







前言
书接上回,【论文精读】Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects【1】
导言部分作为论文的开篇,其主要功能包括:
- 背景介绍:从宏观角度介绍时间序列数据及其在各领域的应用。阐述时间序列分析的重要性及当前面临的主要挑战。
- 问题陈述:明确指出时间序列分析当前面临的关键问题,如标记数据获取困难等。
- 研究动机:解释为何需要新方法解决这些问题,引出自监督学习(SSL)作为潜在解决方案。
- 研究目标:清晰陈述本研究的目标,如全面回顾和分类现有的时间序列SSL方法。
- 相关工作简述:简要回顾该领域的重要相关工作,为本研究提供上下文。
- 主要贡献:明确列出本研究的主要贡献和创新点,在前人已经做了相关工作的寄出上,我的工作是如何做的,如提出新的分类体系、总结常用数据集等。
- 潜在影响:强调本研究对学术界和工业界的潜在影响和意义。
- 论文结构:概述整篇论文的结构,指明每个部分将讨论的内容。
大概带着这个结构去阅读这个文章的导言,这样可以更有偏好的提取自己关注的信息。
introduction
导言部分一般是摘要的扩展,先来看看原文
第一段

翻译
时间序列数据在许多现实场景中比比皆是[1],[2],包括人类活动识别[3]、工业故障诊断[4]、智能建筑管理[5]和医疗保健[6]。基于时间序列分析的大多数任务的关键在于提取有用且信息丰富的特征。近年来,深度学习(Deep Learning,DL)在提取数据的隐藏模式和特征方面展现出了令人印象深刻的性能。通常,有足够大的标记数据是可靠的基于DL的特征提取模型的关键因素之一,这通常被称为监督学习(supervised learning)。不幸的是,在某些实际场景中,特别是对于时间序列数据,这一要求很难满足,因为获取标记数据是一个耗时的过程。作为替代方案,自监督学习(Self-Supervised Learning,SSL)因其标签效率(label-efficiency)和泛化能力(generalization ability)而受到越来越多的关注,因此,许多最新的时间序列建模方法都遵循这种学习范式(learning paradigm)
核心句1
“Self-Supervised Learning (SSL) has garnered increasing attention for its label-efficiency and generalization ability, and consequently, many latest time series modeling methods have been following this learning paradigm.”
解析
- 学术场景表达:
- “garnered attention”: 引起关注
- “abound in”: 大量存在于
- “availability of”: 可获得性,这里用availability很简练,比is hard to get 会好很多。
- “critical factors”: 关键因素
- “referred to as”: 被称为
- “label-efficiency”: 标签效率,类似的还有Data efficiency(数据效率):更广泛的概念,包括对所有类型数据的高效利用。Sample efficiency(样本效率):与label-efficiency相近,但更强调整体样本的使用效率。
- “generalization ability”: 泛化能力,就是作者提到的通过微调表现出来的迁移学习能力
- “learning paradigm”: 学习范式
第二段

