






目录
一、引言
(一)语言模型的发展背景
近年来,自然语言处理(NLP)领域取得了巨大的进展,尤其是大语言模型(LLMs)的出现,极大地推动了人工智能技术的发展。从最初的规则引擎到基于统计学习的方法,再到如今的深度学习模型,语言模型的性能不断提升。然而,传统的语言模型通常需要大量的标注数据来进行训练,这在实际应用中往往面临数据稀缺的问题。为了解决这一问题,零样本学习(Zero-Shot Learning)和少样本学习(Few-Shot Learning)应运而生。
(二)零样本学习与少样本学习的定义
-
零样本学习(Zero-Shot Learning):零样本学习是指模型在没有直接标注数据的情况下,通过学习其他相关任务的知识,来完成新任务的学习方法。它依赖于模型对语言的通用理解能力,以及对任务描述的解析能力。
-
少样本学习(Few-Shot Learning):少样本学习是指模型在只有少量标注数据的情况下,通过微调或其他方法,快速适应新任务的学习方法。它通常需要模型具备快速学习和泛化的能力。
二、零样本学习与少样本学习的概念
(一)零样本学习(Zero-Shot Learning)
零样本学习的核心在于模型能够利用已有的知识,通过任务描述来理解新任务的需求,并生成相应的输出。这种方法不需要任何标注数据,完全依赖于模型的通用语言能力。
1. 零样本学习的应用场景
-
文本分类:根据任务描述,对文本进行分类。
-
问答系统:根据问题的描述,生成准确的答案。
-
文本生成:根据提示生成符合要求的文本内容。
(二)少样本学习(Few-Shot Learning)
少样本学习的核心在于模型能够在只有少量标注数据的情况下,快速适应新任务。它通常需要对模型进行微调或其他优化方法。
1. 少样本学习的应用场景
-
文本分类:在只有少量标注数据的情况下,对文本进行分类。
-
问答系统:在只有少量问答对的情况下,生成准确的答案。
-
机器翻译:在只有少量双语数据的情况下,进行翻译任务。
(三)零样本学习与少样本学习的区别
表格
复制
| 特性 | 零样本学习(Zero-Shot Learning) | 少样本学习(Few-Shot Learning) |
|---|---|---|
| 数据需求 | 不需要标注数据 | 需要少量标注数据 |
| 模型依赖 | 依赖通用语言能力 | 依赖模型的快速学习能力 |
| 应用难度 | 较高,需要良好的任务描述 | 较低,但需要微调 |
| 性能 | 通常较低,但可扩展性强 | 通常较高,但依赖数据质量 |
三、零样本学习与少样本学习的应用场景
(一)文本分类
1. 零样本学习的文本分类
假设我们有一个情感分析任务,需要判断文本是正面还是负面。通过零样本学习,我们可以直接使用任务描述来指导模型完成任务:
[
{
"text": "这部电影太棒了,我非常喜欢!",
"task_description": "判断文本是正面还是负面"
}
]2. 少样本学习的文本分类
假设我们只有少量标注数据,可以通过少样本学习来优化模型:
[
{
"text": "这部电影太棒了,我非常喜欢!",
"label": "positive"
},
{
"text": "这部电影真的很糟糕,不推荐。",
"label": "negative"
}
](二)问答系统
1. 零样本学习的问答系统
假设我们正在开发一个医学问答系统,需要让模型更好地理解医学问题并生成准确的答案:
[
{
"question": "感冒应该如何治疗?",
"task_description": "根据问题生成准确的答案"
}
]2. 少样本学习的问答系统
假设我们只有少量问答对,可以通过少样本学习来优化模型:
[
{
"question": "感冒应该如何治疗?",
"answer": "感冒通常可以通过多喝水、多休息来缓解。如果症状严重,可以服用感冒药。"
}
](三)机器翻译
1. 零样本学习的机器翻译
假设我们正在开发一个中英翻译模型,需要让模型更好地处理中英翻译任务:
[
{
"source": "这是一篇关于人工智能的文章。",
"task_description": "将中文文本翻译成英文"
}
]2. 少样本学习的机器翻译
假设我们只有少量双语数据,可以通过少样本学习来优化模型:
[
{
"source": "这是一篇关于人工智能的文章。",
"target": "This is an article about artificial intelligence."
