







目录
一、理论
1.awk原理
(1)概念
awk由 Aho,Weinberger 和 Kernighan 创建的文本模式扫描和处理语言。
awk非常复杂,所以这不是一个完整的指南,但应该给你一个知道什么 awk 可以做。它使用起来比较简单,强烈建议使用。
(2)基本格式
awk [选项] '处理模式或条件{处理动作}' 文件名
'{ }'为固定格式
(3)内置变量
内置变量,不能用双引号括起来,不然系统会把它当成字符串。
表1 内置变量
| 内置变量 | 功能 |
| $0 | 当前处理的行的整行内容 打印所有 |
| $n | 当前处理行的第n个字段(第n列) |
| NR | 当前处理的行的行号(序数) |
| NF | 当前处理的行的字段个数。$NF代表最后一个字段 |
| FS | 列分割符。指定每行文本的字段分隔符,输入内容的分隔符, 默认为空格或制表位。与"-F"作用相同 用-F可以不加单引号 -F:,用FS必须用="" |
| OFS | 输出内容的列分隔符,默认为空格 |
| ORS | 输出记录分隔符,默认为换行符\n |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件中读取资料时, 将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。默认为换行符\n |
(4)处理动作
①基本格式:awk [选项] '处理模式或条件{处理动作}' 文件名
②print动作:打印,打印'{print $1}'即为打印第一列,'{print $n}'即打印为第n列,'{print $n,$m}'即为打印第n列和第m列。
③print打印顺序:'BEGIN{print "1"} END {print "2"} {print "3"} ',首先打印BEGIN后的print 1,然后打印print 3 最后打印END后的print 2,BEGIN表示第一个打印,END表示最后打印
(5)选项
① 基本格式:awk [选项] '处理模式或条件{处理动作}' 文件名
② 选项若不写默认为以空格为分隔符处理,且会将空格自动压缩。
③ -F 选项 指定分隔符,即指定以什么为分隔符处理内容
注意一定是单引号:'模式或条件 {操作}'
{ }外指定条件,{ }内指定操作。
表2 选项
| 选项 | 功能 |
| -F | “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符 |
| -v(小v) | var=value 变量赋值 |
(6)处理模式
①基本格式:awk [选项] '处理模式或条件{处理动作}' 文件名
②处理模式为空表示无其他额外条件。
③正则表达式匹配模式
正则匹配:与正则表达式配合使用。
2.awk打印
(1)基本打印用法
① 基本打印
指定行号

打印行号和内容
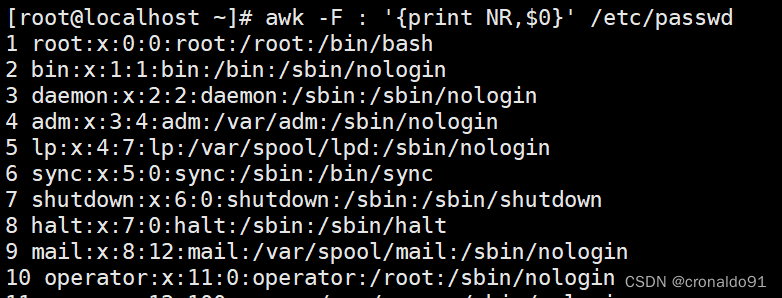
打印第3行

打印第3行到第5行

打印第3行和第5行


②奇偶行打印:
打印偶数

打印奇数

③awk运算:
运算

先打印行,再跳行(奇数)

先跳行,再打印(偶数)

(2)文件内容匹配过滤
与正则表达式配合使用:

(3)BEGIN打印模式
格式:awk 'BEGIN{...};{...};END{...}' 文件
处理过程:
① 在awk处理指定的文本之前,需要先执行BEGIN{...}模式里的命令操作
② 中间的{...} 是真正用于处理文件的命令操作
③ 在awk处理完文件后才会执行END{...}模式里的命令操作。END{ }语句块中,往往会放入打印结果等语句。
BEGIN END模式

