







 本文详细介绍了字符串匹配中的KMP算法,包括其基本思想、next数组的构建及其优化。KMP算法通过预处理匹配串得到next数组,避免了暴力匹配中的冗余比较,提高了时间效率至O(n+m),并在空间效率上达到O(m)。文章还提供了get_nextVal()函数的改进版,进一步优化了匹配过程。
本文详细介绍了字符串匹配中的KMP算法,包括其基本思想、next数组的构建及其优化。KMP算法通过预处理匹配串得到next数组,避免了暴力匹配中的冗余比较,提高了时间效率至O(n+m),并在空间效率上达到O(m)。文章还提供了get_nextVal()函数的改进版,进一步优化了匹配过程。
字符串匹配是一道经典的算法问题,经常出现。例如:
给定主串ss,匹配串pp,返回情况有三种:
- 匹配成功,返回pp在ss中匹配到的第一个字符串的第一个字符的索引。
- 匹配失败,主串中不存在与匹配串pp相匹配的子串,返回-1
- 匹配串为空,返回0
以上就相当于Java中String类的public int indexOf(String str)方法。
1、最笨的方法当然就是暴力匹配
public int strStr(String ss, String pp) {
int n = ss.length(), m = pp.length();
for (int i = 0; i + m <= n; i++) {
boolean flag = true;
for (int j = 0; j < m; j++) {
if (ss.charAt(i + j) != pp.charAt(j)) {
flag = false;
break;
}
}
if (flag) {
return i;
}
}
return -1;
}
将pp匹配串与原串下标 i 开始匹配,一旦匹配失败,i++,继续重新匹配。
这样子效率极其低,
- 时间效率为O(n*m),n 是字符串 ss 的长度,m 是字符串 pp 的长度。
- 空间效率为O(1)
考虑这种情况:
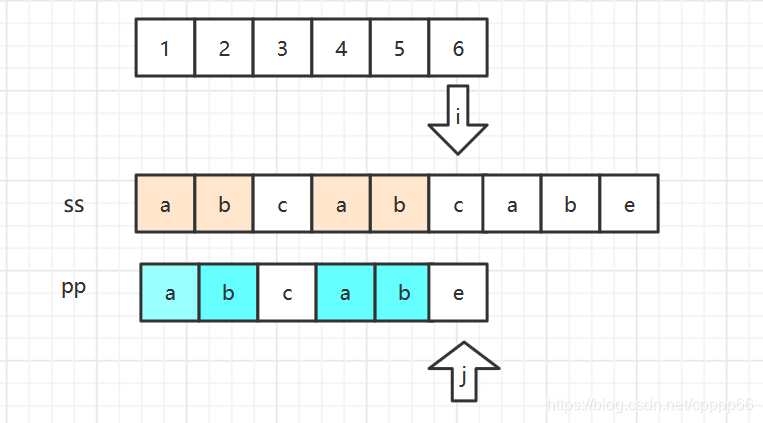
当 i =1 ,j =1 开始(索引0做哨兵,存空格字符),一直匹配到 j=6时发现匹配失败。 若按照暴力(朴素匹配法),会跳出 j 循环。然后开始以下新循环做匹配判断:
- i=2, j=1,匹配失败
- i=3, j=1 匹配失败
- i=4, j=1 匹配成功,i++ ,j++
- i=5, j=2 匹配成功,i++ ,j++
- i=6, j=3 匹配成功,i++ ,j++
然而由于我们知道当 j=6时,在此字符前的已匹配字符串中:蓝左(已匹配字符前缀)与蓝右(已匹配字符后缀)相等。
自然便得到有关系:蓝左=黄右(已被匹配的主串后缀)。
所以我们希望 i =6 不变,j =3,判断ss[6]与pp[3]是否相等。(此时这个j=3就是后文KMP中j=next[6]=3 得到的)
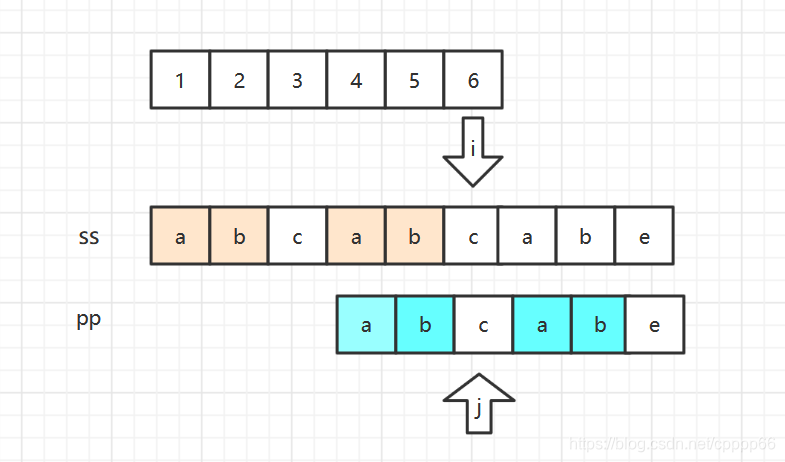
这样子便省略掉了朴素匹配算法中前4步不必要的判断。
由此诞生了KMP算法:
KMP代表了3位科学家
KMP算法的思想就是为pp字符串建立一个next数组,next[ i ]记录的是pp[ i ]字符前已匹配字符串的 前缀的 后一个字符的位置。
注意:此处及之后说的字符前已匹配字符串前缀与后缀之间的关系是两者为相等的字符串!
next[ i ] 有三种情况:
- next[ i ]=0, 当 i=1的时候
- next[ i ]=k, 当第i位字符前的字符串中,开头k-1位字符与结尾k-1位字符相等( k<i )
- next[ i ]=1, 其他情况
ps:(不难知道, next[ 2 ]只要存在,其实值就只能是1)
以下给出几个8位字符串的例子:
- aabcdaaz , next[ ]={0,1,2,1,1,1,2,3}
- aaaaaaaz, next[ ]={0,1,2,3,4,5,6,7}
- abcd efgz ,next[ ]={0,1,1,1,1,1,1,1}
next[ j ] 的含义就是当 ss[ i ] != pp[ j ] 时,跳转到 ss[ i ] 与 pp[ next[ j ] ]的匹配对比
给出next数组的求法:
public static int[] get_next(String pp){
pp = " " + pp; // 匹配串第[0]号字符设置为空格(哨兵),方便理解
int pattern_len = pp.length();
int[] next = new int[pattern_len]; //next数组长度等于匹配串数组长度
int i=1; // next数组的索引
int j=0; // 匹配串的索引
next[1]=0;
while(i < pattern_len-1){
if(j==0 || pp.charAt(i)==pp.charAt(j)){
++i;
++j;
next[i]=j; // 标记1, 在后续改进算法中,此行改为if-else
}else{
j=next[j]; //这一步看以下图解
}
}
return next;
}
关于next数组构建中,倒数第五行,next数组被使用的解释如下:
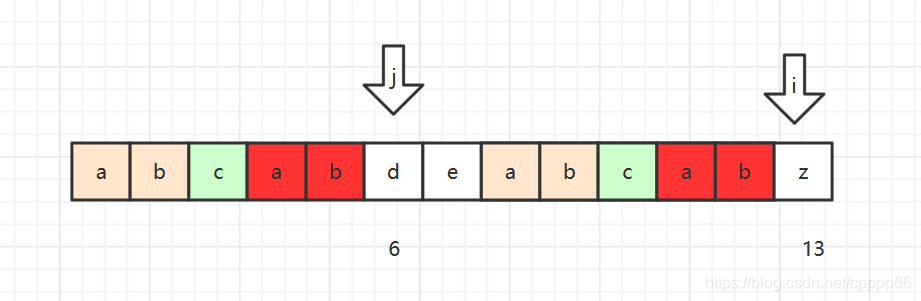
当j=6, i=13时, pp[ 6 ] != pp[ 13 ] , 令j = next[ j ] = 3。 只要p[ 3] == pp[ 13 ] 成立,则可以赋值pp [13]=3。( j字符前串的左黄与i字符前串的右红是相等的)
由此匹配字符串函数便可以写成:
// KMP 算法
// ss: 主串(string) pp: 匹配串(pattern)
public int strStr(String ss, String pp) {
if (pp.isEmpty()) return 0;
// 分别读取原主串和匹配串的长度
int n = ss.length(), m = pp.length();
// 构建 next 数组,数组长度为匹配串的长度+1 (索引0设置为哨兵)
int[] next = get_next(pp);
// 原串和匹配串前面都设置哨兵
