









1 基本介绍
DRBD实际上是一种块设备的实现,主要被用于Linux平台下的高可用(HA)方案之中。它是由内核模块和相关程序而组成,通过网络通信来同步镜像整个设备,有点类似于一个网络RAID的功能,也就是说当你将数据写入本地的DRBD设备上的文件系统时,数据会同时被发送到网络中的另外一台主机之上,并以完全相同的形式记录在文件系统中(实际上文件系统的创建也是由DRBD的同步来实现的),所以当本地节点的主机出现故障时,远程节点的主机上还会保留有一份完全相同的数据,可以继续使用,以达到高可用的目的。
在高可用(HA)解决方案中使用DRBD的功能,可以代替使用一个共享盘阵存储设备。因为数据同时存在于本地主机和远程主机上,在遇到需要切换的时候,远程主机只需要使用它上面的那份备份数据,就可以继续提供服务了。
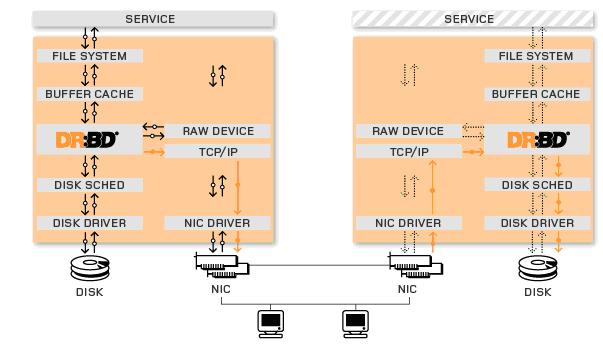
DRBD结构示意图:
2 配置文件
A 文件内容
#
# drbd.conf example
#
# parameters you _need_ to change are the hostname, device, disk,
# meta-disk, address and port in the "on <hostname> {}" sections.
#
# you ought to know about the protocol, and the various timeouts.
#
# you probably want to set the rate in the syncer sections
#
# NOTE common pitfall:
# rate is given in units of _byte_ not bit
#
#
# increase timeout and maybe ping-int in net{}, if you see
# problems with "connection lost/connection established"
# (or change your setup to reduce network latency; make sure full
# duplex behaves as such; check average roundtrip times while
# network is saturated; and so on ...)
#
skip {
As you can see, you can also comment chunks of text
with a 'skip[optional nonsense]{ skipped text }' section.
This comes in handy, if you just want to comment out
some 'resource <some name> {...}' section:
just precede it with 'skip'.
The basic format of option assignment is
<option name><linear whitespace><value>;
It should be obvious from the examples below,
but if you really care to know the details:
<option name> :=
valid options in the respective scope
<value> := <num>|<string>|<choice>|...
depending on the set of allowed values
for the respective option.
<num> := [0-9]+, sometimes with an optional suffix of K,M,G
<string> := (<name>|\"([^\"\\\n]*|\\.)*\")+
<name> := [/_.A-Za-z0-9-]+
}
#
# At most ONE global section is allowed.
# It must precede any resource section.
#
global {
# By default we load the module with a minor-count of 32. In case you
# have more devices in your config, the module gets loaded with
# a minor-count that ensures that you have 10 minors spare.
# In case 10 spare minors are too little for you, you can set the
# minor-count exeplicit here. ( Note, in contrast to DRBD-0.7 an
# unused, spare minor has only a very little overhead of allocated
# memory (a single pointer to be exact). )
#
# minor-count 64;
# The user dialog counts and displays the seconds it waited so
# far. You might want to disable this if you have the console
# of your server connected to a serial terminal server with
# limited logging capacity.
# The Dialog will print the count each 'dialog-refresh' seconds,
# set it to 0 to disable redrawing completely. [ default = 1 ]
#
# dialog-refresh 5; # 5 seconds
# You might disable one of drbdadm's sanity check.
# disable-ip-verification;
# Participate in DRBD's online usage counter at http://usage.drbd.org
# possilbe options: ask, yes, no. Default is ask. In case you do not
# know, set it to ask, and follow the on screen instructions later.
usage-count yes;
