






文法产生式如下:
E->TE'
E'->+TE'|空
T->FT'
T'->*FT'|空
F->(E)|i
非递归实现,必须使用一个栈来完成。
总体思路:根据栈顶符号和输入串的的当前符号,来决定下一步的动作。如果栈顶是一个终结符,那么尝试将该终结符和输入串的的当前符号进行匹配,如果栈顶是一个非终结符,则查找LL(1)分析表,如果找到了某个产生式,则产生式左部符号出栈,右部符号逆序进栈(参照陈意云的编译原理教材)。程序中N表示空串。
#include <stack>
#include <map>
#include <string>
#include <vector>
#include <iomanip>
#include <iostream>
using namespace std;
#define VtNum 5
#define VnNum 5
#define ProNum 13
#define MaxSrcLength 20 //输入串最大长度
struct Table
{
string leftAndCurChar; //产生式左部符号和当前输入串符号。用string,不用char,可以直接存放、处理E'和T’
vector<string> right; //产生式右部,T和E'分别存在两个string中,一起放入vector
}; //T和E'如果连在一起存放成一个string TE',将来要分割出文法符号T和E',会比较困难。
int IsVt(const string vt[], string x, int n); //判断x是否是终结符
void Print(stack<string> s); //打印栈
void Print(const string& src, int i); //打印输入串
void Print(const string& left, const vector<string>& right); //打印产生式
void Error();
int main()
{
//终结符集合
const string vt[VtNum] = { "i","+","*","(",")" };
//非终结符集合
const string vn[VnNum] = { "E","E'","T","T'","F" };
//LL(1)分析表,如果这个表的规模大,可以动态申请内存,等会把这个表的内容存放到map之后,可以delete申请的内存
Table table[ProNum] = {
{"Ei",{"T","E'" }}, //E和i的交叉位置有一个产生式E->TE'
{"E(",{"T","E'"}},
{"E'+",{"+","T","E'"}},
{"E')",{"N"}},
{"E'$",{"N"}},
{"Ti",{"F","T'"}},
{"T(",{"F","T'"}},
{"T'+",{"N"}},
{"T'*",{"*","F","T'"}},
{"T')",{"N"}},
{"T'$",{"N"}},
{"Fi",{"i"}},
{"F(",{"(","E",")"}}
};
//用map存储LL(1)分析表,如果map的底层实现是hash表,那么查找LL(1)表的时间复杂度是O(1),和表的大小规模无关。
//如果是sorted map,那么查找的时间复杂度是O(log2N),此处N=13。
map<string, vector<string>> table_map; //string:E和i(Ei一起作为key) vector<string>:T和E'
for (int i = 0; i < ProNum; i++)
{
table_map.insert(pair<string, vector<string>>(table[i].leftAndCurChar, table[i].right));
}
//开始分析
string src = "i*i+i*i+i+i$";
stack<string> s;
s.push("$");
s.push("E");
string x; //栈顶符号,例如E
string a; //当前输入串符号,例如i
string xa; //例如Ei
int i = 0;
int step = 0;
//输出“输入串”时,占MaxSrcLength宽度
cout << "步骤" << "\t\t" << "栈" << "\t\t" << setw(MaxSrcLength) << "输入串" << "\t\t" << "动作" << endl;
cout << step++ << "\t\t";
Print(s);
Print(src, i);
cout << endl;
bool flag = true;
while (flag)
{
cout << step++ << "\t\t";
x = s.top(); //E
a = string(1, src[i]); //i
xa = x + a; //Ei
s.pop();
if (IsVt(vt, x, VtNum))
{
if (x == a)
{
i++;
a = src[i];
Print(s);
Print(src, i);
cout << endl;
}
else
Error();
}
else if (x == "$")
{
if (x == a)
{
cout << "accept!" << endl;
flag = false;
}
else
Error();
}
else if (table_map.contains(xa))
{
vector<string> right = table_map[xa];
if (right.at(0) != "N") //不是空产生式
{
for (int i = right.size() - 1; i >= 0; i--)
{
s.push(right.at(i));
}
}
Print(s);
Print(src, i);
Print(x, right);
}
else
{
Error();
}
}
return 0;
}
int IsVt(const string vt[], string x, int n)
{
for (int i = 0; i < n; i++)
{
if (vt[i] == x)
{
return 1;
}
}
return 0;
}
void Print(stack<string> s)
{
vector<string> reverse; //逆序存放原来的stack
while (s.size() > 0)
{
reverse.push_back(s.top());
s.pop();
}
for (int i = reverse.size() - 1; i >= 0; i--)
{
cout << reverse.at(i);
}
cout << "\t\t";
}
void Print(const string& src, int i)
{
string temp(src.length() - i, ' ');
for (unsigned int j = i, k = 0; j < src.length(); j++, k++)
temp[k] = src[j];
cout << right << setw(MaxSrcLength) << temp; //输出“输入串”时,右对齐,占MaxSrcLength宽度
cout << "\t\t";
}
void Print(const string& left, const vector<string>& right)
{
cout << left << "->";
for (unsigned int i = 0; i < right.size(); i++)
{
cout << right.at(i);
}
cout << endl;
}
void Error()
{
cout << "error!" << endl;
exit(-1);
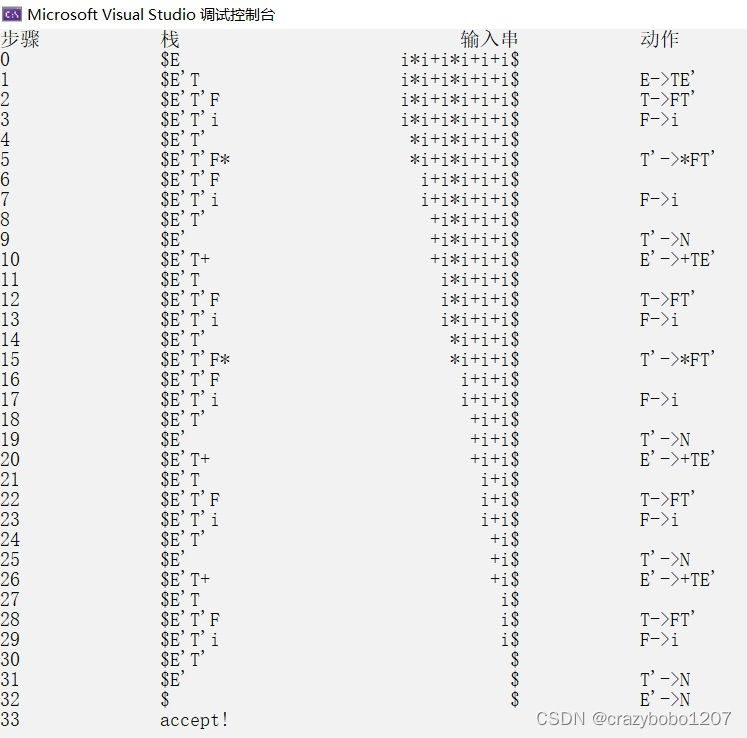
}运行结果如下,其中N表示空串。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









