










第七章 KubeSphere3.3.0 + MySQL8.0.29 单节点部署
前言
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一(来源百度百科),官网地址:https://www.mysql.com/。本文内容采用 KubeSphere3.3.0 + MySQL8.0.29 单节点部署方式。
一、创建配置文件
选择一个项目进入:
1、配置基本信息

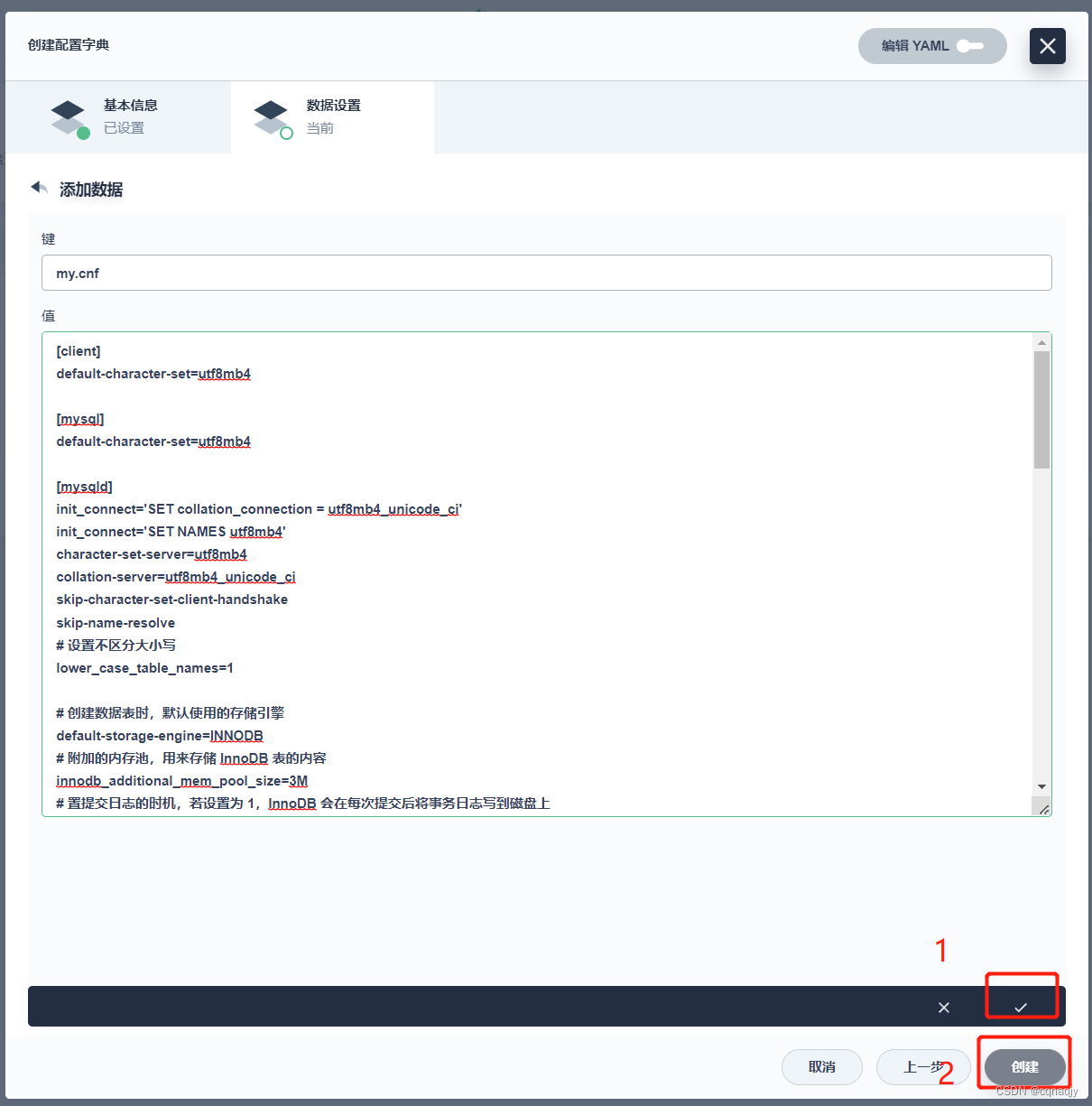
2、配置数据设置
精简版:
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
init_connect='SET collation_connection = utf8mb4_unicode_ci'
init_connect='SET NAMES utf8mb4'
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
