






Tella Rajashekhar Reddy, Palak, Rohan Gandhi, Anjaly Parayil, Chaojie Zhang, Mike Shepperd, Liangcheng Yu, Jayashree Mohan, Srinivasan Iyengar, Shivkumar Kalyanaraman, Debopam Bhattacherjee
微软
摘要
得益于AI计算的高功率密度和新兴推理工作负载,AI的电力需求正在前所未有的增长。在供应方面,丰富的风力发电正等待接入电网的互连队列。
鉴于此,本文主张将AI工作负载带到与风力发电场共址的模块化计算集群中。我们的部署优化策略使得今天经济可行地部署超过600万个高端GPU成为可能,这些GPU可以消耗便宜且绿色的电力来源。我们构建了Heron 1 { }^{1} 1,这是一个跨站点软件路由器,可以通过路由AI推理工作负载来有效利用不同风力发电场之间发电的互补性。使用来自Azure的一周编码和对话生产痕迹以及(真实)可变风力发电痕迹,我们展示了Heron如何比最先进的解决方案提高高达80%的AI计算总吞吐量。
1 引言
随着Transformer [78] 和大型语言模型 (LLMs) [36, 54, 55, 58, 59] 的兴起,以及AI在工业界、政府和个人中的快速采用 [16, 33, 63, 71],现在满足AI不断增长的能源需求至关重要。报告 [51, 66] 指出,GPT查询所消耗的能量远远超过网络搜索,而AI图像生成则与智能手机充电相当。运行AI工作负载的GPU变得显著更耗电 [20, 37, 56, 57],推动了数据中心 (DC) 的电力需求。BCG [48] 预测美国的数据中心能源(同样,电力)需求将以年复合增长率(CAGR) 15-20% [61] 的速度逐年增长,到2030年可能达到1,000 TWh(100+ GW),相当于美国住宅用电量的三分之二。欧盟 [53] 也出现了类似趋势。
意识到这种电力需求激增的风险、电力供应瓶颈 [32, 47] 以及实现可持续发展目标的压力增加,像微软、谷歌等超大规模公司最近宣布与许多可再生能源供应商建立合作伙伴关系 [21, 23, 43, 75]。
然而,简单地向公用电网添加更多可再生能源可能并不足够。特别是,随着电力需求激增,电网难以跟上。首先,扩展电力基础设施——通过新建输电线路、配电系统或储能设施——资本密集型 [29, 76],通常面临监管和物流延迟 [32],尤其是当可再生能源位于远离消费中心的地方时 [42, 77]。因此,伯克利实验室报告 [47] 强调,到2023年,待批准的新发电容量已超过现有安装容量的两倍。其次,即使已批准项目经常因电网拥堵而受到限制,导致清洁电力未被充分利用 [26, 42, 83]。第三,长距离输电和配电 (T&D) 可能造成显著的电力损失,使成本增加超过50% [9, 29]。例如,EIA 报告 [27] 显示美国企业电力成本为 8.5 c / K W h 8.5 \mathrm{c} / \mathrm{KWh} 8.5c/KWh(2024年9月),而风力发电场售价仅为 2.5 c / K W h 2.5 \mathrm{c} / \mathrm{KWh} 2.5c/KWh [15, 72]。最后,大部分电网正在老化——接近或超过其50年的设计寿命 [32, 66]——可能被迫采取损害所有利益相关者长期可持续发展目标的短期措施 [25, 65] [80]。
观察到这一差距,我们提出问题:我们能否为AI提供商提供一种有用的杠杆,以应对电力约束并推进可持续发展目标?在此背景下,我们提出了AI Greenferencing,它将大量AI推理转移到可再生能源农场,重点放在风力发电场,因为它们的部署正在快速增长 [5, 7, 8]。尽管这些站点目前支持数字电视流媒体和加密货币挖矿,但LLM推理(占AI计算的90% [12, 62])提供了主要机会。在电源处运行AI可以缓解电网压力,解决互连队列、限制、T&D损耗和可持续性问题。AI Greenferencing对所有人都是有益的:(1) 用户可以获得可持续的AI服务;(2) AI提供商解锁额外的计算能力、用户覆盖和收入;(3) 风力发电场可以本地化电力变现;(4) 电网从减少负载和获得更多扩展空间中受益;(5) 共址计算初创公司 [5, 7, 8] 获得高价值工作负载。
虽然概念上简单,但实现AI Greenferencing需要解决几个实际问题:
足够的风力发电吗?我们发现,根据Global Energy Monitor数据 [34],全球范围内(同样,在美国)已经有大量的风力发电容量(仅100+ MW部署),总量达640+ GW(150+ GW),并且在50毫秒光纤往返时间(RTT)内靠近Azure数据中心。其中77%的容量在20毫秒RTT范围内(不会显著增加AI推理延迟要求的时间到首令牌或TTFT的服务水平目标(SLO))[1]。
AI计算成本太高吗?我们表明,在可变电力的风力发电场部署昂贵的GPU是经济可行的。具体来说,存在多种可模块化生产的计算部署选择 [10, 24, 52, 56],这些选择可以运送到风力发电场。我们的部署优化策略建议在低于峰值电力生成的情况下部署AI计算。这种方法保证了大多数时间的峰值计算能力,同时通过软件路由器利用跨站点互补性处理剩余不确定性 [9, 74]。部署在风力发电场的硬件在任何时刻都以更低的电力成本运行,这转化为与传统数据中心相当或更低的总拥有成本(TCO)。通过这种方法,我们可以“今天”在风力发电场部署600多万个NVIDIA H100s(至少是NVIDIA 2024年订单簿的3倍 [30, 68])。
变化可预测吗?我们发现,尽管风力发电是可变的,但在15分钟的时间尺度上高度可预测,从而帮助调度器在线做出明智决策。同样,AI推理工作负载到达是可预测的,允许AI Greenferencing软件提前规划带电力约束的分配。
Heron用于AI Greenferencing。当将GPU与风力站点共址时,另一个挑战是在电力和工作负载变化下为AI推理请求提供服务。为了实现这一愿景,我们设计了Heron(如图1所示),一个逻辑上集中的跨站点路由器,它在AI提供商的边缘或数据中心附近拦截推理请求,并将其路由到由风力供电的计算集群。Heron考虑了电力可用性、硬件约束、网络延迟和工作负载模式。它利用应用级旋钮(例如张量并行性)和基础设施级控制(例如频率缩放),同时利用不同风力站点的空间互补性。分层结构用于多时间尺度决策,Heron在基于状态的最新能量感知但变化不可知的基线调度器之上改进AI计算吞吐量高达80% [73]。
本文作出以下贡献:
- 我们展示靠近需求处有显著的风力容量。
-
- 我们展示如何通过调整每个风力站点的AI计算规模,大大减轻电力不确定性。
-
- 我们展示如何利用源头低成本电力抵消剩余不确定性造成的计算周期损失。
-
- 我们展示风力发电和推理工作负载到达虽然是可变的,但却是可预测的。
-
- 我们构建并演示了Heron,一个用于AI Greenferencing的跨站点路由器,它利用预测、工作负载洞察、应用和基础设施级旋钮以及不同站点间的风力发电互补性来解决系统中(调整后)的剩余不确定性。
2 动机与可行性分析
AI计算正变得越来越耗电 [20, 37, 57],仅在美国的数据中心需求就以每年10-15%的速度增长 [48],很快将与居民用电量相当。这种加速的需求有可能压倒老化的电网基础设施,并迫使短期内做出可能损害长期可持续发展目标的决策 [25, 65]。
与此同时,风力发电场代表了一个巨大的、尚未充分利用的电力机会。截至2024年6月,全球运营中的风力发电容量为447 GW,预计总容量超过2.4 TW(包括在建、预建和已宣布的100+ MW站点)[34]。然而,由于电网扩展成本高、复杂性和进展缓慢,大量此类容量闲置,卡在互连队列中 [47]。即使获得批准的风力发电场也经常因电网拥堵而受到限制 [26, 42, 83]。而且,当风力发电通过电网输送时,传输和分配(T&D)损失——通常超过50% [9, 29]——显著增加了成本。
关于AI绿色推理的理由。本文主张一种分散式的AI部署框架,该框架在大型风力发电场中共置“AI”计算集群与电源。与其将电力带到计算,AI绿色推理框架将LLM推理请求路由到地理上分散的站点,适应工作负载特性、电力可用性、发电互补性和硬件容量。这种模型有可能解锁数百万个GPU,以实现可持续的AI基础设施。
本节量化了这一机会并评估了关键的可行性维度: § 2.1 \S 2.1 §2.1评估靠近现有需求的风力容量; § 2.2 \S 2.2 §2.2分析牺牲计算周期以换取更便宜电力的成本权衡; § 2.3 \S 2.3 §2.3探讨如何平抑风力电力和工作负载的变化。
2.1 达到显著风力容量
检查在合理网络距离内的风力发电场对于DCs(需求代理)至关重要。AI推理延迟服务水平目标(SLOs) [73] 包括首次标记时间(TTFT)和标记间时间(TBT)。TTFT范围从几百毫秒到几秒不等,而TBT较低 [87]。网络延迟主要影响TTFT,而不是TBT(流式传输标记)。
图2(a)显示了在2024年6月内,距离Azure位置50毫秒(模拟)光纤往返时间(RTT)范围内的风力发电场(≥100 MW)。这张地图表示了一种枢纽和辐条模型,其中AI请求先到达Azure DC,然后再路由到风力发电场。在实际部署中,Azure网络边缘的跨站点路由器可以进一步减少这种额外延迟。图2(b)显示,大部分这种容量在20毫秒光纤RTT范围内,仅使TTFT(表IV中的[73])膨胀1-8%。类似的分析显示Google数据中心[2]也有相似的接近度(未显示)。不过,并非图2中的所有容量都可用于AI部署。风力发电具有不确定性, § 2.2 \S 2.2 §2.2展示了如何通过调整各风力站点的计算规模确保经济可行性。需要注意的是,虽然运行容量服务于电网,但在源头而非通过电网消耗电力原则上不应破坏电力供应生态系统。
结论:靠近数据中心枢纽(即AI需求)的显著风力电力容量可以在不违反延迟SLOs的情况下使用。
2.2 硬件配置
硬件部署选择。多年来,微软一直在部署模块化数据中心(MDCs) [10]。MDCs可以批量生产和现场组装,因此比传统数据中心的生产成本低 [22, 24, 41]。此外,还有一些初创公司 [5, 8] 在风力发电场甚至涡轮机内部部署和运行计算。NVIDIA最近宣布了SuperPODs [56],这是一种包含1,016个GPU(如H100)的模块化集群,集成了电缆、冷却、网络等组件。还有过去的研究(Parasol [35])探讨了与可再生能源共置的计算运行。鉴于这些能力,我们更关注一个重要问题——在风力发电场部署AI计算是否有经济意义?