}
#
# The common section can have all the sections a resource can have but
# not the host section (started with the "on" keyword).
# The common section must precede all resources.
# All resources inherit the settings from the common section.
# Whereas settings in the resources have precedence over the common
# setting.
#
common {
syncer { rate 10M; }
}
#
# this need not be r#, you may use phony resource names,
# like "resource web" or "resource mail", too
#
resource r0 {
# transfer protocol to use.
# C: write IO is reported as completed, if we know it has
# reached _both_ local and remote DISK.
# * for critical transactional data.
# B: write IO is reported as completed, if it has reached
# local DISK and remote buffer cache.
# * for most cases.
# A: write IO is reported as completed, if it has reached
# local DISK and local tcp send buffer. (see also sndbuf-size)
# * for high latency networks
#
#**********
# uhm, benchmarks have shown that C is actually better than B.
# this note shall disappear, when we are convinced that B is
# the right choice "for most cases".
# Until then, always use C unless you have a reason not to.
# --lge
#**********
#
protocol C;
handlers {
# what should be done in case the node is primary, degraded
# (=no connection) and has inconsistent data.
pri-on-incon-degr "echo O > /proc/sysrq-trigger ; halt -f";
# The node is currently primary, but lost the after split brain
# auto recovery procedure. As as consequence it should go away.
pri-lost-after-sb "echo O > /proc/sysrq-trigger ; halt -f";
# In case you have set the on-io-error option to "call-local-io-error",
# this script will get executed in case of a local IO error. It is
# expected that this script will case a immediate failover in the
# cluster.
local-io-error "echo O > /proc/sysrq-trigger ; halt -f";
# Commands to run in case we need to downgrade the peer's disk
# state to "Outdated". Should be implemented by the superior
# communication possibilities of our cluster manager.
# The provided script uses ssh, and is for demonstration/development
# purposis.
# outdate-peer "/usr/lib/drbd/outdate-peer.sh on amd 192.168.22.11 192.168.23.11 on alf 192.168.22.12 192.168.23.12";
#
# Update: Now there is a solution that relies on heartbeat's
# communication layers. You should really use this.
outdate-peer "/usr/sbin/drbd-peer-outdater";
}
startup {
# Wait for connection timeout.
# The init script blocks the boot process until the resources
# are connected. This is so when the cluster manager starts later,
# it does not see a resource with internal split-brain.
# In case you want to limit the wait time, do it here.
# Default is 0, which means unlimited. Unit is seconds.
#
# wfc-timeout 0;
# Wait for connection timeout if this node was a degraded cluster.
# In case a degraded cluster (= cluster with only one node left)
# is rebooted, this timeout value is used.
#
degr-wfc-timeout 120; # 2 minutes.
}
disk {
# if the lower level device reports io-error you have the choice of
# "pass_on" -> Report the io-error to the upper layers.
# Primary -> report it to the mounted file system.
# Secondary -> ignore it.
# "call-local-io-error"
# -> Call the script configured by the name "local-io-error".
# "detach" -> The node drops its backing storage device, and
# continues in disk less mode.
#
on-io-error detach;