lower_case_table_names=1
#开启binlog日志
#当前为单个节点,随机设置一个ID的值
server-id=1
log-bin=mysql-bin
binlog-format=Row
# 日志存储天数一个月
binlog_expire_logs_seconds=2626560
# 解决导入脚本时function报错问题
log_bin_trust_function_creators=1
增强版:
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
init_connect='SET collation_connection = utf8mb4_unicode_ci'
init_connect='SET NAMES utf8mb4'
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
# 设置不区分大小写
lower_case_table_names=1
# 创建数据表时,默认使用的存储引擎
default-storage-engine=INNODB
# 附加的内存池,用来存储 InnoDB 表的内容
innodb_additional_mem_pool_size=3M
# 置提交日志的时机,若设置为 1,InnoDB 会在每次提交后将事务日志写到磁盘上
innodb_flush_log_at_trx_commit=1
# 来存储日志数据的缓存区的大小
innodb_log_buffer_size=2M
# 缓存的大小,InnoDB 使用一个缓冲池类保存索引和原始数据
innodb_buffer_pool_size=107M
# 日志文件的大小
innodb_log_file_size=54M
# 在 InnoDB 存储引擎允许的线程最大数
innodb_thread_concurrency=18
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
# 回收空闲连接的时间
wait_timeout = 86400
# 允许同时访问 MySQL 服务器的最大连接数。其中一个连接是保留的,留给管理员专用的
max_connections=100
# 数据库 写入的 数据包 最大值
max_allowed_packet = 512M
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=10
# 查询时的缓存大小,缓存中可以存储以前通过 SELECT 语句查询过的信息,再次查询时就可以直接从缓存中拿出信息,可以改善查询效率
query_cache_size=0
# 所有进程打开表的总数
table_cache=256
# 内存中每个临时表允许的最大大小
tmp_table_size=35M
# 缓存的最大线程数
thread_cache_size=8
# MySQL 重建索引时所允许的最大临时文件的大小
myisam_max_sort_file_size=100G
# 重建索引时的缓存大小
myisam_sort_buffer_size=69M