翻译
**自监督学习是无监督学习的一个子集,它利用预设任务(pretext tasks)从未标记数据中获取监督信号。**这些预设任务是自生成的挑战,模型通过解决这些挑战来从数据中学习,从而为下游任务创建有价值的表示。自监督学习不需要额外的手动标记数据,因为监督信号是从数据本身派生的。在精心设计的预设任务的帮助下,自监督学习最近在计算机视觉(CV)[7]–[10]和自然语言处理(NLP)[11],[12]领域取得了巨大成功。
核心句1
SSL is a subset of unsupervised learning that utilizes pretext tasks to derive supervision signals from unlabeled data.
解析
这一段主要说明了自监督学习(SSL)是通过pretext task来work的,“pretext task"通常被翻译为"前置任务”,但也可以称为"预任务"或"自监督任务"。类似的还有一个代理任务(proxy task)的概念,proxy task和pretext task在自监督学习的语境中经常被交替使用,不过proxy task更宽泛一点,在迁移学习,多任务学习,更多的,我们会看到proxy task这样的词。在自监督场景下,我们把proxy task可以自动在脑子里转换为pretext task,更强调这个任务是预先设定的,用于学习有用的特征表示。
Pretext task是自监督学习中的一个核心概念,指的是一种人为设计的辅助任务,用于从未标记数据中学习有用的特征表示。
目的:
- 让模型学习数据的内在结构和特征,而无需人工标注。
- 为下游任务(如分类、检测等)提供良好的初始化权重或特征表示。
特点:
- 不需要人工标注数据
- 任务的设计通常基于数据的内在结构或属性
- 解决这些任务需要模型理解数据的高级语义或结构信息
除了文中给出的一些参考文献,这里再给出一些供各位老师参考,常见的pretext tasks示例:
计算机视觉领域:
图像旋转预测 (Image Rotation Prediction):
任务:预测图像被旋转的角度(通常是0°, 90°, 180°, 270°)。
目的:学习识别图像中的物体方向和结构特征。
论文:《Unsupervised Representation Learning by Predicting Image Rotations》
链接:https://arxiv.org/abs/1803.07728
被引用次数:3641
拼图游戏 (Jigsaw Puzzle):
任务:将图像切成多个小块并打乱,模型需要重建原始图像。
目的:学习图像的空间关系和局部-全局结构。
论文:《Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles》
链接:https://arxiv.org/abs/1603.09246
被引用次数:3275
颜色化 (Colorization):
任务:将灰度图像转换为彩色图像。
目的:学习物体的语义信息和典型颜色分布。
论文:《Colorful Image Colorization》
链接:https://arxiv.org/abs/1603.08511
被引用次数:4136
图像修复 (Image Inpainting):
任务:预测图像中被遮挡或删除的部分。
目的:学习图像的上下文信息和结构。
论文:《Context Encoders: Feature Learning by Inpainting》
链接:https://arxiv.org/abs/1604.07379
被引用次数:6305
上下文预测 (Context Prediction):
任务:预测图像中某个补丁相对于另一个补丁的相对位置。
目的:学习图像的空间关系和全局结构。
论文:《Unsupervised Visual Representation Learning by Context Prediction》
链接:https://arxiv.org/abs/1505.05192
被引用次数:3202
实例辨别 (Instance Discrimination):
任务:区分不同图像的增强版本。
目的:学习区分性特征,提高特征表示的质量。
论文:《Unsupervised Feature Learning via Non-Parametric Instance Discrimination》
链接:https://arxiv.org/abs/1805.01978
被引用次数:3868
运动预测 (Motion Prediction):
任务:在视频序列中预测下一帧。
目的:学习时间动态和物体运动特征。
论文:《Self-Supervised Learning of Video-Induced Visual Invariances》
链接:https://arxiv.org/abs/1912.02783
被引用次数:71
深度估计 (Depth Estimation):
任务:从单个图像预测深度图。
目的:学习3D结构信息和场景理解。
论文:《Unsupervised Learning of Depth and Ego-Motion from Video》
链接:https://arxiv.org/abs/1704.07813
被引用次数:2917
自然语言处理(NLP)
- 词嵌入训练 (Word Embedding Training)
任务:通过预测上下文中的单词,学习每个单词的向量表示。
目的:捕捉单词的语义和句法信息,使得相似语义的单词在向量空间中距离较近。
论文:《Efficient Estimation of Word Representations in Vector Space》
链接:https://arxiv.org/abs/1301.3781
被引用次数:42218
- 句子顺序预测 (Sentence Order Prediction)
任务:给定一组乱序的句子,模型需要预测它们的正确顺序。
目的:学习句子之间的逻辑和语义关系。
论文:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
链接:https://arxiv.org/abs/1810.04805
被引用次数:104676
- 掩码语言模型 (Masked Language Model)
任务:在输入文本中随机掩码一些单词,然后模型需要预测这些被掩码的单词。
目的:学习上下文信息,捕捉句子中的语法和语义特征。
论文:不错,还是在下《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
链接:https://arxiv.org/abs/1810.04805
被引用次数:104676
- 下一个句子预测 (Next Sentence Prediction)
任务:给定两个句子,模型需要预测第二个句子是否是第一个句子的下一句。
目的:学习段落级的语义关系。
论文:哎呀,又是在下《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
链接:https://arxiv.org/abs/1810.04805
被引用次数:104676
- 句子嵌入对比学习 (Sentence Embedding Contrastive Learning)
任务:通过对比学习的方式,使得相似句子的嵌入向量距离更近,不相似句子的嵌入向量距离更远。
目的:获得语义丰富的句子表示。
论文:《A Simple Framework for Contrastive Learning of Visual Representations》
链接:https://arxiv.org/abs/2002.05709
被引用次数:17553
第三段

