







最后改了模型又做了数据增强,不过好像还是没什么进步,后面了看别人的笔记,又学了一些上分技巧,在这里分享给大家,由于时间问题目前还没来得及尝试,有空了再试试,看有什么提升。
大佬们的一些上分思路分享
1.从数据出发
对于我们这些搞机器学习的人而言,看到图像第一反应可能就是把图像加载到内存中,作为一个矩阵去跑 各种机器学习算法,但我们忽略了一点,那就是图像本身的元数据。
以传统图像为例, 其记录的并不仅仅是图片的像素信息, 还记录了相机型号、ISO 感光值、GPS 地址等 Exif 信息。而 NIFTI 格式的医疗影像也记录了对应的元数据, 俺测试后, 仅通过其中的 db_name 字段就能推断出 100 个测试用例中 15 个的标签。
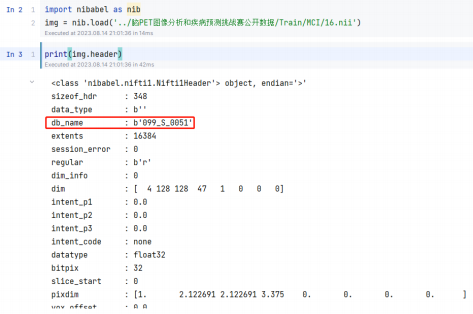
如图 上所示, 赛题所提供的 db_name 字段存在数据, 这里我做了个猜想, 若 2 个影像的 db_name 字段相 同, 则会有同样的标签。对 100 个测试用例对训练集中的样本做匹配, 发现了 15 个 db_name 相同的样本
| uuid | label | db_name |
| 33 | MCI | 031_S_0294 |
| 36 | MCI | 036_S_0656 |
| 42 | MCI | 036_S_0945 |
| 43 | MCI | 036_S__1240 |
| 46 | MCI | 041_S_0282 |
| 53 | MCI | 041_S__1010 |
| 63 | MCI | 094_S__1188 |
| uuid | label | db_name |
| 44 | NC | 005_S_0223 |
| 45 | NC | 005_S_0610 |
| 48 | NC | 009_S_0751 |
| 49 | NC | 011_S_0002 |
| 51 | NC | 011_S_0005 |
| 52 | NC | 011_S_0008 |
| 54 | NC | 011_S_0016 |
| 57 | NC | 011_S_0221 |
2.计算数据中的各类数据数量
将预测标签全为 NC 的数据交上去后,得到的分数 y 为 0.74214 分,再根据F1 Score公式即可计算出交上去的数据中存在 59 个正常的,显然说明这 100 个测试样例中存在 59 个 NC ,41 个 MCI。
3 构造实验验证标签
前面已经算出, 100 个测试用例中存在 59 个 NC,41 个 MCI。并推断出了其中的 8 个 NC 、7 个 MCI 的编 号。前者在数学上被证实了,但后者还只是猜想,得验证才行,这里就构造个简单的实验验证下。如下表的实验。显然,提交成绩与预测成 绩吻合,成功石锤这 15 个样例的标签
| 提交方案 | 验证 8 个 NC | 验证 7 个 MCI | 全 NC | 全 NC+7 个 MCI 修正 |
| 构造方法 | 对表 3 中的样例,取 NC,其余取 MCI | 对表 2 中的样例取 NC,其余取 MCI | 全取 NC | 对表 2 中的样例,取 MCI,其余取 NC |
| 分数 | 0.23881 | 0 | 0.74214 | 0.77632 |
| 预计成绩 | 0.23880597 | 0 | 这个是参照 | 0.77631579 |
二、自己的一些思考
1.PET图像是连续的图像
首先本次比赛使用的PET图像,以下是对PET图像的一些介绍
正电子发射断层扫描(PET)是一种核成像技术(也称为分子成像),可以显示体内代谢过程。PET成像的基础是该技术检测由正电子发射放射性核素(也称为放射性药物,放射性核素或放射性示踪剂)间接发射的γ射线对。将示踪剂注入生物活性分子的静脉中,通常是用于细胞能量的糖。PET系统灵敏的探测器捕获身体内部的伽马射线辐射,并使用软件绘制三角测量排放源,创建体内示踪剂浓度的三维计算机断层扫描图像。
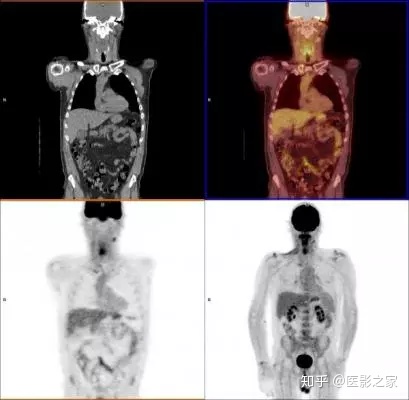
PET-CT头颈癌扫描显示各种图像重建。左上图是显示解剖结构的单独CT扫描。右上角扫描显示融合的PET和CT扫描,添加假色以帮助解释图像。左下扫描是初始FDG PET图像,其显示颈部中的示踪剂热点和由于癌症引起的右颌中的淋巴结。右下图是延迟增强扫描,显示随时间的示踪剂摄取,在膀胱,肾,睾丸和脑中具有正常的热点,其通常具有更高的代谢活性。解剖结构的低级灰色阴影是由于整个身体中FDG的正常细胞代谢摄取。