# 关键词的缓存大小
key_buffer_size=55M
# MyISAM 表全表扫描的缓存大小
read_buffer_size=64K
#将排序好的数据存入该缓存中
read_rnd_buffer_size=256K
#用于排序的缓存大小
sort_buffer_size=256K
#开启binlog日志
#当前为单个节点,随机设置一个ID的值
server-id=1
log-bin=mysql-bin
binlog-format=Row
# 日志存储天数
expire_logs_days=7
# 解决导入脚本时function报错问题
log_bin_trust_function_creators=1
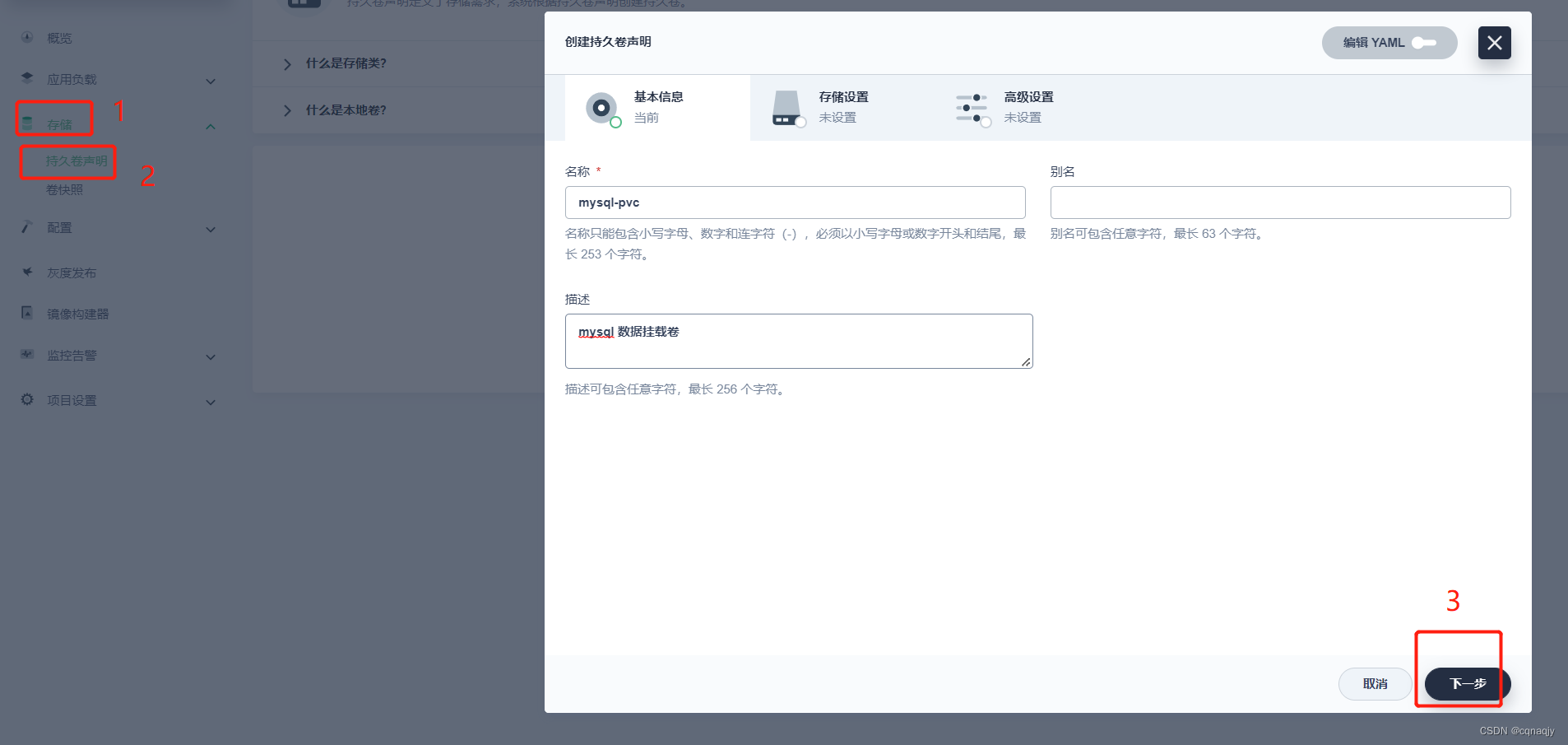
二、创建存储卷
1、创建存储卷PVC基本信息
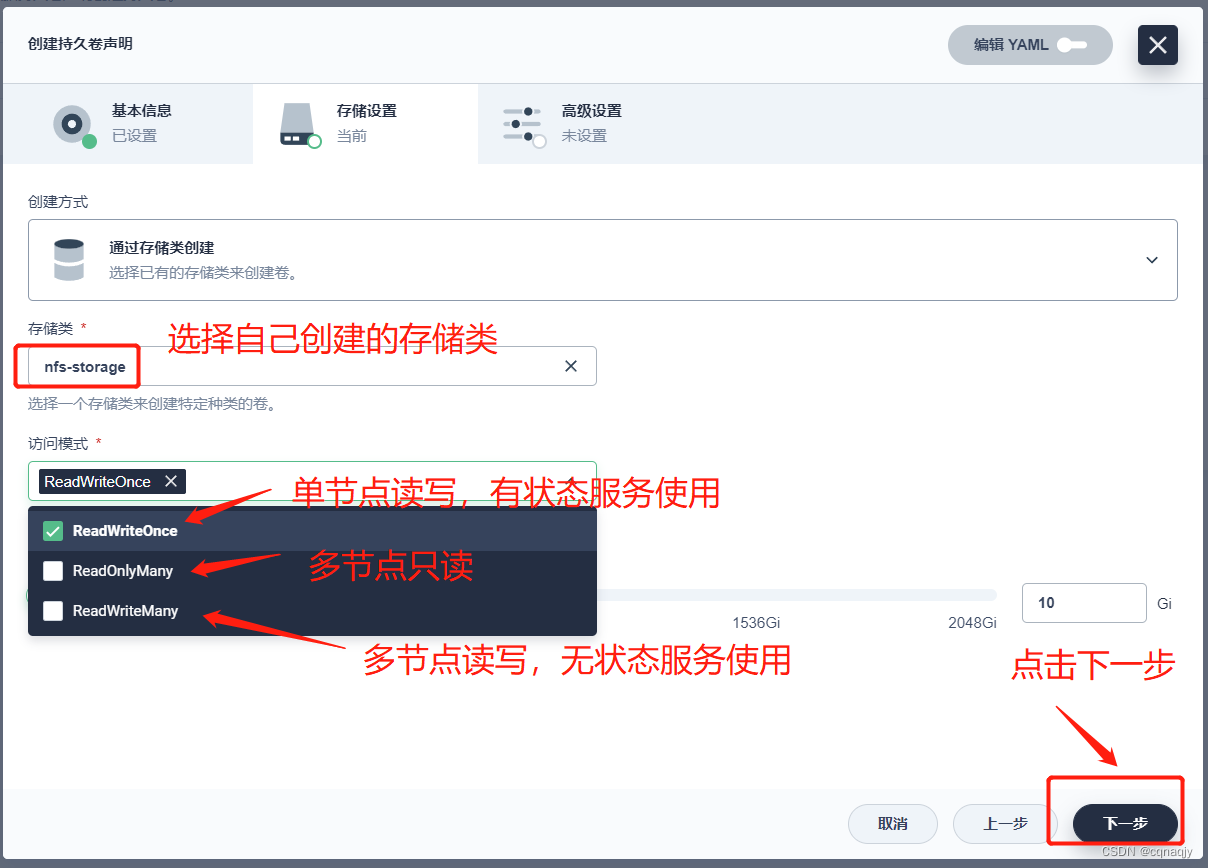
2、配置存储设置及创建
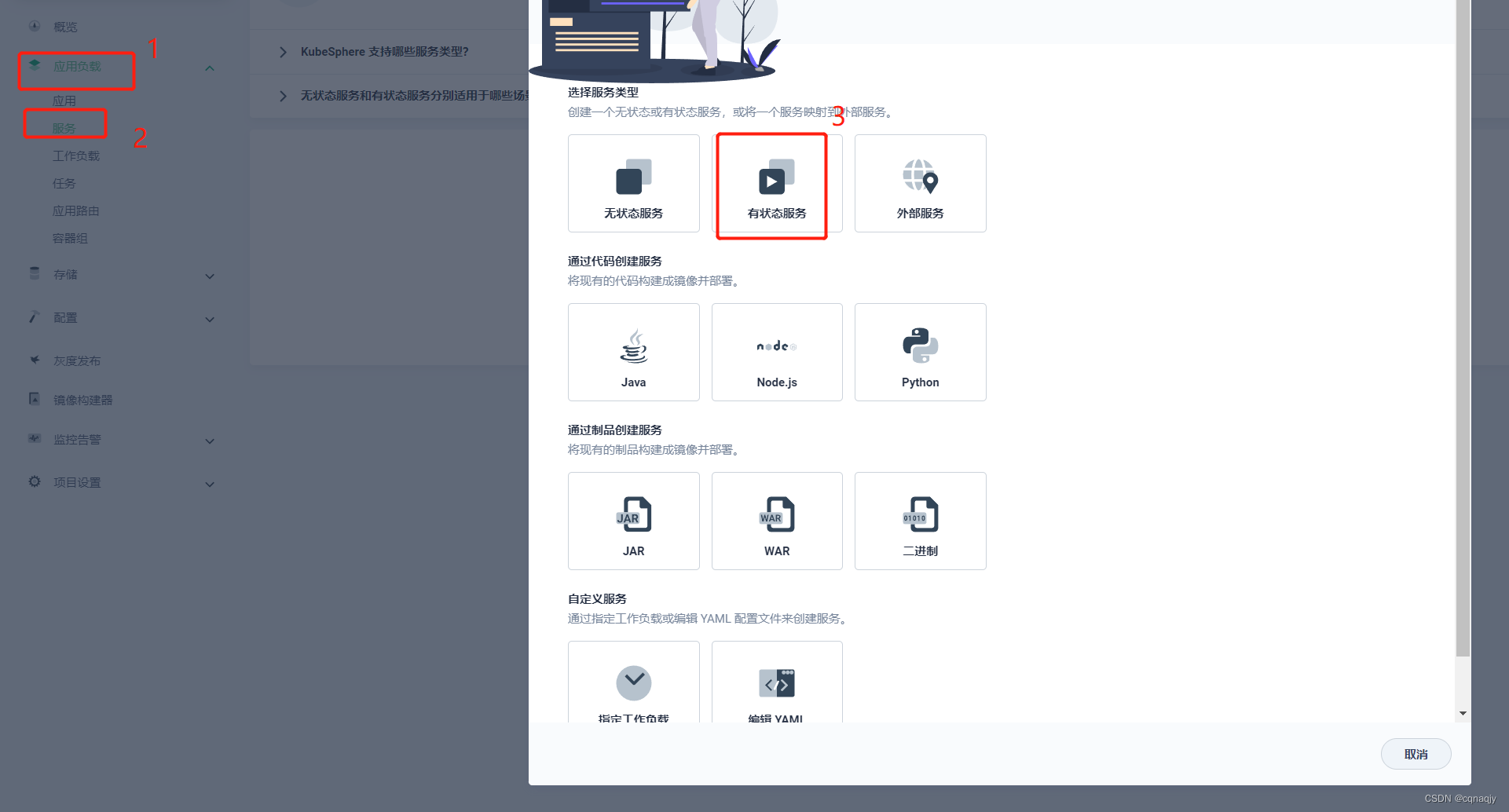