# Controls the fencing policy, default is "dont-care". Before you
# set any policy you need to make sure that you have a working
# outdate-peer handler. Possible values are:
# "dont-care" -> Never call the outdate-peer handler. [ DEFAULT ]
# "resource-only" -> Call the outdate-peer handler if we primary and
# loose the connection to the secondary. As well
# whenn a unconnected secondary wants to become
# primary.
# "resource-and-stonith"
# -> Calls the outdate-peer handler and freezes local
# IO immediately after loss of connection. This is
# necessary if your heartbeat can STONITH the other
# node.
# fencing resource-only;
# In case you only want to use a fraction of the available space
# you might use the "size" option here.
#
# size 10G;
}
net {
# this is the size of the tcp socket send buffer
# increase it _carefully_ if you want to use protocol A over a
# high latency network with reasonable write throughput.
# defaults to 2*65535; you might try even 1M, but if your kernel or
# network driver chokes on that, you have been warned.
# sndbuf-size 512k;
# timeout 60; # 6 seconds (unit = 0.1 seconds)
# connect-int 10; # 10 seconds (unit = 1 second)
# ping-int 10; # 10 seconds (unit = 1 second)
# ping-timeout 5; # 500 ms (unit = 0.1 seconds)
# Maximal number of requests (4K) to be allocated by DRBD.
# The minimum is hardcoded to 32 (=128 kByte).
# For high performance installations it might help if you
# increase that number. These buffers are used to hold
# datablocks while they are written to disk.
#
# max-buffers 2048;
# When the number of outstanding requests on a standby (secondary)
# node exceeds bdev-threshold, we start to kick the backing device
# to start its request processing. This is an advanced tuning
# parameter to get more performance out of capable storage controlers.
# Some controlers like to be kicked often, other controlers
# deliver better performance when they are kicked less frequently.
# Set it to the value of max-buffers to get the least possible
# number of run_task_queue_disk() / q->unplug_fn(q) calls.
#
# unplug-watermark 128;
# The highest number of data blocks between two write barriers.
# If you set this < 10 you might decrease your performance.
# max-epoch-size 2048;
# if some block send times out this many times, the peer is
# considered dead, even if it still answers ping requests.
# ko-count 4;
# If you want to use OCFS2/openGFS on top of DRBD enable
# this optione, and only enable it if you are going to use
# one of these filesystems. Do not enable it for ext2,
# ext3,reiserFS,XFS,JFS etc...
# allow-two-primaries;
# This enables peer authentication. Without this everybody
# on the network could connect to one of your DRBD nodes with
# a program that emulates DRBD's protocoll and could suck off
# all your data.
# Specify one of the kernel's digest algorithms, e.g.:
# md5, sha1, sha256, sha512, wp256, wp384, wp512, michael_mic ...
# an a shared secret.
# Authentication is only done once after the TCP connection
# is establised, there are no disadvantages from using authentication,
# therefore I suggest to enable it in any case.
# cram-hmac-alg "sha1";
# shared-secret "FooFunFactory";
# In case the nodes of your cluster nodes see each other again, after
# an split brain situation in which both nodes where primary
# at the same time, you have two diverged versions of your data.
#
# In case both nodes are secondary you can control DRBD's
# auto recovery strategy by the "after-sb-0pri" options. The
# default is to disconnect.
# "disconnect" ... No automatic resynchronisation, simply disconnect.
# "discard-younger-primary"
# Auto sync from the node that was primary before
# the split brain situation happened.
# "discard-older-primary"
# Auto sync from the node that became primary
# as second during the split brain situation.
# "discard-least-changes"
# Auto sync from the node that touched more
# blocks during the split brain situation.
# "discard-node-NODENAME"
# Auto sync _to_ the named node.
after-sb-0pri disconnect;
# In one of the nodes is already primary, then the auto-recovery
# strategie is controled by the "after-sb-1pri" options.
# "disconnect" ... always disconnect
# "consensus" ... discard the version of the secondary if the outcome
# of the "after-sb-0pri" algorithm would also destroy
# the current secondary's data. Otherwise disconnect.
# "violently-as0p" Always take the decission of the "after-sb-0pri"
# algorithm. Even if that causes case an erratic change
# of the primarie's view of the data.
# This is only usefull if you use an 1node FS (i.e.
# not OCFS2 or GFS) with the allow-two-primaries
# flag, _AND_ you really know what you are doing.
# This is DANGEROUS and MAY CRASH YOUR MACHINE if you
# have a FS mounted on the primary node.
# "discard-secondary"
# discard the version of the secondary.
# "call-pri-lost-after-sb" Always honour the outcome of the "after-sb-0pri"
# algorithm. In case it decides the the current
# secondary has the right data, it panics the
# current primary.
# "suspend-primary" ???
after-sb-1pri disconnect;
# In case both nodes are primary you control DRBD's strategy by
# the "after-sb-2pri" option.
# "disconnect" ... Go to StandAlone mode on both sides.
# "violently-as0p" Always take the decission of the "after-sb-0pri".
# "call-pri-lost-after-sb" ... Honor the outcome of the "after-sb-0pri"
# algorithm and panic the other node.
after-sb-2pri disconnect;
# To solve the cases when the outcome of the resync descissions is
# incompatible to the current role asignment in the cluster.
# "disconnect" ... No automatic resynchronisation, simply disconnect.
# "violently" .... Sync to the primary node is allowed, violating the
# assumption that data on a block device is stable
# for one of the nodes. DANGEROUS, DO NOT USE.
# "call-pri-lost" Call the "pri-lost" helper program on one of the
# machines. This program is expected to reboot the
# machine. (I.e. make it secondary.)
rr-conflict disconnect;
