






摘要
有监督微调是深度学习中一种重要的技术,它通过在特定任务上对预训练模型进行微调,能够显著提升模型在特定领域的性能。本文从有监督微调的基本概念出发,详细介绍了其原理、实现方法、应用场景以及注意事项。通过代码示例和实际案例,帮助读者快速掌握有监督微调的技巧,并在实际项目中应用。本文还通过数据流图和架构图,清晰地展示了有监督微调的流程和关键环节。
一、引言
-
介绍深度学习在各个领域的广泛应用。
-
引出有监督微调的概念及其重要性。
-
阐述本文的结构和目标。
二、有监督微调的基本概念
(一)深度学习与预训练模型
-
简述深度学习的基本原理。
-
介绍预训练模型的概念及其优势(如BERT、GPT等)。
-
说明预训练模型如何为有监督微调提供基础。
(二)有监督微调的定义
-
定义有监督微调的概念。
-
解释其与无监督学习、强化学习的区别。
-
强调有监督微调在特定任务上的优势。
(三)有监督微调的流程
-
数据准备:标注数据的收集和处理。
-
模型选择:选择合适的预训练模型。
-
微调过程:调整模型参数以适应特定任务。
-
模型评估:使用验证集和测试集评估模型性能。
三、有监督微调的实现方法
(一)数据准备
-
数据收集:如何获取高质量的标注数据。
-
数据预处理:清洗、标准化、分词等操作。
-
数据增强:通过数据增强提升模型泛化能力。
(二)模型选择
-
常见的预训练模型:BERT、GPT、ResNet等。
-
如何根据任务选择合适的模型。
-
模型的加载和初始化。
(三)微调过程
-
微调策略:全参数微调、部分参数微调、冻结参数微调等。
-
损失函数的选择:交叉熵损失、均方误差损失等。
-
优化器的选择:SGD、Adam等。
-
超参数调整:学习率、批次大小、训练轮数等。
(四)模型评估
-
评估指标:准确率、召回率、F1值、AUC等。
-
使用验证集进行模型选择。
-
使用测试集进行最终评估。
四、代码示例
(一)环境准备
-
安装必要的库:TensorFlow、PyTorch、Transformers等。
-
导入所需的模块。
(二)数据准备
import pandas as pd
from sklearn.model_selection import train_test_split