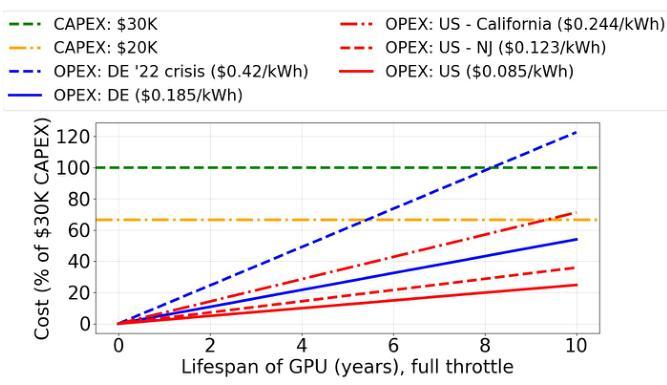
图3:NVIDIA H100 GPU在其生命周期内的电力成本可能是其CAPEX的一个重要部分。
在风力发电场部署GPU的主要挑战是电力变化(§2.3)。考虑到高昂的GPU成本 [69],我们评估可变但廉价的电力是否能证明CAPEX(资本支出)投资的合理性。GPU的使用寿命有限,利用率不足会导致CAPEX浪费。我们将OPEX(运营支出)与CAPEX进行比较,以确定最佳配置,确保较低的OPEX抵消失去的CAPEX。
OPEX对比CAPEX。数据中心(DC)的总拥有成本(TCO)主要由四个组成部分驱动 [13]:(1) DC CAPEX(作为DC折旧),(2) DC OPEX,(3) 服务器CAPEX(作为服务器折旧),和(4) 服务器OPEX。众所周知,MDCs由于规模经济效应生产成本较低 - 它们可以批量生产 [22, 24, 41]。此外,当在风力发电场中其他未使用的土地上部署时,由于这种部署给风力发电场带来的收入机会,土地收购或租金成本也应该较低 [40, 60]。因此,我们预计AI Greenferencing部署的DC CAPEX不会高于传统DCs。此外,MDCs由于其标准设计更容易维护。如果风力发电场
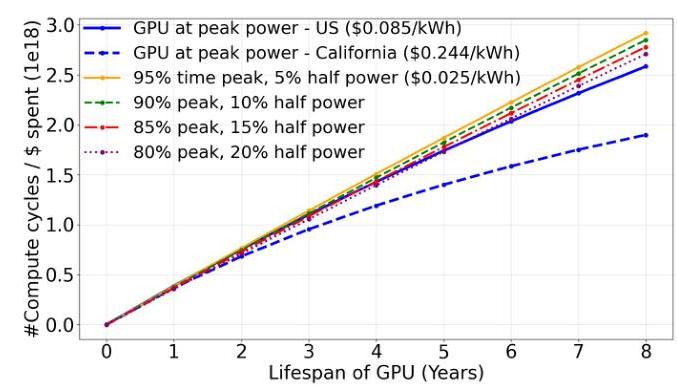
图4:风力站点的C/P更具竞争力。
雇员/操作员经过培训执行基本的DC维护活动 [44, 86],这实际上可能会降低DC OPEX成本,而传统的DC会更高。此外,风力发电场中的计算可以自然利用空气冷却,从而减少对液体冷却的依赖,进而进一步降低OPEX。因此,这里我们更加关注服务器CAPEX和OPEX方面——前者主要由GPU价格驱动,后者则显著受电力成本影响,通过AI Greenferencing风格的部署可以显著降低。
鉴于GPU成本在过去几年大幅增加 [69],NVIDIA H100s单价约为30,000美元/GPU,人们很容易认为CAPEX应该驱动服务器部署选择,因为电力成本传统上较低。在这里我们展示相反的结果——在整个GPU生命周期内,OPEX(我们分析中的电力成本)成为TCO的重要部分。图5显示了NVIDIA H100 GPU的CAPEX和OPEX成分,按其公开已知的价格30,000美元 [69] 进行归一化(y=100的水平线)。第二条水平线(CAPEX为20,000美元)代表大批量买家可能的最低规模经济界限。所有其他线条显示在美国 [27] 和德国(DE) [18] 购买电力的总OPEX,假设整个GPU运行期间满负荷运行。如我们所见,在5年内,美国的OPEX为12.4%(假设CAPEX为30,000美元,否则为20,000美元)。在德国,这些数字要高得多——分别为27%和40.5%。在特殊情况下,与30,000美元的CAPEX相比,OPEX在美国(加利福尼亚州)可能高达35.6%,而在德国(2022年危机 [64])可能高达61%。
结论:OPEX可能占高端GPU拥有成本的很大一部分。
比传统DC更好的C/P。由于电力消费成本是AI计算TCO的重要部分,我们认为在电力成本显著较低的情况下,即使在生命周期中丢失一些GPU周期也是更好的选择。让我们看看在风力发电场部署GPU如何与在传统DC中部署相抗衡,就能力/价格(C/P=总计算周期/花费的美元)而言,分母是CAPEX和OPEX的总和。
图4绘制了单个GPU随时间变化的C/P。假设GPU在其峰值性能时每年可维持约 ( 1 0 22 ) (10^{22}) (1022)次浮点运算 [4]。美国企业客户的电力成本平均为0.085 USD/kWh,加州截至2024年9月的电力成本为0.244 USD/kWh(EIA报告 [27])。另一方面,风力发电源头的电力成本,正如报道的PPAs [15, 72](购电协议)所示,显著较低——在美国主要风力发电地区为0.025 USD/kWh。这种较低的电力成本在AI计算部署于电力源头时转化为显著的OPEX减少,即风力发电场。另外,需要注意的是,这种较低的电力成本实际上是源头电力成本相对于通过电网获取电力的上限——被削减的电力无论如何都会浪费掉,实际上几乎是免费的。
在风力发电场的峰值功率处配置计算会浪费计算周期。相反,我们在第X百分位的发电量处进行配置,确保在任何时候都能获得更便宜的电力,同时最小化利用率不足。图4显示,这种策略在几年内实现了比传统DC更高的C/P。在第5百分位时,两年内即可达到平衡;在第15百分位和第20百分位(较大集群)时,分别需要4年和5年。
结论:通过在风力发电场适当调整AI计算配置并在源头消耗低成本电力,可以有效抵消失去的计算周期。
高部署意愿。关键是按照某个风力发电站的较低百分位发电量来配置AI计算,确保即使偶尔失去周期,也能保持与传统数据中心相当或更高的C/P。ELIA数据 [28] 显示,第X百分位的功率远低于X%的峰值容量——例如(第5百分位,1%),(10,2%),(15,4%),(20,5%)等。
这种方法转换为固定数量的GPU集群,随着风力发电场规模扩大而增加。
我们现在评估在全球范围内,如果只选择Global Energy Monitor数据集中峰值发电容量最大的Y%风力发电场,在峰值容量的第20百分位处部署会是什么样子。对于这项评估,我们假设部署将以NVIDIA H100 SuperPODs为单位进行,每个H100 SuperPOD包含1,016个H100 GPU,峰值功耗为1.3 MW。如图5所示,全球运营中的前20%(x=80,250+MW站点)风力发电场可部署的NVIDIA SuperPODs总数为6,636个,这相当于670万个H100 GPU(超过NVIDIA 2024年H100订单簿的3倍 [30, 68])。鉴于这些是大型风力发电场,即使是峰值容量的第20百分位(5%)在最小的此类发电场中也是一个合理的部署规模,即9个SuperPODs(9K+ H100 GPU)。一般来说,当我们选择峰值功率的较小百分位用于计算调整时,总体部署规模更大,但最小部署规模更小(更碎片化)。这是AI推理提供商应根据因素如软件路由器可扩展性、每站点维护开销、物理安全问题等来决定的一个参数。
结论:尽管采用了调整策略,估计今天仍可在较大的风力发电场部署600多万个H100 GPU。
2.3 平抑电力和工作负载不确定性
跨越多个风力站点的AI Greenferencing需要缓解两端的不确定性:(1) 风力站点的电力生成和(2) 推理工作负载到达。下面我们将探索风力电力和AI推理工作负载的具体特征(接下来讨论),以更好地了解这些变化的可预测性——这是软件路由器可以利用的一个特性。
2.3.1 风力电力特征
可预测性。众所周知,风力电力因风速和天气条件的临时变化而具有波动性。我们在 §2.2 中讨论了在风力发电场配置AI计算时如何适应这种波动性。尽管风力电力具有波动性,但它也是可预测的,这种特性可以被AI Greenferencing软件利用来跨多个风力RE站点路由工作负载。我们观察到,在15分钟粒度(2024年1月至7月,ELIA数据集 [28])上,Wallonia和Flanders地区的不同组合与Elia和Dso电网的平均自相关得分在滞后1时为0.991。在EMHIRES数据集 [85] 中的235个风力发电场站点,1小时粒度下的发电数据(2018-19年)的平均(同样,中位数)自相关得分为0.989(0.99)。这些观察结果表明,使用时间序列或机器学习预测模型(可以使用历史数据、季节性、当地天气、涡轮机规格和方向、风电场布局等附加输入特征)可以在不同的时间粒度上强烈预测风力电力。我们自定义构建的基于AI的能源预测框架 4 { }^{4} 4 使用多样化的现场和离场输入,并整合各种开源模型,如Google的TFT [50] 和Microsoft的DeepMC [45]。该框架相较于仅使用现场数据的最先进预测器TFT,相对提高了20%的预测误差。这种正交工作有助于在系统设计中将风力电力生成视为预言。
互补性。不同地理位置的风力电力生成可以通过利用不同的风系统表现出互补性,这一点已在以往工作中强调过。SkyBox [74] 和Virtual Battery [9] 利用互补性主动迁移虚拟机工作负载,Heron可以利用风力电力的这一特性来绕过低发电情况下的AI推理请求。需要注意的是,每个站点仍然受到已配置硬件的限制,正如我们在 §2.2 中讨论的那样。Heron可以路由到一组提供足够互补性的站点,这样所有站点的发电量不会同时下降。由于通常在50毫秒光纤RTT范围内有许多站点选择(§2.1),我们可以识别出跨国站点集合,以最小化聚合发电量的变异系数(CoV)。在EMHIRES数据集中,我们发现来自多个国家的4个风力站点组合(假设峰值发电量为250 MW,遵循我们在 §2.2 中的讨论;在EMHIRES中标准化为1.0)可以将CoV降低36%(同样,32%),相比于单个站点(同样,4个不同站点但都在同一国家)。其中一个组合包括冰岛、挪威、瑞士和英国的4个风力发电场,如图6所示,长期CV为0.475(1年的数据,EMHIRES)。虚线表示已配置硬件的峰值需求(长期发电量的第20百分位),正如我们在 §2.2 中讨论的那样。请注意,每个站点的发电量通常高于这个峰值需求,并且很少所有站点的发电量同时降至峰值需求阈值。
结论:风力电力在时间上的可预测性允许软件路由提前计划。风力电力的空间互补性有助于移动推理工作负载。
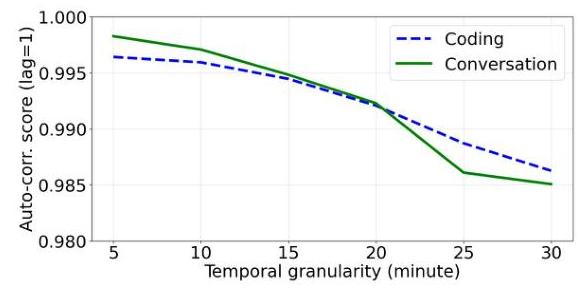
图7:AI推理请求到达在不同时间粒度下具有高自相关分数(滞后1)。
2.3.2 可预测的AI推理工作负载
我们使用来自Azure的真实一周长编码和对话生产跟踪记录 [11] 来测量其可变性和可预测性。两条轨迹都显示出明显的昼夜和周模式(图12,右侧)。为了理解工作负载的可预测性,我们进行了简单的时序分析,如图7所示,其中我们将所有请求到达时间窗口(X分钟,x轴;5的倍数)汇总,并计算滞后1的自相关分数。可以看出,分数通常非常接近1.0。在15分钟粒度下,两条轨迹的相关分数均高于0.994。这种强烈的时序相关性表明,通过回归或机器学习模型结合额外输入特征(如一天中的时间、一周中的天等),工作负载到达是高度可预测的。工作负载可预测性帮助Heron在线做出明智、智能的决策。
