






目录
一、引言
(一)联邦学习的发展背景
随着人工智能技术的广泛应用,数据隐私和安全问题日益突出。传统的集中式训练方法需要将数据集中到一个中心服务器上进行处理,这不仅增加了数据泄露的风险,还可能违反数据隐私法规。联邦学习(Federated Learning, FL)作为一种分布式机器学习方法,允许模型在多个客户端上进行训练,而无需将数据集中到一个中心服务器上。这种方法在保护数据隐私的同时,还能充分利用分散的数据资源,提高模型的性能。
(二)联邦学习在大语言模型中的应用
大语言模型(LLMs)通常需要大量的数据进行训练,但在实际应用中,数据往往分散在不同的机构或用户手中。联邦学习技术可以通过在多个客户端上分布式训练语言模型,解决数据隐私和数据分散的问题。例如,在智能医疗、智能金融和智能教育等领域,联邦学习可以帮助机构在不共享数据的情况下,共同训练一个更强大的语言模型。
二、联邦学习的基本概念
(一)联邦学习的定义
联邦学习是一种分布式机器学习方法,允许多个客户端(如设备或机构)在本地训练模型,并通过安全的通信协议将模型更新汇总到一个中心服务器上。中心服务器再将这些更新聚合,生成全局模型,并将其分发回各个客户端。这一过程重复进行,直到模型收敛。
(二)联邦学习的关键组件
-
客户端(Client):参与训练的设备或机构。
-
中心服务器(Server):负责聚合模型更新并分发全局模型。
-
通信协议(Communication Protocol):客户端与服务器之间用于传输模型更新的协议。
-
模型聚合策略(Model Aggregation Strategy):用于将多个客户端的模型更新合并为全局模型的策略。
三、联邦学习在大语言模型中的应用
(一)分布式训练
联邦学习允许在多个客户端上分布式训练大语言模型,每个客户端可以在本地数据上训练模型,然后将模型更新发送到中心服务器。这种方法可以显著提高训练效率,同时减少数据传输量。
(二)数据隐私保护
联邦学习通过在本地训练模型,避免了数据的集中式处理,从而保护了数据隐私。这对于处理敏感数据(如医疗记录、金融数据等)尤为重要。
四、联邦学习技术的实现方法
(一)通信协议设计
通信协议是联邦学习的核心组件之一,它决定了客户端与服务器之间如何传输模型更新。常见的通信协议包括点对点通信和多对一通信。
(二)模型聚合策略
模型聚合策略决定了如何将多个客户端的模型更新合并为全局模型。常见的聚合策略包括简单的平均聚合和加权平均聚合。
(三)训练过程
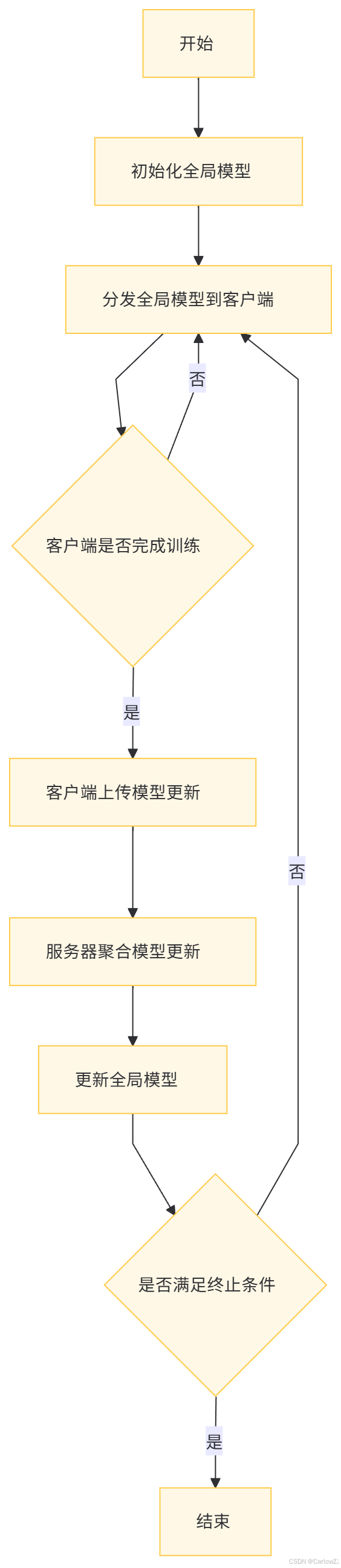
联邦学习的训练过程包括以下步骤:
-
初始化全局模型:中心服务器初始化全局模型。
-
分发全局模型:中心服务器将全局模型分发给各个客户端。
-
本地训练:每个客户端在本地数据上训练模型,并生成模型更新。
-
模型更新传输:客户端将模型更新发送到中心服务器。
-
模型聚合:中心服务器将多个客户端的模型更新聚合,生成新的全局模型。
-
