







Nginx实现10万+并发
在优化内核时,可以做的事情很多,不过,我们通常会根据业务特点来进行调整,当Nginx作为静态web内容服务器、反向代理或者提供压缩服务器的服务器时,期内核参数的调整都是不同的,
概述:
由于默认的linux内核参数考虑的是最通用场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改Linux内核参数,让Nginx可以拥有更高的性能;
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从下面的链接获取: 码云
参考关键的Linux内核优化参数
/etc/sysctl.conf
修改 /etc/sysctl.conf 来更改内核参数
修改好配置文件,执行 sysctl -p 命令,使配置立即生效
fs.file-max = 2024000
fs.nr_open = 1024000
net.ipv4.tcp_tw_reuse = 1
ner.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_rmem = 10240 87380 12582912
net.ipv4.tcp_wmem = 10240 87380 12582912
net.core.netdev_max_backlog = 8096
net.core.rmem_default = 6291456
net.core.wmem_default = 6291456
net.core.rmem_max = 12582912
net.core.wmem_max = 12582912
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_tw_recycle = 1
net.core.somaxconn=262114
net.ipv4.tcp_max_orphans=262114
针对Nginx支持超高吞吐,需要优化的,主要是文件句柄数,TCP网络参数:
系统最大可以打开的句柄数
fs.file-max = 2024000
将TIME_WAIT状态的socket重新用于新的TCP链接
net.ipv4.tcp_tw_reuse = 1
#参数设置为 1 ,表示允许将TIME_WAIT状态的socket重新用于新的TCP链接,这对于服务器来说意义重大,因为总有大量TIME_WAIT状态的链接存在;
TCP发送keepalive消息的频度
ner.ipv4.tcp_keepalive_time = 600
#当keepalive启动时,TCP发送keepalive消息的频度;
默认是2小时,将其设置为10分钟,可以更快的清理无效链接。
socket保持在FIN_WAIT_2状态的最大时间
net.ipv4.tcp_fin_timeout = 30
#当服务器主动关闭链接时,socket保持在FIN_WAIT_2状态的最大时间
允许TIME_WAIT套接字数量的最大值
net.ipv4.tcp_max_tw_buckets = 5000
# 这个参数表示操作系统允许TIME_WAIT套接字数量的最大值,
# 如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。
# 该参数默认为180000,过多的TIME_WAIT套接字会使Web服务器变慢。
本地端口的取值范围
net.ipv4.ip_local_port_range = 1024 65000
#定义UDP和TCP链接的本地端口的取值范围。
每个Socket在Linux中都映射为一个文件,并与内核中两个缓冲区(读缓冲区、写缓冲区)相关联。或者说,每个Socket拥有两个内核缓冲区。通过下面的四个选项配置
- rmem_default:一个Socket的被创建出来时,默认的读缓冲区大小,单位字节;
- wmem_default:一个Socket的被创建出来时,默认的写缓冲区大小,单位字节;
- rmem_max:一个Socket的读缓冲区可由程序设置的最大值,单位字节;
- wmem_max:一个Socket的写缓冲区可由程序设置的最大值,单位字节;
net.core.rmem_default = 6291456
#表示内核套接字接受缓存区默认大小。
net.core.wmem_default = 6291456
#表示内核套接字发送缓存区默认大小。
net.core.rmem_max = 12582912
#表示内核套接字接受缓存区最大大小。
net.core.wmem_max = 12582912
#表示内核套接字发送缓存区最大大小。
注意:以上的四个参数,需要根据业务逻辑和实际的硬件成本来综合考虑;
还有两个参数,tcp_rmem、tcp_wmem。为每个TCP连接分配的读、写缓冲区内存大小,单位是Byte
tcp_rmem接受缓存的最小值、默认值、最大值
net.ipv4.tcp_rmem = 10240 87380 12582912
#定义了TCP接受缓存的最小值、默认值、最大值。
第一个数字表示缓冲区最小值,为TCP连接分配的最小内存,默认为pagesize(4K字节),每一个socket接收窗口大小下限;
