工作前面的示例:
#include <iostream>
#include <syncstream>
#include <thread>
#include <array>
using namespace std::literals::chrono_literals;
int main() {
std::stop_source source;
const auto worker{[](std::stop_source sr, int num){
std::stop_token token = sr.get_token();
while (!token.stop_requested()) {
std::osyncstream{std::cout} << "Thread with id
" << num << " is currently working.\n";
std::this_thread::sleep_for(200ms);
}
std::osyncstream{std::cout} << "Thread with id " <<
num << " is now stopped!\n";
}};
std::array<std::jthread, 3> my_threads{
std::jthread{worker, source, 0},
std::jthread{worker, source, 1},
std::jthread{worker, source, 2}
};
std::this_thread::sleep_for(1s);
source.request_stop(); // this is not a blocking call,
it is just a request. {1}
Std::osyncstream{std::cout} << "Main thread just
requested stop!\n";
return 0; // jthread dtors join them here.
}
main方法从声明std::stop_source源开始,这将被main线程用来向所有子工作线程发出信号并请求它们停止。工作lambda函数略有修改,以便接受std::stop_source sr作为输入。这实际上是通知工作函数停止请求的通信渠道。std::stop_source对象在与启动线程关联的所有工作函数中被复制。
与其遍历所有线程并对每个线程发出停止请求,我们只需要在main线程中直接调用request_stop()(标记{1})。这将向所有消费它的工作函数广播停止请求。
正如名称所暗示的,对停止源对象调用request_stop()方法只是一个请求,而不是一个阻塞调用。因此,不要期望你的线程在调用完成后立即停止。
以下是程序的示例输出:
Thread with id 0 is currently working.
Thread with id 1 is currently working.
Thread with id 2 is currently working.
Thread with id 1 is currently working.
Thread with id 2 is currently working.
Thread with id 0 is currently working.
Thread with id 1 is currently working.
Thread with id 2 is currently working.
Thread with id 0 is currently working.
Thread with id 1 is currently working.
Thread with id 0 is currently working.
Thread with id 2 is currently working.
Thread with id 1 is currently working.
Thread with id 0 is currently working.
Thread with id 2 is currently working.
Main thread just requested stop!
Thread with id 1 is now stopped!
Thread with id 0 is now stopped!
Thread with id 2 is now stopped!
我们现在熟悉了两种在 C++ 中停止线程执行的机制。现在,是时候看看如何在多个线程之间共享数据了。
在C++中,任务由一个工作函数以及两个关联组件组成:promise(承诺) 和 future(未来)。这些组件通过一个共享状态连接,它是一种数据通道。promise完成工作并将结果放在共享状态中,而future检索结果。promise和future可以在不同的线程中运行。future的一个独特之处在于它可以在稍后时间检索结果,使得promise计算结果的时间独立于关联future检索结果的时间。
现在,让我们深入了解如何在并行执行中共享数据。
在并行执行期间共享数据
以任务为思考方式而不是线程(https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#cp4-think-in-terms-of-tasks-rather-than-threads)。
回顾C++核心准则,它们建议我们更多地关注于任务而不是线程。线程是一种技术实现的思路,是对机器工作方式的一种看法。另一方面,任务是一个实际的概念,用于你想要完成的工作,理想情况下与其他任务并行进行。通常,实际概念更易于理解并提供更好的抽象,我们更倾向于使用它们。
但在C++中,任务是什么?任务不是另一种标准库原语,而是一个更高层次的抽象。它允许开发者以更灵活和抽象的方式来处理并发和并行问题。通过使用任务,开发者可以将关注点从线程的管理和同步转移到实际要执行的工作上,从而简化并发编程。任务通常通过标准库中的std::async、std::future和std::promise等工具来实现,它们提供了在不同线程中启动和管理异步操作的机制。
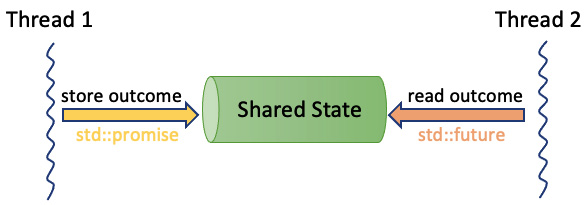
图6.4 – 线程间通信
标准库中定义的<future>头文件对于使用任务至关重要。它提供了获取在单独线程中执行的函数的结果的能力,这些函数也被称为异步任务,并且能够管理它们可能抛出的任何异常。通过使用std::promise类,这些结果通过一个共享状态进行通信,异步任务可以在其中存储其返回值或异常。然后可以使用std::future访问此共享状态以检索返回值或存储的异常。
让我们看一个简单的示例,其中一个线程向其父线程报告一个字符串作为结果:
#include <future>
#include <thread>
#include <iostream>
using namespace std::literals::chrono_literals;
int main() {
std::promise<std::string> promise; // {1}
std::future<std::string> future{promise.get_future()};
// {2} – Get the future from the promise.