结论:AI推理工作负载到达是可预测的,从而允许Heron进行智能提前规划。
3 设计概述
受风力发电容量靠近需求和风力发电可预测变化的启发,我们现在详细介绍了我们的跨站点路由器Heron,它可以智能地跨站点路由AI推理请求以获得良好的性能。Heron在路由推理请求时考虑了延迟SLOs、风力发电变化、工作负载变化、工作负载特征以及应用和基础设施级别的能力。本节
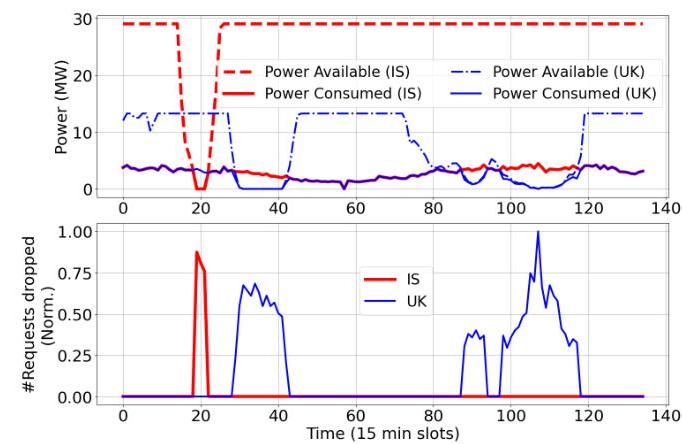
图8:缺乏跨站点智能利用跨站点互补性的DynamoLLM需要丢弃请求。概述了关键的设计挑战和机会,而下一节深入探讨了Heron的设计组件。
3.1 挑战
(C1) 剩余的电力不确定性。在每个风力站点调整计算部署规模(参见§2.2)显著减少了电力不确定性。然而,在站点的峰值发电量的第20百分位处部署计算,仍然意味着20%的时间电力低于峰值。一个幼稚的路由策略可能会暂时带来超出站点电力限制的工作负载,导致请求丢弃。图8展示了这一挑战。真实的AI推理工作负载(稍后在§5中讨论的实际跟踪)被路由到英国的两个风力发电场站点(计算配置为13.25 MW峰值需求)和冰岛(同样,29 MW峰值需求),采用轮询策略。每个站点运行一个DynamoLLM调度器 [73](我们的基线;在§6中进一步讨论),其目的是最小化电力/能耗(假设无限的硬件和电力可用性,如同传统数据中心)。我们看到,在冰岛站点的285-315分钟之间,以及英国站点的435-630分钟、1320-1395分钟和1470-1755分钟之间,可用电力下降到配置峰值以下,也低于分配工作负载的最低需求,导致显著的请求丢弃(底部图表,按峰值下降归一化)。
(C2) 复杂的工作负载特征。在这项工作中,我们专注于大语言模型(LLM)推理。不同的LLM用例可能有不同的输入和输出长度、延迟SLOs,并且可以用不同的张量并行性(TP)、GPU频率和负载(每秒请求数或RPS)配置运行。运行配置决定了请求的命运——它消耗的电力和经历的端到端(E2E)延迟。在跨站点动态电力和计算受限的环境中,这个在线匹配问题构成了挑战。
(C3) 不同开销的旋钮。上述TP和GPU频率旋钮有不同的开销程度。虽然通过nvidia-smi改变GPU频率只需几毫秒,但改变TP程度可能需要几秒到几分钟,因为涉及多个步骤——等待现有请求完成、重新划分模型权重、将它们传输到相关的GPU并同步GPU。在跨站点设置中调整这些旋钮,同时考虑它们的不同开销,需要仔细规划。
(C4) 延迟与电力的权衡。鉴于电力和计算限制,可以运行AI Greenferencing系统以最小化总请求延迟或总电力消耗。我们在§5中讨论如何在电力和延迟之间进行权衡。虽然我们留给AI运营商决定操作点,但AI Greenferencing设计需要意识到这两种选择。
3.2 关键想法
Heron通过以下关键想法解决了上述挑战:
(K1) 空间电力互补性。图8中(C1)的所有请求丢弃都可以通过绕过“坏”的电力状况来避免,因为站点组合在此时间段内提供了完全的互补性。Heron利用这种空间互补性来减轻剩余的时间不确定性,从而在基线上改善吞吐量(§5.2)。它在路由工作负载时使用站点级电力预言(§2.3)。
(K2) 工作负载特征到查找表。为解决C2,我们在先前工作的基础上运行了深度电力配置基准测试,但针对更近期的Llama 3.170B模型。我们根据输入和输出长度对推理请求进行分类,量化可能的延迟SLOs,并量化不同TP程度和频率如何在同一请求类别(在不同负载或RPS水平下)以不同电力和延迟运行。配置练习帮助我们获得了两个有用的功能(查找表):e2e(c, f, t, l),给出端到端延迟和power(c, f, t, l),给出c类请求在负载l下以TP t和GPU频率f运行时的峰值电力消耗。查找表包含大约2,000行。在动态环境下,当可用电力有时低于峰值时,重要的是很好地利用这些调整旋钮以保持在资源限制之内。我们在§5.1中讨论了两种轨迹的配置结果,尽管配置可以与用例无关(不是模型)。
(K3) Heron的分层设计。为解决不同配置旋钮的开销问题(C3),Heron采用分层设计——一个组件以较粗的时间粒度运行,决定所有站点的GPU实例的TP程度、频率和负载,而另一个组件更频繁地重新配置仅频率和负载。这种架构帮助Heron适应改变这些旋钮的差异,如挑战C3所述,同时仍优化实时条件。Heron尽量减少TP和频率重新配置的次数。这与事实相符,即电力和工作负载的变化也是渐进的(见§2.3)。Heron还采用DynamoLLM [73]优化(使用GPU之间的NVLink并在后台传输权重),以最小化TP重新配置期间的重新分片开销。分层决策有效地解决了粗时间尺度上的误预测问题。
(K4) Heron的不同目标。Heron组件可以以最小延迟或最小电力消耗为目标(C4)。不同组件协同工作,具有相同的目标,除了一个旨在更好打包请求以改善响应延迟的启发式方法。我们的结果比较了这两个目标,并量化了权衡。
4 HERON DESIGN
Heron跨站点请求路由器由多个组件组成,如图9所示。Heron的目标是确定每个可再生站点不同类型请求的GPU数量、TP程度、GPU频率和负载。注意,推理工作负载可以根据输入和输出长度划分为多个类别 [73],每个类别具有不同的电力需求和延迟SLO(将在§5.1中讨论)。我们将Heron分解为三个关键组件,它们在不同时间尺度上运行:Planner-L、Planner-S和带有打包启发式的Request Scheduler。Planner-L以较粗的时间尺度运行(例如,15分钟),并分配TP程度、频率和负载。Planner-S每几秒运行一次,并根据近乎实时的电力和工作负载条件更新频率和负载,同时遵守Planner-L所做的TP分配。一个实时打包启发式算法与Request Scheduler一起运行,以进一步处理变化条件。我们将在下面详细说明它们。
表1:符号:Planner-L和Planner-S的ILP
| 符号 | 描述 |
|---|---|
| C , T C, T C,T | 工作负载类别和TP程度集合 |
| F , L F, L F,L | 所有频率和负载(每秒请求数)集合 |
| S S S | 风电场站点集合 |
| R L R_{L} RL | 重新配置限制 |
| N s , P s N_{s}, P_{s} Ns,Ps | 站点
s
s
s的GPU数量(调整规模,§2.2)和 功率(来自真实跟踪) |
| Load c _{c} c | 类别 c c c的峰值负载(来自生产跟踪) |
| T P _ G P U ( t ) T P \_G P U(t) TP_GPU(t) | TP程度 t t t所需的GPU数量 |
|
ϵ
2
ϵ
(
c
,
f
,
t
,
l
)
\epsilon 2 \epsilon(c, f, t, l)
ϵ2ϵ(c,f,t,l) power ( c , f , t , l ) (c, f, t, l) (c,f,t,l) | 类别 c c c,频率 f f f,TP t t t,负载 l l l(来自配置练习 - 查找表)的端到端延迟和功率 |
| Old c , f , t , s , l _{c, f, t, s, l} c,f,t,s,l | 上次迭代中类别[c, f, t, s, l]的GPU数量 |
| G P U s , c , t G P U_{s, c, t} GPUs,c,t | 分配给[s, c, t]的GPU数量 |
| X c , f , t , s , l X_{c, f, t, s, l} Xc,f,t,s,l | 类别[c, f, t, s, l]的实例数量 |
| Y c , f , t , s , l Y_{c, f, t, s, l} Yc,f,t,s,l | 如果类别[c, f, t, s, l]至少有一个实例,则设置二进制标志 |
| R c , f , t , s , l R_{c, f, t, s, l} Rc,f,t,s,l | 类别[c, f, t, s, l]的重新配置数量 |
| Z c , f , t , s , l Z_{c, f, t, s, l} Zc,f,t,s,l | Planner-S计算的GPU数量 |
ILP变量: X c , f , t , s , l X_{c, f, t, s, l} Xc,f,t,s,l
目标:最小化
∑
c
∈
C
,
f
∈
F
∑
t
∈
T
,
s
∈
S
,
l
∈
L
X
c
,
f
,
t
,
s
,
l
⋅
ϵ
2
ϵ
(
c
,
f
,
t
,
l
)
\sum_{c \in C, f \in F} \sum_{t \in T, s \in S, l \in L} X_{c, f, t, s, l} \cdot \epsilon 2 \epsilon(c, f, t, l)
∑c∈C,f∈F∑t∈T,s∈S,l∈LXc,f,t,s,l⋅ϵ2ϵ(c,f,t,l)
约束条件:
(1) 每个站点的GPU数量限制:
∀
s
∈
S
,
∑
c
∈
C
,
f
∈
F
,
t
∈
T
,
l
∈
L
X
c
,
f
,
t
,
s
,
l
⋅
T
P
_
G
P
U
(
t
)
≤
N
s
\forall s \in S, \sum_{c \in C, f \in F, t \in T, l \in L} X_{c, f, t, s, l} \cdot T P \_G P U(t) \leq N_{s}
∀s∈S,∑c∈C,f∈F,t∈T,l∈LXc,f,t,s,l⋅TP_GPU(t)≤Ns
(2) 每个站点的功率限制:
∀
s
∈
S
,
∑
c
∈
C
,
f
∈
F
,
t
∈
T
,
l
∈
L
X
c
,
f
,
t
,
s
,
l
⋅
power