翻译
随着自监督学习(SSL)在计算机视觉(CV)和自然语言处理(NLP)领域取得巨大成功,将SSL扩展到时间序列数据变得很有吸引力。然而,直接将为CV/NLP设计的前置任务(pretext tasks)转移到时间序列数据上并非易事,在许多情况下往往会失败。在此,**我们重点说明(highlight)将SSL应用于时间序列数据时出现的一些典型挑战。**首先,时间序列数据表现出独特的特性,如季节性、趋势和频域信息[13]-[15]。由于大多数为图像或语言数据设计的预训练任务并未考虑这些与时间序列数据相关的语义,因此无法直接采用。SSL中常用的一些技术,如数据增强(data augmentation),需要专门为时间序列数据设计。例如,旋转和裁剪是图像数据常用的增强技术[16]。然而,这两种技术可能会破坏序列数据的时间依赖性。第三,大多数时间序列数据包含多个维度,即多变量时间序列(multivariate time series)。然而,有用的信息通常只存在于少数几个维度中,这使得使用其他数据类型的SSL方法难以从时间序列中提取有用信息。
核心句
Here we highlight some typical challenges that arise when applying SSL to time series data. 1. 2. 3.
表达
1.文中的一些单词
- appealing(吸引人的)
- non-trivial(不平凡的)
- exhibit(展现)
- semantics(语义)
- temporal(时间的)
- multivariate(多变量的)
2.文中的句式
- “With the great success of…, it is appealing to…”(引出研究动机)
- “First,…Second,…Third,…”(用于列举多个要点)
- “However, … making it difficult to…”(用于说明问题和困难)
解析
前面介绍了自监督学习的内核pretext task在CV和NLP大杀四方,然后这段文字主要介绍了将自监督学习(SSL)应用于时间序列数据时面临的挑战。然后详细阐述了三个主要挑战:时间序列数据的语义信息如何提取(如季节性和趋势)、数据增强如何设计、以及多变量时序数据中特征如何提取。
第四段

翻译
据我们所知,尽管关于计算机视觉(CV)或自然语言处理(NLP)的自监督学习(SSL)文献丰富[17],[18],但目前还没有针对时间序列数据的SSL进行全面系统的综述。Eldele等人[19]和Deldari等人[20]提出的综述与我们的工作部分相似。然而,这两篇综述仅讨论了自监督对比学习(self-supervised contrastive learning,SSCL)的一小部分,需要更全面的文献综述。此外,还需要包含基准时间序列数据集的总结,而且关于时间序列SSL的潜在研究方向也很少。
表达
-
词汇表达:
- comprehensive(全面的)
- systematic(系统的)
- extensive(广泛的)
- scarce(稀少的)
-
短语表达:
-
“To the best of our knowledge”(据我们所知)这是一句必备的学术表达!尤其是在介绍研究贡献或声明工作新颖性时,想象一下,我们刚写完一篇惊天动地的论文,信心满满地准备投稿。但是,要是有人早就做过类似的研究怎么办?咱们的研究不就没意义了嘛,别担心!只要我们输入这句咒语"To the best of our knowledge",我们就立刻获得了学术界的"免死金牌"。
这句话就像是在告诉审稿人和读者:"我已经尽力了!如果还有什么遗漏,我不背锅“。它暗示了作为作者的我们可能有不知道的地方,同时又说明了我们已经做了充分的调研。
-
“in contrast to”(与…相比)
-
“partly similar to”(部分类似于)
-
-
句型表达:
- “There has yet to be…”(还没有…)
- “However, … which requires…”(然而,…这需要…)
- “Furthermore, … and … are also scarce.”(此外,…而且…也很少。)
-
学术场景常见表达:
- “This paper presents a comprehensive review of…”(本文对…进行了全面综述)
- “Previous studies have focused on…”(先前的研究主要集中在…)
- “Our work differs from existing surveys in that…”(我们的工作与现有综述的不同之处在于…)
- “We identify several gaps in the current literature…”(我们发现当前文献中存在几个缺口…)
- “This study aims to bridge the gap between…”(本研究旨在弥合…之间的差距)
解析
这段在承上启下,前面说明问题,这段蜻蜓点水地点出相关工作和不足,后面就要开始介绍本文的工作了。
第五段

