






目录
使用Hugging Face Transformers进行多语言任务
引言
随着全球化的加速,多语言自然语言处理(NLP)任务的需求日益增长。多语言模型能够处理多种语言的文本,为跨语言任务提供了强大的支持。Hugging Face Transformers库提供了丰富的多语言预训练模型,如XLM-R、mBERT等,这些模型在多种语言上进行了预训练,能够捕捉不同语言的通用特征。
本文将详细介绍如何使用Hugging Face Transformers进行多语言模型的应用和跨语言任务的开发,包括概念讲解、代码示例、应用场景、注意事项以及相关的架构图和流程图。
多语言模型概述
什么是多语言模型?
多语言模型是指在多种语言的文本数据上进行预训练的模型。这些模型能够处理多种语言的文本,为跨语言任务提供了强大的支持。例如,XLM-R(Cross-lingual Language Model - RoBERTa)是一个在100多种语言上进行预训练的模型,能够捕捉不同语言的通用特征。
多语言模型的优势
-
跨语言能力:多语言模型能够处理多种语言的文本,适用于跨语言任务,如跨语言文本分类、跨语言问答等。
-
资源节约:通过使用预训练的多语言模型,可以减少为每种语言单独训练模型的资源消耗。
-
性能提升:多语言模型在多种语言上进行了预训练,能够捕捉语言的通用特征,从而在跨语言任务上表现出色。
使用Hugging Face Transformers进行多语言任务
1. 加载多语言模型
Hugging Face Transformers库提供了多种多语言预训练模型。以下是一个加载XLM-R模型的代码示例:
Python
复制
from transformers import XLMRobertaTokenizer, XLMRobertaModel
# 加载预训练模型的Tokenizer
tokenizer = XLMRobertaTokenizer.from_pretrained("xlm-roberta-base")
# 加载预训练模型
model = XLMRobertaModel.from_pretrained("xlm-roberta-base")2. 数据准备
在进行多语言任务之前,需要准备多语言的数据集。以下是一个简单的代码示例,展示如何准备多语言文本分类数据集:
Python
复制
from datasets import load_dataset
# 加载多语言数据集
dataset = load_dataset("xnli", "all_languages")
# 数据预处理函数
def preprocess_function(examples):
return tokenizer(examples["premise"], examples["hypothesis"], truncation=True, padding=True, max_length=128)
# 应用预处理函数
tokenized_datasets = dataset.map(preprocess_function, batched=True)
# 分割数据集
train_dataset = tokenized_datasets["train"]
eval_dataset = tokenized_datasets["validation"]3. 定义训练循环
使用Trainer类进行训练:
Python
复制
from transformers import Trainer, TrainingArguments
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
# 训练模型
trainer.train()4. 模型评估
在测试集上评估模型性能:
Python
复制
# 评估模型
results = trainer.evaluate()
# 打印评估结果
print(results)5. 模型保存与加载
保存训练好的模型,以便后续使用:
Python
复制
# 保存模型
model.save_pretrained("./my_finetuned_model")
# 加载模型
model = XLMRobertaModel.from_pretrained("./my_finetuned_model")代码示例:跨语言文本分类
以下是一个完整的代码示例,展示如何使用Hugging Face Transformers进行跨语言文本分类:
Python
复制
from datasets import load_dataset
from transformers import XLMRobertaTokenizer, XLMRobertaForSequenceClassification
from transformers import Trainer, TrainingArguments
# 加载多语言数据集
dataset = load_dataset("xnli", "all_languages")
# 加载预训练模型的Tokenizer
tokenizer = XLMRobertaTokenizer.from_pretrained("xlm-roberta-base")
# 数据预处理函数
def preprocess_function(examples):
return tokenizer(examples["premise"], examples["hypothesis"], truncation=True, padding=True, max_length=128)
# 应用预处理函数
tokenized_datasets = dataset.map(preprocess_function, batched=True)
# 分割数据集
train_dataset = tokenized_datasets["train"]
eval_dataset = tokenized_datasets["validation"]
# 加载预训练模型
model = XLMRobertaForSequenceClassification.from_pretrained("xlm-roberta-base", num_labels=3)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
# 保存模型
model.save_pretrained("./my_finetuned_model")应用场景
1. 跨语言文本分类
跨语言文本分类是指将文本分类任务扩展到多种语言。例如,对新闻文章进行多语言分类:
Python
复制
from transformers import pipeline
# 加载分类器
classifier = pipeline("text-classification", model="./my_finetuned_model")
# 输入文本
text = "Le gouvernement a annoncé une nouvelle politique pour soutenir les petites entreprises."
# 进行分类
result = classifier(text)
print(result)2. 跨语言问答
跨语言问答是指在多种语言之间进行问答任务。例如,使用多语言模型回答不同语言的问题:
Python
复制
from transformers import XLMRobertaTokenizer, XLMRobertaForQuestionAnswering
# 加载预训练模型的Tokenizer
tokenizer = XLMRobertaTokenizer.from_pretrained("xlm-roberta-base")
# 加载预训练模型
model = XLMRobertaForQuestionAnswering.from_pretrained("xlm-roberta-base")
# 输入问题和上下文
question = "What is the capital of France?"
context = "The capital of France is Paris."