-v


(4)BEIGIN模式指定
BEGIN模式在awk执行前改变分隔符,执行过程中,以“:”分割,打印指定内容
指定换行符


(5)awk的三元表达式
awk的三元表达式继承了java的用法,格式与Java相似
格式:awk '(条件表达式)?(A表达式或者值):(B表达式或者值)'
三元表达式(面试):
将变量 max 设置为输入行字段 3 和 4 之间的最大值。
? : 运算符是 if-else 语句的简写,因此此行等效于 if ($3 >= $4) { max=$3 } else { max=$4 }
取比较结果的最大值,赋值给变量max,并且输出max行的所有内容,然后打印其中的1-6行;

(6)awk的精准筛选
awk支持使用正则进行模糊匹配,也支持字符串和数字的精确匹配,并且支持逻辑与和逻辑或
表2 条件匹配
| 比较符号 | 描述 |
| // | 全行数据正则匹配 |
| !// | 对全行数据正则匹配后取反 |
| ~// | 对特定数据正则匹配 |
| !~// | 对特定数据正则匹配后取反 |
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| && | 逻辑与,如A&&B,要求满足A并且满足B |
| || | 逻辑或,如A||B,要求满足A或者满足B |
表3 awk的精准筛选
| 变量 | 功能 |
| $n(> < ==) | 用于对比数值 |
| $n~"字符串" | 代表第n个字段包含某个字符串 |
| $n!~"字符串" | 代表第n个字段不包含某个字符串 |
| $n=="字符串" | 代表第n个字段为某个字符串 |
| $n!="字符串" | 代表第n个字段不为某个字符串 |
| $NF | 代表最后一个字段 |
-F

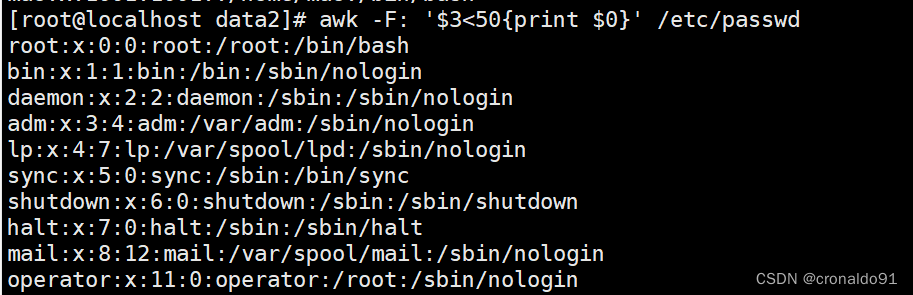
小于等于10 uid

取反
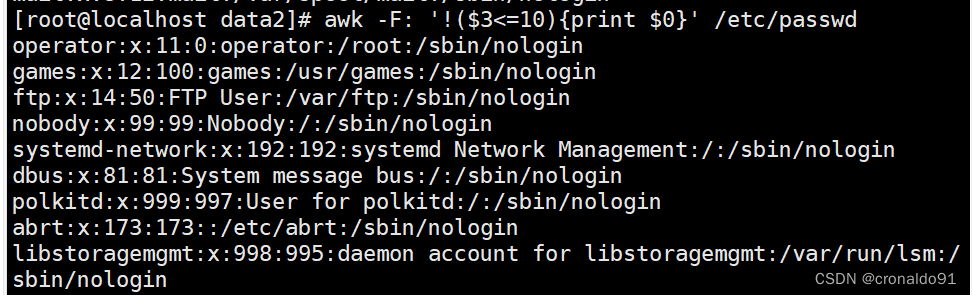
(7)awk的分隔符用法
① RS 指定行分隔符:
awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录,
而awk一次仅读入一条记录进行处理。内置变量RS的预设值是"\n" 也就是换行。
也可以使用BEGIN模式在操作前进行行分隔符的改变。
② 指定输出的分隔符:
OFS:输出内容的列分隔符。($n=$n用于激活,否则不生效,n必须存在)
对于输出时改变分隔符,我们常用到tr,awk,它们都可以实现在输出内容改变原本的分隔符
③ awk改变输出分隔符
精准筛选