翻译
本文对时间序列数据的最新自监督学习(SSL)方法进行了全面综述。我们首先回顾了最近关于SSL和时间序列数据的研究动态,继而提出了一种新的分类方法,从基于生成(generative-based)、基于对比(contrastive-based)和基于对抗(adversarial-based)三个角度进行分析。这一分类方法虽然与Liu等人[21]提出的类似,但专门聚焦于时间序列数据。
在基于生成(generative-based)方法中,我们详细阐述了三个框架:
-
基于自回归的预测(autoregressive-based forecasting)
-
基于自编码器的重建(auto-encoder-based reconstruction)
-
和基于扩散模型的生成(diffusion-based generation)
对于基于对比(contrastive-based)方法,我们根据正负样本的生成方式,将现有工作分为五类:
- 采样对比(sampling contrast)
- 预测对比(prediction contrast)
- 数据增强对比(augmentation contrast)
- 原型对比(prototype contrast)
- 和专家知识对比(expert knowledge contrast)
在(基于对抗)(adversarial-based)方法方面,我们根据两个主要任务进行了归类和总结:
-
时间序列生成/插补(time series generation/imputation)
-
和辅助表示增强(auxiliary representation enhancement)
图1展示了我们提出的完整分类体系。
文章最后,我们探讨了时序自监督学习的未来发展方向,包括数据增强的选择与组合、SSCL中正负样本的选择策略、时序自监督学习的归纳偏置、SSCL的理论分析、时间序列的对抗攻击与鲁棒性分析、时间序列领域适应、关于时间序列的预训练和大模型、协作系统中的时序自监督学习,以及时序自监督学习的基准评估等多个方面。我们的主要贡献概述如下。
表达
-
词汇表达:
-
state-of-the-art(最先进的)也就是我们平常听得最多的SOTA的全称了,我们自己写作的时候,想描述一些领域的工作的时候,可以说这些词,
-
cutting-edge(尖端的)
-
advanced(先进的)
-
leading-edge(前沿的)
-
pioneering(开创性的)
-
innovative(创新的)
-
taxonomy(分类法)比classification不知道高到哪里去了
-
-
短语表达:
- “provide a review of”(提供…的综述)
- “propose a new taxonomy”(提出新的分类法)
- “divide the existing work into”(将现有工作分为)
- “conclude this work by discussing”(通过讨论…来结束本工作)
-
句型表达:
- “We begin by… and then…”(我们首先…然后…)
- “Our main contributions are summarized as follows.”(我们的主要贡献总结如下。)
解析
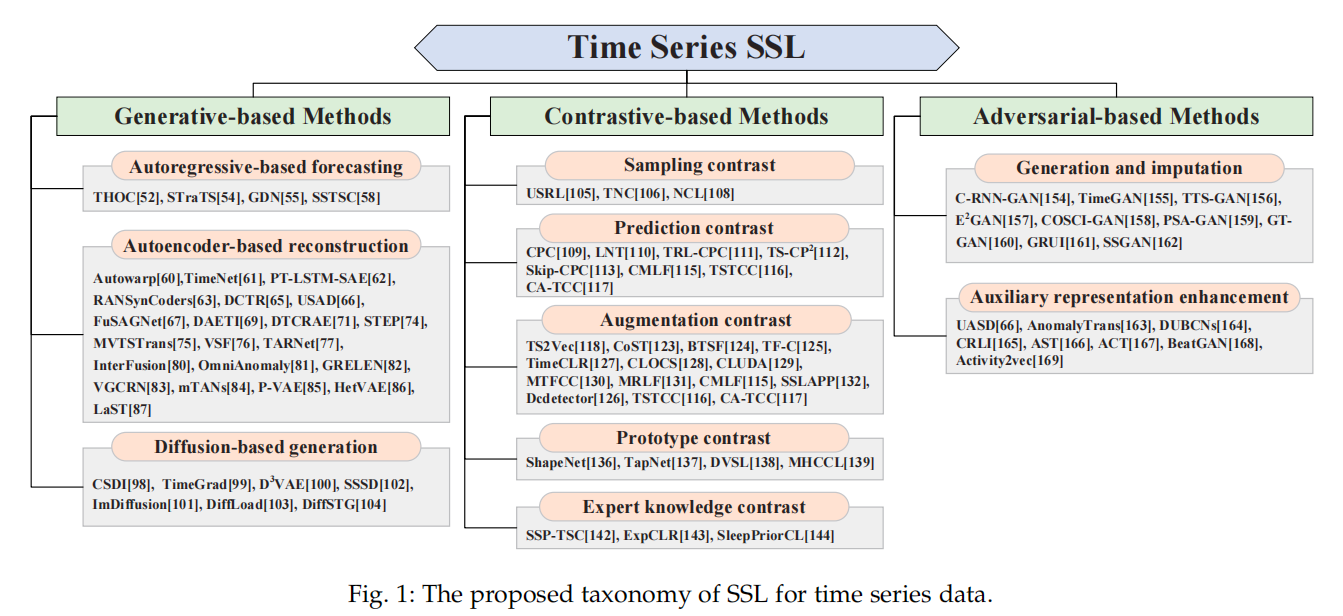
这段说明了本文的主要工作内容和贡献,可以看做是对图1的展开说明,本文提出了一种新的时间序列数据自监督学习方法分类体系,涵盖(基于生成)(generative-based)、(基于对比)(contrastive-based)和(基于对抗)(adversarial-based)三个主要方向,3大类又进一步分成3小类。
第六段(以第五段命名的第六段)

