







 本文详细介绍了如何在Python环境中安装和配置Tesseract OCR,包括下载安装Tesseract,设置环境变量,解决安装Tesserocr时遇到的问题,以及通过代码验证安装是否成功。在安装过程中,重点强调了添加TESSDATA_PREFIX环境变量和处理安装错误的方法。
本文详细介绍了如何在Python环境中安装和配置Tesseract OCR,包括下载安装Tesseract,设置环境变量,解决安装Tesserocr时遇到的问题,以及通过代码验证安装是否成功。在安装过程中,重点强调了添加TESSDATA_PREFIX环境变量和处理安装错误的方法。
Tesserocr 是 Python 的一个 OCR 识别库,但其实是对 Tesseract 做的一层 Python API 封装,所以它的核心是 Tesseract,所以在安装 Tesserocr 之前我们需要先安装 Tesseract,本文用来记录安装流程以及安装过程中遇到的一些问题和处理方式。
第一步,下载 Tesseract
Tesseract为 Tesserocr 提供了支持,下载链接为:http://digi.bib.uni-mannheim.de/tesseract/。这里我直接下载的最新版:(注意其中文件名中带有 dev 的为开发版本,不带 dev 的为稳定版本,可以选择下载不带 dev 的版本。)
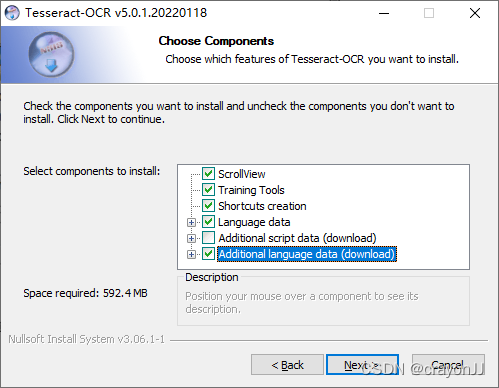
下载完成后双击运行,按照提示一步步next就行,如果想要提前多下载一些语言,则需要勾选Additional language data(download),但是如果勾选了该选项也会增加安装耗时,自己根据需要选择(笔者因为要用到多国语言识别,所以勾选了该选项):
之后就是漫长的等待安装下载过程~
第二步:添加环境变量
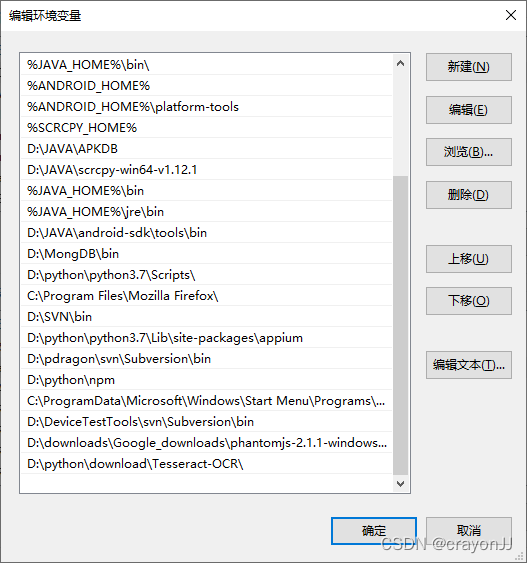
1,下载完成后,复制安装路径,我的安装路径是D:\python\download\Tesseract-OCR,打开电脑系统属性→高级→环境变量,在path下新建Tesseract-OCR的环境变量,添加之后,记得所有确定都点击!
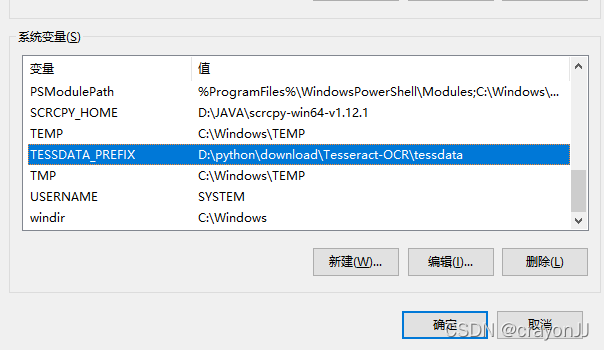
2,增加一个TESSDATA_PREFIX变量名,变量值为我的语言字库文件夹安装路径F:\Tesseract-OCR\tessdata 添加到变量中;如下图:
如果没有添加TESSDATA_PREFIX的变量,执行命令会出现如下错误:

