







角色规划
一个节点在默认情况会下同时扮演:master eligible,data node 和 ingest node。

在生产环境中建议每个节点只承担一个角色:
-
Dedicated master eligible nodes:负责分片管理,索引创建,集群管理等操作,使用低配置的 CPU,RAM 和磁盘。
-
Dedicated data nodes:负责数据存储及处理客户端请求,使用高配置的 CPU, RAM 和磁盘。
-
Dedicated ingest nodes:负责数据处理,使用高配置 CPU,中等配置的RAM,低配置的磁盘。
-
Dedicate coordinating only node (client node):扮演Load Balancers,降低master和data nodes的负载,负责搜索结果的Gather/Reduce。使用高/中等配置 CPU,高/中等配置的RAM,低配置的磁盘。

节点间数据加密
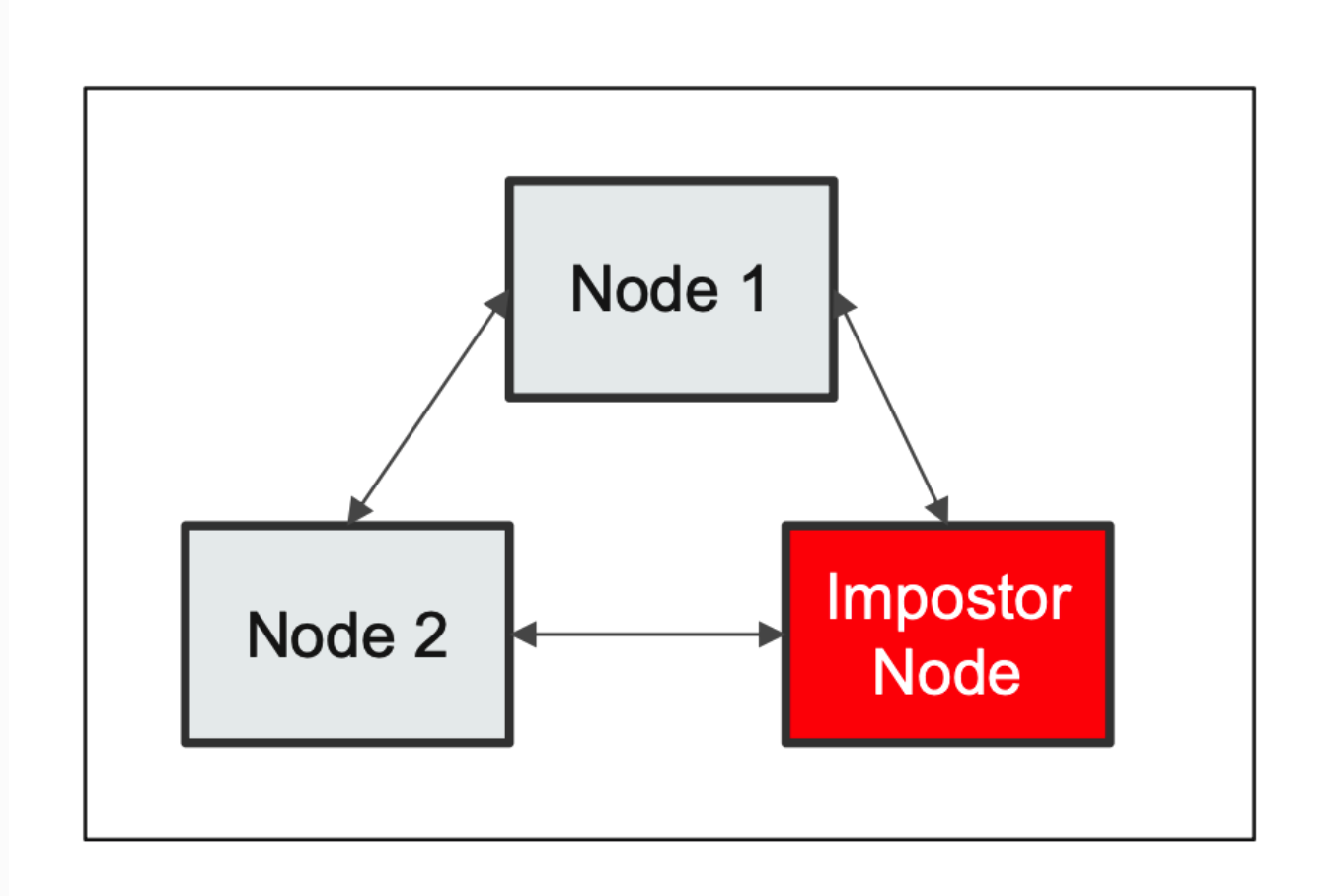
- 加密数据 ,避免数据抓包,敏感信息泄漏。
- 验证身份 ,避免 Impostor Node。
#生成CA
bin/elasticsearch-certutil ca
#签名证书
bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12
#elasticsearch.yml配置
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12
主节点选举
从高可用 & 避免脑裂的角度出发,一般在生产环境中配置3台master节点。
在新版7.0的es中,对es的集群发现系统做了调整,不再有discovery.zen.minimum_master_nodes这个控制集群脑裂的配置,转而由集群自主控制,并且新版在启动一个新的集群的时候需要有cluster.initial_master_nodes初始化集群列表。在集群初始化第一次完成选举后,应当删除cluster.initial_master_nodes配置。
discovery.seed_hosts: ["master1","master2","master3"] #master-eligible节点
cluster.initial_master_nodes: ["master1"] #初始化选举的master节点
架构设计