# DRBD-0.7's behaviour is equivalent to
# after-sb-0pri discard-younger-primary;
# after-sb-1pri consensus;
# after-sb-2pri disconnect;
}
syncer {
# Limit the bandwith used by the resynchronisation process.
# default unit is kByte/sec; optional suffixes K,M,G are allowed.
#
# Even though this is a network setting, the units are based
# on _byte_ (octet for our french friends) not bit.
# We are storage guys.
#
# Note that on 100Mbit ethernet, you cannot expect more than
# 12.5 MByte total transfer rate.
# Consider using GigaBit Ethernet.
#
rate 10M;
# Normally all devices are resynchronized parallel.
# To achieve better resynchronisation performance you should resync
# DRBD resources which have their backing storage on one physical
# disk sequentially. The express this use the "after" keyword.
after "r2";
# Configures the size of the active set. Each extent is 4M,
# 257 Extents ~> 1GB active set size. In case your syncer
# runs @ 10MB/sec, all resync after a primary's crash will last
# 1GB / ( 10MB/sec ) ~ 102 seconds ~ One Minute and 42 Seconds.
# BTW, the hash algorithm works best if the number of al-extents
# is prime. (To test the worst case performace use a power of 2)
al-extents 257;
}
on amd {
device /dev/drbd0;
disk /dev/hde5;
address 192.168.22.11:7788;
flexible-meta-disk internal;
# meta-disk is either 'internal' or '/dev/ice/name [idx]'
#
# You can use a single block device to store meta-data
# of multiple DRBD's.
# E.g. use meta-disk /dev/hde6[0]; and meta-disk /dev/hde6[1];
# for two different resources. In this case the meta-disk
# would need to be at least 256 MB in size.
#
# 'internal' means, that the last 128 MB of the lower device
# are used to store the meta-data.
# You must not give an index with 'internal'.
}
on alf {
device /dev/drbd0;
disk /dev/hdc5;
address 192.168.22.12:7788;
meta-disk internal;
}
}
#
# yes, you may also quote the resource name.
# but don't include whitespace, unless you mean it :)
#
resource "r1" {
protocol C;
startup {
wfc-timeout 0; ## Infinite!
degr-wfc-timeout 120; ## 2 minutes.
}
disk {
on-io-error detach;
}
net {
# timeout 60;
# connect-int 10;
# ping-int 10;
# max-buffers 2048;
# max-epoch-size 2048;
}
syncer {
}
on amd {
device /dev/drbd1;
disk /dev/hde6;
address 192.168.22.11:7789;
meta-disk /dev/somewhere [7];
}
on alf {
device /dev/drbd1;
disk /dev/hdc6;
address 192.168.22.12:7789;
meta-disk /dev/somewhere [7];
}
}
resource r2 {
protocol C;
startup { wfc-timeout 0; degr-wfc-timeout 120; }
disk { on-io-error detach; }
net { timeout 60; connect-int 10; ping-int 10;
max-buffers 2048; max-epoch-size 2048; }
syncer { rate 4M; } # sync when r0 and r1 are finished syncing.
on amd {
address 192.168.22.11:7790;
disk /dev/hde7; device /dev/drbd2; meta-disk "internal";
}
on alf {
device "/dev/drbd2"; disk "/dev/hdc7"; meta-disk "internal";
address 192.168.22.12:7790;
}
}
resource r3 {
protocol C;
startup { wfc-timeout 0; degr-wfc-timeout 120; }
disk { on-io-error detach; }
syncer {
}
on amd {
device /dev/drbd3;
disk /dev/hde8;
address 192.168.22.11:7791;
meta-disk internal;
}
on alf {
device /dev/drbd3;
disk /dev/hdc8;
address 192.168.22.12:7791;
meta-disk /some/where[8];
}
}
B 配置等待peer节点出现时间,默认是永远等待
startup{
wfc-timeout 120; //单位是秒
}
C 配置自动处理脑裂
DRBD自动处理脑裂有如下几种方式:
下面是一种简单的自动处理脑裂的脚本:
after-sb-0pri. Split brain has just been detected, but at this timethe resource is not in the Primary role on any host. Forthis option, DRBD understands the following keywords:
disconnect. Do not recover automatically, simply invokethesplit-brainhandler script (ifconfigured), drop the connection and continue indisconnected mode.
discard-younger-primary. Discard and roll back the modifications madeon the host which assumed the Primary rolelast.
discard-least-changes. Discard and roll back the modifications onthe host where fewer changes occurred.
discard-zero-changes. If there is any host on which no changesoccurred at all, simply apply all modificationsmade on the other and continue.
after-sb-1pri. Split brain has just been detected, and at this timethe resource is in the Primary role on one host. Forthis option, DRBD understands the following keywords:
disconnect. As withafter-sb-0pri, simplyinvoke thesplit-brainhandlerscript (if configured), drop the connection andcontinue in disconnected mode.
consensus. Apply the same recovery policies asspecified inafter-sb-0pri. If asplit brain victim can be selected afterapplying these policies, automatically resolve.Otherwise, behave exactly as ifdisconnectwere specified.