逻辑且

3.awk条件判断
(1)条件判断打印
if判断后面如果只有一个动作指令,则花括号{}可省略,如果if判断后面的指令为多条指令则需要使用花括号括起来,多个指令使用分号分隔。
使用了if语句,内部条件(),外部条件{},整个加{}作为一条语句执行,相当于嵌套语法
①单分支语法
if(判断条件){
动作指令序列;
}查找cpu使用率大于0.3的进程:
ps -eo user,pid,pcpu,comm | awk '{if($3>0.5) print}'
②双分支语法
if(判断条件){
动作指令1;
} else {
动作指令2;
}统计系统用户与普通用户的个数:
awk -F: '{if($3<1000){x++} else{y++}} END{print "系统用户个数:"x"","普通用户个数:"y""}' /etc/passwd③ 多分支语句
if(判断条件){
动作指令1;
} else if(判断条件2){
动作指令2;
} else {
动作指令N;
}If条件:

4.awk数组与循环
awk结合数组运用
awk中定义数组打印:

①数组遍历
语法:
for(变量 in 数组名){
动作指令序列
}awk中的数组形成遍历,处理文件去重统计:
Awk结合数组去重

出现几次赋值几次,把$1的值作为索引下标

②for循环
采用与C语言一样的语法格式
for(表达式1;表达式2;表达式3) {
动作指令序列
}awk 'BEGIN{ for (i=1;i<=4;i++) {print i}}'
awk -F: '{ \
for(i=1;i<=NF;i++) \
> {if($i=="root") x++} \
> } END {print x}' /etc/passwd③ while循环
语法:
while(条件判断){
动作指令序列;
}awk 'BEGIN{ i=1; while(i<=5) {print i;i++}}'④ 中断语句
与shell类似,awk提供了continue、break、exit循环中断语句。
awk 'BEGIN{ \
i=0;
while(i<=5) { \
i++; \
if(i==3) {continue}; \
print i \
}; \
} \
END {print "END"}' /tmp/hosts5.awk函数
(1)内置I/O函数
① getline
能让awk立刻读取下一行数据(读取下一条记录并复制给$0,并重新设置NF、NR和FNR).
#解决挂载逻辑卷时,分区信息跨行显示的问题
df -h | awk '{if(NF==1) {getline;print $3}; if(NF==6) {print $4}}'getline的工作过程:
1)当getline左右无重定向符号(“<”,">")或者管道符号(“|”)时,
awk首先读取的是第一行,而getline获取的是光标跳转至下一行的内容(也就是第二行)。
2)当getline左右有管道符号或重定向符时,
getline则作用定向输入文件,由于文件是刚打开,并没有被awk读入一行,
而只是getline读入,所以getline返回的是文件的第一行,而不是跳转至一行输入
原因:getline运行之后awk会改变NF,NR,$0,FNR等内部变量,所以此时读取$0的行号不再为1,而是2。
重定向:

getline 管道服 (赋值变量):