第二个数字表示缓冲区的默认值,为TCP连接分配的缺省内存,默认值为16K,为接收窗口大小,所谓的窗口大小只是一个限制数值,实际对应的内存缓冲区由协议栈管理分配;
第三个数字表示缓冲区的最大值,为TCP连接分配的最大内存,每个socket链路接收窗口大小上限,用于tcp协议栈自动调整窗口大小的上限。
注意:实际对应的内存缓冲区由协议栈管理分配
一般按照缺省值分配,上面的例子最新为10KB,默认86KB
发送缓存的最小值、默认值、最大值。
net.ipv4.tcp_wmem = 10240 87380 12582912
#定义TCP发送缓存的最小值、默认值、最大值。
以上是TCP socket的读写缓冲区的设置,每一项里面都有三个值:
- 第一个值是缓冲区最小值
- 中间值是缓冲区的默认值
- 最后一个是缓冲区的最大值
net.core与net.ipv4开头的区别
net.core开头的配置为网络层通用配置,net.ipv4开头的配置为ipv4使用网络配置。
虽然ipv4缓冲区的值不受core缓冲区的值的限制,但是缓冲区的最大值仍旧受限于core的最大值。
net.core.netdev_max_backlog = 8096
#当网卡接收数据包的速度大于内核处理速度时,会有一个列队保存这些数据包。这个参数表示该列队的最大值。
TCP socket缓冲区大小是他自己控制而不是由core内核缓冲区控制。
TCP发送缓冲区和接收缓冲区的模型如下:
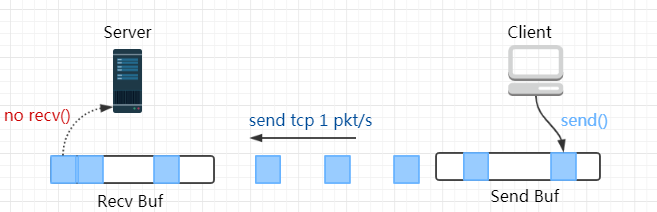
Client 创建一个 TCP 的 socket,并通过 SO_SNDBUF 选项设置它的发送缓冲区大小为 4096 字节,连接到 Server 后,每 1 秒发送一个 TCP 数据段长度为 1024 的报文。Server 端不调用 recv()。预期的结果分为以下几个阶段:
Phase 1 Server 端的 socket 接收缓冲区未满,所以尽管 Server 不会 recv(),但依然能对 Client 发出的报文回复 ACK;
Phase 2 Server 端的 socket 接收缓冲区被填满了,向 Client 端通告零窗口(Zero Window)。Client 端待发送的数据开始累积在 socket 的发送缓冲区;
Phase 3 Client 端的 socket 的发送缓冲区满了,用户进程阻塞在 send() 上。
用于解决TCP的SYN攻击
net.ipv4.tcp_syncookies = 1
#与性能无关。用于解决TCP的SYN攻击。
接受SYN请求列队的最大长度
net.ipv4.tcp_max_syn_backlog = 8192
#这个参数表示TCP三次握手建立阶段接受SYN请求列队的最大长度,默认1024,
# 将其设置的大一些
# 可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的链接请求。
启用timewait快速回收
net.ipv4.tcp_tw_recycle = 1
#这个参数用于设置启用timewait快速回收。
调节系统同时发起的TCP连接数
net.core.somaxconn=262114
# 选项默认值是128,
# 这个参数用于调节系统同时发起的TCP连接数,
# 在高并发的请求中,默认的值可能会导致链接超时或者重传,因此需要结合高并发请求数来调节此值。
防止简单的DOS攻击
net.ipv4.tcp_max_orphans=262114
# 选项用于设定系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。
# 如果超过这个数字,孤立链接将立即被复位并输出警告信息。
# 这个限制只是为了防止简单的DOS攻击,
# 不用过分依靠这个限制甚至认为的减小这个值,更多的情况是增加这个值。
单进程的文件句柄数配置
/etc/security/limits.conf
/etc/security/limits.conf
* soft nofile 1024000
* hard nofile 1024000
* soft nproc 655360
* hard nproc 655360
* soft stack unlimited
* hard stack unlimited
* soft memlock unlimited
* hard memlock unlimited
进程最大打开文件描述符数
* soft nofile 1000000
* hard nofile 1000000
* soft nproc 655360
* hard nproc 655360
# *代表针对所有用户
# nproc 是代表最大进程数
# nofile 是代表最大文件打开数
hard和soft的区别:在设定上,通常soft会比hard小,
举例来说,soft可以设置为80,而hard设定为100,那么你可以使用到90(没有超过100),但介于80~100之间时,系统会有警告信息通知你。
总之:
a. 所有进程打开的文件描述符数不能超过/proc/sys/fs/file-max
b. 单个进程打开的文件描述符数不能超过user limit中nofile的soft limit