从上面的介绍可以看出他是一种三维成像技术,就是通过扫描进行三维重建,而且目前的PET都和CT合成在一起了。就像我们平时去做CT的时候,都会从头开始扫描一偏,因此我们其实可以把PET的数据看做是连续的一串数据,而不是Baseline里面的单纯是一堆通道图像
2.作为连续图像,我们也可看做是视频帧图像
如果我们把他看做连续的图像就可以把这个问题转变为视频分类问题
与图像识别相比,视频分类任务中视频比静态图像可以提供更多的信息,包括随时间演化的复杂运动信息等。视频(即使是短视频)中包含成百上千帧图像,但并不是所有图像都有用,处理这些帧图像需要大量的计算。最简单的方法是将这些视频帧视为一张张静态图像,应用CNN识别每一帧,然后对预测结果进行平均处理来作为该视频的最终结果。然而,这个方法使用了不完整的视频信息,因此使得分类器可能容易发生混乱。这看着来挺像本次遇到的情况。如果是视屏分类任务一般可从以下方面改进
(1) 监督学习方法
i. 基于图像的视频分类:将视频片段视为视频帧的集合,每个视频帧的特征通过ImageNet数据集上预先训练的最高水平的深度模型(如AlexNet,VGGNet,GoogLeNet,ResNet)进行获取。最终,帧层特征汇聚为视频层特征,作为标准分类器(如SVM)识别的输入。
ii. 端到端的CNN网络:关注于利用CNN模型学习视频隐含的时空模式,如3D CNN,Two-stream CNN,TSN模型等。
iii. 双流(Two-stream)法中的时间CNN只能获取很短时间窗口内的运动信息,难以处理长时间多种行为组成的复杂事件和行为。因此,引入RNN来建模长期时间动态过程,常用的模型有LSTM,GRU-RNN等。LSTM避免了梯度消失的问题,在许多图像和视频摘要、语音分析任务中非常有效。
iv. 视频中包含了很多帧,处理所有的视频帧计算代价很大,也会降低识别那些与类别相关的视频帧的性能。因此,引入视觉注意力机制来识别那些与目标语义直接相关的最有判别力的时空特征
(2) 非监督学习方法
采用非监督学习的方法,整合空间和时间上下文信息,是发现和描述视频结构的一种很有前途的方法。
(3)视频分类目前的主要方向
· 大规模多标签视频分类与标注(large-scale multi-label video classification / annotation)
· 视频的时间/序列模型和池化方法(temporal /sequence modeling and pooling approaches for video)
· 时间注意力模型机制(temporal attention modeling mechanisms)
· 视频描述学习,如分类性能vs.视频描述符大小(video representation learning e.g., classification performance vs. video descriptor size)
· 多模型(声音-视觉)建模和融合方法(multi-modal (audio-visual) modeling and fusion approaches)
· 从噪声/不完整的人工标注标签中学习(learning from noisy / incomplete ground-truth labels)
· 多重实例学习multiple-instance learning (training frame-/segment-level models from video labels)
· 迁移学习,领域适应和泛化(transfer learning, domain adaptation, generalization)
· 衡量:性能 vs.训练数据和计算量(scale: performance vs. training data & compute quantity)
3.按照连续序列数据处理
如果按照序列数据来处理的话,可以试着用时间序列分类的相关方法做分类,由于篇幅的关系这里就不做赘述了,大家可以参考这篇文章。把目前数据的每个通道,看做是一个时间段来处理就可以了。
深度学习在时间序列分类中的应用 - 知乎 (zhihu.com)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









