







大家好,今天我们主要讲解pandas模块的进阶用法,包括数据的查找、替换、插入、删除、排序、筛选、运算,以及数据表的结构转换和拼接等。
一、数据的查找和替换
查找数据 使用模块中的isin()函数可以查看DataFrame是否包含某个值,演示代码如下:
import pandas as qq
data=qq.read_excel('D:/shujufenxi/qwe.xlsx')
data1 = data.isin(['a3','王明'])#在表中查找符合'a3'与'王明'的值,标为True,否则为False
data2 = data['姓名'].isin(['王明'])# 表示在姓名列查找值王明,等于的地方标为True,否则为False
print(data)
print(data1)
print(data2)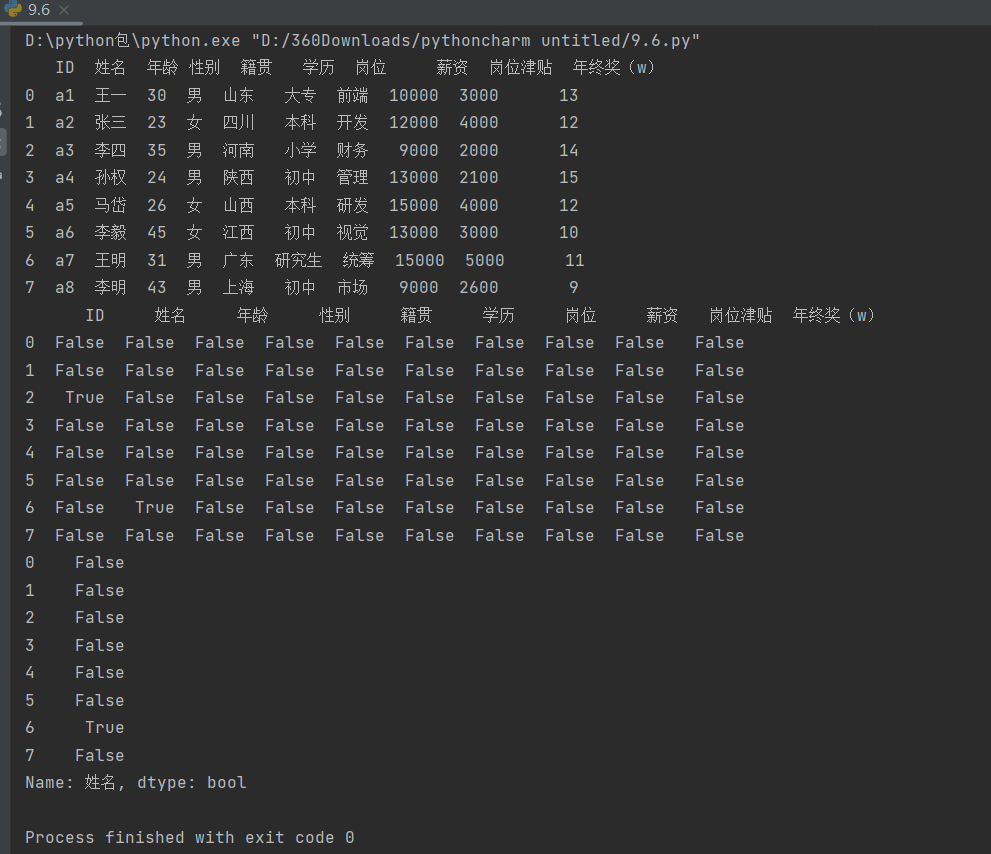
替换数据 使用replace()函数进行替换,代码演示如下:
import pandas as qq
data=qq.read_excel('D:/shujufenxi/qwe.xlsx')
data.replace('研发','技术',inplace=True)# 一对一替换,将'研发'替换为'技术'
data.replace(['研发','开发'],'技术',inplace=True)# 多对一替换,将'研发','开发'都替换为'技术'