c. nofile的soft limit不能超过其hard limit
d. nofile的hard limit不能超过/proc/sys/fs/nr_open
RocketMQ生产环境配置
参考的broker 配置
集群架构为异步刷盘、同步复制
#请修改
brokerClusterName=XXXCluster
brokerName=broker-a
brokerId=0
listenPort=10911
#请修改
namesrvAddr=x.x.x.x:9876;x.x.x.x::9876
defaultTopicQueueNums=4
autoCreateTopicEnable=false
autoCreateSubscriptionGroup=false
deleteWhen=04
fileReservedTime=48
mapedFileSizeCommitLog=1073741824
mapedFileSizeConsumeQueue=50000000
destroyMapedFileIntervalForcibly=120000
redeleteHangedFileInterval=120000
diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/data/rocketmq/store
#commitLog存储路径
storePathCommitLog=/data/rocketmq/store/commitlog
#消费队列存储路径
storePathConsumeQueue=/data/rocketmq/store/consumequeue
# 消息索引存储路径
storePathIndex=/data/rocketmq/store/index
# checkpoint 文件存储路径
storeCheckpoint=/data/rocketmq/store/checkpoint
#abort 文件存储路径
abortFile=/data/rocketmq/store/abort
maxMessageSize=65536
flushCommitLogLeastPages=4
flushConsumeQueueLeastPages=2
flushCommitLogThoroughInterval=10000
flushConsumeQueueThoroughInterval=60000
brokerRole=SYNC_MASTER
flushDiskType=ASYNC_FLUSH
checkTransactionMessageEnable=false
maxTransferCountOnMessageInMemory=1000
transientStorePoolEnable=true
warmMapedFileEnable=true
pullMessageThreadPoolNums=128
slaveReadEnable=true
transferMsgByHeap=false
waitTimeMillsInSendQueue=1000
ElasticSearch生产环境配置
参考的配置文件
/etc/sysctl.conf
fs.file-max = 2024000
fs.nr_open = 1024000
net.ipv4.tcp_tw_reuse = 1
ner.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_rmem = 10240 87380 12582912
net.ipv4.tcp_wmem = 10240 87380 12582912
net.core.netdev_max_backlog = 8096
net.core.rmem_default = 6291456
net.core.wmem_default = 6291456
net.core.rmem_max = 12582912
net.core.wmem_max = 12582912
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_tw_recycle = 1
net.core.somaxconn=262114
net.ipv4.tcp_max_orphans=262114
net.ipv4.tcp_retries2 = 5
vm.max_map_count = 262144
操作系统
较大的文件描述符
Lucene使用了非常大量的文件。 并且Elasticsearch使用大量的套接字在节点和HTTP客户端之间进行通信。
所有这些都需要可用的文件描述符。
可悲的是,许多现代的Linux发行版每个进程允许一个不允许的1024个文件描述符。
这对于一个小的Elasticsearch节点来说太低了,更不用说处理数百个索引的节点了。
设置MMap
Elasticsearch还针对各种文件使用NioFS和MMapFS的混合。
确保配置最大映射计数,以便有足够的虚拟内存可用于mmapped文件。
Elasticsearch默认使用一个mappfs目录来存储索引。默认操作系统对mmap计数的限制可能太低,这可能会导致内存不足异常。
