







实验目的:
本实验要求通过requests和re第三方库用于爬取b站的弹幕并保存为txt文件。
爬取网站:
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=767237785'实验操作环境:
电脑操作环境为Window10系统,采用python3.9并利用Pycharm IDE进行爬虫相关操作。
第三方库版本:
requests: 2.28.1
fake_useragent:1.2.1
实验步骤:
导入相关库:
import requests # 用于发送HTTP请求
import re # 导入正则表达式库,用于文本解析
from fake_useragent import UserAgent # 用于随机生成随机User-Agent生成请求头:
利用UserAgent生成随机请求头:
# 设置请求的URL
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=767237785'
headers = {'user-agent': UserAgent().random} # 设置请求的URL发送请求:
r = requests.get(url, headers=headers) # 请求发送
# 查看请求结果
print(r.text)结果:

分析:可以看出出现乱码,因此下一步进行编码转换。
# 编码转换
r.encoding = 'utf-8'
# 输出结果
print(r.text)结果如下:其中红色为我们需要爬取的内容: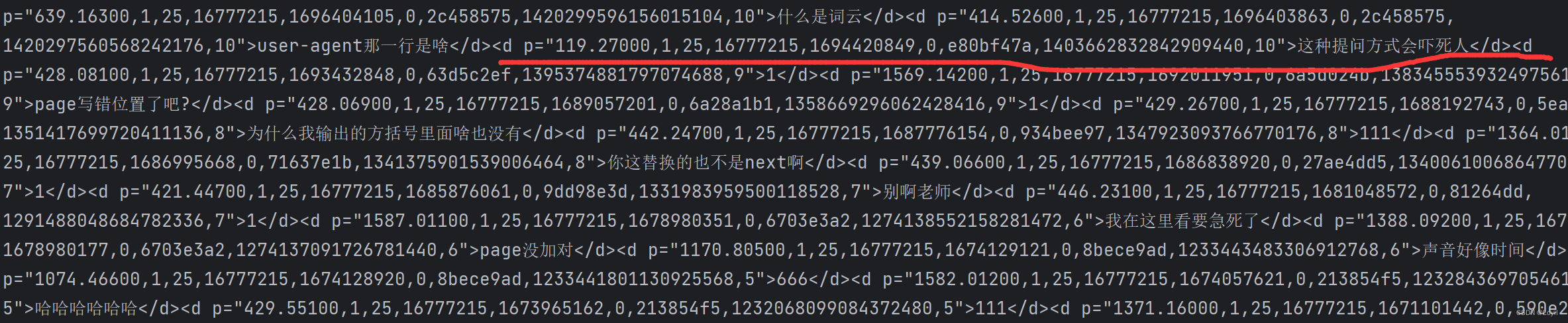
解析文本数据:
以下".*?"为正则化表达式,用于匹配以上红线元素p内容,()括号内同理,其为我们需要爬取的内容。
# 使用正则表达式解析响应文本,获取所有匹配的内容
content_list = re.findall('<d p=".*?">(.*?)</d>', r.text) 文档写入:
注意提前创建"弹幕.txt"文件。
# 将解析的数据写入文件
for content in content_list: # 遍历解析得到的内容列表
# 以追加模式打开文件,编码方式为UTF-8
with open('弹幕.txt', 'a', encoding='utf-8') as f:
f.write(content) # 将内容写入文件
f.write('\n') # 在内容后添加换行符 文档内容如下:
















 2333
2333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