(
c
,
f
,
t
,
l
)
≤
P
s
\forall s \in S, \sum_{c \in C, f \in F, t \in T, l \in L} X_{c, f, t, s, l} \cdot \operatorname{power}(c, f, t, l) \leq P_{s}
∀s∈S,∑c∈C,f∈F,t∈T,l∈LXc,f,t,s,l⋅power(c,f,t,l)≤Ps
(3) 每个类别的服务容量足够:
∀
c
∈
C
,
∑
s
∈
S
,
f
∈
F
,
t
∈
T
,
l
∈
L
X
c
,
f
,
t
,
s
,
l
⋅
l
≥
Load
c
\forall c \in C, \sum_{s \in S, f \in F, t \in T, l \in L} X_{c, f, t, s, l} \cdot l \geq \operatorname{Load}_{c}
∀c∈C,∑s∈S,f∈F,t∈T,l∈LXc,f,t,s,l⋅l≥Loadc
(4) 每个配置只有单一的
f
f
f和
l
l
l:
∀
s
∈
S
,
c
∈
C
,
t
∈
T
,
∑
f
∈
F
,
l
∈
L
Y
c
,
f
,
t
,
s
,
l
≤
1
\forall s \in S, c \in C, t \in T, \sum_{f \in F, l \in L} Y_{c, f, t, s, l} \leq 1
∀s∈S,c∈C,t∈T,∑f∈F,l∈LYc,f,t,s,l≤1
(5) 表达
Y
Y
Y与
X
X
X的关系:
∀
s
∈
S
,
c
∈
C
,
t
∈
T
,
f
∈
F
,
l
∈
L
,
1
≥
Y
c
,
f
,
t
,
s
,
l
≥
X
c
,
f
,
t
,
s
,
l
sum
(
N
S
)
\forall s \in S, c \in C, t \in T, f \in F, l \in L, 1 \geq Y_{c, f, t, s, l} \geq \frac{X_{c, f, t, s, l}}{\operatorname{sum}\left(N_{S}\right)}
∀s∈S,c∈C,t∈T,f∈F,l∈L,1≥Yc,f,t,s,l≥sum(NS)Xc,f,t,s,l
(6) 重新配置的数量有界:
∑
c
∈
C
,
f
∈
F
∑
t
∈
T
,
s
∈
S
,
l
∈
L
R
c
,
f
,
t
,
s
,
l
≤
R
L
\sum_{c \in C, f \in F} \sum_{t \in T, s \in S, l \in L} R_{c, f, t, s, l} \leq R_{L}
∑c∈C,f∈F∑t∈T,s∈S,l∈LRc,f,t,s,l≤RL
(7) 表达
R
c
,
f
,
t
,
s
,
l
,
∀
s
∈
S
,
c
∈
C
,
t
∈
T
,
f
∈
F
,
l
∈
L
R_{c, f, t, s, l}, \forall s \in S, c \in C, t \in T, f \in F, l \in L
Rc,f,t,s,l,∀s∈S,c∈C,t∈T,f∈F,l∈L,
R
c
,
f
,
t
,
s
,
l
≥
R_{c, f, t, s, l} \geq
Rc,f,t,s,l≥ Old
c
,
f
,
t
,
s
,
l
−
X
c
,
f
,
t
,
s
,
l
,
R
c
,
f
,
t
,
s
,
l
≥
X
c
,
f
,
t
,
s
,
l
−
_{c, f, t, s, l}-X_{c, f, t, s, l}, R_{c, f, t, s, l} \geq X_{c, f, t, s, l}-
c,f,t,s,l−Xc,f,t,s,l,Rc,f,t,s,l≥Xc,f,t,s,l− Old
c
,
f
,
t
,
s
,
l
_{c, f, t, s, l}
c,f,t,s,l
图10:公式:Planner-L的ILP
Planner-L。每个站点的工作负载到达和风力发电在15分钟粒度上都高度可预测(见§2),这些预测以及推理配置数据(一个查找表)被一个长期(15分钟)前瞻Planner-L ILP(整数线性规划)利用。基于预测,Planner-L制定了一个计划,为每个站点的推理请求类别(基于输入和输出长度)的下一个15分钟窗口的峰值负载分配实例(GPU)数量。此外,它还为特定站点的特定类别分配单一频率和负载的TP程度。我们应用此约束以在不影响最优性的情况下扩展ILP。类和频率的值详见§5.1。
Planner-L限制TP重新配置以进一步辅助隐藏重新配置开销的策略(在§5.2中讨论)。Planner-L输出TP和频率重新配置所需的内容,每个GPU实例的负载(RPS),以及每个类别的推理请求应路由到各个站点实例的比例。表1和图10详细说明了ILP的符号和公式——它将工作负载类别、TP程度、GPU运行频率、每类每实例的负载水平(在延迟SLO限制内的RPS)、每个站点的GPU数量和可用功率、每类请求的峰值负载以及之前的配置作为输入,并输出最小化推理端到端延迟的最佳实例数量。ILP最小化工作负载的总端到端延迟(从而不妥协用户体验),确保配置遵守(1)硬件和(2)每个站点的电力可用性约束,(3)每类请求都获得足够的服务能力以满足峰值负载,(4,5)服务某类请求的TP实例获得相同的频率分配以对应相同的负载,以及(6,7)每个时间槽所需的重新配置次数有界。
配置器。配置器负责更新不同GPU集群所需变化的站点特定配置器中的TP和运行频率。它限制Planner-S考虑具有待处理重新配置的集群进行工作负载放置。
ILP变量: Z c , f , t , s , l Z_{c, f, t, s, l} Zc,f,t,s,l
目标:最小化
∑
s
∈
S
,
c
∈
C
,
t
∈
T
∑
f
∈
F
,
l
∈
L
Z
c
,
f
,
t
,
s
,
l
⋅
ϵ
2
ϵ
(
c
,
f
,
t
,
l
)
\sum_{s \in S, c \in C, t \in T} \sum_{f \in F, l \in L} Z_{c, f, t, s, l} \cdot \epsilon 2 \epsilon(c, f, t, l)
∑s∈S,c∈C,t∈T∑f∈F,l∈LZc,f,t,s,l⋅ϵ2ϵ(c,f,t,l)
约束条件:
(1) 每个站点的功率限制:
∀
s
∈
S
,
∑
c
,
f
,
t
,
l
Z
c
,
f
,
t
,
s
,
l
⋅
power
(
c
,
f
,
t
,
l
)
≤
P
s
\forall s \in S, \sum_{c, f, t, l} Z_{c, f, t, s, l} \cdot \operatorname{power}(c, f, t, l) \leq P_{s}
∀s∈S,∑c,f,t,lZc,f,t,s,l⋅power(c,f,t,l)≤Ps
(2) 每类有足够的服务能力:
∀
c
∈
C
,
∑
s
∈
S
,
f
∈
F
,
t
∈
T
,
l
∈
L
Z
c
,
f
,
t
,
s
,
l
⋅
l
≥
Load
c
\forall c \in C, \sum_{s \in S, f \in F, t \in T, l \in L} Z_{c, f, t, s, l} \cdot l \geq \operatorname{Load}_{c}
∀c∈C,∑s∈S,f∈F,t∈T,l∈LZc,f,t,s,l⋅l≥Loadc
(3) 每个配置的GPU数量限制:
∀
s
∈
S
,
c
∈
C
,
t
∈
T
,
∑
l
∈
L
,
f
∈
F
Z
c
,
f
,
t
,
s
,
l
≤
G
P
U
s
,
c
,
t
\forall s \in S, c \in C, t \in T, \sum_{l \in L, f \in F} Z_{c, f, t, s, l} \leq G P U_{s, c, t}
∀s∈S,c∈C,t∈T,∑l∈L,f∈FZc,f,t,s,l≤GPUs,c,t
图11:公式:Planner-S的ILP
Planner-S。虽然Planner-L每15分钟运行一次并重新配置TP、运行频率和每GPU实例的负载,但我们每几秒到几十秒运行一个轻量级的Planner-S(受站点数量增长的可扩展性限制;见§5.3),仅重新配置频率和负载,因为TP变化较重。在更细的时间尺度上运行Planner-S有两个主要好处:(1)它可以应对近实时的电力和工作负载到达不确定性,(2)当可用电力增加时,它可以通过以高于Planner-L分配的GPU频率运行请求来释放性能机会,从而改善TTFT和TBT延迟。
Planner-S也是一个ILP(表1中的符号和图11中的公式),它重新计算每个配置的最佳频率和负载分配。请注意,Planner-S与Planner-L具有相同的目标(最小化端到端延迟),但仅重新配置频率(执行速度更快且开销极小),同时使用Planner-L计算的TP。ILP变量 Z o , f , t , s , l Z_{o, f, t, s, l} Zo,f,t,s,l表示为每个配置(站点、类别和TP程度的元组)分配的实例数量及频率和负载。请注意,仅对个体配置重新分配频率和负载。约束条件是:(1)满足功率约束,(2)服务能力足以应对峰值负载,(3)符合Planner-L分配的相同GPU预算。
请注意,Planner-L和Planner-S的公式可以简单地修改为最小化能耗。
请求调度器。该组件负责在到达队列中的推理请求到达时跨多个站点分发这些请求。它使用Planner-S的输出来学习权重,以便对每类(输入/输出长度)请求跨分配给各类别的GPU集群执行加权轮询(WRR)路由。为了将类别分配给请求,它使用了一个请求类别预测器,该预测器以请求和模型作为输入,预测输出长度,从而确定类别。我们的预测器包含一个Albert/DistilBert/Longformer [14, 46, 67] 层用于输入嵌入,然后是一个回归器,可以以99.95%以上的准确率预测输出长度区间(短/中/长)。因此,按照DynamoLLM [73]的脚步,我们在实验中将输出长度视为预言。请求调度器还具有一种打包启发式方法,我们将在接下来描述。
