







原教程链接AI夏令营第三期 - 脑PET图像分析和疾病预测挑战赛教程 - 飞书云文档 (feishu.cn)
一、环境搭建
本次采用Anaconda+Pycharm的方式进行,首先在Anaconda中创建环境,使用以下命令创建python版本为3.10名称为PETCompete的虚拟环境
conda create -n PETCompete python=3.10激活conda环境
activate PETCompete使用conda安装cuda11.8及PyTorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia安装juypter
pip install jupyter在pycharm中创建项目并使用刚刚创建conda环境
1.在新建项目时添加本地环境
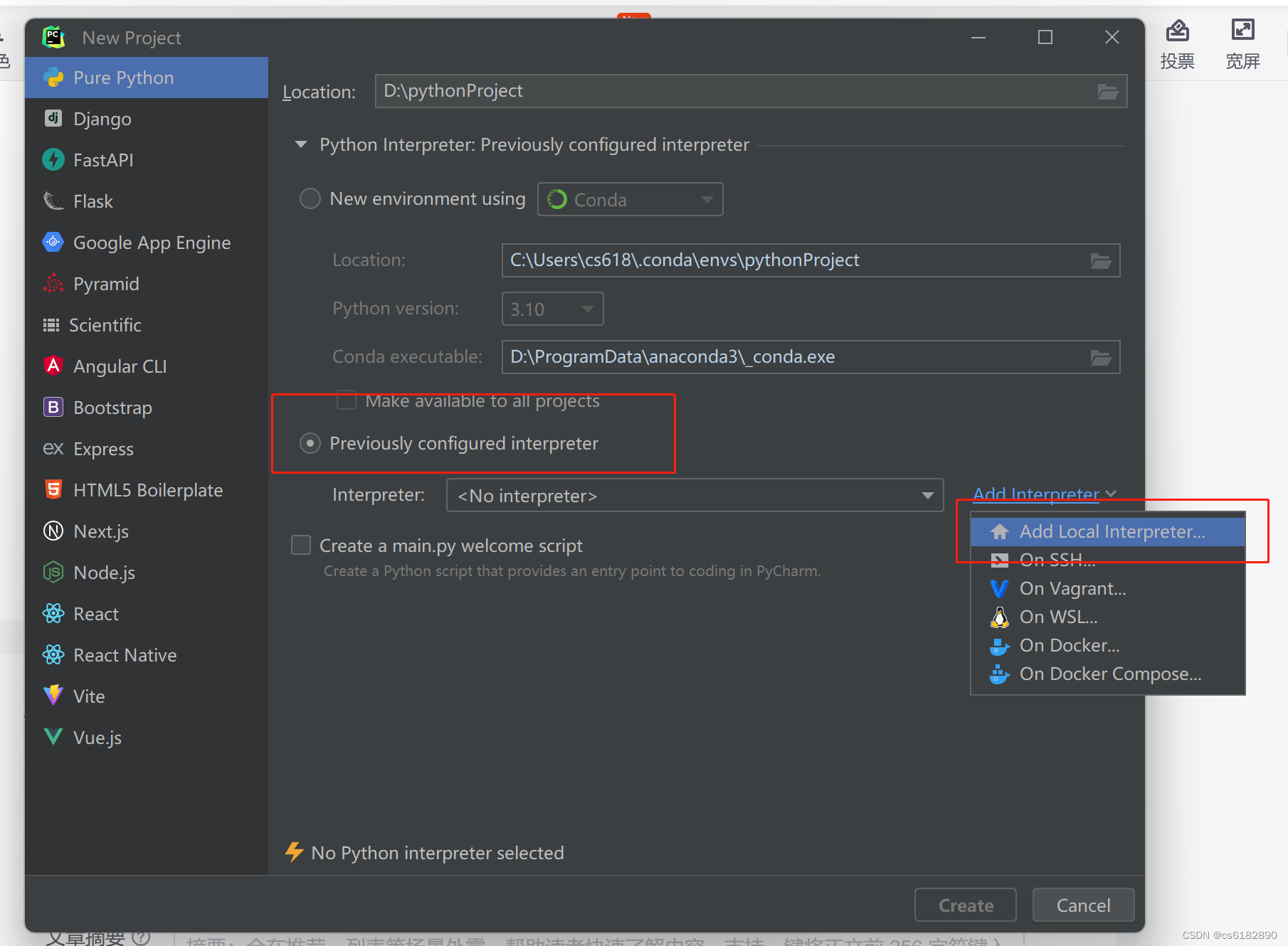
选择刚刚创建的conda环境
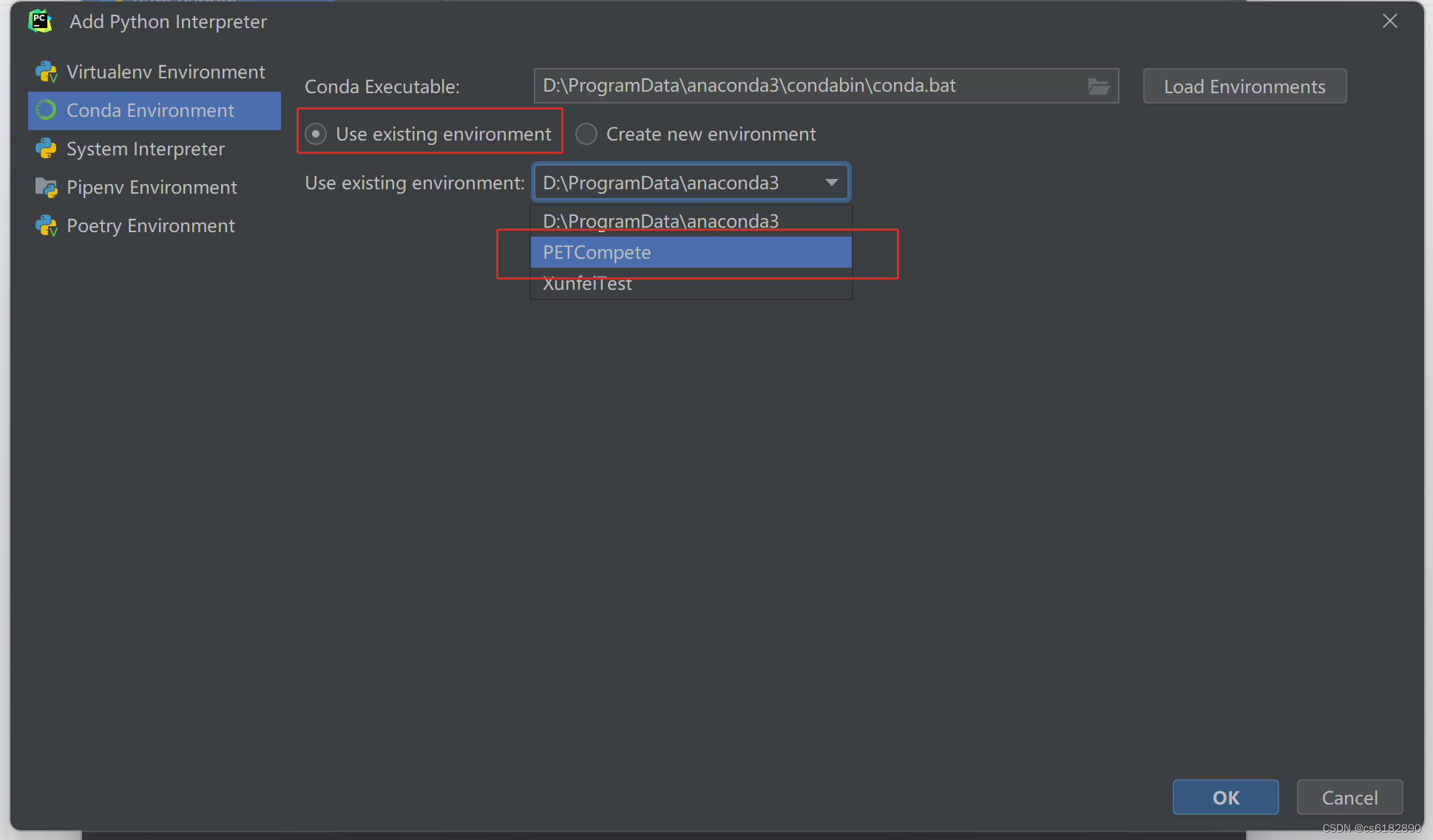
二、Baseline运行
1.下载数据集并新建jupyter notebook
数据集下载链接
2.安装对应包
pip install pandas tqdm scikit-learn nibabel albumentations 3.读取数据并进行数据增强
import os, sys, glob, argparse
import pandas as pd
import numpy as np
from tqdm import tqdm
import cv2
from PIL import Image
from sklearn.model_selection import train_test_split, StratifiedKFold, KFold
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
import nibabel as nib
from nibabel.viewers import OrthoSlicer3D
import albumentations as A
#读取数据集
train_path = glob.glob('./脑PET图像分析和疾病预测挑战赛公开数据/Train/*/*')
test_path = glob.glob('./脑PET图像分析和疾病预测挑战赛公开数据/Test/*')
#将训练集和测试集随机打乱
np.random.shuffle(train_path)
np.random.shuffle(test_path)
DATA_CACHE = {}
#定义数据集读取方法
class XunFeiDataset(Dataset):
def __init__(self, img_path, transform=None):
self.img_path = img_path
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
if self.img_path[index] in DATA_CACHE:
img = DATA_CACHE[self.img_path[index]]
else:
img = nib.load(self.img_path[index])
img = img.dataobj[:,:,:, 0]
DATA_CACHE[self.img_path[index]] = img
# 随机选择一些通道
idx = np.random.choice(range(img.shape[-1]), 50)
img = img[:, :, idx]
img = img.astype(np.float32)