call-pri-lost-after-sb. Apply the recovery policies as specified inafter-sb-0pri. If a split brainvictim can be selected after applying thesepolicies, invoke thepri-lost-after-sbhandler on thevictim node. This handler must be configured inthehandlerssection and isexpected to forcibly remove the node from thecluster.
discard-secondary. Whichever host is currently in the Secondaryrole, make that host the split brainvictim.
after-sb-2pri. Split brain has just been detected, and at this time the resource is in the Primary role on both hosts. This option accepts the same keywords asafter-sb-1priexceptdiscard-secondaryandconsensus.handers{
pri-lost-after-sb "echo b>/proc/sysrq-trigger;reboot -f";
}
net{
after-sb-0pri discard-older-primary;
after-sb-1pri call-pri-lost-after-sb;
after-sb-2pri call-pri-lost-after-sb;
}
不过DRBD官方文档建议优先选择手动处理方式,手动处理方式的原文如下:
Manual split brain recovery
RBD protocol handshake. If DRBD detects that both nodes are (or were at some point, while disconnected) in the primary role, it immediately tears down the replication connection. The tell-tale sign of this is a message like the following appearing in the system log:
Split-Brain detected, dropping connection!
After split brain has been detected, one node will always have the resource in a StandAlone connection state. The other might either also be in the StandAlone state (if both nodes detected the split brain simultaneously), or in WFConnection (if the peer tore down the connection before the other node had a chance to detect split brain).
At this point, unless you configured DRBD to automatically recover from split brain, you must manually intervene by selecting one node whose modifications will be discarded (this node is referred to as the split brain victim). This intervention is made with the following commands:
drbdadm secondary resource
drbdadm -- --discard-my-data connect resource
On the other node (the split brain survivor), if its connection state is also StandAlone, you would enter:
drbdadm connect resource
You may omit this step if the node is already in the WFConnection state; it will then reconnect automatically.
If the resource affected by the split brain is a stacked resource, use drbdadm
--stackedinstead of just drbdadm.Upon connection, your split brain victim immediately changes its connection state to
SyncTarget, and has its modifications overwritten by the remaining primary node.After re-synchronization has completed, the split brain is considered resolved and the two nodes form a fully consistent, redundant replicated storage system again.
3 DRBD各种状态含义
The resource-specific output from
/proc/drbdcontains various pieces ofinformation about the resource:
cs(connection state). Status of the network connection. See the section called “Connection states” for details about the various connection states.
ro(roles). Roles of the nodes. The role of the local node isdisplayed first, followed by the role of the partnernode shown after the slash. See the section called “Resource roles” for details about thepossible resource roles.
ds(disk states). State of the hard disks. Prior to the slash thestate of the local node is displayed, after the slashthe state of the hard disk of the partner node isshown. See the section called “Disk states” for details about the variousdisk states.
ns(network send). Volume of net data sent to the partner via thenetwork connection; in Kibyte.
nr(network receive). Volume of net data received by the partner viathe network connection; in Kibyte.
dw(disk write). Net data written on local hard disk; inKibyte.
dr(disk read). Net data read from local hard disk; in Kibyte.
al(activity log). Number of updates of the activity log area of the metadata.
bm(bit map). Number of updates of the bitmap area of the metadata.
lo(local count). Number of open requests to the local I/O sub-systemissued by DRBD.
pe(pending). Number of requests sent to the partner, but thathave not yet been answered by the latter.
ua(unacknowledged). Number of requests received by the partner via thenetwork connection, but that have not yet beenanswered.
ap(application pending). Number of block I/O requests forwarded to DRBD, butnot yet answered by DRBD.
ep(epochs). Number of epoch objects. Usually 1. Might increaseunder I/O load when using either thebarrieror thenonewriteordering method. Since 8.2.7.
wo(write order). Currently used write ordering method:b(barrier),f(flush),d(drain) orn(none). Since8.2.7.
oos(out of sync). Amount of storage currently out of sync; inKibibytes. Since 8.2.6.
4 DRBD连接状态
A resource may have one of the following connectionstates:
StandAlone. No network configuration available. The resourcehas not yet been connected, or has beenadministratively disconnected (using drbdadm disconnect), or has dropped its connectiondue to failed authentication or split brain.
Disconnecting. Temporary state during disconnection. The nextstate is StandAlone.
Unconnected. Temporary state, prior to a connection attempt.Possible next states: WFConnection andWFReportParams.