打包启发式方法。如果请求调度器在线观察到某个GPU实例的请求类别负载低于预期,它会将一部分较小的请求(例如LS)移动到这个类别(例如LM)以提高性能。它从较大的请求开始,重新分配并逐步移动到较小的请求,在每一步释放资源。
元选择。(1)Heron可以在AI提供者的网络入口或靠近DC处部署以拦截工作负载。(2)我们排除了完整的DC和现场电池/发电机,以测试Heron处理剩余电力和工作负载到达不确定性的能力。(3)尽管Heron支持任何本地站点调度器,但在本工作中我们使用了一个FIFO轮询调度器来进行GPU分配。
5 HERON评估
我们探讨以下关键问题(以及其他问题):§5.1:当工作负载以不同的TP、频率和负载组合运行时,功耗和延迟如何变化?§5.2:拥有跨站点全局视图如何在不确定性下提高提供的吞吐量?§5.3:分层设计是否释放Heron的性能?
数据。对于以下实验,我们使用以下数据:(1)Azure上的两个用例(编码和对话)的一周LLM推理生产跟踪记录 [11]。图12显示了Azure上对话和编码生产跟踪记录的特征差异。输入(左图)在1到约8K令牌之间变化,编码输入的中位数约为对话的2倍。输出(中间图)在约1K令牌内,对话在第95百分位时的输出约为编码的6倍。
(2)冰岛、挪威、瑞士和英国四个风电场每小时发电量(假设峰值发电量为250MW,根据§2.2中的讨论;在EMHIRES中归一化为1.0)的672小时数据(见图6),来自2015年的EMHIRES [85]。对于我们的实验,我们将时间维度缩小0.25倍,从而将其转换为15分钟粒度的一周发电数据。我们无法使用ELIA数据(见§2.3.2),因为它仅涵盖比利时的两个地区。(3)上述四个风电场在2015年全年每小时粒度上的第20百分位发电量,记录在EMHIRES中。这些长期阈值(冰岛:29MW,挪威:16.5MW,瑞士:7MW,英国:13.25MW)因当地条件而异,并决定了配置的计算集群大小。我们在模拟中以NVIDIA H100 SuperPODS(1,016 GPUs,1.3 MW峰值功率消耗)的倍数部署计算。
5.1 工作负载分析
对于每个生产跟踪记录,我们将请求分为9个桶[SS, SM, SL, MS, MM, ML, LS, LM, LL]——输入和输出的3×3组合,分别为短(整个星期的第33百分位),中(第66百分位),和长(第100百分位)。我们在H100 DGX和Llama 3.1 70B模型上分析了每类请求的峰值功率、平均功率、首次标记时间(TTFT)、标记间时间(TBT)和端到端(E2E)延迟,针对不同组合的负载(每秒请求数)、张量并行性(TP2、TP4和TP8)以及GPU频率(0.8、1、1.2、1.4、1.6、1.8和2 GHz)。对于每个类 c c c、频率 f f f、TP t t t和负载 l l l的组合,GPU实例(多块GPU;例如TP8需要8块)服务于负载 l l l的泊松到达请求5分钟,并通过NVIDIA的DCGM接口[3]提取功率消耗统计数据,以及通过vLLM[6]服务引擎提取延迟统计数据。单个特定类别的请求在TP8和2 GHz频率下独立运行时,TTFT和TBT延迟SLO设置为其值的5倍。
图13显示了在不同TP和频率组合下,对话(左)和编码(右)工作负载的MM请求在各种负载级别(每秒请求数或RPS)下的峰值功率和E2E延迟。灰色单元格(右上角)表示TTFT/TBT违规——注意TP2无法支持此类请求的任何高于0.5次/秒的负载。对于特定的TP和频率,随着负载增加,峰值功率消耗和延迟(E2E以及TTFT)都会增加。在其他条件不变的情况下,更高的TP程度(或更大的操作频率)会导致更好的延迟,但代价是更高的功率消耗。我们已经验证了两种轨迹的不同类别趋势相似,尽管确切的阈值不同。编码轨迹通常具有更大的输入(上下文),因此相对于对话来说无法承受高负载水平(SLO违规)。
分析练习生成了查找表(函数)如e2e(c, f, t, l)和power(c, f, t, l),涵盖了对话和编码轨迹的所有请求类别,这些被Heron利用。需要注意的是,Heron仅考虑那些不会导致TTFT/TBT SLO违规的[c, f, t, s, l]组合。此外,我们在所有后续实验中使用了从power(c, f, t, l)得出的所有功率数字的固定倍数1.82,以容纳其他组件(CPU、风扇、网络、内存)的混合。每个H100 DGX盒子(8块GPU)的峰值功率消耗为10.2千瓦,这比8块GPU的总峰值功率(8 × 700瓦)高出1.82倍。
5.2 Planner-L组件测试
现在我们单独观察Planner-L的实际运行情况(没有Heron组件Planner-S和请求调度器的打包启发式)。这项练习展示了拥有跨多个站点的全局视图(类似于SDN的控制平面[82])以及对电力可变性的感知如何帮助Heron超越当前使用本地站点视图和简单轮询路由的基线所实现的性能。这也帮助量化了其他Heron组件在§5.3中的增量收益。对于以下实验,我们假设Planner-L的决策被请求调度器和配置器盲目遵循。
设置。我们对两周的模拟进行了两次生产跟踪,分别在欧洲的四个风力发电站上运行Llama 3.1 70B参数模型。我们将两个Planner-L调度器变体与两个基线进行比较如下:(a) Planner-L-min-power: 目标是最小化总功耗。(b) Planner-L-min-latency: 目标是最小化每15分钟的总E2E延迟。© WRR (加权轮询) + DynamoLLM: DynamoLLM调度器[73]试图随着时间减少功耗(能量)。WRR路由器按比例转发各站点计算能力分配的传入请求。(d) 贪婪最低延迟基线:一种尝试通过为GPU实例分配TP8、最高运行频率和最低负载水平来实现低延迟的启发式算法。然而,我们观察到由于GPU容量限制,它无法分配~33%的请求。为了解决这一局限性,我们根据需要增加每个GPU实例的负载,但仍分配TP8和最高频率。我们观察到延迟与负载曲线会产生一个“拐点”——在此点之前,延迟增加很小。我们计算了每类请求的拐点,并将每个GPU实例的负载限制在这些拐点内。
Planner-L提供了高吞吐量。我们首先以15分钟粒度运行4个调度器,并比较图14(左)中调度器遇到不足以支持全部传入工作负载的功率的情况的频率。由于DynamoLLM或最低延迟基线不了解功率可变性,且WRR路由器无法利用站点间的功率互补性,它们在每个站点分配了超过服务能力的工作负载,导致请求丢弃。图14(左)显示了在不同编码工作负载体积(x-倍于生产跟踪中的到达率)的一周内,调度器因本地电力不可用而遇到请求丢弃的频率(至少有一个请求丢弃的15分钟时段数量)。两个Planner-L变体(最小功耗和最小延迟)都可以在没有请求丢弃的情况下显著处理更高工作负载。本质上,在极端资源受限情况下,Planner-L最小延迟收敛到Planner-L最小功耗——如果Planner-L最小功耗已经因资源限制而丢弃请求,那么Planner-L最小延迟能提供的最佳计划与最小功耗相同;因此,图中有重叠。另外,请注意我们未使用电池、发电机或完整的数据中心的选择是对Planner-L的压力测试。在实际部署中,Planner-L实际上可以保证无请求丢弃,因其具备功率可变性意识。
接下来,对于固定倍数为60倍的传入编码工作负载,我们绘制了Planner-L(两个版本一致)相对于两个基线(c和d)的吞吐量改进因子。此改进因子是Planner-L与相应基线的吞吐量之比。图14(中间)显示,Planner-L(因此Heron)相比基线最多可提升1.8倍的吞吐量。请注意,由于我们在§2.2中的计算调整策略,四个选项中的任何一个在80%以上的时间(y=0.8)都没有困难处理工作负载。即使在图14(中间)中表现良好的基线实际上是我们的另一个重要贡献之一(参见§2.2中的部署调整策略)。在某些情况下,吞吐量改进因子在超过80百分位标记时仍然保持为1,这是因为站点的功率下降时,工作负载到达率也下降。顶部右侧的质量(80%的吞吐量改进)对应于冰岛站点有时完全关闭的情景——HERON(Planner-L)提前智能地将工作负载分配到其他站点。类似地,图15显示了在与§5.2相同的设置下,Heron(Planner-L)在使用WRR路由的对话跟踪中的吞吐量改进为基线的50倍。我们看到两种Planner-L变体均实现了1.8倍的改进,且无需丢弃请求,这得益于Heron利用空间发电互补性的能力。
Planner-L变体提供权衡。图16展示了Planner-L的两种变体在整个星期内对编码跟踪(60倍)所提供的权衡。我们拟合了一条三次曲线来表示Planner-L最小延迟与最小功率版本相比的E2E延迟百分比改进和相应的功率膨胀百分比(所有请求的每15分钟插槽的平均值)。25%(同样,50%)的E2E延迟改进带来了42%(同样,198%)的功率膨胀成本。对于对话(50倍)跟踪,25%的延迟改进对应49%的功率膨胀。
Planner-L配置粘性。Planner-L ILP使用重新配置阈值RL(X%)来限制每15分钟插槽允许的TP变化次数(风力发电场的变化是渐进的,跨越多个这样的时间段)。我们对两个工作负载进行了为期一周的实验,使用了不同的RL值,发现即使RL值低至3%,也没有显著增加95百分位(跨时间段)的平均E2E延迟或平均功耗。然而,当RL<3%时,延迟有所增加。
Planner-L的可扩展性。图14(右)绘制了Planner-L在标准CPU上针对不同数量风电场的执行时间(以及我们稍后讨论的其他Heron组件)。请注意,它在我们测试的范围内呈线性增长(y轴为对数刻度),始终消耗≤1%的CPU和≤1GB RAM。即使对于64个风电场站点(累计功率2+GW),它也能在6分钟内执行完毕,远远低于15分钟的预算。我们在实验中使用了COIN-OR [19]求解器,如果需要,ILP可以通过运行商业求解器如CPLEX [79]并使用多核来加速。