# 使用Tokenizer将问题和上下文转换为模型可接受的格式
inputs = tokenizer(question, context, return_tensors="pt")
# 将输入传递给模型
outputs = model(**inputs)
# 解码答案
answer_start = torch.argmax(outputs.start_logits)
answer_end = torch.argmax(outputs.end_logits) + 1
answer = tokenizer.decode(inputs['input_ids'][0][answer_start:answer_end], skip_special_tokens=True)
print(answer)注意事项
数据预处理
-
多语言分词:多语言模型通常使用子词分词器(如Byte Pair Encoding, BPE),能够处理多种语言的文本。
-
数据清洗:在将文本输入模型之前,需要对文本进行清洗,例如去除HTML标签、特殊字符等。
模型选择
-
任务适配:不同的多语言模型适用于不同的任务。例如,
XLM-R适用于跨语言文本分类和问答任务。 -
模型大小:多语言模型有多种大小可供选择,例如
xlm-roberta-base和xlm-roberta-large。较大的模型通常具有更好的性能,但需要更多的计算资源和内存。
超参数调整
-
学习率:学习率是影响模型训练效果的重要超参数。通常需要通过实验找到合适的学习率。
-
批大小:批大小决定了每次训练使用的样本数量。较大的批大小可以提高训练速度,但可能会导致模型性能下降。
-
训练轮数:训练轮数决定了模型训练的次数。过多的训练轮数可能会导致过拟合,过少的训练轮数可能会导致欠拟合。
性能优化
-
硬件加速:使用GPU可以大大加快模型的训练和推理速度。如果条件允许,建议使用支持CUDA的GPU。
-
分布式训练:对于大规模数据集,可以使用分布式训练来加速模型的训练过程。
-
模型压缩:对于资源受限的设备,可以使用模型压缩技术(如量化和剪枝)来减少模型的大小和计算复杂度。
架构图与流程图
流程图
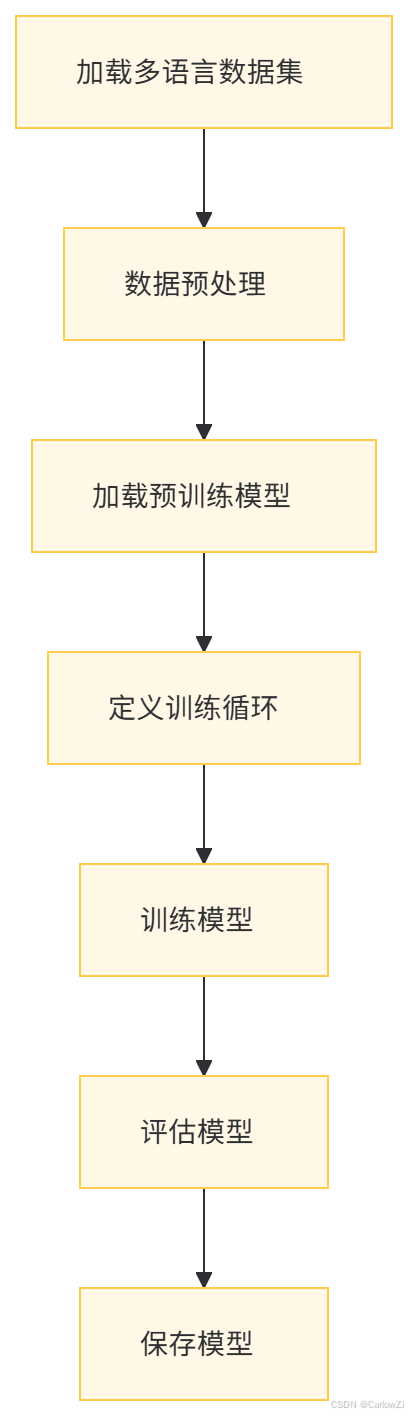
以下是跨语言文本分类任务的流程图,展示了从数据准备到模型训练的完整流程:
总结
多语言模型为跨语言任务提供了强大的支持,Hugging Face Transformers库提供了丰富的多语言预训练模型和工具。本文详细介绍了如何使用Hugging Face Transformers进行多语言模型的应用和跨语言任务的开发,包括数据准备、模型选择、训练循环、模型评估以及一些常见的应用场景和注意事项。希望本文能够帮助读者掌握这些技能,并将其应用于实际的NLP项目中。在未来的学习中,读者可以进一步探索模型的优化和部署,以实现更复杂的应用。
参考资料
-
Hugging Face Transformers官方文档
https://huggingface.co/transformers/
官方文档提供了详细的API说明、示例代码和教程,是学习Hugging Face Transformers的最佳资源。 -
XLM-R论文
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., ... & Stoyanov, V. (2019). Unsupervised Cross-lingual Representation Learning at Scale. arXiv preprint arXiv:1911.02116.
[1911.02116] Unsupervised Cross-lingual Representation Learning at Scale
XLM-R的原始论文,介绍了其设计原理和实现方法。 -
PyTorch官方文档
PyTorch documentation — PyTorch 2.7 documentation
PyTorch是Hugging Face Transformers库的主要依赖之一,其官方文档提供了详细的API说明和使用指南。 -
TensorFlow官方文档
https://www.tensorflow.org/api_docs
TensorFlow也是Hugging Face Transformers库的一个可选依赖,其官方文档提供了详细的API说明和使用指南。 -
Hugging Face Blog
https://huggingface.co/blog
Hugging Face官方博客,提供了关于Transformers库的最新动态、教程和案例研究。 -
GitHub代码示例
https://github.com/huggingface/transformers
Hugging Face Transformers库的GitHub仓库,提供了大量的代码示例和实现细节,是学习和开发的重要参考。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