翻译
-
**新的分类体系和全面综述。**我们提供了一个新的分类体系,并对时序自监督学习进行了详细且最新的综述。我们将现有方法划分为十个类别,对每个类别,我们描述了基本框架、数学表达、细粒度分类、详细比较以及优缺点。据我们所知,这是首次对时间序列数据的SSL研究进行全面系统的综述。
-
**应用和数据集汇集。**我们汇集了时序自监督学习的相关资源,包括应用和数据集,并调查了相关数据来源、特点及对应的工作。
-
**丰富的未来研究方向。**我们从应用和方法论两个角度指出了该领域的关键问题,分析了其成因和可能的解决方案,并讨论了时序自监督学习的未来研究方向。我们坚信我们的努力将激发对时序自监督学习更多的研究兴趣。
解析
这是本文的主要贡献,也是我们在速通一篇论文的时候特别需要关注的部分,这部分涵盖了本文的主要内容,我们速通文章的时候可以通过文章的主要贡献来判断这篇工作是不是需要我们继续阅读的。
第七段

翻译
本文的其余部分安排如下。第2节提供了一些关于SSL和时间序列数据的综述文献。第3节到第5节分别描述了基于生成(generation-based)、基于对比(contrastive-based)和基于对抗(adversarial-based)的方法。第6节从应用角度列出了一些常用的时间序列数据集。同时还提供了定量性能比较和讨论。第7节讨论了时间序列SSL的有前景的方向,第8节对文章进行了总结。
解析
最后作者这里给出了文章的结构做为导论的收尾。
2 RELATED SURVEYS
to be continue


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