# 加载数据
data = pd.read_csv('data.csv')
# 划分训练集、验证集和测试集
train_data, temp_data = train_test_split(data, test_size=0.3, random_state=42)
valid_data, test_data = train_test_split(temp_data, test_size=0.5, random_state=42)(三)模型加载与微调
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
# 加载预训练模型和分词器
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 数据编码
train_encodings = tokenizer(train_data['text'].tolist(), truncation=True, padding=True)
valid_encodings = tokenizer(valid_data['text'].tolist(), truncation=True, padding=True)
# 将数据转换为模型需要的格式
class Dataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = Dataset(train_encodings, train_data['label'].tolist())
valid_dataset = Dataset(valid_encodings, valid_data['label'].tolist())
# 微调模型
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
evaluate_during_training=True,
logging_dir='./logs',
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset
)
trainer.train()(四)模型评估
from sklearn.metrics import accuracy_score, f1_score
# 使用测试集评估模型
test_encodings = tokenizer(test_data['text'].tolist(), truncation=True, padding=True)
test_dataset = Dataset(test_encodings, test_data['label'].tolist())
predictions = trainer.predict(test_dataset)
predicted_labels = predictions.predictions.argmax(-1)
print("Accuracy:", accuracy_score(test_data['label'], predicted_labels))
print("F1 Score:", f1_score(test_data['label'], predicted_labels, average='weighted'))五、应用场景
(一)自然语言处理
-
文本分类:情感分析、垃圾邮件检测等。
-
命名实体识别:从文本中提取关键信息。
-
机器翻译:提升翻译质量。
(二)计算机视觉
-
图像分类:识别图像中的物体。
-
目标检测:在图像中定位和识别目标。
-
图像分割:将图像分割为多个区域。
(三)语音识别
-
语音转文字:提高识别准确率。
-
情感分析:分析语音中的情感。
六、注意事项
(一)数据质量的重要性
-
数据标注的准确性。
-
数据的多样性和平衡性。
(二)过拟合与欠拟合
-
过拟合的识别与解决方法。
-
欠拟合的识别与解决方法。
(三)超参数调整
-
如何选择合适的超参数。
-
使用网格搜索或贝叶斯优化。
(四)计算资源与训练时间
-
微调的计算资源需求。
-
如何优化训练时间。
七、架构图与数据流图
(一)架构图
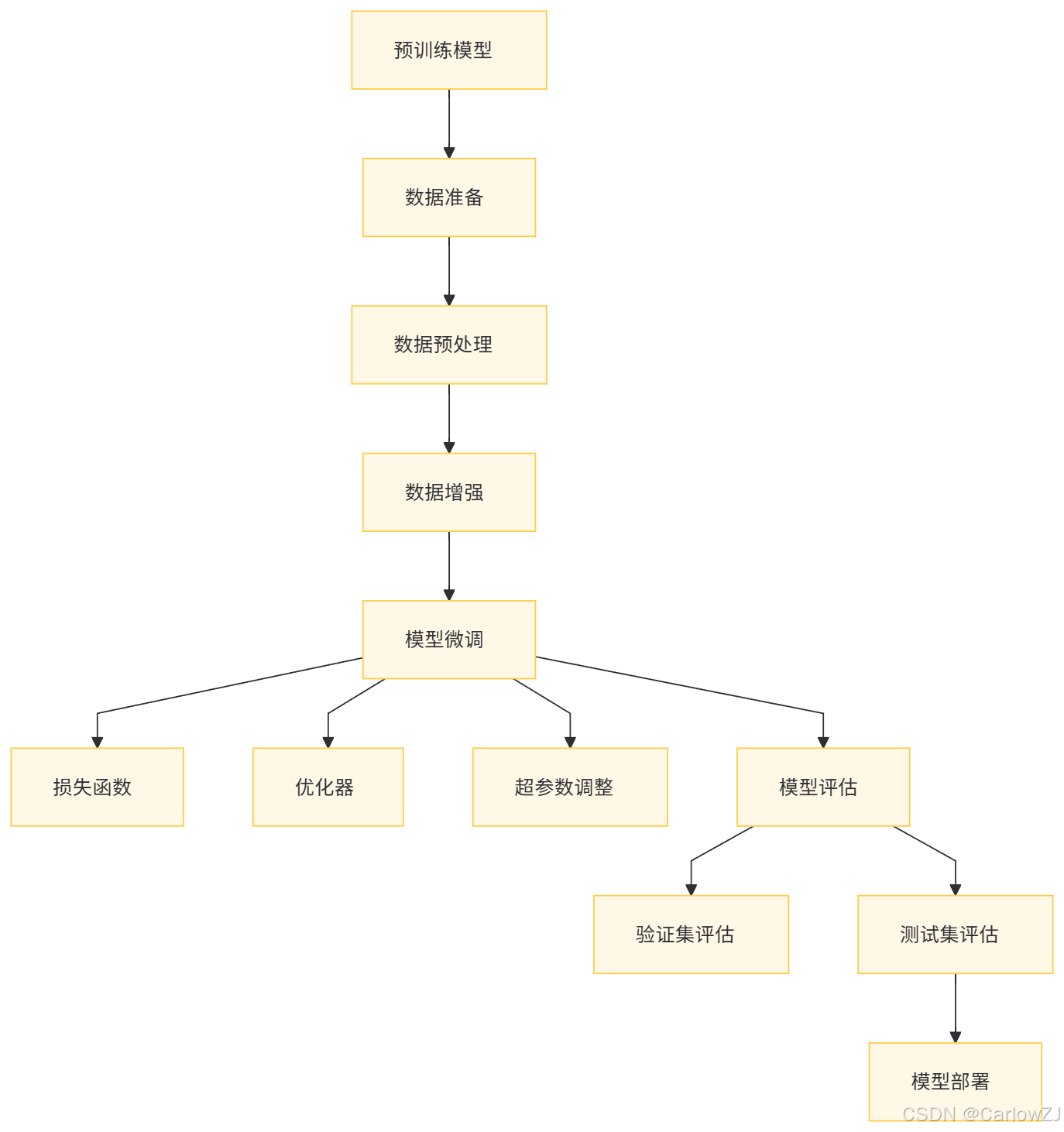
(二)数据流图
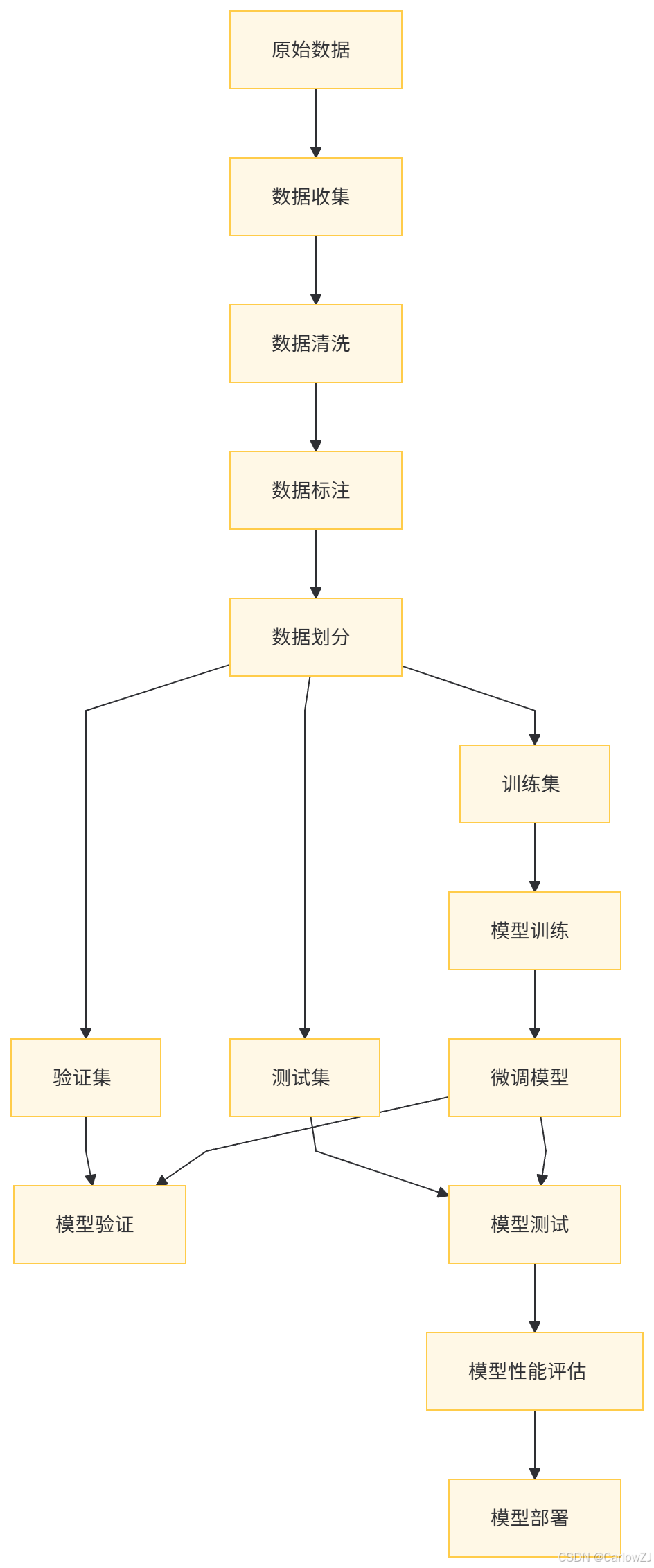
八、总结
-
回顾有监督微调的基本概念和实现方法。
-
强调其在实际应用中的重要性和优势。
-
提出未来研究方向和改进方法。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