-
当系统中有大量的复杂查询及聚合时候,增加 Coordinating 节点,增加查询的性能。
-
当磁盘容量无法满足需求时或者磁盘读写压力大时,可以增加数据节点。
-
读写分离:配置LB负载均衡写请求到Ingest节点,读请求到Coordinating节点。

-
Kibana部署在每台Coordinating上,同样使用LB做流量分发。
Hot & Warm 架构
Hot 节点(通常使用 SSD):索引有不断有新文档写入,通常使用 SSD。

Warm 节点(通常使用 HDD):索引不存在新数据的写入,同时也不存在大量的数据查询。

实现原理,借助Elasticsearch的分片分配策略:
- 第一:集群节点层面支持规划节点类型,这是划分热暖节点的前提。
- 第二:索引层面支持将数据路由到给定节点,这为数据写入冷、热节点做了保障。
在 Elastic Stack 6.6 版本后推出了新功能 Index Lifecycle Management(索引生命周期管理),支持针对索引的全生命周期托管管理,并且在 Kibana 上也提供了一套UI界面来配置策略。
例如这里配置了一条IML策略:
- 当docs数超过5000时进行rollover操作。
- 20天后进入warm阶段,索引只读。
- 40天后进入cold阶段,副本分片缩减为0。
- 60天后进入delete阶段,删除索引。
PUT /_ilm/policy/log_ilm_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_docs": 5000
}
}
},
"warm": {
"min_age": "20d",
"actions": {
"allocate": {
"include": {
"box_type": "warm"
}
},
"readonly": {}
}
},
"cold": {
"min_age": "40d",
"actions": {
"allocate": {
"include": {
"box_type": "cold"
},
"number_of_replicas": 0
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
}
}
}
Rack Awareness