暂时设置 sysctl -w vm.max_map_count=262144
永久设置
$ vim /etc/sysctl.conf
# 设置操作系统mmap数限制,Elasticsearch与Lucene使用mmap来映射部分索引到Elasticsearch的地址空间
# 为了让mmap生效,Elasticsearch还需要有创建需要内存映射区的能力。最大map数检查是确保内核允许创建至少262144个内存映射区
vm.max_map_count = 262144
JVM虚拟机
除非Elasticsearch网站上另有说明,否则应始终运行最新版本的Java虚拟机(JVM)。
Elasticsearch和Lucene都是比较苛刻的软件。
Lucene的单元和集成测试通常暴露JVM本身的错误。
Number of threads(线程数或者进程数)
Elasticsearch为不同类型的操作使用了许多线程池。它能够在需要时创建新线程,这一点很重要。确保Elasticsearch用户可以创建的线程数量至少是4096个。
$ vim /etc/security/limits.conf
elasticsearch soft nproc 4096
elasticsearch hard nproc 4096
给lucene留下一半的内存空间
一个常见的问题是配置一个太大的堆。你有一个64GB的机器,并且你想给Elasticsearch所有64GB的内存。
更多更好?!堆对Elasticsearch绝对重要,它被许多内存数据结构使用以提供快速操作。
但是还有另一个主要的内存用户是 Lucene。Lucene旨在利用底层操作系统来缓存内存中的数据结构。
Lucene的segment 段存储在单独的文件中,因为段是不可变的,所以这些文件从不改变。这使得它们非常易于缓存,并且底层操作系统将适合的保持segment驻留在内存中以便更快地访问。
这些段包括反向索引(用于全文搜索)和docvalues(用于聚合)。
Lucene的性能依赖于与操作系统的这种交互。但是如果你给Elasticsearch的堆提供所有可用的内存,Lucene就不会有任何剩余的内存。
这会严重影响性能。
标准建议是给Elasticsearch堆提供50%的可用内存,同时保留其他50%的空闲内存。
它不会不使用; Lucene会愉快地吞噬剩下的任何东西。
如果你不是聚合在分析的字符串字段(例如你不需要fielddata),你可以考虑降低堆更多。你可以做的堆越小,你可以期望从
Elasticsearch(更快的GC)和Lucene(更多的内存缓存)更好的性能。
不要超过32G
事实证明,当堆大小小于32GB时,HotSpot JVM使用一个技巧来压缩对象指针。
可以通过-XX:+PrintFlagsFinal来查看,在es2.2.0后不用设置,启动后会打印compressed ordinary object pointers [true]
在Java中,所有对象都在堆上分配并由指针引用。
Ordinary object pointers(OOP)指向这些对象,并且通常是CPU本地字的大小:32位或64位,取决于处理器。
指针引用值的确切字节位置。 对于32位系统,这最大堆大小为4GB。
对于64位系统,堆大小可以变得更大,但64位指针的开销意味着更多的浪费空间,因为指针更大。并且比浪费的空间更糟,当在主存储器和各种高速缓存(LLC,L1等)之间移动值时,较大的指针占用更多的带宽。
Java使用一个名为compress oops的技巧来解决这个问题。指针不是指向存储器中的精确字节位置,而是引用对象偏移。这意味着32位指针可以引用四十亿个对象,而不是40亿字节。
最终,这意味着堆可以增长到大约32 GB的物理大小,同时仍然使用32位指针。
一旦你超越32GB边界,指针切换回Ordinary object pointers。
每个指针的大小增加,使用更多的CPU内存带宽,并且您有效地丢失了内存。
事实上,它需要直到大约40到50GB的分配的堆,你有一个堆的相同有效内存刚刚低于32GB使用压缩oops。所以即使你有内存,尽量避免跨越32 GB堆边界。它浪费内存,降低CPU性能,并使GC与大堆争夺。
swapping是性能的死穴
它应该是显而易见的,但它明确拼写出来:将主内存交换到磁盘会破坏服务器性能。 内存中操作是需要快速执行的操作。如果内存交换到磁盘,100微秒操作将花费10毫秒。 现在重复所有其他10us操作的延迟增加。 不难看出为什么交换对于性能来说是可怕的。
1、最好的办法是在系统上完全禁用交换。 这可以临时完成:
sudo swapoff -a
要永久禁用则需要编辑/etc/fstab。请查阅操作系统的文档。
2、如果完全禁用交换不是一个选项,您可以尝试
sysctl vm.swappiness = 1(查看cat /proc/sys/vm/swappiness)
这个设置控制操作系统如何积极地尝试交换内存。 以防止在正常情况下交换,但仍然允许操作系统在紧急情况下交换。swappiness值1比0好,因为在一些内核版本上,swappiness为0可以调用OOM-killer。
3、最后,如果两种方法都不可能,就应该启用mlockall。 这允许JVM锁定其内存,并防止它被操作系统交换。 可以在elasticsearch.yml中设置:
bootstrap.mlockall: true
TCP retransmission timeout(TCP重传超时)
集群中的每一对节点通过许多TCP连接进行通信,这些TCP连接一直保持打开状态,直到其中一个节点关闭或由于底层基础设施中的故障而中断节点之间的通信。
TCP通过对通信应用程序隐藏临时的网络中断,在偶尔不可靠的网络上提供可靠的通信。在通知发送者任何问题之前,您的操作系统将多次重新传输任何丢失的消息。大多数Linux发行版默认重传任何丢失的数据包15次。重传速度呈指数级下降,所以这15次重传需要900秒才能完成。这意味着Linux使用这种方法需要花费许多分钟来检测网络分区或故障节点。Windows默认只有5次重传,相当于6秒左右的超时。
Linux默认允许在可能经历很长时间包丢失的网络上进行通信,但是对于单个数据中心内的生产网络来说,这个默认值太大了,就像大多数Elasticsearch集群一样。高可用集群必须能够快速检测节点故障,以便它们能够通过重新分配丢失的碎片、重新路由搜索以及可能选择一个新的主节点来迅速作出反应。因此,Linux用户应该减少TCP重传的最大数量。
$ vim /etc/sysctl.conf
net.ipv4.tcp_retries2 = 5
config/ jvm.options
- Elasticsearch有足够的可用堆是非常重要的。
- 堆的最小值(Xms)与堆的最大值(Xmx)设置成相同的。
- Elasticsearch的可用堆越大,它能在内存中缓存的数据越多。但是需要注意堆越大在垃圾回收时造成的暂停会越长。
- 设置Xmx不要大于物理内存的50%。用来确保有足够多的物理内存预留给操作系统缓存。
- 禁止用串行收集器来运行Elasticsearch(-XX:+UseSerialGC),默认JVM配置通过Elasticsearch的配置将使用CMS回收器。
-Xms32g
-Xmx32g
硬件方面
内存
首先最重要的资源是内存,排序和聚合都可能导致内存匮乏,因此足够的堆空间来容纳这些是重要的。
即使堆比较小,也要给操作系统高速缓存提供额外的内存,因为Lucene使用的许多数据结构是基于磁盘的格式,Elasticsearch利用操作系统缓存有很大的影响。
64GB RAM的机器是最理想的,但32GB和16GB机器也很常见。
少于8GB往往适得其反(你最终需要许多,许多小机器),大于64GB可能会有问题,我们将在讨论在堆:大小和交换。
CPU
大多数Elasticsearch部署往往对CPU要求很不大。因此,确切的处理器设置比其他资源更重要,应该选择具有多个内核的现代处理器。通用集群使用2到8核机器。
如果需要在较快的CPU或更多核之间进行选择,请选择更多核。 多核提供的额外并发将远远超过稍快的时钟速度。
硬盘
磁盘对于所有集群都很重要,尤其是对于索引很重的集群(例如摄取日志数据的磁盘)。 磁盘是服务器中最慢的子系统,这意味着大量写入的群集可以轻松地饱和其磁盘,这反过来成为群集的瓶颈。
如果你能买得起SSD,他们远远优于任何旋转磁盘。 支持SSD的节点看到查询和索引性能方面的提升。
如果使用旋转磁盘,请尝试获取尽可能最快的磁盘(高性能服务器磁盘,15k转速驱动器)。
使用RAID 0是提高磁盘速度的有效方法,适用于旋转磁盘和SSD。 没有必要使用RAID的镜像或奇偶校验变体,因为高可用性是通过副本建立到Elasticsearch中。
最后,避免网络连接存储(NAS)。 NAS通常较慢,显示较大的延迟,平均延迟的偏差较大,并且是单点故障。
网络
快速和可靠的网络对于分布式系统中的性能显然是重要的。低延迟有助于确保节点可以轻松地进行通信,而高带宽有助于分段移动和恢复。现代数据中心网络(1GbE,10GbE)对于绝大多数集群都是足够的。
避免跨越多个数据中心的群集,即使数据中心位置非常接近。绝对避免跨越大地理距离的集群。
Elasticsearch集群假定所有节点相等,而不是一半的节点距离另一个数据中心中有150ms。较大的延迟往往会加剧分布式系统中的问题,并使调试和解决更加困难。
与NAS参数类似,每个人都声称数据中心之间的管道是稳健的和低延迟。(吹牛)。从我们的经验,管理跨数据中心集群的麻烦就是浪费成本。
其他配置
现在可以获得真正巨大的机器如数百GB的RAM和几十个CPU内核。 另外也可以在云平台(如EC2)中启动数千个小型虚拟机。 哪种方法最好?
一般来说,最好选择中到大盒子。 避免使用小型机器,因为您不想管理具有一千个节点的集群,而简单运行Elasticsearch的开销在这种小型机器上更为明显。
同时,避免真正巨大的机器。 它们通常导致资源使用不平衡(例如,所有内存正在使用,但没有CPU),并且如果您必须为每台机器运行多个节点,可能会增加后期的运维复杂性。
技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
以上尼恩 架构笔记、面试题 的PDF文件更新,请到《技术自由圈》公号获取↓↓↓














 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