Timeout. Temporary state following a timeout in thecommunication with the peer. Next state:Unconnected.
BrokenPipe. Temporary state after the connection to the peerwas lost. Next state: Unconnected.
NetworkFailure. Temporary state after the connection to thepartner was lost. Next state: Unconnected.
ProtocolError. Temporary state after the connection to thepartner was lost. Next state: Unconnected.
TearDown. Temporary state. The peer is closing theconnection. Next state: Unconnected.
WFConnection. This node is waiting until the peer node becomesvisible on the network.
WFReportParams. TCP connection has been established, this nodewaits for the first network packet from thepeer.
Connected. A DRBD connection has been established, datamirroring is now active. This is the normalstate.
StartingSyncS. Full synchronization, initiated by theadministrator, is just starting. The next possiblestates are: SyncSource or PausedSyncS.
StartingSyncT. Full synchronization, initiated by theadministrator, is just starting. Next state:WFSyncUUID.
WFBitMapS. Partial synchronization is just starting. Nextpossible states: SyncSource or PausedSyncS.
WFBitMapT. Partial synchronization is just starting. Nextpossible state: WFSyncUUID.
WFSyncUUID. Synchronization is about to begin. Next possiblestates: SyncTarget or PausedSyncT.
SyncSource. Synchronization is currently running, with thelocal node being the source ofsynchronization.
SyncTarget. Synchronization is currently running, with thelocal node being the target ofsynchronization.
PausedSyncS. The local node is the source of an ongoingsynchronization, but synchronization is currentlypaused. This may be due to a dependency on thecompletion of another synchronization process, ordue to synchronization having been manuallyinterrupted by drbdadm pause-sync.
PausedSyncT. The local node is the target of an ongoingsynchronization, but synchronization is currentlypaused. This may be due to a dependency on thecompletion of another synchronization process, ordue to synchronization having been manuallyinterrupted by drbdadm pause-sync.
VerifyS. On-line device verification is currently running,with the local node being the source ofverification.
VerifyT. On-line device verification is currently running,with the local node being the target ofverification.
5 DRBD角色
DRBD detects split brain at the time connectivity becomes available again and the peer nodes exchange the initial DA resource's role canbe observed either by monitoring/proc/drbd, or by issuing the drbdadm role command:
drbdadm role resource
Primary/Secondary
The local resource role is always displayed first, the remoteresource role last.
You may see one of the following resource roles:
Primary. The resource is currently in the primary role, and may be read from and written to. This role only occurson one of the two nodes, unless dual-primary node is enabled.
Secondary. The resource is currently in the secondary role. It normally receives updates from its peer (unless running in disconnected mode), but may neither be read from nor written to. This role may occur on one node or both nodes.
Unknown. The resource's role is currently unknown. The local resource role never has this status. It is only displayed for the peer's resource role, and only in disconnected mode.
6 DRBD磁盘状态
A resource's disk state can be observed either bymonitoring /proc/drbd, or by issuing thedrbdadm dstate command:
drbdadm dstate resource
UpToDate/UpToDate
The local disk state is always displayed first, the remote disk state last.
Both the local and the remote disk state may be one of thefollowing:
Diskless. No local block device has been assigned to theDRBD driver. This may mean that the resource has neverattached to its backing device, that it has beenmanually detached using drbdadm detach, or that it automatically detachedafter a lower-level I/O error.
Attaching. Transient state while reading meta data.
Failed. Transient state following an I/O failure report bythe local block device. Next state: Diskless.
Negotiating. Transient state when an Attach is carried out onan already-connected DRBD device.
Inconsistent. The data is inconsistent. This status occursimmediately upon creation of a new resource, on bothnodes (before the initial full sync). Also, thisstatus is found in one node (the synchronizationtarget) during synchronization.
Outdated. Resource data is consistent, but outdated.
DUnknown. This state is used for the peer disk if no networkconnection is available.
Consistent. Consistent data of a node without connection. Whenthe connection is established, it is decided whetherthe data are UpToDate or Outdated.
UpToDate. Consistent, up-to-date state of the data. This isthe normal state.
7 要点
1)DRBD在同步的过程中,节点的角色可以进行切换,不影响同步的过程。
2)安装完DRBD后在DRBD节点进行同步前,可以事先对主从机的DRBD磁盘分区进行格式化,这样在同步的时候,会加快同步速度,但是格式化操作不能在创建资源以前进行,否则会造成资源创建不成功。















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