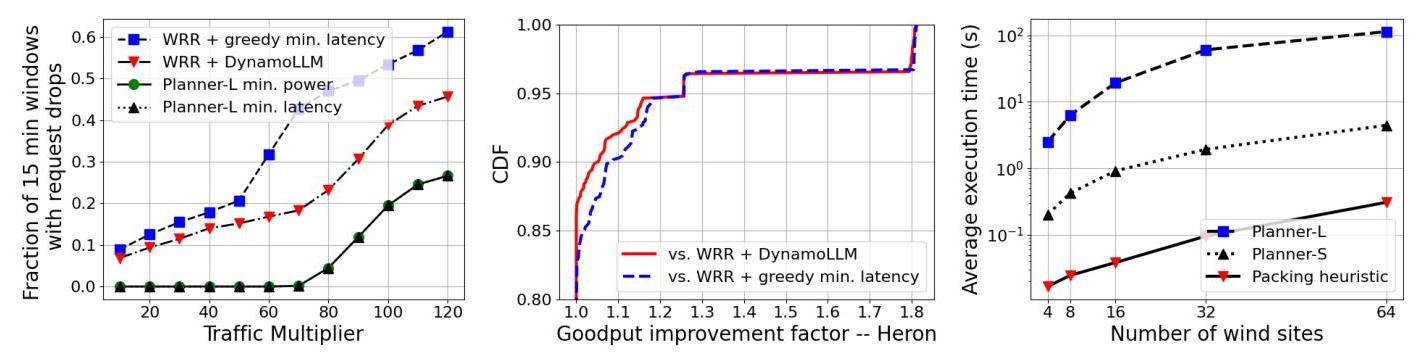
图14:(左)在不同编码工作负载量下,基线导致更频繁的请求丢弃。(中)对于给定的工作负载,Heron(planner-L)在较高百分位数(残余不确定性)下的吞吐量因子显著更高。(右)Heron组件的执行时间。
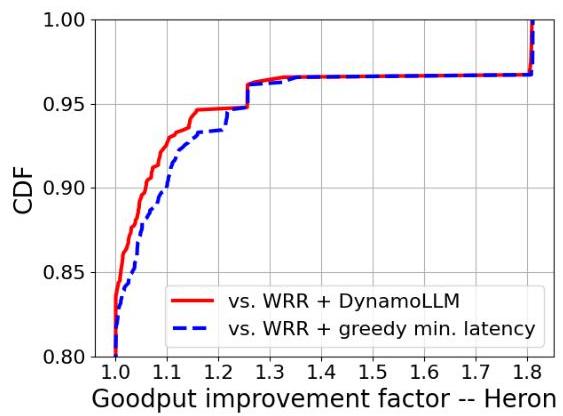
图15:对于对话(50×)工作负载,在较高百分位数(残余不确定性)下,Heron(planner-L)的吞吐量因子显著更高。
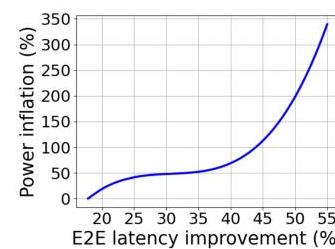
图16:Planner-L最小延迟以更高的功耗提供更低的延迟,相较于Planner-L最小功耗。
对于以上所有结果,编码和对话之间的总体观察和趋势相似。因此,我们专注于其中一个,根据需要报告另一个。
5.3 释放更多性能
Planner-S每5秒在此设置中运行一次,涉及4个风电场站点,重新配置运行频率和负载,贪婪打包启发式方法(与请求调度器一起)在线贪婪地将较小的请求打包到为较大请求配置的GPU实例中(例如LS请求可以
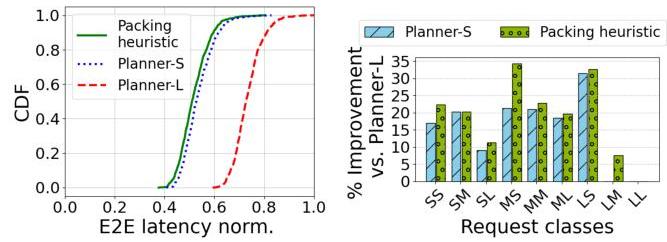
图17:(左)Planner-S和贪婪打包启发式方法在Planner-L(最小延迟)分配的基础上逐步改进E2E延迟。(右)Planner-L基础上的逐类请求平均E2E延迟改进。
被分配到LM实例)从而导致E2E延迟改进。在图17中,我们展示了这些组件与Planner-L(最小延迟)协同运行时在一个15分钟插槽中的增量延迟效益。CDF图(图17,左)显示了当请求基于Planner-L、Planner-L+S和Planner-L+S+打包启发式方法分配时的E2E延迟(每秒平均值)。在中位数时,与仅Planner-L相比,Planner-S和打包启发式方法分别使E2E延迟总体改进了27%和额外的3%。对于对话跟踪,Planner-S在中位数时比Planner-L最小延迟延迟改进了12%,而打包启发式方法进一步提高了2%。图17(右)显示了Planner-L基础上逐类请求的平均延迟减少情况,增量改进在7.5%到34.4%之间,LL请求没有改进,因为打包启发式方法没有更好的类别可以分配这些请求。请注意,在这种情况下,Planner-L和Planner-S都以相同的优化目标运行,即最小化E2E延迟。
Planner-S的功率弹性。我们通过将可用功率减少20%并仍按照Planner-L分配进行路由来压力测试Planner-L。我们在随机选取的5秒窗口内观察到,仅在一个1秒窗口中,约7%的请求必须被丢弃以保持在减少的功率预算内(低于预期)。然而,Planner-S能够容纳这个1秒窗口中的所有请求。
可扩展性。如图14(右)所示,Planner-S比Planner-L快约30倍。对于小型设置(4个风力发电站),Planner-S可以在一秒内运行多次,而对于大型64个站点部署,它可以每5秒运行一次(15分钟内运行180次)。因此,由于Planner-S不触碰TP配置,Planner-S可以比Planner-L精细几个数量级。打包启发式方法再次显著快于其他组件(即使是更大规模部署也在亚秒级别),并且可以与在线请求调度器一起运行。
6 相关工作
运行在可再生能源上的数据中心。以前的研究作品[35, 39, 49, 70, 84]探讨了利用太阳能、电池、电网抽取和调度优化的可再生能源供电的数据中心。AI Greenferencing的关键区别在于:(1) 动机:我们旨在解锁更多的AI计算,以应对不断增长的电力需求。(2) 电源来源:我们关注风能,因为太阳能发电需要严重依赖电池或发电机。(3) 规模调整:我们建议在更大的风电场中部署更小的计算,这一策略显著减少了电力不确定性。(4) 跨站点:我们的工作利用了站点间的电力互补性。(5) 工作负载:AI推理对电力波动的适应性比传统工作负载更强。
将计算移向电源。Virtual Battery & SkyBox [9, 74] 利用站点间可再生能源的互补性来运行计算。与AI Greenferencing的区别在于:(1) 配置:我们不仅关注电力互补性,还关注计算规模调整和智能路由软件。(2) 可扩展性:SkyBox不利用发电量变化大的站点,而我们仍然可以包括这些站点。(3) 工作负载:SkyBox专注于较重的虚拟机放置和迁移。我们则专注于AI推理请求的智能路由。
能源感知AI推理。DynamoLLM [73] 通过调整TP程度和GPU频率来最小化AI推理中的能耗/功率消耗。虽然我们基于这项工作构建了Heron,但关键区别在于:(1) 跨站点:我们的工作重点是跨站点路由,而不是特定站点的调度。(2) 假设:DynamoLLM假设没有电力或计算限制,而我们在风力站点受到两方面的限制。(3) 方法:我们对电力变化有感知。
7 讨论
电池/发电机。它们通过往返损失、混合能源组合和更高的CAPEX代价缓解了一些风力发电的不确定性。在这里,我们在不使用任何这些附加模式的情况下对Heron进行了压力测试,而是利用适当配置、电力互补性和应用/基础设施旋钮来应对电力不确定性。
超越风能。我们把探索其他可持续能源来源用于AI工作负载留作未来工作。太阳能发电场面临约50%的不可用性,需要昂贵的电池/发电机备份,增加了CAPEX和OPEX。虽然核电因其稳定的基荷负荷而受到大AI玩家的关注[21, 75],但它也有自己的挑战:(1) 高CAPEX,(2) 核废料管理,(3) 公众认知和法规,(4) 限制区域,(5) 长期建设时间。
GPU淘汰。随着像NVIDIA这样的GPU领导者几乎每年宣布新一代产品,超大规模公司需要具体计划来淘汰快速老化的GPU。AI Greenferencing可以帮助将这些GPU运送到风力发电场,并以低成本运行相关AI工作负载的一部分。
自主维护。除了培训当地劳动力进行基本集群维护外,还可以在这些MDCs中引入廉价机器人进行基本维修任务[44]。
大象与老鼠。在AI Greenferencing中,大型风力发电场与较小的部署配对可能会造成不平衡,要求超出较小站点容量的重新路由。图2(a)显示数据中心在低网络延迟范围内有多样化的风力发电场,使得大规模部署能够有效处理电力不确定性。
模型的安全性。AI推理提供商可以选择部署自己的计算资源,或者利用第三方计算资源(初创公司[5,7,8]在风力发电场共址计算资源)。采用后者方法时,AI提供商需要诉诸隐私保护的模型分割技术[31, 38]。
8 结论
AI Greenferencing将AI计算带到风能源处,绕过电力传输挑战,以可持续方式满足日益增长的AI需求。我们提出了可行性研究和调整策略以减轻风能不确定性。我们的跨站点路由器高效管理残余不确定性,交付高达现有最先进解决方案1.8倍的吞吐量。这项工作没有引发任何伦理问题。
参考文献
[1] 2023. Azure locations (public). https://gist.github.com/lpellegr/8ed20 4b10c2589a1fb925a160191b974. (2023).
[2] 2024. GCP locations (public). https://github.com/GoogleCloudPlatfo rm/region-picker/blob/main/data/regions.json. (2024).
[3] 2025. DCGML https://microsoft.github.io/VirtualClient/docs/workloa ds/dcgml/. (2025).
[4] 2025. NVIDIA H100 Tensor Core GPU. https://resources.nvidia.com/e n-us-tensor-core/nvidia-tensor-core-gpu-datasheet. (2025).
[5] 2025. Soluna. https://www.solunacomputing.com/. (2025).
[6] 2025. vLLM. https://docs.vllm.ai/en/latest/. (2025).
[7] 2025. WestfalenWIND. https://www.westfalenwind.de/. (2025).
[8] 2025. windCORES. https://www.windcores.de/en/. (2025).
[9] Anup Agarwal, Jinghan Sun, Shadi Noghabi, Srinivasan Iyengar, Anirudh Badam, Ranveer Chandra, Srinivasan Seshan, and Shivkumar Kalyanaraman. 2021. Redesigning data centers for renewable energy. In ACM HotNets.
[10] Azure. 2025. Azure Modular Data Center (MDC) Operator and User Documentation. https://learn.microsoft.com/en-us/azure-stack/mdc/. (2025).
[11] AzurePublicDataset. 2025. Azure LLM inference trace 2024. https://github.com/Azure/AzurePublicDataset/blob/master/AzureLLMInferenceDataset2024.md. (2025).
[12] Jeff Barr. 2019. Amazon EC2 Update - Inf1 Instances with AWS Inferentia Chips for High Performance Cost-Effective Inferencing. https://aws.amazon.com/blogs/aws/amazon-ec2-update-inf1-insta nces-with-aws-inferentia-chips-for-high-performance-cost-effectiv e-inferencing/. (2019).