ss = " " + ss;
pp = " " + pp;
// 转化为字符数组
char[] s = ss.toCharArray();
char[] p = pp.toCharArray();
int i=1,j=1; // 都从索引1开始匹配
while(i<=n && j<=m){
if(j==0 || s[i]==p[j]){
++i;
++j;
}else {
j = next[j];
}
}
if(j > m){
return i-m-1;
}else {
return -1;
}
}
然而KMP算法仍然可以继续提高效率:
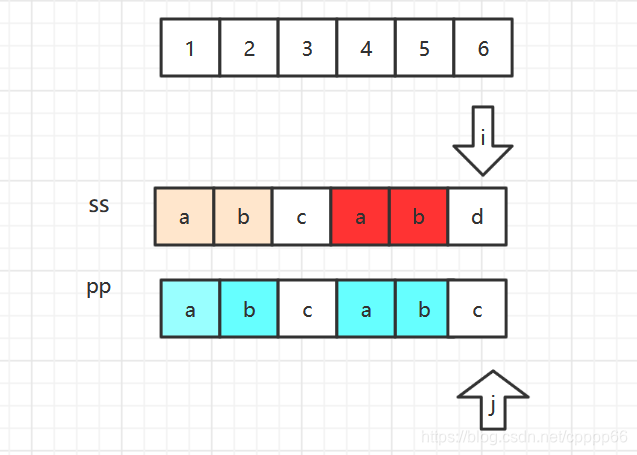
当pp[ 6 ]!= ss[ 6] 时候,j=next[ j ] =3 ,然而pp[ 3 ] 与 pp [6 ]相等,匹配的结果肯定为false,所以我们希望pp[6]直接等于next[ next[6] ]=1.
所以在构造next[ i ]时:
如果pp[ next[ i ] ] == pp[ i ]成立,则next[ i ] 应该等于 next[ next[ i ] ]。
将get_next()中的标记1, 那行代码改为如下if-else便可以改进。
if(pp[j]!=pp[i]){ // 当前字符与前缀字符不同时
next[i]=j;
}else { // 若该前缀字符与当前字符相同,则将前缀字符处的nextVal值赋给nextVal[i]
next[i]=next[j];
}
将改进后的next数组用nextVal来表示,完整的get_nextVal()函数如下:
public static int[] get_nextVal(String pp){
pp = " " + pp; // 匹配串第[0]号字符设置为空格(哨兵),方便理解
int pattern_len = pp.length();
int[] nextVal = new int[pattern_len]; //next数组长度等于匹配串数组长度
int i=1; // next数组的索引
int j=0;
nextVal[1]=0; // 索引0为哨兵,从索引1开始记录
while(i < pattern_len-1){
if(j==0 || pp.charAt(i)==pp.charAt(j)){
++i;
++j;
if(pp.charAt(i)!=pp.charAt(j)){ // 当前字符与前缀字符不同时
nextVal[i]=j;
}else { // 若该前缀字符与当前字符相同,则将前缀字符处的nextVal值赋给nextVal[i]
nextVal[i]=nextVal[j];
}
}else{
j=nextVal[j];
}
}
return nextVal;
}
这样子时间效率变成了O(n+m),空间效率为O(m),牺牲一点空间效率改进时间效率是非常值得的!
可以在理解的情况下,背下来get_nextVal()的构造方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