data.replace({'研发':'技术','男':'man','女':'women'},inplace=True)# 多对多替换,将'研发'替换为'技术','男'替换为'man','女'替换为'women'
print(data)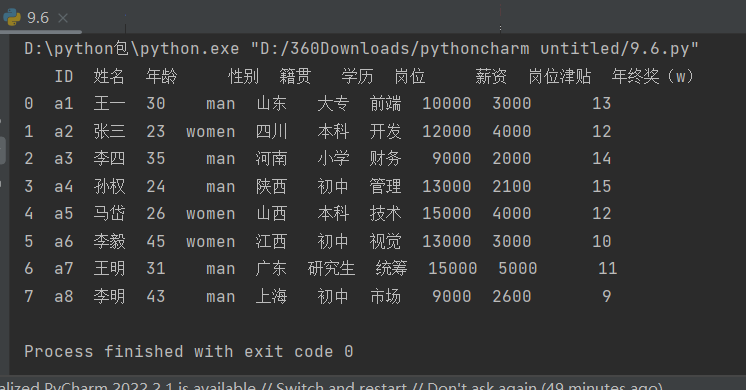
二、数据的处理
插入数据 插入数据主要有以下两种方法:
以赋值的方法直接在数据表最右侧插入列数据
用insert()函数在数据表的指定位置进行插入。 代码演示:
import pandas as qq
data=qq.read_excel('D:/shujufenxi/qwe.xlsx')
qq.set_option('display.unicode.ambiguous_as_wide', True) # 这行以及下一行的意思为调整列标题与下面数据对齐
qq.set_option('display.unicode.east_asian_width', True) # 同上
data['等级']=['A','B','C','D','E','F','G','H']# 以赋值的方法在数据表最右侧插入列数据
data.insert(3,'等级',['A','B','C','D','E','F','G','H']) # 用insert()函数在数据表的指定位置进行插入
print(data)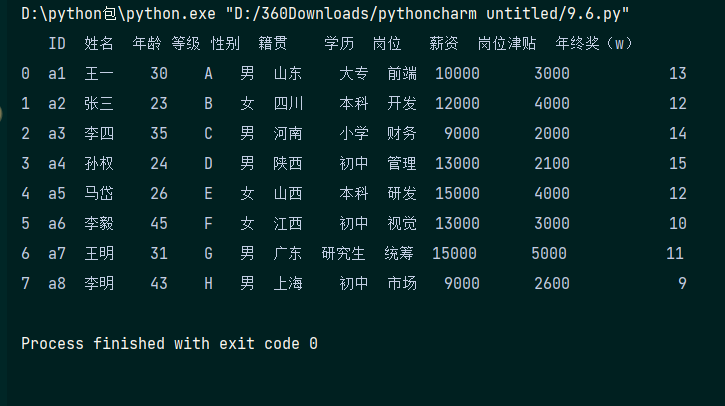
删除数据 如要删除数据表中的数据,可以使用pandas模块中的drop()函数,删除列:
import pandas as qq