std::jthread th1{[p{std::move(promise)}]() mutable { //
{3} – Move the promise inside the worker thread.
std::this_thread::sleep_for(20ms);
p.set_value_at_thread_exit("I promised to call you
back once I am ready!\n"); // {4}
}};
std::cout << "Main thread is ready.\n";
std::cout << future.get(); // {5} – This is a blocking
call!
return 0;
}
正如我们之前讨论的,线程之间使用共享状态进行通信。在int main()方法中,我们声明了std::promise<std::string> promise,这是我们的事实上的数据源(标记{1})。std::promise类是一个模板类,一旦实例化,就需要参数化。在我们的示例中,我们希望我们的工作线程std::thread th1返回一个字符串作为结果。因此,我们使用std::string类型实例化std::promise。我们还需要一种方法让main线程能够获取工作线程将要设置的结果。为此,我们需要从我们已经实例化的承诺中获取一个std::future对象。这是可能的,因为std::promise类型有一个返回其关联的未来的方法——std::future<...> get_future()。在我们的示例中,我们实例化了一个未来对象future,它由承诺的get_future()方法初始化(标记{2})。
由于我们已经有了一个承诺及其关联的未来,我们现在准备将承诺作为工作线程的一部分进行移动。我们这样做是为了确保它不会再被main线程使用(标记{3})。我们的工作线程非常简单,它只是睡眠20ms并在承诺中设置结果(标记{4})。std::promise类型提供了几种设置结果的方式。结果可以是承诺参数化的类型的值,也可以是工作执行期间抛出的异常。值由set_value()和set_value_at_thread_exit()方法设置。这两种方法的主要区别在于set_value()立即通知共享状态值已准备好,而set_value_at_thread_exit()则在线程执行完成时这样做。
与此同时,main线程的执行被阻塞,等待工作线程的结果。这是通过调用future.get()方法完成的。这是一个阻塞调用,等待线程被阻塞,直到共享状态被通知未来的结果已经设置。在我们的示例中,这在工作线程完成后发生,因为只有在工作完成时共享状态才会被通知(标记{5})。
程序的预期输出如下:
Main thread is ready.
I promised to call you back once I am ready!
屏障和锁存器
C++20标准引入了新的线程同步原语。屏障和锁存器是直接的线程同步原语,它们阻塞线程等待直到一个计数器达到零。这些原语以std::latch和std::barrier类的形式由标准库提供。
这两种同步机制有何区别?关键区别在于std::latch只能使用一次,而std::barrier可以被多个线程多次使用。
与C++标准提供的其他同步原语(如条件变量和锁)相比,屏障和锁存器有什么优势?屏障和锁存器更容易使用,更直观,在某些情况下,可能提供更好的性能。
让我们来看以下示例:
#include <thread>
#include <iostream>
#include <array>
#include <latch>
#include <syncstream>
using namespace std::literals::chrono_literals;
int main() {
std::latch progress{2}; // {1}
std::array<std::jthread, 2> threads {
std::jthread{[&](int num){
std::osyncstream{std::cout} << "Starting thread
" << num << " and go to sleep.\n";
std::this_thread::sleep_for(100ms);
std::osyncstream{std::cout} << "Decrementing
the latch for thread " << num << '\n';
progress.count_down(); // {2}
std::osyncstream{std::cout} << "Thread " << num
<< " finished!\n";
}, 0},
std::jthread{[&](int num){
std::osyncstream{std::cout} << "Starting thread
" << num << ". Arrive on latch and wait to
become zero.\n";
progress.arrive_and_wait(); // {3}
std::osyncstream{std::cout} << "Thread " << num
<< " finished!\n";
}, 1}
};
std::osyncstream{std::cout} << "Main thread waiting
workers to finish.\n";
progress.wait(); // {4} wait for all threads to finish.