}
](四)文本生成
1. 零样本学习的文本生成
假设我们正在开发一个创意写作助手,需要让模型生成有趣的科幻故事:
[
{
"prompt": "在一个遥远的星球上,有一个会说话的猫……",
"task_description": "根据提示生成有趣的故事"
}
]2. 少样本学习的文本生成
假设我们只有少量生成样本,可以通过少样本学习来优化模型:
[
{
"prompt": "在一个遥远的星球上,有一个会说话的猫……",
"output": "这个猫名叫米洛,它拥有神奇的力量……"
}
]四、零样本学习与少样本学习的实现方法
(一)零样本学习的实现
零样本学习通常依赖于预训练模型的通用语言能力,通过任务描述来引导模型完成任务。以下是一个基于Hugging Face Transformers库的零样本学习代码示例:
1. 代码示例:零样本学习
from transformers import pipeline
# 加载预训练模型
model_name = "facebook/bart-large-mnli"
classifier = pipeline("zero-shot-classification", model=model_name)
# 定义任务描述和文本
text = "这部电影太棒了,我非常喜欢!"
candidate_labels = ["positive", "negative"]
task_description = "判断文本是正面还是负面"
# 使用零样本分类器
result = classifier(text, candidate_labels)
print(result)(二)少样本学习的实现
少样本学习通常需要对模型进行微调,以适应少量标注数据。以下是一个基于Hugging Face Transformers库的少样本学习代码示例:
1. 代码示例:少样本学习
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset
# 加载预训练模型和分词器
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载数据集
dataset = load_dataset("glue", "mrpc")
# 数据预处理
def preprocess_function(examples):
return tokenizer(examples["sentence1"], examples["sentence2"], truncation=True)