三、创建MySQL有状态服务
1、选择有状态服务
2、配置基础信息
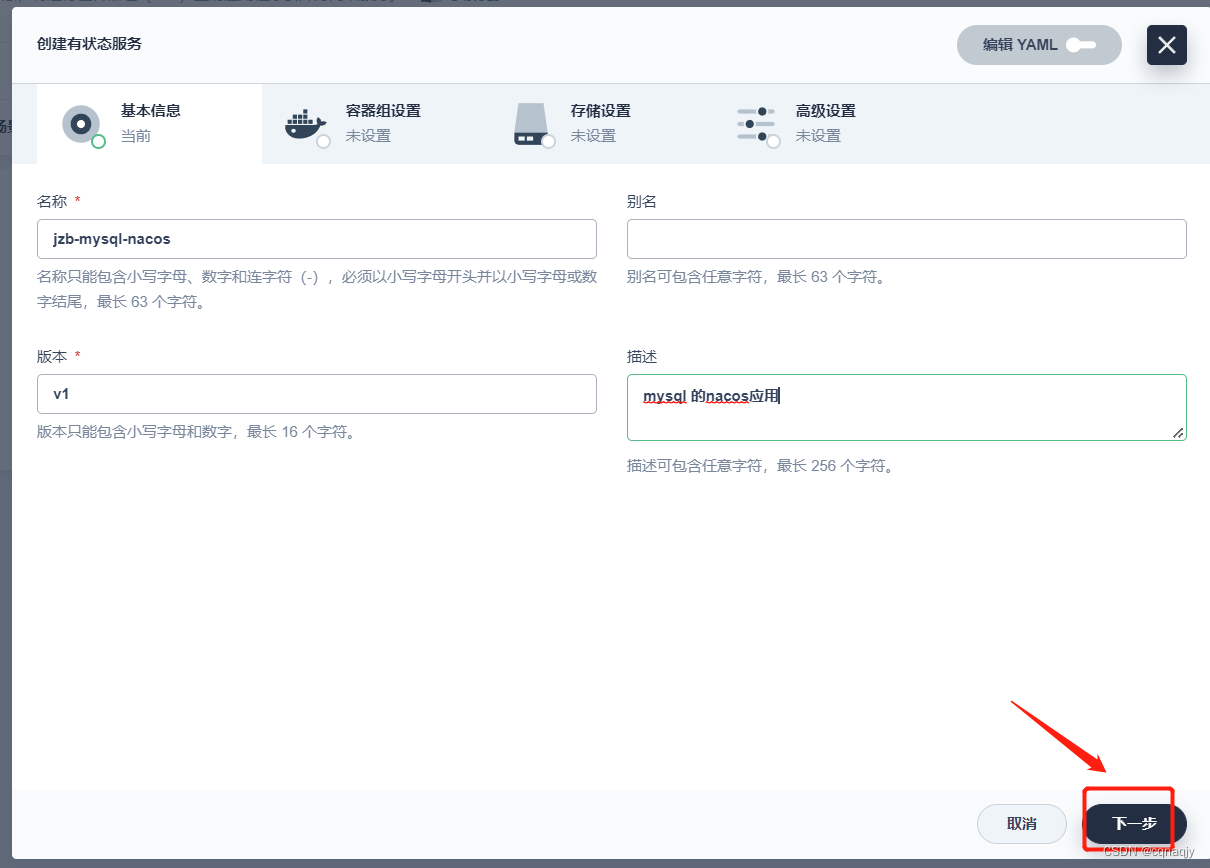
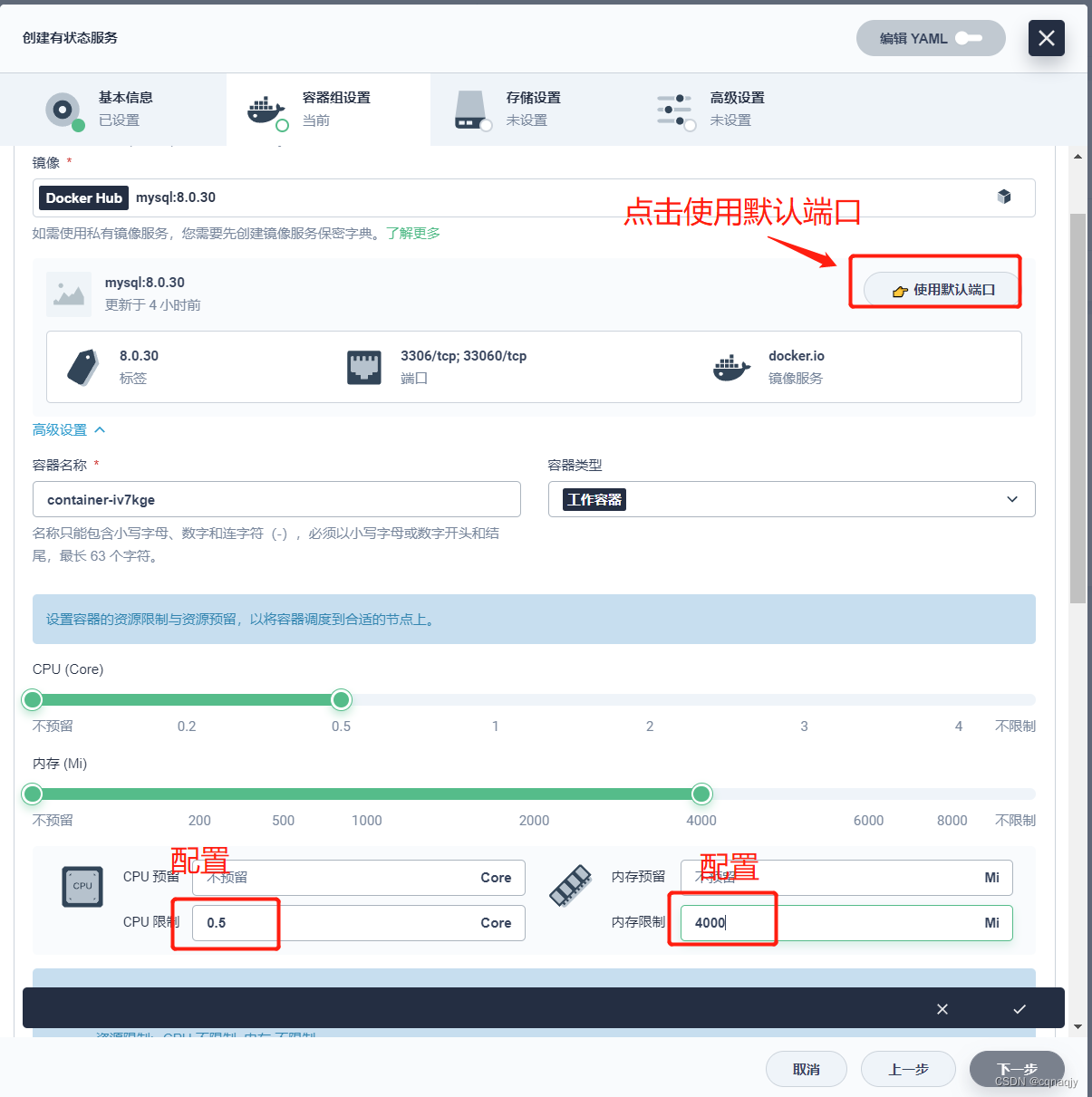
3、配置容器组
提示:这里只能选择1个副本,多个副本就变成集群模式
选择镜像: mysql:8.0.29
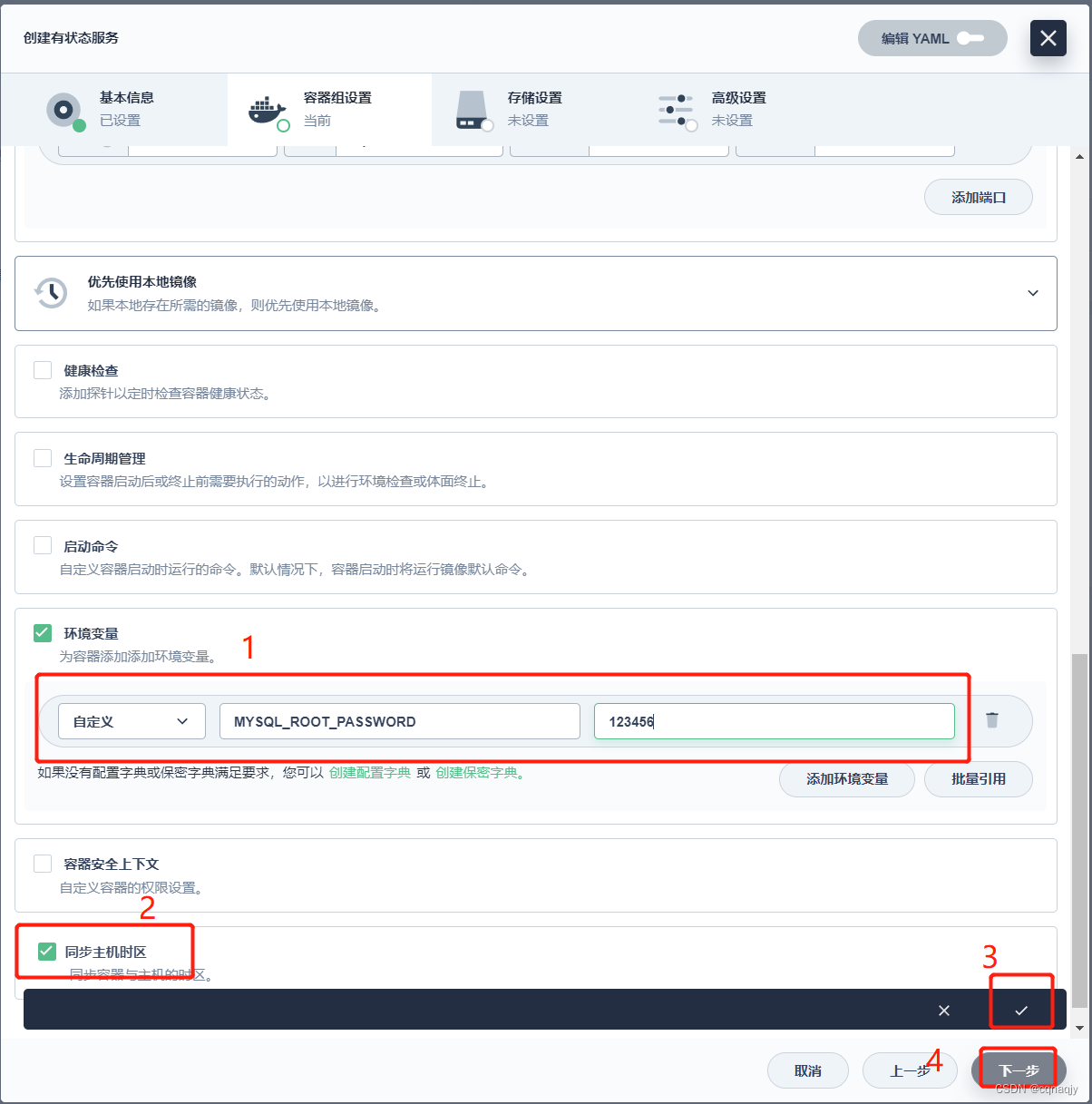
配置环境变量:
键:MYSQL_ROOT_PASSWORD
值:123456
3、配置存储
提示:如果提前没有配置PVC存储卷,这里可以点击添加持久卷声明模板临时创建
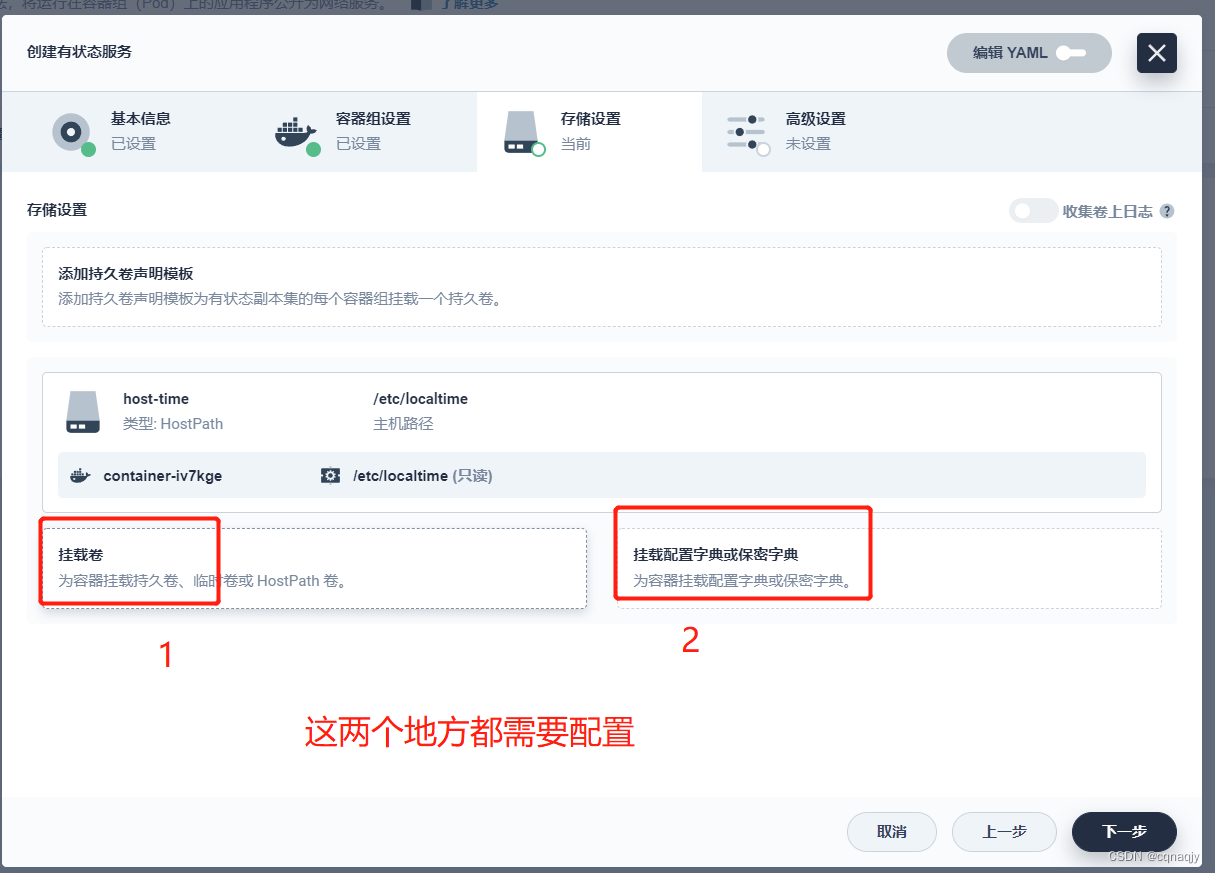
- 存储卷
挂载路径:/var/lib/mysql
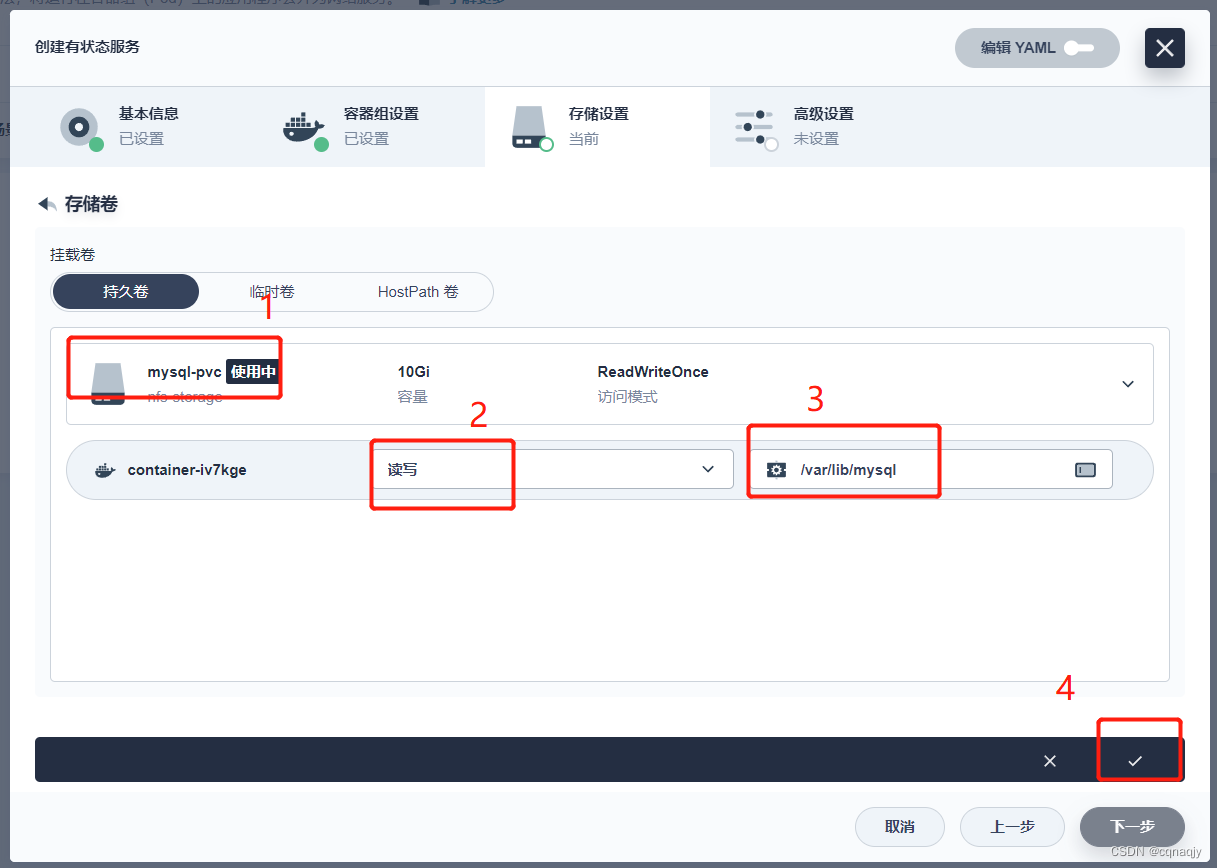
- 挂载配置文件
挂载地址:/etc/mysql/conf.d