第三步:安装Tesserocr
这里在直接使用pip安装时,总是出错:
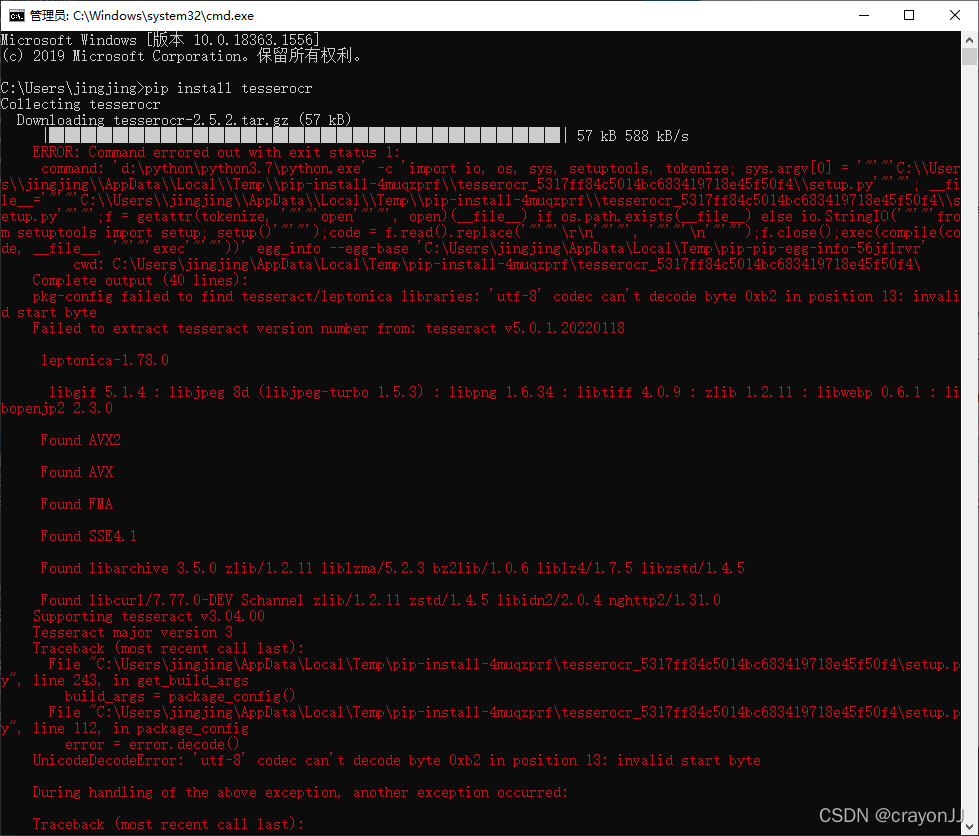
于是采取镜像安装的方法:先在whl下载地址(https://github.com/simonflueckiger/tesserocr-windows_build/releases)下载和自己python版本以及电脑操作系统对应的whl文件,比如笔者是python3.7,64位操作系统,就应该下载如下版本:
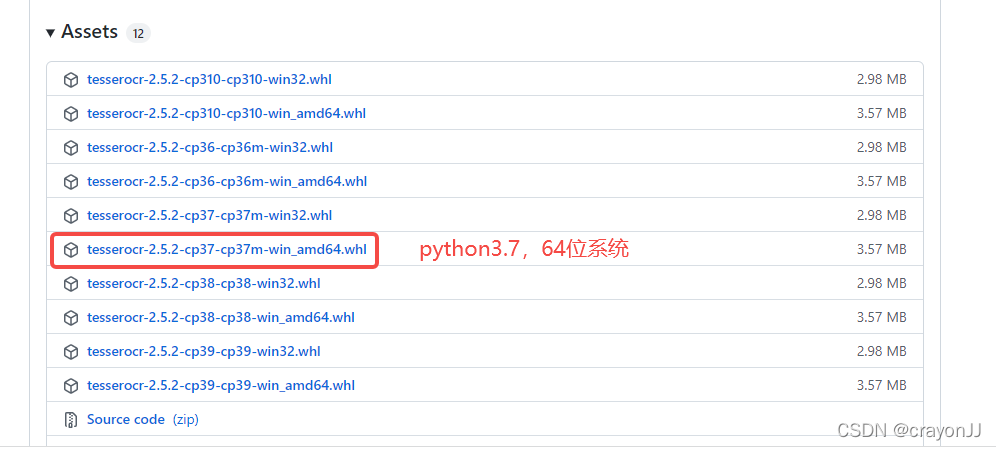
然后再pip install 镜像文件地址,镜像文件可以直接拖入install后面,即可迅速安装成功:

第四步,代码验证安装成功
我随便截了张图作为样例图片进行测试:

代码如下:
import tesserocr
from PIL import Image
image = Image.open('test.jpg')
print(tesserocr.image_to_text(image))
结果出现如下报错:
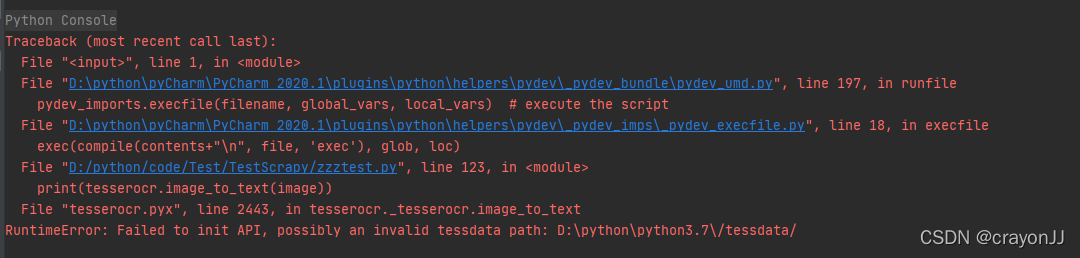
解决方法:打开报错的位置,D:\python\python3.7,没有tessdata文件才报错,于是将原本D:\python\download\Tesseract-OCR\tessdata路径下的tessdata文件复制到改路径下:
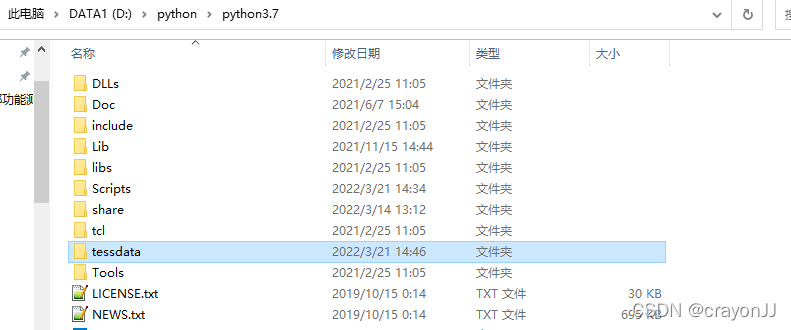
然后再次运行代码,就可以成功识别到文字啦:
参考链接:https://segmentfault.com/a/1190000039929696
https://blog.csdn.net/moxiao1995071310/article/details/82630996

















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