std::cout << "Main thread finished!\n";
return 0;
}
我们有一个由两个线程组成的数组,这些线程在锁存器上同步。这意味着每个线程开始执行并进行其工作,直到它到达锁存器。
std::latch 类是一种利用递减计数器来协调线程的同步机制。计数器在初始化时设置,并作为参数传递给构造函数。线程可以等待直到计数器达到零。一旦初始化,就不可能增加或重置计数器。从多个线程并发访问std::latch的成员函数是线程安全的,且不会发生数据竞争。
在我们的示例(标记{1})中,我们使用值为2初始化了锁存器,因为我们有两个工作线程需要与主线程同步。一旦工作线程到达锁存器,它有三个选择:
- 减少它并继续(标记
{2})。这是通过std::latch类的成员方法——void count_down(n = 1)来完成的。这个调用是非阻塞的,并自动将锁存器的内部计数器值减少n。如果尝试用负值或大于内部计数器当前值的值来减少计数器,将导致未定义行为。在我们的示例中,这是一个ID为0的工作线程,一旦准备好,就减少锁存器计数器并完成。 - 减少它并等到锁存器变为零(标记
{3})。为此,您需要使用std::latch类的另一种方法——void arrive_and_wait(n = 1)。一旦调用此方法,它将锁存器减少n,并阻塞直到锁存器的内部计数器达到0。在我们的示例中,这是一个ID为1的工作线程,一旦准备好,就开始等待直到其他工作线程完成。 - 只是阻塞并等待直到锁存器的内部计数器变为零(标记
{4})。这是可能的,因为std::latch提供了一种方法——void wait() const。这是一个阻塞调用,调用线程被阻塞,直到锁存器的内部计数器达到零。在我们的示例中,main线程阻塞并开始等待工作线程完成它们的执行。
我们程序的结果是,main线程的执行被暂停,直到工作线程完成它们的工作。std::latch类提供了一种方便的方式来同步几个线程的执行:
Main thread waiting workers to finish.
Starting thread 1. Arrive on latch and wait to become zero.
Starting thread 0 and go to sleep.
Decrementing the latch for thread 0
Thread 0 finished!
Main thread finished!
Thread 1 finished!
std::barrier是一种与std::latch非常相似的同步原语。屏障是线程同步原语,允许一组线程等待,直到所有线程都达到特定的同步点。与锁存器不同,屏障可以多次使用。一旦线程从同步点释放,它们可以重用屏障。同步点是线程可以暂停其执行直到满足特定条件的特定时刻。这使得屏障非常适合同步重复任务,或者由许多线程执行同一更大任务的不同阶段。
为了更好地理解屏障是什么,让我们使用一个例子。想象你在家中安装了一个温度传感器网络。每个房间都安装了一个传感器。每个传感器在特定时间段内进行温度测量,并将结果缓存在其内存中。当传感器完成10次测量后,它会将这些数据作为一组发送到服务器。这个服务器负责收集你家中所有传感器的所有测量数据,并计算温度平均值——每个房间的平均温度和你整个家的平均温度。
现在让我们讨论算法。为了计算整个家的平均温度,我们首先需要处理传感器在某特定时间段发送到服务器的温度测量数据。这意味着我们需要处理接收到的特定房间的所有温度样本,以计算该房间的平均温度,并且我们需要对家中的所有房间都这样做。最后,根据每个房间计算出的平均温度,我们可以计算出整个家的平均温度。
听起来我们需要处理大量的数据。尝试在可能的地方并行化数据处理是有意义的。是的,你说得对:并不是所有的数据处理都可以并行化!我们需要遵守一系列严格的操作顺序。首先,我们需要计算每个房间的平均温度。由于房间之间没有依赖关系,所以我们可以并行执行这些计算。一旦我们计算出所有房间的温度,我们就可以继续计算整个家的平均温度。这正是std::barrier将派上用场的地方。
std::barrier同步原语在特定的同步点(屏障)阻塞线程,直到所有线程到达。然后,它允许调用回调并执行特定的操作。在我们的例子中,我们需要等待所有房间的计算完成——在屏障上等待。然后,将执行一个回调,在这个回调中,我们将计算整个家的平均温度:
using Temperature =
std::tuple<std::string, // The name of the room
std::vector<double>, // Temperature
measurements
double>; // Calculated mean temperature
// value for a specific room
std::vector<Temperature> room_temperatures {
{"living_room",{}, 0.0},
{"bedroom", {}, 0.0},
{"kitchen", {}, 0.0},
{"closet", {}, 0.0}
};
首先,让我们定义我们的数据容器,在这里我们将存储每个房间的温度测量数据以及由工作线程计算出的它们的平均值。我们将使用一个房间向量room_temperature,在其中存储房间名称、测量数据的向量和平均值。
现在,我们需要定义将并行计算每个房间平均值的工作线程:
std::stop_source message;
std::barrier measurementBarrier{ // {1}
static_cast<int>(room_temperatures.size()), // {2}
[&message]() noexcept { // {3}