重复步骤2-5:重复上述过程,直到模型收敛。
五、代码示例
(一)联邦学习环境搭建
以下是一个基于Python的联邦学习环境搭建代码示例:
import numpy as np
class Client:
def __init__(self, data):
self.data = data
self.model = np.random.rand(10) # 示例模型参数
def train(self):
# 在本地数据上训练模型
self.model += np.sum(self.data) * 0.1 # 示例训练逻辑
return self.model
class Server:
def __init__(self):
self.global_model = np.random.rand(10) # 初始化全局模型
def aggregate(self, client_updates):
# 聚合客户端的模型更新
self.global_model = np.mean(client_updates, axis=0)
# 创建客户端和服务器
clients = [Client(np.random.rand(100)) for _ in range(5)]
server = Server()
# 分发全局模型
for client in clients:
client.model = server.global_model.copy()
# 本地训练并上传更新
client_updates = [client.train() for client in clients]
# 聚合模型更新
server.aggregate(client_updates)(二)联邦学习训练
以下是一个联邦学习训练的代码示例:
for round in range(10): # 训练10轮
# 分发全局模型
for client in clients:
client.model = server.global_model.copy()
# 本地训练并上传更新
client_updates = [client.train() for client in clients]
# 聚合模型更新
server.aggregate(client_updates)
print(f"Round {round + 1}, Global Model: {server.global_model}")六、联邦学习的应用场景
(一)智能医疗
在智能医疗领域,联邦学习可以帮助多个医疗机构在不共享患者数据的情况下,共同训练一个更强大的医疗诊断模型。这不仅保护了患者的隐私,还能提高模型的准确性和泛化能力。
(二)智能金融
在智能金融领域,联邦学习可以帮助金融机构在不共享用户数据的情况下,共同训练一个更强大的风险评估模型。这对于保护用户隐私和提高金融安全性至关重要。
(三)智能教育
在智能教育领域,联邦学习可以帮助多个学校在不共享学生数据的情况下,共同训练一个更强大的教育推荐模型。这可以提高教育资源的分配效率和个性化教育的质量。