Elasticsearch的节点可能分布在不同的机架,当一个机架断电时,可能会丢失几个节点。如果一个索引相同的主分片和副本分片同时在这个机架上,就有可能导致数据的丢失。通过Rack Awareness的机制,就可以尽可能避免将同一个索引的主副分片分配在一个机架的节点上。
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "rack",
"cluster.routing.allocation.awareness.force.rack.values": "rack1,rack2"
}
}
系统配置
文件描述符
Elasticsearch使用大量的文件描述符(文件句柄)。用完文件描述符可能是灾难性的,并极有可能导致数据丢失。确保将运行Elasticsearch的用户打开文件描述符的数量限制增加到65,536或更高。
编辑/etc/security/limits.conf文件,设置打开的文件句柄数:
elasticsearch - nofile 65535
通过该命令查看Elasticsearch每个节点所能使用的最大文件描述符数量:
GET _nodes/stats/process?filter_path=**.max_file_descriptors
禁用swap
swap对节点的性能和稳定性非常不利,swap可能导致GC持续几分钟而不是几毫秒,还可能导致节点响应缓慢,甚至断开与集群的连接。
sudo swapoff -a #并将/etc/fstab 文件中包含swap的行注释掉。
也可以通过在 elasticsearch.yml 中设置 bootstrap.memory_lock: true,以保持 JVM 锁定内存,保证 Elasticsearch 的性能。
虚拟内存
Easticsearch 对各种文件混合使用了 NioFs( 非阻塞文件系统)和 MMapFs ( 内存映射文件系统)。请确保配置的最大映射数量,以便有足够的虚拟内存可用于 mmapped 文件。
编辑/etc/sysctl.conf文件:
vm.max_map_count=262144
线程数
Elasticsearch对不同类型的操作使用许多线程池,能够在需要时创建新线程很重要。确保Elasticsearch用户可以创建的线程数至少为4096。
elasticsearch - nproc 4096
JVM
- 将内存 Xms 和 Xmx 设置成一样,避免 heap resize 时引发停顿。
- Xmx 设置不要超过物理内存的 50%,单个节点上,最大内存建议不要超过 32 G 内存。

-
OS Cache: Lucene 中的倒排索引 segments 存储在文件中,为提高访问速度,都会把它加载到OS Cache中,从而提高 Lucene 性能,所以建议至少留系统一半内存给Lucene。
-
Node Query Cache:负责缓存filter 查询结果,每个节点有一个,被所有 shard 共享,filter query查询结果不涉及 scores 的计算。
-
Indexing Buffe:索引缓冲区,用于存储新索引的文档,当其被填满时,缓冲区中的文档被写入磁盘中的 segments 中。
-
Shard Request Cache: 用于缓存aggregations,suggestions,hits.total的请求结果。
-
Field Data Cache:Elasticsearch 加载内存 fielddata 的默认行为是延迟加载 。在首次对text类型字段做聚合、排序或者在脚本中使用时,需要设置字段为fielddata数据结构,它将会完整加载这个字段所有 Segment 中的倒排索引到堆内存中。不推荐使用,因为fielddata会占用大量堆内存空间 ,聚合或者排序使用doc_value。
硬件配置
搜索等性能要求高的场景,建议 SSD,按照 1 :10 的比例配置内存和硬盘。
日志类和查询并发低的场景,可以考虑使用机械硬盘存储,按照 1:50 的比例配置内存和硬盘。
单节点数据建议控制在 2 TB 以内,最大不建议超过 5 TB。
大多数的ES集群对于CPU要求都不高,一般2C~8C的配置都可以,具体CPU数根据业务场景来。
ES JVM heap 最大建议不要超过 32 G 内存 ,30G heap 大概能处理的数据量 10T,其余都给OS cache,标准的建议是分50%的机器内存给JVM,剩余给OS cache,或可适当将OS cache比例上调。
资源预估
- 通过数据量预估磁盘容量
腾讯云在2019年4月的 meetup 分享中建议:磁盘容量大小 = 原始数据大小 * 3.38。假设一条文档数据1K,预计数据量有1亿条,那么就有100G的原始数据大小,磁盘占用上可能就会有300多G的内容(存储倒排索引,行存和列存等)。
- 通过搜索吞吐率预估系统配置
Lucene引擎非常依赖底层的File System Cache,搜索如果需要达到ms级响应,那就需要有足够的内存去缓存大部分的索引数据。 比如10亿级文档数,300G数据总量,假设用到5台数据服务器,8C64G,内存总量大小为300G,其中150G分给JVM堆内存,剩余150G分给OS cache,操作系统用掉了50G大小,那么剩余100G的OS cache可以用于存储索引数据,大约会有30%的概率是基于OS cache做磁盘索引文件的读写,平均响应差不多会在亚秒级~秒级。
分片与副本
分片大小
为什么要控制分片存储大小?
- 提高 Update 的性能。
- Merge 时,减少所需的资源。
- 丢失节点后,具备更快的恢复速度 / 便于分片在集群内 Rebalancing。
日志类应用,单个分片不要大于 50 GB;搜索类应用,单个分片不要超过20 GB。
分片数量
为什么要控制分片的数量?
- 每个分片是一个 Lucene 的 索引,会使用机器的资源。过多的分片会导致额外的性能开销。
- 分片的 Meta 信息由 Master 节点维护。过多,会增加管理的负担。
一个很好的经验法则是:确保每个节点的分片数量保持在低于每1GB堆内存对应集群的分片在20-25之间。分片总数在控制在10W以内。
合理设置主分片数,确保均匀分配在所有数据节点上。 限定每个索引在每个节点上可分配的主分片数:
PUT my_index
{
"settings": {
"routing.allocation.total_shards_per_node": 2
}
}
#5 个节点的集群。 索引有 5 个主分片,1 个副本,应该如何设置?
#(5+5)/5=2
索引设计
Mapping 是定义文档和字段的字段的存储和索引方式的过程(类似于Mysql里的表结构设计),一般会从如下角度去设计与优化:

Mapping 字段的相关设置:
-
enabled – 设置成 false,仅做存储,不支持搜索和聚合分析 (数据保存在 _source 中)
-
index – 是否构倒建排索引。设置成 false,无法被搜索,但还是支持 aggregation,并出现在 _source
中。
-
index_options: 控制将哪些信息添加到倒排索引中,以进行搜索和高亮显示。它接受以下设置:docs | freqs | posistions | offsets。
-
norms – 如果字段⽤用来过滤和聚合分析,可以关闭,节约存储。
-
doc_values – 是否启用 doc_values,⽤用于排序和聚合分析。
-
fielddata – 如果要对 text 类型启用排序和聚合分析, fielddata 需要设置成true
-
store – 默认不存储,数据默认存储在 _source。
-
coerce – 默认开启,是否开启数据类型的自动转换(例如,字符串转数字)。
-
fields 多字段特性。
-
dynamic – true / false / strict 控制 Mapping 的自动更新。
Elasticsearch != 关系型数据库。尽可能 Denormalize 数据,从而获取最佳的性能,使用 Nested 类型的数据,查询速度会慢几倍。使用 Parent / Child 关系,查询速度会慢几百倍。
读写优化
写入优化
Translog
默认 translog 是每 5 秒被 fsync 刷新到硬盘。如果ES有大量的写请求会导致频繁IO影响性能,在允许数据丢失情况(极低概率,断电或宕机等故障)可以调低translog的刷盘频率、提高落盘文件的大小和周期、并改用异步方式来提升写的性能:
PUT my-index/_settings
{
"translog.flush_threshold_size": "1gb", #默认512M,当 translog 超过该值,会触发 flush
"translog.sync_interval": "60s", #默认5s
"translog.durability": "async" #默认是 request,每个请求都落盘,忽视translog.sync_interval。设置成 async,异步写入,根据index.translog.sync_interval参数的间隔时间做fsync。
}
Refresh_interval
默认情况下,ES每一秒会refresh一次,产生一个新的segment,这样会导致产生的 segment较多,segment merge较为频繁,系统开销增大。如果对数据的实时查询性要求较低,可以通过下面的命令提高refresh的时间间隔,降低系统开销:
PUT my-index/_settings
{
"refresh_interval": "60s" #默认1s
}
Index Buffer
默认是10%,这意味着分配给一个节点的总堆栈的10%将用作所有分片共享的索引缓冲区大小,用满会导致自动触发refresh,可以通过编辑elasticsearch.yml文件,调整配置参数适当调大:
indices.memory.index_buffer_size: 20% #默认10%
Merge并发控制
Lucene会不断地把一些小的segment合并成一个大的segment,合并时并发线程数默认值是Math.max(1, Math.min(4, <<node.processors, node.processors>> / 2)),当节点配置的cpu核数较高时,merge占用的资源可能会偏高,影响集群的性能,可以通过下面的命令调整某个index的merge过程的并发度:
PUT my-index/_settings
{
"merge.scheduler.max_thread_count": 2
}
Dynamic Mapping
建议关闭dynamic index:
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": false
}
}
#或者设置白名单
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "logstash-*,kibana*"
}
}
Bulk
-
单个 bulk 请求体的数据量不要太大,官方建议大约5-15mb。
-
写入端的 bulk 请求超时需要足够长,建议60s以上。
-
写入端尽量将数据轮询打到不同节点。
-
客户端批量写入数据时尽量使用下面的bulk接口批量写入,提高写入效率:
POST _bulk {"index":{"_index":"test"}} {"field1":"value1"} {"index":{"_index":"test"}} {"field2":"value2"} {"index":{"_index":"test"}} {"field3":"value3"}
写入数据不指定_id,让ES自动产生
如果用户显示指定id写入数据时,ES会先发起查询来确定index中是否已经有相同id的doc存在,若有则先删除原有doc再写入新doc,这样每次写入时,ES都会耗费一定的资源做查询。如果不 指定就直接跳过查询直接随机id入库,性能可快一倍。
Routing
对于数据量较大的index,一般会配置多个shard来分摊压力。这种场景下,一个查询会同时搜索所有的shard,然后再将各个shard的结果合并后,返回给用户。对于高并发的小查询场景,每个分片通常仅抓取极少量数据,此时查询过程中的调度开销远大于实际读取数据的开销,且查询速度取决于最慢的一个分片。开启routing功能后,ES会将routing相同的数据写入到同一个分片中(也可以是多个,由index.routing_partition_size参数控制)。如果查询时指定routing,那么ES只会查询routing指向的那个分片,可显著降低调度开销,提升查询效率。
PUT my_index/_doc/1?routing=user1&refresh=true
{
"title": "This is a document"
}
GET my_index/_doc/1?routing=user1
分片设定
副本在写入时设为 0,完成后再增加。
PUT my-index/_settings
{
"number_of_replicas": 0
}
查询优化
使用query-bool-filter组合取代普通query
默认情况下,ES通过一定的算法计算返回的每条数据与查询语句的相关度,并通过_score字段来表征。但对于非全文索引的使用场景,用户并不care查询结果与查询条件的相关度,只是想精确的查找目标数据。此时,可以通过query-bool-filter组合来让ES不计算_score,并且尽可能的缓存filter的结果集,供后续包含相同filter的查询使用,提高查询效率。
# 普通query查询
GET my-index/_search
{
"query": {
"term": {
"user": {
"value": "kimchy"
}
}
}
}
# query-bool-filter 加速查询
GET my-index/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"user": "kimchy"
}
}
]
}
}
}
禁用通配符开始的正则表达
通配符开头的正则,性能非常糟糕,需避免使用。
GET my-index/_search
{
"query": {
"wildcard": {
"user": {
"value": "*imchy"
}
}
}
}
避免查询时脚本
避免使用script查询,例如这里想查询userlist列表中元素个数等于3的doc:
#避免使用script查询
GET my-index/_search
{
"query": {
"script": {
"script": "doc['userlist.keyword'].length==3"
}
}
}
可以在 Index 文档时,使用 Ingest Pipeline,计算并写入user_length用于记录userlist列表中元素的个数,需要查询的时候直接查询user_length。
#定义pipline
PUT _ingest/pipeline/my-pipline
{
"description": "score user length",
"processors": [
{
"script": {
"lang": "painless",
"source": "ctx.user_length = ctx.userlist.length" #添加user_length字段
}
}
]
}
#在插入数据时使用pipline
POST my-index/_doc?pipeline=my-pipline
{
"userlist": ["user1","user2","user3"]
}
欢迎关注
















 2181
2181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