// 1. Compute the mean temperature of the entire
home.
// 2. Push new temperature data
// 3. After 5 measurement cycles request stop.
}
};
std::vector<std::jthread> measurementSensors;
for (auto& temp : room_temperatures) {
measurementSensors.emplace_back([&measurementBarrier,
&message, &temp](){
const auto& token = message.get_token();
while(!token.stop_requested()) {
ProcessMeasurement(temp);
measurementBarrier.arrive_and_wait(); // {4}
}
});
}
我们为每个房间创建相同数量的jthread实例。每个jthread实例都被创建,并且分配了一个工作lambda函数。如你所见,工作lambda捕获了一个std::stop_source对象,该对象将用于通知它不再有其他工作待处理,线程执行应该结束。lambda还捕获了std::barrier measurementBarrier,当每个线程完成其计算并准备好时,这个屏障将用于阻塞线程,直到所有其他线程也准备好(标记{1})。
std::barrier实例需要用同步点的数量初始化(标记{2})。这意味着当达到屏障的线程数量等于初始化值时,屏障将被触发。在我们的例子中,我们用将并发计算每个房间平均温度的工作线程数量初始化屏障。屏障接受的一个可选初始化参数是回调函数(标记{3})。这个函数必须不能抛出异常,因此我们将其标记为noexcept。当所有线程在某个周期到达屏障并且在屏障被触发之前,这个函数将被调用。请记住,标准并没有指定这个回调将在哪个线程上执行。我们将使用这个回调来执行以下操作:
- 遍历所有已计算的房间平均温度,并计算整个家的平均温度。这是我们希望程序提供的结果。
- 为工作线程提供下一个计算周期的新温度数据。与
std::latch不同,std::barrier允许我们根据需要多次使用同一个屏障。 - 检查我们是否已经计算了五次整个家的平均温度,如果是这样,通知工作线程他们需要优雅地停止并退出程序。
当一个线程开始工作并准备好其计算时,它将达到屏障(标记{4})。这是可能的,因为std::barrier暴露了一个方法:void arrive_and_wait()。此调用有效地减少了屏障的内部计数器,通知屏障线程已到达,并阻塞线程,直到计数器达到零并触发屏障的回调。
在以下代码中,您可以找到负责生成示例温度值和计算平均温度值的方法:
void GetTemperatures(Temperature& temp) {
std::mt19937 gen{std::random_device{}()};
// Add normal distribution with mean = 20
// and standard deviation of 8
std::normal_distribution<> d{20, 8};
auto& input_data{std::get<1>(temp)};
input_data.clear();
for (auto n{0}; n < 10; ++n) {
// Add input data
input_data.emplace_back(d(gen));
}
}
void ProcessMeasurement(Temperature& temp){
const auto& values{std::get<1>(temp)};
auto& mean{std::get<2>(temp)};
mean = std::reduce(values.begin(), values.end()) /
values.size();
}
一旦我们拥有了所有必要的代码部分,让我们来看看我们程序的main方法实现:
int main() {
// Init data
std::ranges::for_each(room_temperatures,
GetTemperatures);
std::stop_source message;
std::barrier measurementBarrier{
static_cast<int>(room_temperatures.size()),
[&message]() noexcept {
// Get all results
double mean{0.0};
for (const auto& room_t : room_temperatures) {
std::cout << "Mean temperature in "
<< std::get<0>(room_t)
<< " is " << std::get<2>(room_t)
<< ".\n";
mean += std::get<2>(room_t);
}
mean /= room_temperatures.size();
std::cout << "Mean temperature in your home is
" << mean << " degrees Celsius.\n";
std::cout << "=======================
======================\n";
// Add new input data
std::ranges::for_each(room_temperatures,
GetTemperatures);
// Make 4 measurements and request stop.
