







本次实战采取爬取糗事百科的段子
首先找到糗事百科的网址:http://www.qiushibaike.com/

我们这次打算爬取文字模块。其网址部分是http://www.qiushibaike.com/text/
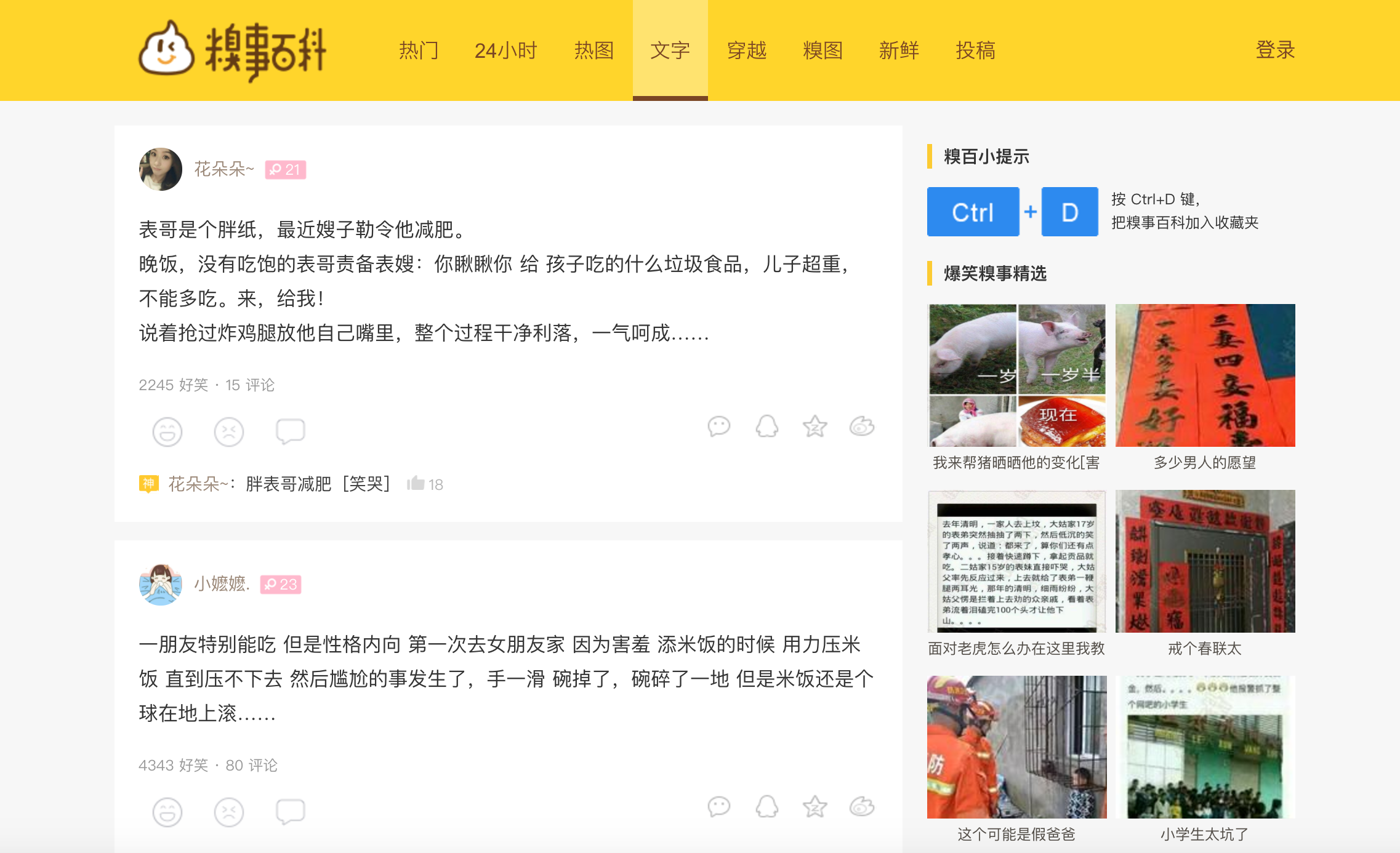
然后去找到总共有多少页。打开审查元素,选择左上角的箭头,选择网页上的元素
可以看到
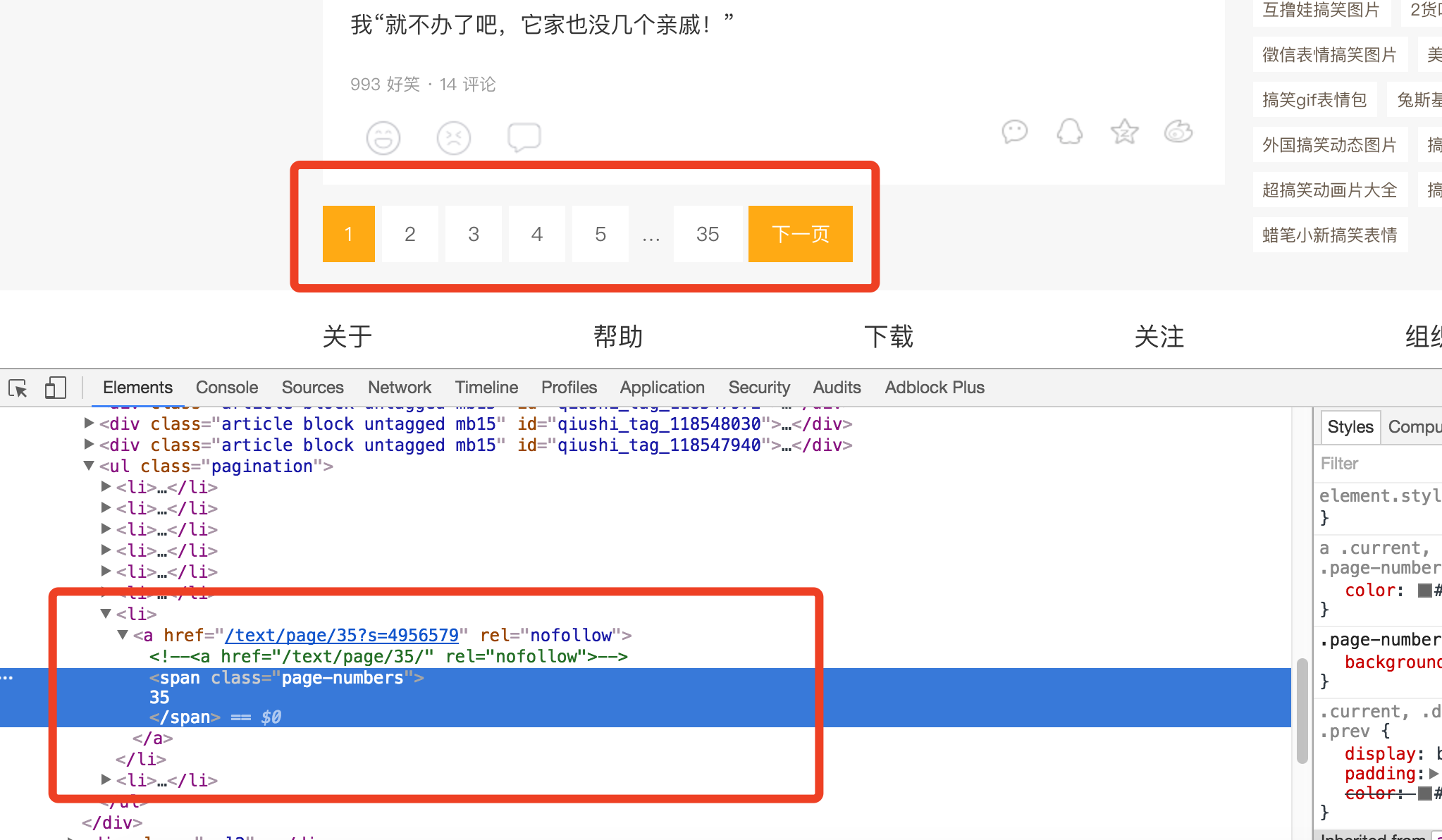
我们所需要的元素都在li标签下的span内,这对我们之后写正则表达式起到关键的作用。
再仔细观察每页的网址,如第2页, 第8页,第35页等,可以发现一个规律

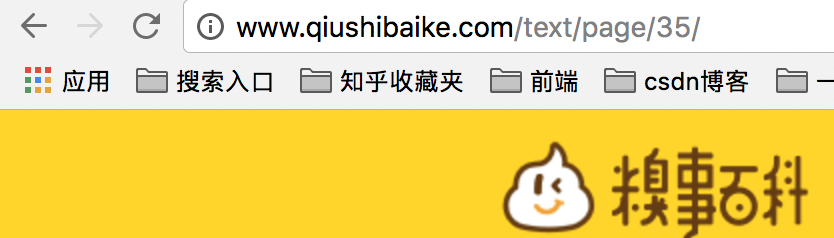

即所有页面的规律符合http://www.qiushibaike.com/text/page/X/ (对第一页同样成立)
结合以上所有的信息,我们可以编写出我们的Python 爬虫
# -*- coding: utf-8 -*-
import re
from bs4 import BeautifulSoup
import requests
import random
# ----------- 处理页面上的各种标签 -----------
class HTML_Tool:
# 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
BgnCharToNoneRex = re.compile("(\t|\n| |<a.*?>|<img.*?>)")
# 用非 贪婪模式 匹配 任意<>标签
EndCharToNoneRex = re.compile("<.*?>")
# 用非 贪婪模式 匹配 任意<p>标签
BgnPartRex = re.compile("<p.*?>")