if self.transform is not None:
img = self.transform(image = img)['image']
img = img.transpose([2,0,1])
return img,torch.from_numpy(np.array(int('NC' in self.img_path[index])))
def __len__(self):
return len(self.img_path)
#训练集载入与并对图像镜像增强(随机旋转90度,随机裁剪,随机水平翻转,随机对比度,随机亮度对比度)
train_loader = torch.utils.data.DataLoader(
XunFeiDataset(train_path[:-10],
A.Compose([
A.RandomRotate90(),
A.RandomCrop(120, 120),
A.HorizontalFlip(p=0.5),
A.RandomContrast(p=0.5),
A.RandomBrightnessContrast(p=0.5),
])
), batch_size=2, shuffle=True, num_workers=1, pin_memory=False
)
#验证集载入及数据增强(随机裁剪)
val_loader = torch.utils.data.DataLoader(
XunFeiDataset(train_path[-10:],
A.Compose([
A.RandomCrop(120, 120),
])
), batch_size=2, shuffle=False, num_workers=1, pin_memory=False
)
#测试集载入及数据增强(随机裁剪,随机水平翻转,随机对比度)
test_loader = torch.utils.data.DataLoader(
XunFeiDataset(test_path,
A.Compose([
A.RandomCrop(128, 128),
A.HorizontalFlip(p=0.5),
A.RandomContrast(p=0.5),
])
), batch_size=2, shuffle=False, num_workers=1, pin_memory=False
)
2.定义模型,Baseline采用PyTorch自带的Resnet18网络,也可使用Resnet50,Resnet101等,增加了一层卷积层对图像特征镜像进一步提取,增加了512*2的全连接层,用于将输出转为二分类问题
class XunFeiNet(nn.Module):
def __init__(self):
super(XunFeiNet, self).__init__()
model = models.resnet18(True)
model.conv1 = torch.nn.Conv2d(50, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
model.avgpool = nn.AdaptiveAvgPool2d(1)
model.fc = nn.Linear(512, 2)
self.resnet = model
def forward(self, img):
out = self.resnet(img)
return out
model = XunFeiNet()
model = model.to('cuda')
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.AdamW(model.parameters(), 0.001)3.模型训练及验证(WIndows用户需要将原Baseline这一段9和33行的target修改为target.long())
