









 文章介绍了一个Python函数,该函数能够接受含有表格数据的字符串,将其转换为PandasDataFrame。这样,用户可以直接从Excel复制数据,而无需查找和读取文件路径。函数考虑了存在或不存在表头的情况,并允许指定列分隔符。测试显示,无论是否有表头,函数都能正确转换数据。
文章介绍了一个Python函数,该函数能够接受含有表格数据的字符串,将其转换为PandasDataFrame。这样,用户可以直接从Excel复制数据,而无需查找和读取文件路径。函数考虑了存在或不存在表头的情况,并允许指定列分隔符。测试显示,无论是否有表头,函数都能正确转换数据。
需求:
有时候我们会在excel里复制一些数据来做处理,
准备一个空串
pandas_test=r"""在这里粘贴你从excel复制的东西"""
从excel贴出来的数据长这个样子
pandas_test=r"""id code createtime modifytime date ts vehicleplate
1 G006033002000620010 2023/1/19 2023/1/19 2023/1/19 1674057600 b'\xe6\xb5\x9999'
2 G006033002000620010 2023/1/19 2023/1/19 2023/1/19 1674057600 b'\xe6\xb5\x9999'"""
打印出来,我们可以看到它是乘一个很规律的格式的

如果我们能将这个字符串直接转换成pandas的dataframe格式,岂不是就不用去额外读一个表了【主要是不用呆呆地去找路径了,贴上来直接用】
函数实现
我们通过写一个函数来实现,接受一个字符串
def string_to_dataframe_plus(data_string, header=0, delimiter='\t'):
"""将字符串转换为DataFrame
Args:
data_string: 包含数据的字符串
header: 表头所在的行数,默认为0,表示第一行是表头,传入None表示没有表头
delimiter: 列之间的分隔符,默认为制表符\t,即默认字符串是从excel文件复制过来的,如果你是csv文件复制过来的,你需要填写','作为分隔符
Returns:
转换后的DataFrame
"""
# 拆分字符串为行列表
lines = data_string.strip().split('\n')
# 判断是否存在表头
if header is not None:
# 如果有表头,则提取表头和数据行
# 提取表头
columns = lines[header].strip().split(delimiter)
# 提取数据行
data_rows = lines[header + 1:]
else:
# 如果没有表头,则生成0-n的表头,数据行即为全部行
# 生成默认表头
columns = [str(i) for i in range(len(data_rows[0].strip().split(delimiter)))]
# 提取全部数据行
data_rows = lines
# 因为字典可以很方便转换成dataframe类型,利用dict(zip())将每行数据转化为字典
records = [dict(zip(columns, row.strip().split(delimiter))) for row in data_rows]
# 创建DataFrame
df = pd.DataFrame(records)
# 返回DataFrame
return df
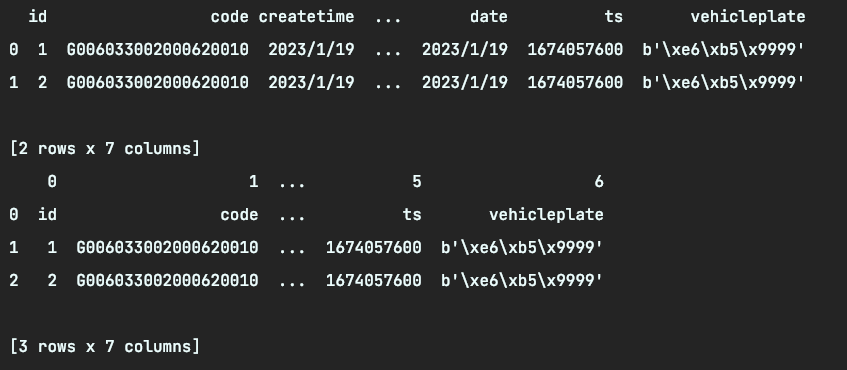
效果测试
测试代码:
df=string_to_dataframe_plus(pandas_test) # 默认首行为表头
df2=string_to_dataframe_plus(pandas_test,header=None) # 没有表头
print(df)
print(df2)
返回结果:

















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