encoded_dataset = dataset.map(preprocess_function, batched=True)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
num_train_epochs=3,
weight_decay=0.01,
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
)
# 开始训练
trainer.train()五、零样本学习与少样本学习的注意事项
(一)数据质量与多样性
无论是零样本学习还是少样本学习,数据质量都是影响模型性能的关键因素。在少样本学习中,少量的标注数据需要具备高质量和多样性,以避免模型过拟合。在零样本学习中,任务描述的质量和清晰度直接影响模型的理解能力。
(二)模型选择与适配
不同的预训练模型在零样本学习和少样本学习中的表现可能不同。例如,一些模型可能更适合零样本学习,而另一些模型可能更适合少样本学习。选择合适的模型并进行适当的适配是提高性能的关键。
(三)性能评估与优化
在零样本学习和少样本学习中,性能评估尤为重要。由于数据量有限,模型的泛化能力需要通过严格的验证来评估。此外,优化超参数和选择合适的评估指标也是提高性能的重要手段。
六、架构图与流程图
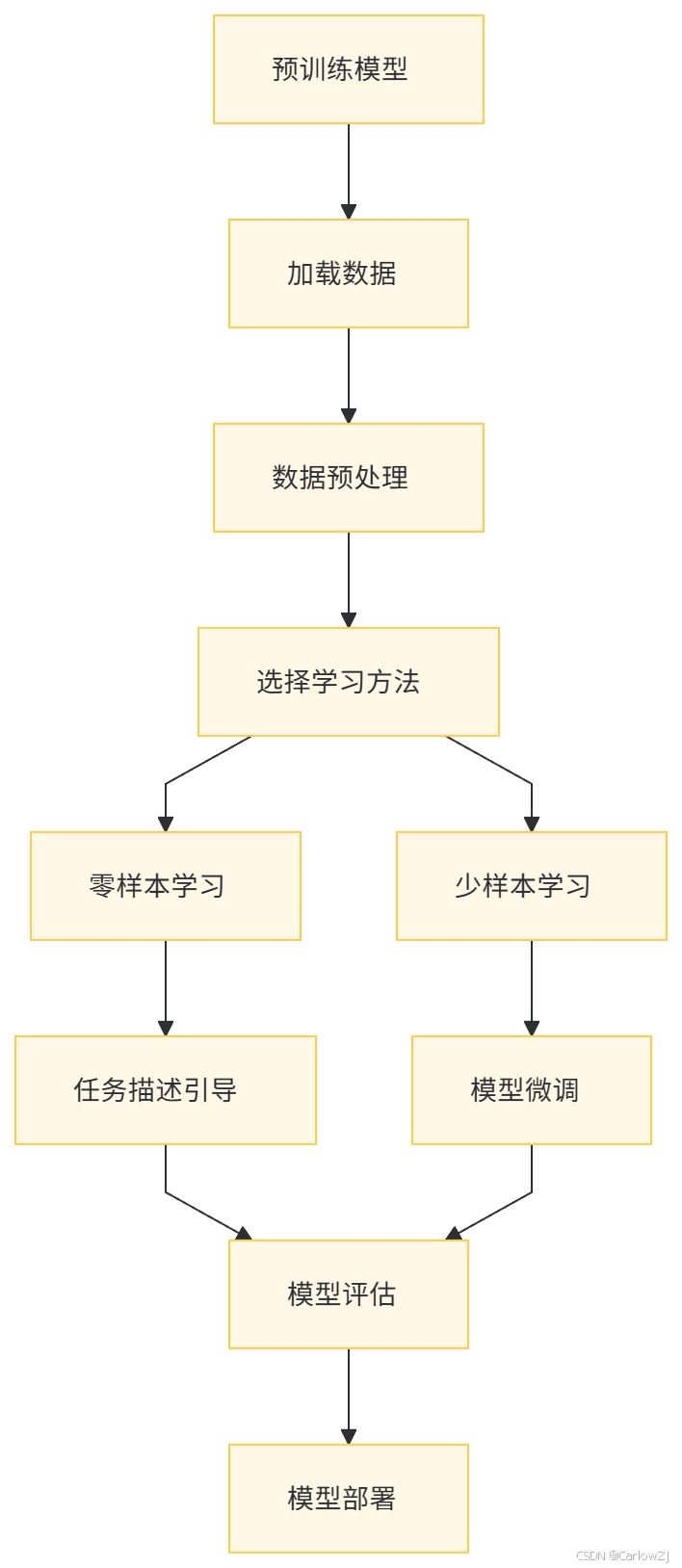
(一)架构图
以下是一个零样本学习与少样本学习的整体架构图:
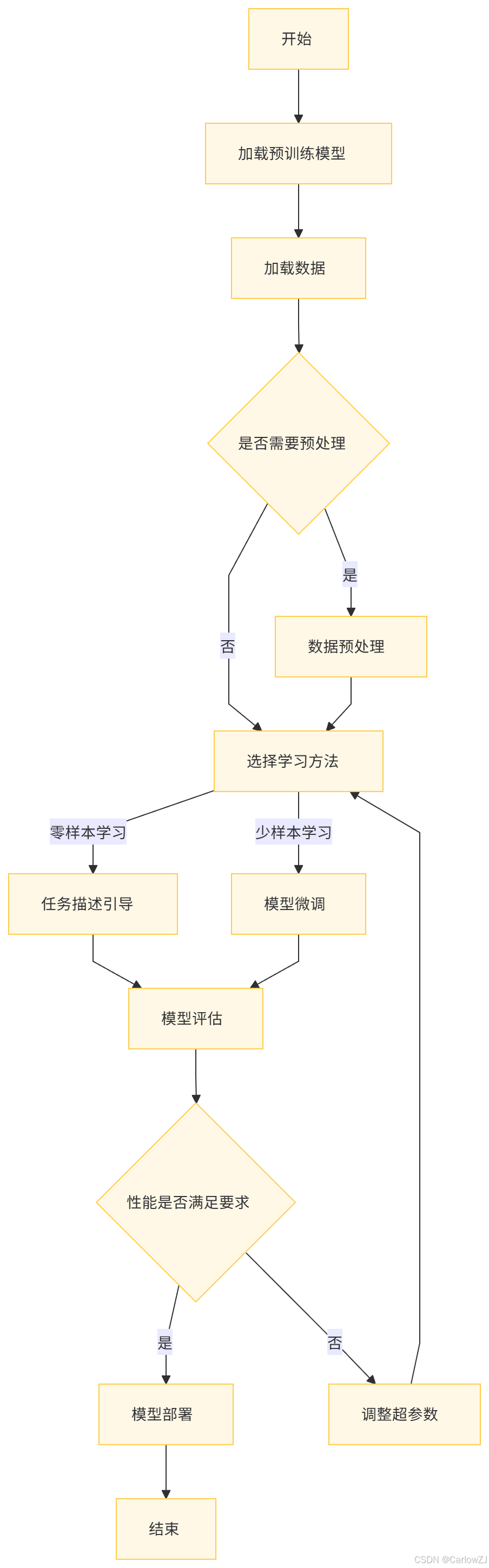
(二)流程图
以下是一个零样本学习与少样本学习的详细流程图:
七、总结
零样本学习和少样本学习是自然语言处理领域的重要技术,它们能够在数据稀缺的情况下,显著提高模型的性能和适应性。本文详细介绍了零样本学习和少样本学习的概念、应用场景、实现方法、代码示例以及注意事项,并通过架构图和流程图帮助读者更好地理解整个过程。希望本文对您有所帮助!如果您有任何问题或建议,欢迎在评论区留言。
在未来的文章中,我们将继续深入探讨大语言模型的更多高级技术,如多模态学习、强化学习等,敬请期待!
八、参考文献
-
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
-
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9.
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