static unsigned timer{0};
if (timer >= 3) {
message.request_stop();
}
++timer;
}
};
std::vector<std::jthread> measurementSensors;
for (auto& temp : room_temperatures) {
measurementSensors.emplace_back
([&measurementBarrier, &message, &temp](){
const auto& token = message.get_token();
while(!token.stop_requested()) {
ProcessMeasurement(temp);
measurementBarrier.arrive_and_wait();
}
});
}
return 0;
}
在我们的示例中,为了输入温度数据,我们使用了一个随机数生成器,它产生符合正态分布的数据。因此,我们得到了以下输出:
Mean temperature in living_room is 18.7834.
Mean temperature in bedroom is 16.9559.
Mean temperature in kitchen is 22.6351.
Mean temperature in closet is 20.0296.
Mean temperature in your home is 19.601 degrees Celsius.
=============================================
Mean temperature in living_room is 19.8014.
Mean temperature in bedroom is 20.4068.
Mean temperature in kitchen is 19.3223.
Mean temperature in closet is 21.2223.
Mean temperature in your home is 20.1882 degrees Celsius.
=============================================
Mean temperature in living_room is 17.9305.
Mean temperature in bedroom is 22.6204.
Mean temperature in kitchen is 17.439.
Mean temperature in closet is 20.3107.
Mean temperature in your home is 19.5752 degrees Celsius.
=============================================
Mean temperature in living_room is 19.4584.
Mean temperature in bedroom is 19.0377.
Mean temperature in kitchen is 16.3529.
Mean temperature in closet is 20.1057.
Mean temperature in your home is 18.7387 degrees Celsius.
=============================================
总结
在本章中,我们探讨了C++中与并发和并行相关的几个主题。我们首先讨论了并发和并行的术语和区别,包括抢占式多任务处理。然后,我们深入探讨了程序在单个和多个处理单元上的执行方式,区分了进程和执行线程,并简要地探索了诸如管道、套接字和共享内存等通信机制。
在C++的背景下,我们考察了该语言如何支持并发,特别是通过std::thread类和在C++20中引入的新std::jthread原语。我们还讨论了与竞争条件和数据竞争相关的风险,包括一个资金转账操作的例子。为了避免这些问题,我们研究了诸如锁、原子操作和内存屏障等机制。
接着,我们仔细研究了std::jthread类,探讨了其功能和正确用法。此外,我们还了解了C++20中提供的一种新的同步流包装器,用于在并发环境中打印。我们还介绍了如何使用std::stop_token取消运行中的线程,以及如何使用std::stop_source请求停止多个线程。
然后,我们转移到了如何使用std::future和std::promise从线程返回结果的主题。此外,我们讨论了std::latch和std::barrier的使用,通过一个温度站的例子演示了后者如何用于同步线程。
总体而言,我们探讨了C++中与并发和并行相关的一系列主题,从基本术语和概念到更高级的技术和机制,以避免数据竞争和同步线程。但请继续关注,因为在下一章中,您将熟悉一些在软件编程中广泛使用的进程间通信(IPC)机制。















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