七、联邦学习的注意事项
(一)数据隐私保护
联邦学习的核心优势之一是保护数据隐私。在实现过程中,需要确保数据在客户端上进行处理,避免数据泄露。
(二)模型收敛性
联邦学习的收敛速度和最终性能受到客户端数据分布和通信频率的影响。需要通过适当的策略和超参数调整来确保模型的收敛性。
(三)性能评估
联邦学习模型的性能评估需要综合考虑多个客户端的贡献。可以使用分布式数据集进行验证和测试,以确保模型的泛化能力。
八、架构图与流程图
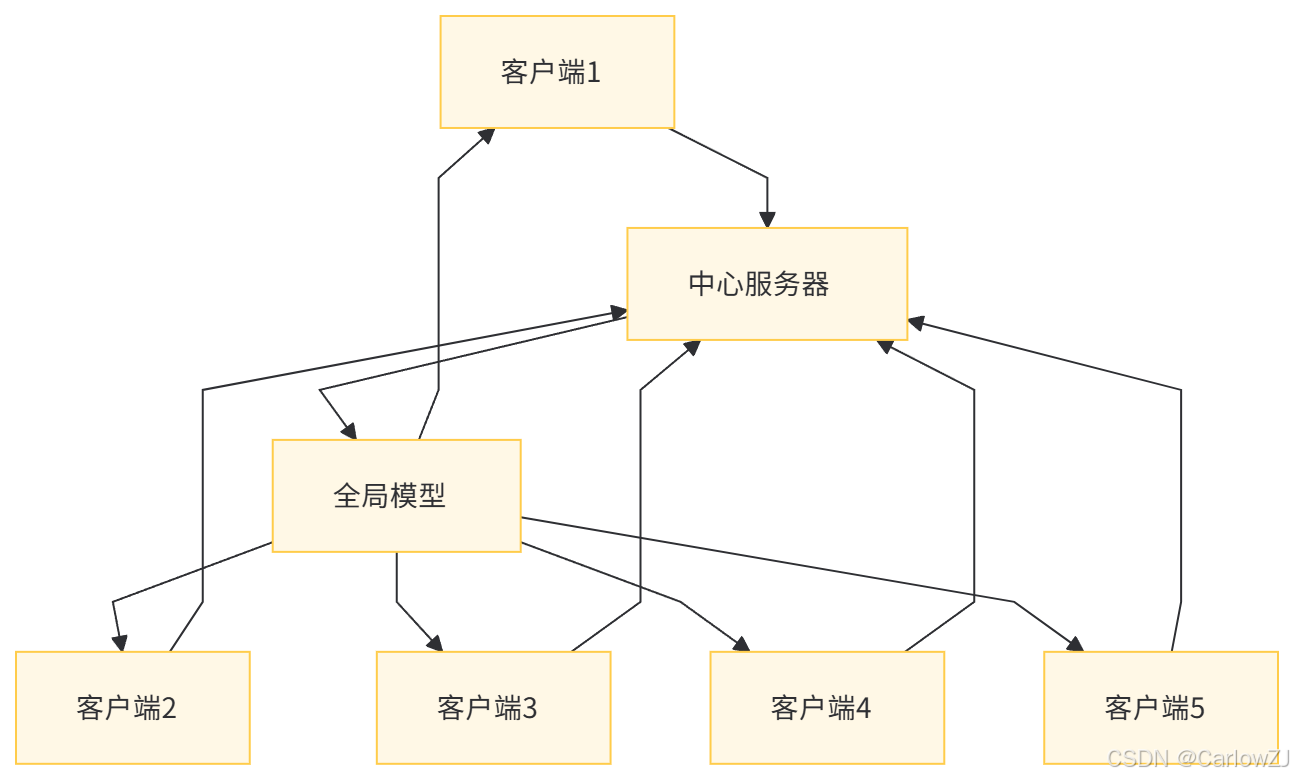
(一)架构图
以下是一个联邦学习的整体架构图:
(二)流程图
以下是一个联邦学习的详细流程图:
九、总结
联邦学习是大语言模型训练中的重要技术之一,它通过分布式训练和数据隐私保护,解决了数据分散和隐私问题。本文详细介绍了联邦学习的基本概念、应用场景、实现方法、代码示例以及注意事项,并通过架构图和流程图帮助读者更好地理解整个过程。希望本文对您有所帮助!如果您有任何问题或建议,欢迎在评论区留言。
在未来的文章中,我们将继续深入探讨大语言模型的更多高级技术,如多模态融合、强化学习等,敬请期待!
十、参考文献
-
McMahan, H. B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2016). Communication-efficient learning of deep networks from decentralized data. arXiv preprint arXiv:1602.05629.
-
Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. K., ... & Zhao, S. (2019). Advances and open problems in federated learning. arXiv preprint arXiv:1912.04977.
-
Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A., McMahan, H. B., Patel, S., ... & Ramage, D. (2019). Towards federated learning at scale: System design. arXiv preprint arXiv:1902.01046.
-
Hard, A., Rao, K., Ramage, D., & McMahan, H. B. (2018). Federated learning for mobile keyboard prediction. arXiv preprint arXiv:1811.03604.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