[13] Luiz André Barroso, Urs Hölzle, and Parthasarathy Ranganathan. 2019. The datacenter as a computer: Designing warehouse-scale machines. Springer Nature.
[14] Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. arXiv:2004.05150 (2020).
[15] Berkeley Lab. 2024. Land-based wind market report. https://emp.lbl.gov/sites/default/files/2024-08/Land-Based\ Wind\ Market\ Report_2024\ Edition.pdf. (2024).
[16] Alexander Bick, Adam Blandin, and David J Deming. 2024. The rapid adoption of generative AI. Technical Report. National Bureau of Economic Research.
[17] Ilker Nadi Bozkurt, Waqar Aqeel, Debopam Bhattacherjee, Balakrishnan Chandrasekaran, Philip Brighten Godfrey, Gregory Laughlin, Bruce M Maggs, and Ankit Singla. 2018. Dissecting Latency in the Internet’s Fiber Infrastructure. arXiv:1811.10737 (2018).
[18] Clean Energy Wire. 2024. Industry electricity prices for German companies drop almost one quarter in early 2024. https://www.cleane nergywire.org/news/industry-electricity-prices-german-companies -drop-almost-one-quarter-early-2024. (2024).
[19] COIN-OR Foundation. 2025. COIN-OR. https://www.coin-or.org/. (2025).
[20] CoreSite. 2024. AI and the Data Center: Driving Greater Power Density. https://www.coresite.com/blog/ai-and-the-data-center-driving-gre ater-power-density. (2024).
[21] Casey Crownhart. 2024. Why Microsoft made a deal to help restart Three Mile Island. https://www.technologyreview.com/2024/09/26/11 04516/three-mile-island-microsoft/. (2024).
[22] Databank. 2024. Exploring Modular Data Centers: Benefits, Design, And Deployment. https://www.databank.com/resources/blogs/explori ng-modular-data-centers. (2024).
[23] Tim De Chant. 2024. Google kicks off $20 B renewable energy building spree to power AI. https://techcrunch.com/2024/12/10/google-kicks-o ff-20b-renewable-energy-building-spree-to-power-ai/. (2024).
[24] Delta Power Solutions. 2024. Modular Data Centers: The Rise and the Advantages. https://www.deltapowersolutions.com/en-in/mcis/techn ical-article-modular-data-centers-the-rise-and-the-advantages.php. (2024).
[25] Diana DiGangi. 2023. Dominion Energy projects adding up to 9 GW of gas-fired capacity in Virginia to bolster reliability. https://tinyurl.com/4fbeds24. (2023).
[26] EIA. 2024. Why are Midwest grid operators turning away wind power? https://www.eia.gov/todayinenergy/detail.php?id=62406. (2024).
[27] EIA. 2025. Electric Power Monthly. https://www.eia.gov/electricity/monthly/epm_table_grapher.php?t=epmt_5_6_a. (2025).
[28] Elia. 2025. Wind power generation. https://www.elia.be/en/grid-data/generation-data/wind-power-generation. (2025).
[29] Robert L Fares and Carey W King. 2017. Trends in transmission, distribution, and administration costs for US investor-owned electric utilities. Energy Policy (2017).
[30] Karl Freund. 2024. Welcome To 2024. It Promises To Be Quite The AI Ride! https://www.forbes.com/sites/karlfreund/2024/01/04/welcome-t o-2024-it-promises-to-be-quite-the-ai-ride/. (2024).
[31] Shucun Fu, Fang Dong, Dian Shen, and Tianyang Lu. 2024. Privacy-preserving model splitting and quality-aware device association for federated edge learning. Software: Practice and Experience (2024).
[32] Bill Gates. 2023. The surprising key to a clean energy future. https://www.gatesnotes.com/Transmission. (2023).
[33] GitHub. 2025. GitHub Copilot. https://github.com/features/copilot. (2025).
[34] Global Energy Monitor. 2024. Global Wind Power Tracker. https://globalenergymonitor.org/projects/global-wind-power-tracker/. (2024).
[35] Iñigo Goiri, William Katsak, Kien Le, Thu D Nguyen, and Ricardo Bianchini. 2013. Parasol and greenswitch: Managing datacenters powered by renewable energy. ACM SIGPLAN Notices (2013).
[36] Google. 2023. Gemini. https://blog.google/technology/ai/google-gemini-ai/. (2023).
[37] Diana Goovaerts and Matt Hamblen. 2024. Could GPU power levels break the data center ecosystem? https://www.fierce-network.com/cloud/could-gpu-power-levels-break-data-center-ecosystem. (2024).
[38] Jialin Guo, Jie Wu, Anfeng Liu, and Neal N Xiong. 2021. LightFed: An efficient and secure federated edge learning system on model splitting. IEEE TPDS (2021).