CharToNewLineRex = re.compile("(<br/>|</p>|<tr>|<div>|</div>)")
CharToNextTabRex = re.compile("<td>")
# 将一些html的符号实体转变为原始符号
replaceTab = [("<", "<"), (">", ">"), ("&", "&"), ("&", "\""), (" ", " ")]
def Replace_Char(self, x):
x = self.BgnCharToNoneRex.sub("", x)
x = self.BgnPartRex.sub("\n ", x)
x = self.CharToNewLineRex.sub("\n", x)
x = self.CharToNextTabRex.sub("\t", x)
x = self.EndCharToNoneRex.sub("", x)
for t in self.replaceTab:
x = x.replace(t[0], t[1])
return x
class Qiubai_Spider:
# 申明相关的属性
def __init__(self, url):
self.user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
self.iplist=[]
response = requests.get('http://haoip.cc/index/2061578.htm')
ips = BeautifulSoup(response.text, 'lxml').find_all('tr')
# print ips
for ip in ips:
# print ip.find('td').get_text().strip()
self.iplist.append(ip.find('td').get_text().strip())
UA=random.choice(self.user_agent_list)
print UA
header={'User-Agent':UA}
html=requests.get(url,header)
contents=BeautifulSoup(html.text,'lxml').find_all('span',class_="page-numbers")[-1].get_text()
print contents
for i in range(1,int(contents)+1):
self.myUrl = url +'page/'+str(i)
print self.myUrl
self.datas = []
self.myTool = HTML_Tool()
self.find_title(self.myUrl)
print u'已经启动糗事百科爬虫,咔嚓咔嚓'
def find_title(self, myPage):
# 匹配 <h1 class="core_title_txt" title="">xxxxxxxxxx</h1> 找出标题
# myMatch = re.search(r'<h3.*?>(.*?)</h3>', myPage, re.S)
page_html=requests.get(myPage)
contents=BeautifulSoup(page_html.text,'lxml').find_all('div',class_="content")
for content in contents:
# pattern=re.compile('<span>(.*?)</span>',re.S)
# items=re.findall(pattern,content)
# for item in items:
# title = content.replace('\\', '').replace('/', '').replace(':', '').replace('*', '').replace('?', '').replace('"','').replace(
# '>', '').replace('<', '').replace('|', '')
# print content
text=content.find('span').get_text().replace('\\', '').replace('/', '').replace(':', '').replace('*', '').replace('?', '').replace('"','').replace(
'>', '').replace('<', '').replace('|', '')
print (text+'\n\n')
# return title
# -------- 程序入口处 ------------------
print u"""#---------------------------------------
# 程序:糗事百科爬虫
"""
bdurl = 'http://www.qiushibaike.com/text/'
mySpider = Qiubai_Spider(bdurl)
结果为
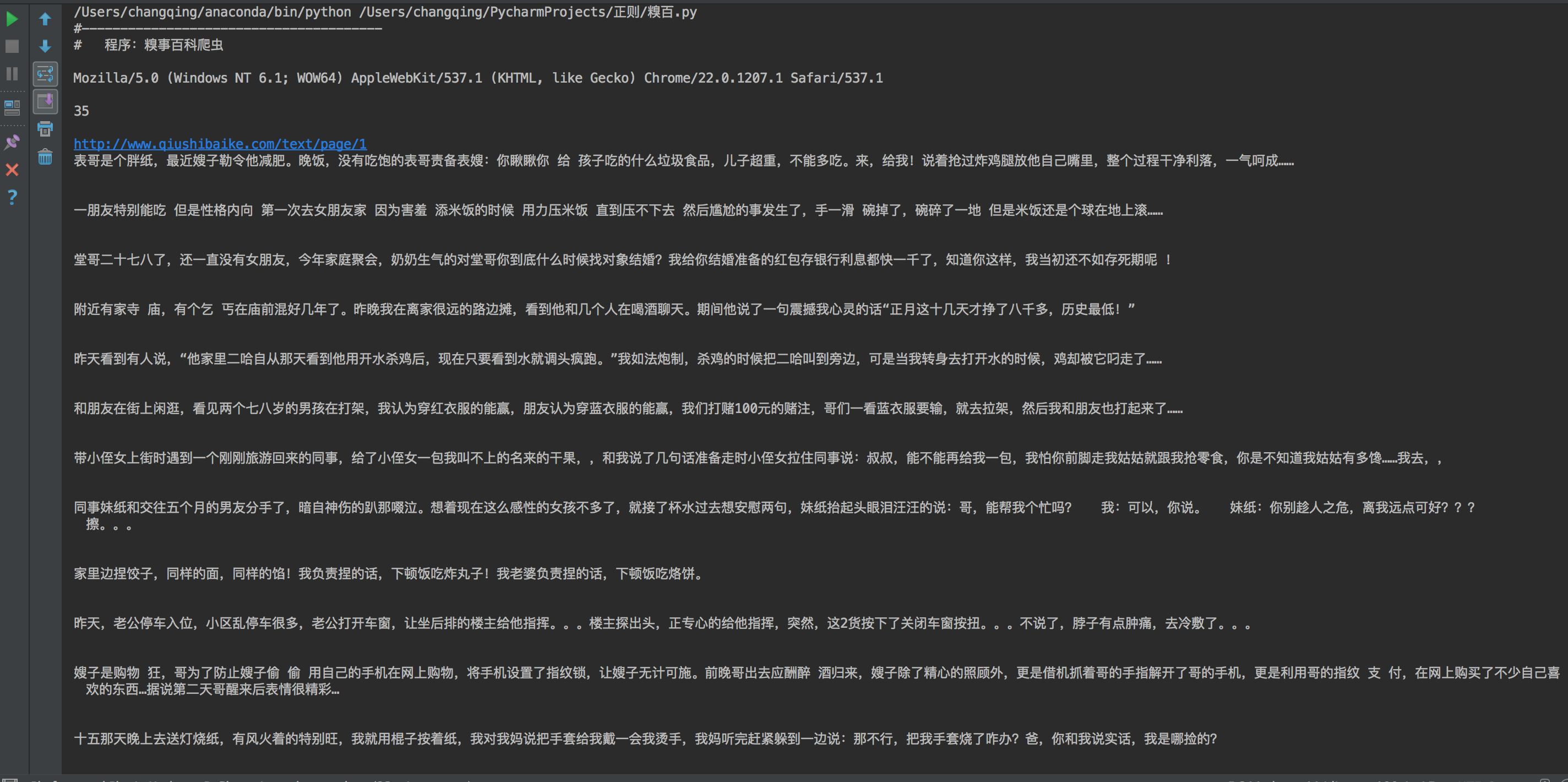
当然还有很大的完善空间,比如或保存,以及代理设定,timeout等,不过现在得去上课(哎),以后会完善















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