def train(train_loader, model, criterion, optimizer):
model.train()
train_loss = 0.0
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
output = model(input)
loss = criterion(output, target.long())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 20 == 0:
print(loss.item())
train_loss += loss.item()
return train_loss/len(train_loader)
def validate(val_loader, model, criterion):
model.eval()
val_acc = 0.0
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target.long())
val_acc += (output.argmax(1) == target).sum().item()
return val_acc / len(val_loader.dataset)
for _ in range(3):
train_loss = train(train_loader, model, criterion, optimizer)
val_acc = validate(val_loader, model, criterion)
train_acc = validate(train_loader, model, criterion)
print(train_loss, train_acc, val_acc)4.模型预测与提交,WIndows用户需将Baseline的25行中的/替换为\\
def predict(test_loader, model, criterion):
model.eval()
val_acc = 0.0
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
input = input.cuda()
target = target.cuda()
output = model(input)
test_pred.append(output.data.cpu().numpy())
return np.vstack(test_pred)
pred = None
for _ in range(10):
if pred is None:
pred = predict(test_loader, model, criterion)
else:
pred += predict(test_loader, model, criterion)
submit = pd.DataFrame(
{
'uuid': [int(x.split('\\')[-1][:-4]) for x in test_path],
'label': pred.argmax(1)
})
submit['label'] = submit['label'].map({1:'NC', 0: 'MCI'})
submit = submit.sort_values(by='uuid')
submit.to_csv('submit2.csv', index=None)5.提交生成的submit2.csv文件,获得评分0.73418

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