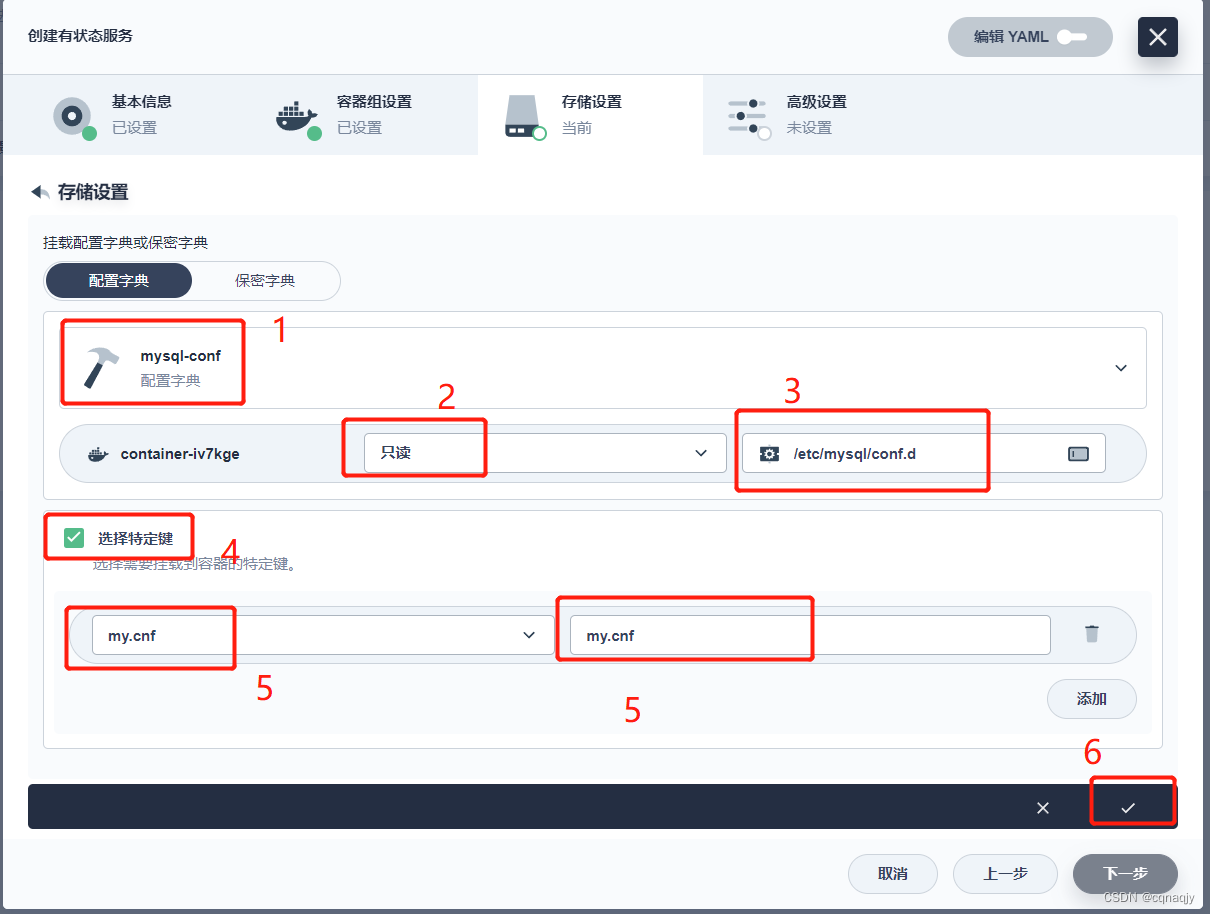
4、服务创建完成

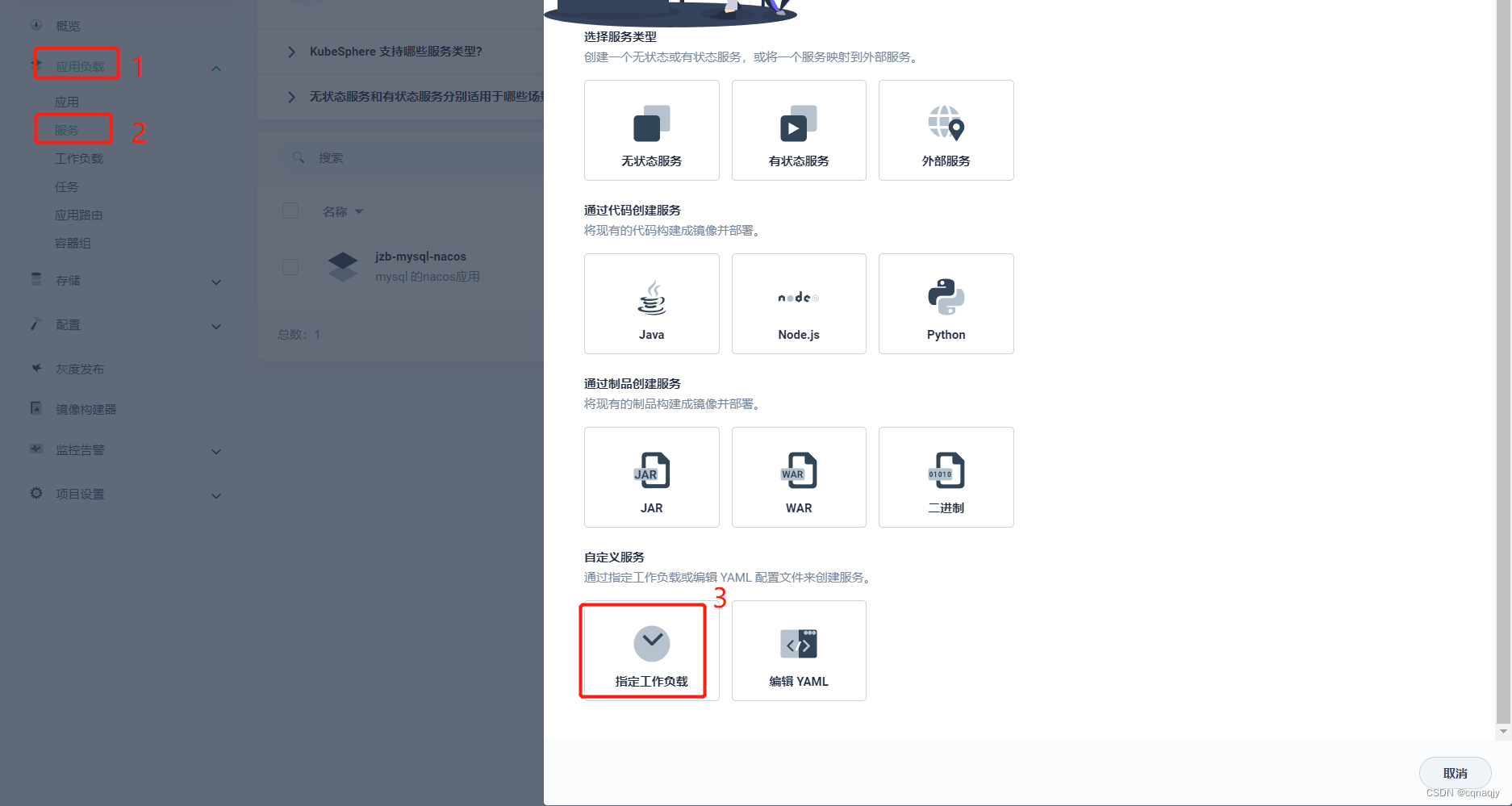
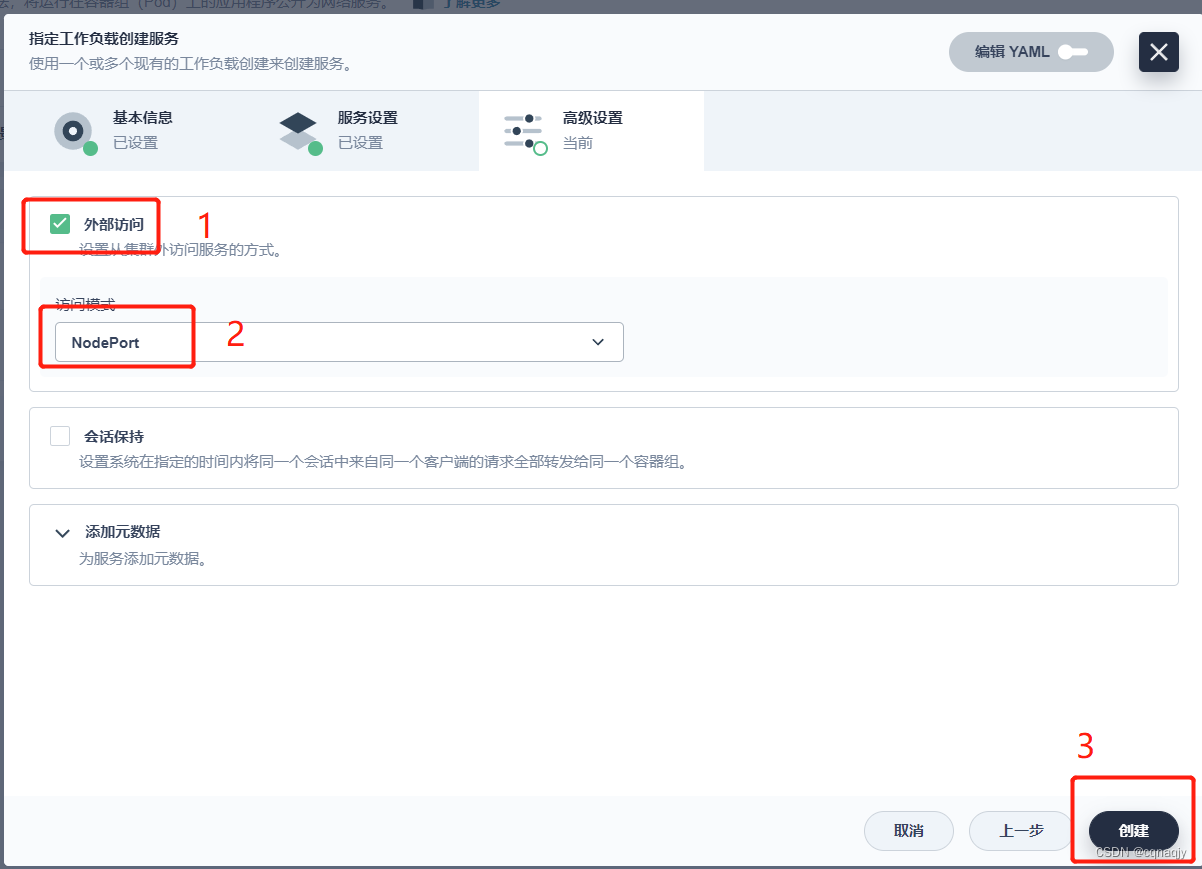
四、开启外网访问端口
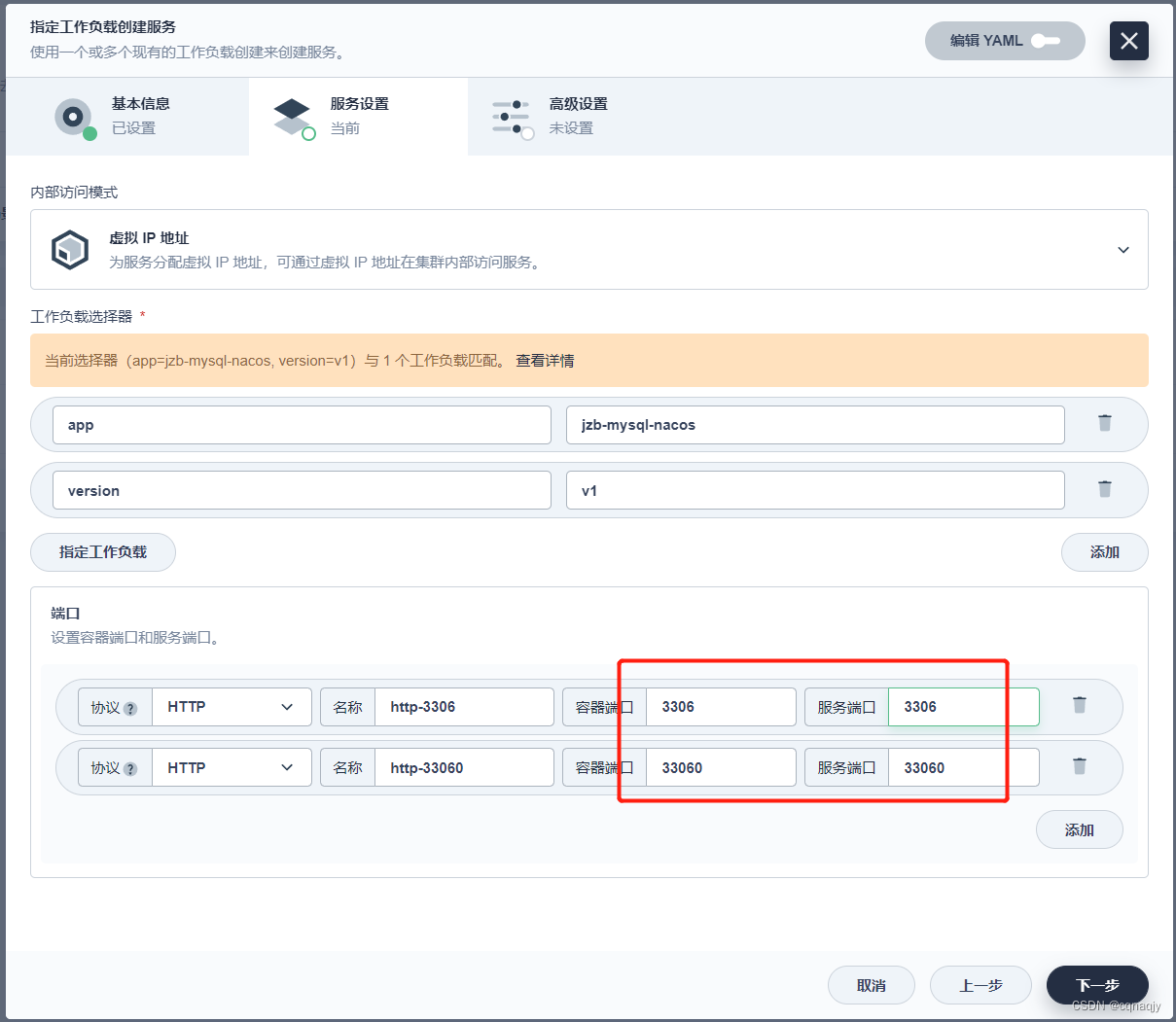
1、指定工作负载
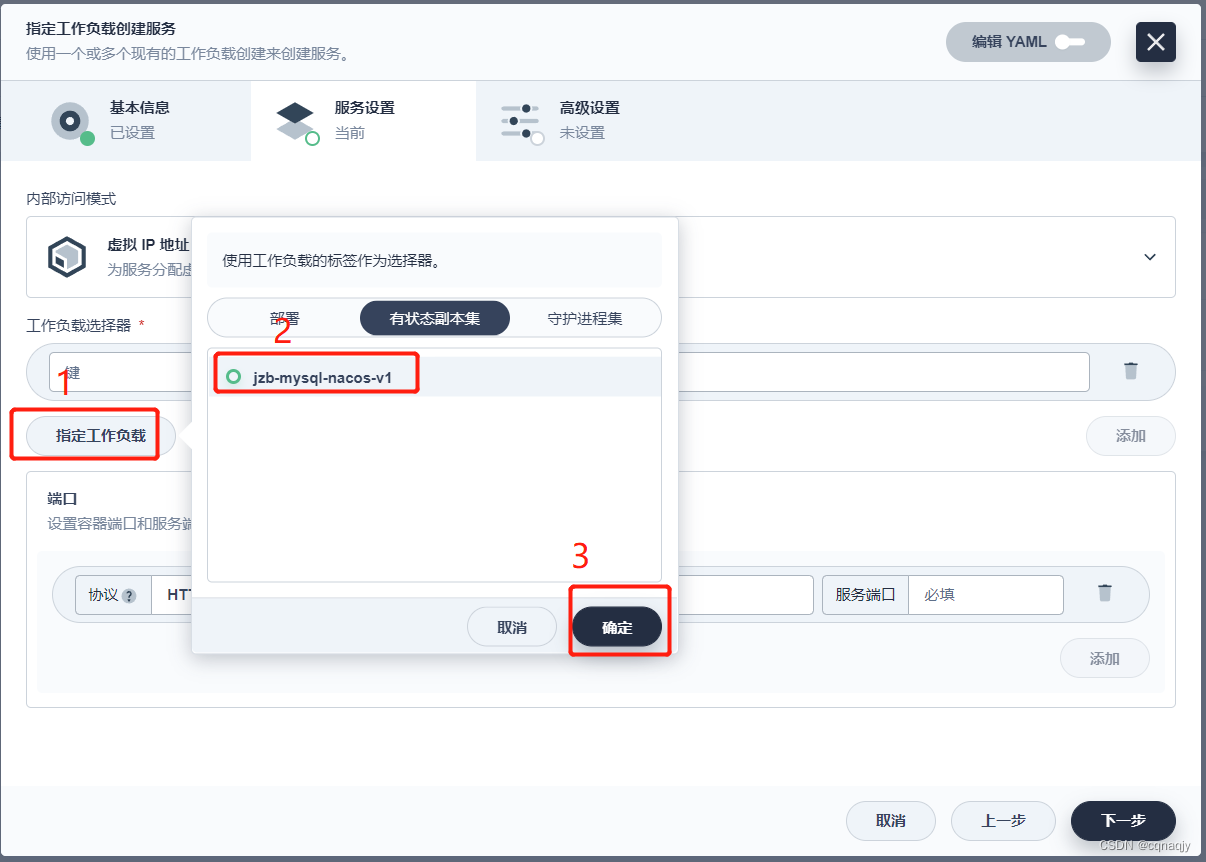
2、配置端口
端口:3306 、33060

五、总结
至此,关于使用KubeSphere3.3.0管理平台搭建一个MySQL单节点部署到这里就结束了。作者制作不易,别忘了点赞、关注、加收藏哦,我们下期见。。。
六、其他文章传送门
第一章 KubeSphere 3.3.0 + Seata 1.5.2 + Nacos 2.1.0 (nacos集群模式)
第二章 KubeSphere3.3.0 + Nacos 2.1.0 (集群部署)
第三章 KubeSphere3.3.0 + Sentinel 1.8.4 + Nacos 2.1.0 集群部署
第四章 KubeSphere3.3.0 + Redis7.0.4 + Redis-Cluster 集群部署
第五章 KubeSphere3.3.0 + MySQL8.0.25 集群部署
第六章 KubeSphere3.3.0 安装部署 + KubeKey2.2.1(kk)创建集群
第七章 KubeSphere3.3.0 + MySQL8.0 单节点部署
第八章 KubeSphere3.3.0 + Redis7.0.4 单节点部署
第九章 KubeSphere3.3.0 + Nacos2.1.0 单节点部署
第十章 KubeSphere3.3.0 + FastDFS6.0.8 部署
第十一章 KubeSphere3.4.1 + MinIO:2024.3.15 部署
















 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