[39] Md E Haque, IZigo Goiri, Ricardo Bianchini, and Thu D Nguyen. 2015. Greenpar: Scheduling parallel high performance applications in green datacenters. In ACM ICS.
[40] Dylan Harrison-Atlas, Anthony Lopez, and Eric Lantz. 2022. Dynamic land use implications of rapidly expanding and evolving wind power deployment. Environmental Research Letters (2022).
[41] Astrid Hennevogl-Kaulhausen and Ulrike Ostler. 2024. Modular data centers: Faster, more flexible and more energy-efficient in the data centers. https://www.deltapowersolutions.com/en-in/mcis/technical -article-modular-data-centers-faster-more-flexible-and-more-energ y-efficient-in-the-data-centers.php. (2024).
[42] Javier C. Hernandez. 2017. It Can Power a Small Nation. But This Wind Farm in China Is Mostly Idle. https://www.nytimes.com/2017/0 1/15/world/asia/china-gansu-wind-farm.html. (2017).
[43] Bobby Hollis. 2024. Accelerating the addition of carbon-free energy: An update on progress. https://www.microsoft.com/en-us/microsoft t-cloud/blog/2024/09/20/accelerating-the-addition-of-carbon-free-e nergy-an-update-on-progress/. (2024).
[44] Freddie Hong, Iason Sarantopoulos, Elliott Hogg, David Richardson, Yizhong Zhang, Hugh Williams, David Sweeney, Andromachi Chatzieleftheriou, and Antony Rowstron. 2024. Self-maintaining [networked] systems: The rise of datacenter robotics!. In ACM HotNets.
[45] Peeyush Kumar, Ranveer Chandra, Chetan Bansal, Shivkumar Kalyanaraman, Tamuja Ganu, and Michael Grant. 2021. Micro-climate prediction-multi scale encoder-decoder based deep learning framework. In ACM SIGKDD.
[46] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. (2020). arXiv.v.s.CL/1909.11942 https://arxiv.org/abs/1909.11942
[47] Lawrence Berkeley National Laboratory. 2024. Queued Up: 2024 Edition. https://emp.lbl.gov/sites/default/files/2024-04/Queued\ 2024\ 2024%20Edition_R2.pdf. (2024).
[48] Vivian Lee. 2024. U.S. Data Center Power Outlook: Balancing competing power consumption needs. https://www.linkedin.com/pulse/us-d ata-center-power-outlook-balancing-competing-consumption-lee-i z4pe/. (2024).
[49] Chao Li, Amer Qouneh, and Tao Li. 2012. iSwitch: Coordinating and optimizing renewable energy powered server clusters. ACM SIGARCH Computer Architecture News (2012).
[50] Bryan Lim, Nicolas Loeff, Sercan Arik, and Tomas Pfister. 2021. Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting.
[51] Sasha Luccioni, Yacine Jernite, and Emma Strubell. 2024. Power hungry processing: Watts driving the cost of AI deployment?. In The 2024 ACM Conference on Fairness, Accountability, and Transparen------
cy.
[52] Shreya Mandi, Srinivas Varadarajan, Kalyan Mangalapalli, Tanvi Lall, Mohan Srinivas, Sasank
Chilamkurthy 和 Swaroop Rajagopalan。2024。微型是新的巨型。https://tinyurl.com/47rk6ptb。(2024)。
[53] 麦肯锡公司。2024
------。电力在解锁欧洲AI革命中的作用。https://tinyurl.com/bdf952sr。(2024)。
[54] Meta。2023。Llama 2。https://www.llama.com/llama2/。(2023)。
[55] Meta。2024。Llama 3.1。https://ai.meta.com/blog/meta-llama-3-1/。(2024)。
[56] NVIDIA。2023。NVIDIA DGX SuperPOD 数据中心设计。https://docs.nvidia.com/nvidia-dgx-superpod-data-center-design-dgx-h100.pdf。(2023)。
[57] NVIDIA。2025。NVIDIA 数据中心 GPU。https://www.nvidia.com/en-in/data-center/data-center-gpus/。(2025)。
[58] OpenAI。2023。GPT-3.5 Turbo。https://platform.openai.com/docs/model#gpt-3-5-turbo。(2023)。
[59] OpenAI。2023。GPT-4。https://openai.com/index/gpt-4/。(2023)。
[60] 我们的能源世界。2023。风力发电场需要多少土地?https://www.ourworldofenergy.com/vignettes.php?type=wind-power&id=9。(2023)。
[61] Dylan Patel,Daniel Nishball 和 Jeremie Eliahou Ontiveros。2024。AI 数据中心能源困境——AI 数据中心空间竞赛。https://semianalysis.com/2024/03/13/ai-datacenter-energy-dilemma-race/#datacenter-math。(2024)。
[62] Pratyush Patel,Esha Choukse,Chaojie Zhang,İtigo Goiri,Brijesh Warrier,Nithish Mahalingam 和 Ricardo Bianchini。2024。表征云中LLM的电源管理机会。在ACM ASPLOS中。
[63] Cheng Peng,Xi Yang,Aokun Chen,Kaleb E Smith,Nima PourNejatian,Anthony B Costa,Cheryl Martin,Mona G Flores,Ying Zhang,Tanja Magoc 等。2023。生成大型语言模型在医学研究和医疗保健中的应用研究。NPJ数字医学(2023)。
[64] 路透社。2022。德国采取新措施应对能源危机。https://www.weforum.org/stories/2022/08/energy-crisis-germany-europe/。(2022)。
[65] Martin Rosenberg。2024。Evergy努力减少碳排放,因为能源需求激增。https://tinyurl.com/mtw7rmj6。(2024)。
[66] 高盛。2024。AI有望推动数据中心电力需求增长160%。https://www.goldmansachs.com/insights/articles/A1-poised-to-drive-160-increase-in-power-demand。(2024)。
[67] Victor Sanh,Lysandre Debut,Julien Chaumond 和 Thomas Wolf。2020。DistilBERT,BERT的精简版:更小、更快、更便宜、更轻便。(2020)。arXiv:cs.CL/1910.01108 https://arxiv.org/abs/1910.01108
[68] Anton Shilov。2023。据报道,NVIDIA将在2024年将计算GPU产量提高三倍:高达2百万个H100。https://www.tomshardware.com/news/nvidia-to-reportedly-triple-output-of-compute-gpus-in-2024-up-to-2-million-h100s。(2023)。
[69] Anton Shilov。2023。NVIDIA将在2023年销售55万个H100 GPU用于AI。https://www.tomshardware.com/news/nvidia-to-sell-550000-h100-compute-gpus-in-2023-report。(2023)。
[70] Rahul Singh,David Irwin,Prashant Shenoy 和 Kadangode K Ramakrishnan。2013。Yank:使绿色数据中心能够拔掉插头。在USENIX NSDI中。
[71] Jared Spataro。2023。Microsoft 365 Copilot。https://blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot-your-copilot-for-work/。(2023)。
[72] statista。2024。美国2008年至2022年平均平准PPA风电价格。https://www.statista.com/statistics/217841/us-cumulative-capacity-weighted-average-wind-power-price/。(2024)。
[73] Jovan Stojkovic,Chaojie Zhang,İtigo Goiri,Josep Torrellas 和 Esha Choukse。2025。Dynamollm:为性能和能效设计的LLM推理集群。在IEEE HPCA中。
[74] Jinghan Sun,Zibo Gong,Anup Agarwal,Shadi Noghabi,Ranveer Chandra,Marc Snir 和 Jian Huang。2024。探索基于可再生能源的大规模模块化数据中心的效率。在ACM SoCC中。
[75] Michael Terrell。2024。与Kairos Power的新核清洁能源协议。https://blog.google/outreach-initiatives/sustainability/google-kairos-power-nuclear-energy-agreement/。(2024)。
[76] Thunder Said Energy。2024。美国电力公司:输电和配电成本?https://thundersaidenergy.com/downloads/us-electric-utilities-transmission-and-distribution-costs/。(2024)。
[77] 美国能源部。2022。风能的优势与挑战。https://www.energy.gov/eere/wind/advantages-and-challenges-wind-energy。(2022)。
[78] Ashish Vaswani,Noam Shazeer,Niki Parmar,Jakob Uszkoreit,Llion Jones,Aidan N. Gomez,Łukasz Kaiser 和 Illia Polosukhin。2017。注意力就是你所需要的全部。CoRR abs/1706.03762(2017)。http://arxiv.org/abs/1706.03762
[79] 维基百科。2025。CPLEX。https://en.wikipedia.org/wiki/CPLEX。(2025)。
[80] 维基百科。2025。能源组合。https://en.wikipedia.org/wiki/Energy_mix。(2025)。
[81] 维基百科。2025。亚历山大的希罗。https://en.wikipedia.org/wiki/Hero_of_Alexandria。(2025)。
[82] 维基百科。2025。软件定义网络。https://en.wikipedia.org/wiki/Software-defined_networking。(2025)。
[83] 维基百科。2025。英国风能:限制支付。https://en.wikipedia.org/wiki/Wind_power_in_the_United_Kingdom#Constraint_payments。(2025)。
[84] Fan Yang 和 Andrew A Chien。2016。ZCCloud:利用浪费的绿色电力进行高性能计算。在IEEE IPDPS中。
[85] Zenodo。2021。EMHIRES 数据集:风电和太阳能发电。https://zenodo.org/records/8340501。(2021)。
[86] Mary Zhang。2023。数据中心维护:全面指南。https://dgflinfra.com/data-center-maintenance/。(2023)。
[87] Zhong Yinmin,Liu Shengyu,Chen Junda,Hu Jianbo,Zhu Yibo,Liu Xuanzhe,Jin Xin 和 Zhang Hao。2024。Distserve:分离预填充和解码以优化大型语言模型服务的吞吐量。arXiv:2401.09670(2024)。
参考论文:https://arxiv.org/pdf/2505.09989


















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