② next函数
停止处理当前的输入记录,立刻读取下一条记录并返回awk程序的第一个模式匹配重新处理数据。
有点类似于循环语句中的continue,不会执行当次循环的后续语句
awk -F: '/root/{getline;print "next line:",$0} {print "normal line"}' /etc/passwdawk -F: '/root/{next;print "next line:",$0} {print "normal line"}' /etc/passwd
总结:getline,会继续执行后续的指令print “next line:”,而next不会执行后续指令,而是重新开始匹配。
③system(命令)函数
可以直接在awk中调用shell命令,会启动一个新shell进程执行命令。
awk 'BEGIN{system("ls")}'
awk '{system("echo date:"$0)}' /tmp/hosts(2)内置数值函数
cos(expr)、sin(expr)、sqrt(expr)
可以对小数取整
awk 'BEGIN{print int(6.8)}'
6rand()函数
返回0到1之间的随机数
awk 'BEGIN{print rand()}'
awk 'BEGIN{for(i=1;i<=5;i++) print int(100*rand())}' #生成5个100以内的随机数
srand([expr])
可以使用expr定义新的随机数种子,没有expr时则使用当前系统的时间为随机数种子
awk 'BEGIN{srand();print rand()}' #使用时间做随机数种子
awk 'BEGIN{srand(22);print rand()}' #使用数值做随机数种子(3)内置字符串函数
length([s])函数
可以统计字符串s的长度,如果不指定字符串s则统计$0的长度
awk 'BEGIN{test="hello"; print length(test)}' #打印字符串长度
awk 'BEGIN{t[0]="hi";t[1]="the"; print length(t)}' #返回数组元素个数
awk '{print length()}' /etc/shells #返回文件每行的字符长度index(字符串1,字符串2)
返回字符串2在字符串1中的位置
awk 'BEGIN{test="hello";print index(test,"l")}'match(s,r)
根据正则表达式r返回其在字符串s中的位置坐标
awk 'BEGIN{print match("How much","[a-z]")}' #小写字母在第2个位置开始出现
2tolower(srt)
可以将字符串转换为小写
awk 'BEGIN{print tolower("HELLo")}'
hellotoupper(str)
将字符串转为大写
将字符串按特定的分隔符切片后存储在数组中,如果没指定分隔符,则使用IFS定义的。
数组下标从1开始
awk 'BEGIN{split("hello world",test); print test[1],test[2]}'
awk 'BEGIN{split("hello:world",test,":"); print test[1],test[2]}' #指定冒号(:)为分隔符
gsub(r,s,[,t])
将字符串t中所有与正则表达式r匹配的字符串全部替换为s,如果没有指定字符串t,则默认对$0进行替换操作
head -1 /etc/passwd | awk '{gsub("[0-9]","**");print $0}'
root:x:**:**:root:/root:/bin/bashsub(r,s,[,t])
与gsub类似,但仅替换第一个匹配的字符串,而不是替换全部
对字符串s进行截取,从第i位开始,截取n个字符串,如果n没有指定则一直截取到字符串s的末尾位置
awk 'BEGIN{hi="Hello World"; print substr(hi,2,3)}' #从第2位开始截取3个字符
ell(4)内置时间函数
systime()
返回当前时间距离1970-01-01 00:00:00有多少秒
awk 'BEGIN{print systime()}'
(5)用户自定义函数
语法:
function 函数名(参数列表) { 命令序列 }awk ' \
function max(x,y) { \
if(x>y) {print x} \
else {print y} } \
BEGIN {max(5,6)} '6.常用命令
cat example.txt | awk 'NR%2==1' #删除example.txt文件中的所有偶数行
echo " false" |awk -F' ' '{print $NF}' #去掉前面的空格
docker images | grep 'mysql' | awk '{printf"%s:%s\n",$1,$2}' #获取镜像名:Tag
ps -ef | grep java | grep -v 'color' awk '{for (i=8;i<=NF;i++)printf("%s ", $i);print ""}' #获取从第八列开始到最后一列的内容
二、实验
1.统计磁盘可用容量
(1)运行结果

2.统计/etc下文件总大小
(1)运行结果

3.CPU使用率
(1)运行结果

4.统计内存
(1)脚本截图

(2)运行结果

5.监控硬盘
(1)脚本截图
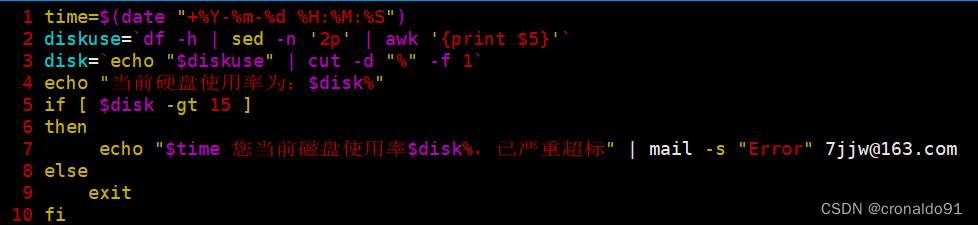
(2)运行结果

















 5291
5291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