data=qq.read_excel('D:/shujufenxi/qwe.xlsx')
a=data.drop(['年龄','年终奖(w)'],axis=1) # 删除'等级','年终奖(w)'两列数据,axis=1,意思为按列删除
b= data.drop(data.columns[[3,6]],axis=1)# 删除数据表中的第3、6列
print(a)
print(b)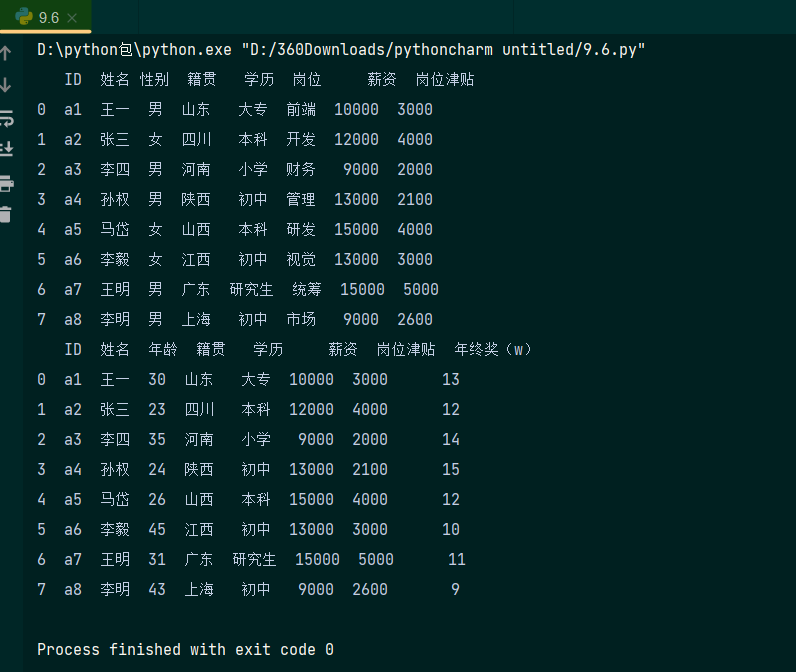
删除行 删除数据行与上面删除列的方法类似,只不过是需要将参数axis设置为0即可,其余代码参考以上删除行演示代码,在这里就不细细讲解。
查看缺失值:
import pandas as qw
data=qw.read_excel('D:/shujufenxi/qwe.xlsx')
print(data)
# 查看每一列的缺失值,可以用info()函数,例如print(data.info())
# 还可以使用isnull()函数判断是否为缺失值,例如:a=data.isnull()
# print(a)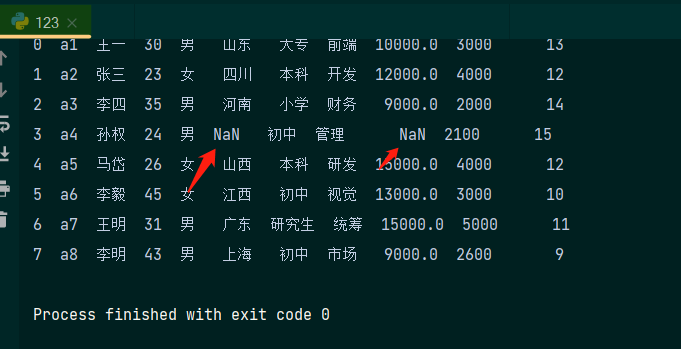
缺失值的填充:
使用fillna()函数可将数据表中的所有缺失值填充为指定的值,演示代码如下:
import pandas as qw
data=qw.read_excel('D:/shujufenxi/qwe.xlsx')
a= data.fillna(0)# 将所有缺失值都替换为0
b= data.fillna({'籍贯':'陕西','薪资':'15000'}) #通过fillna()函数传入一个字典,将不同列中的缺失值设置为不同的填充值。
print(a)
print(b)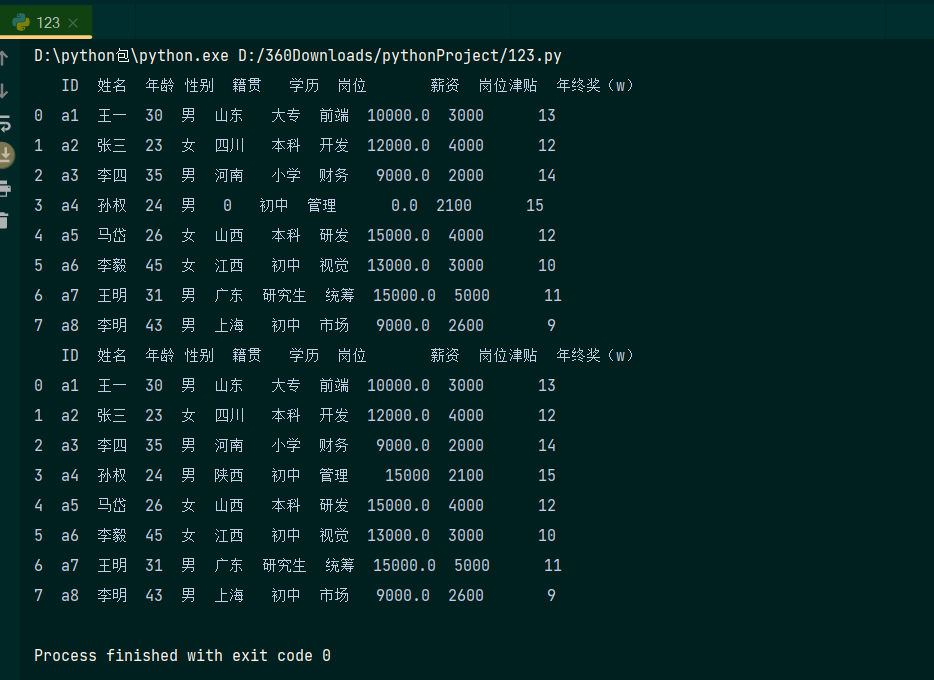
筛选数据,根据指定条件对数据进行筛选,代码演示如下:
import pandas as qw
data=qw.read_excel('D:/shujufenxi/qwe.xlsx')
a=data[data['ID']=='a3']# 筛选出数据表中ID为3的数据,==为比较运算符
b= data[data['薪资']>9000]#筛选出数据表中薪资>9000的数据
c= data[(data['薪资']>9000)& (data['性别']=='女')]# 筛选出数据表中薪资>9000,且性别为女的数据
d= data[(data['年终奖(w)']>13) | (data['籍贯']=='河南')]#筛选出数据表中年终奖>13的或者籍贯为河南的数据
print(a)
print(b)
print(c)
print(d)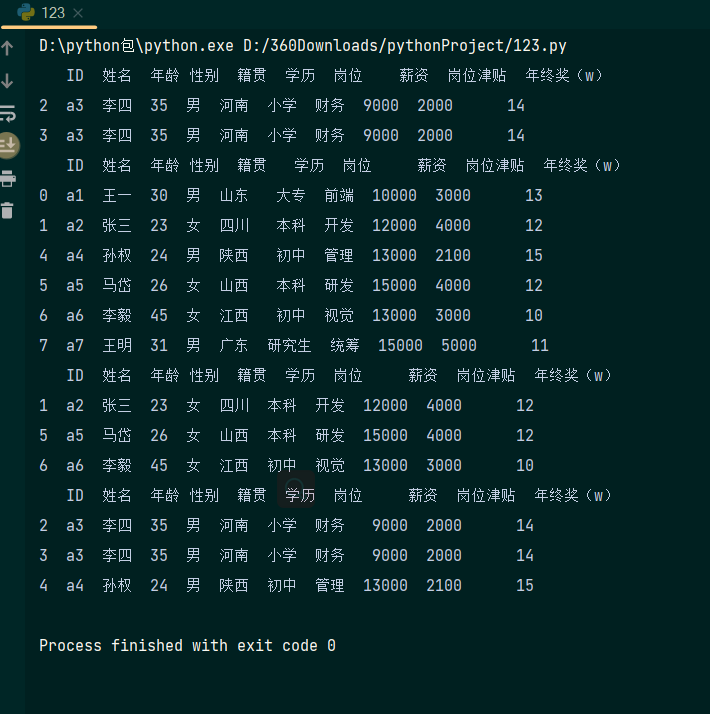
三、数据表的处理
转置数据表的行列 演示代码如下:
import pandas as qw
data=qw.read_excel('D:/shujufenxi/qwe.xlsx')
a=data.T
print(a)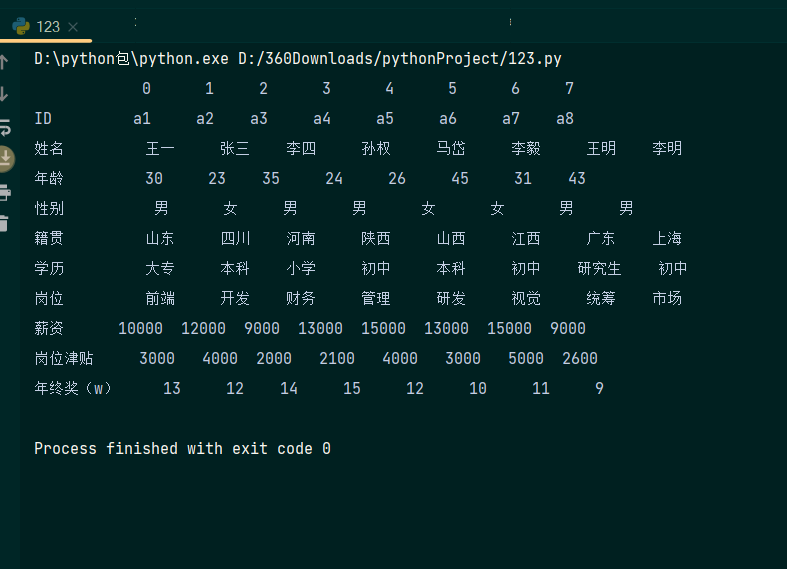
将数据表转换为树形结构 演示代码如下:
import pandas as qw
data=qw.read_excel('D:/shujufenxi/qwe1.xlsx')
a=data.stack()
print(a)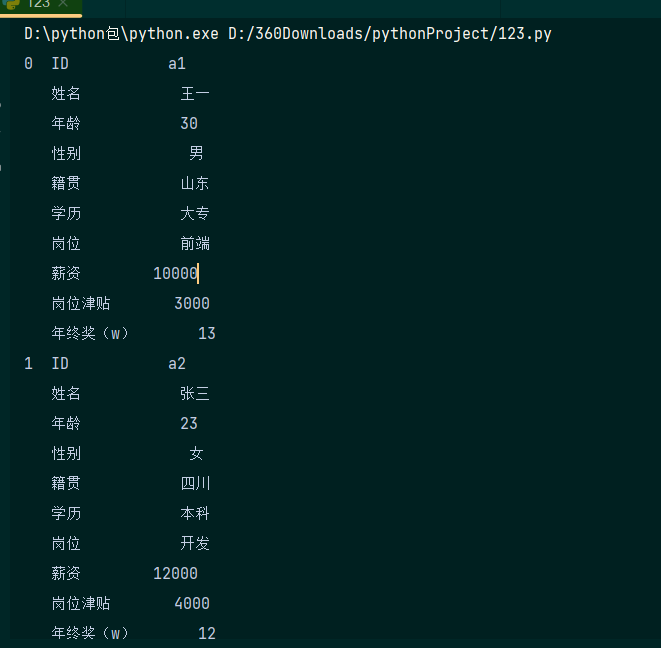
数据表的拼接 数据表的拼接是指将两个或多个数据表合并为一个数据表,用要用到merge()函数、concat()函数、append()函数,使用语法格式如下:
data1=qw.read_excel('D:/shujufenxi/qwe.xlsx')
a=qw.merge(data,data1,how='outer','on'='姓名')#使用merge()函数合并数据表,hou参数为合并两个表中所有的数据;on参数则是用来指定依据哪一列进行合并操作
b=qw.concat([data,data1],ignore_index=True)# 采用cincat()函数合并工作表,ignore_index参数重置行标签
c=data.append(data1)#采用append()函数合并工作表,也可以用于在数据表的末尾追加数据,如:c=data.append({'ID':a9,’姓名‘:'张一'},ignore_index=True)结果在此就不一一演示,大家可以自己运行一下试试看。
四、数据的运算
获取数值分布状况:
import pandas as qw
data=qw.read_excel('D:/shujufenxi/qwe1.xlsx')
a=data.describe()
print(a)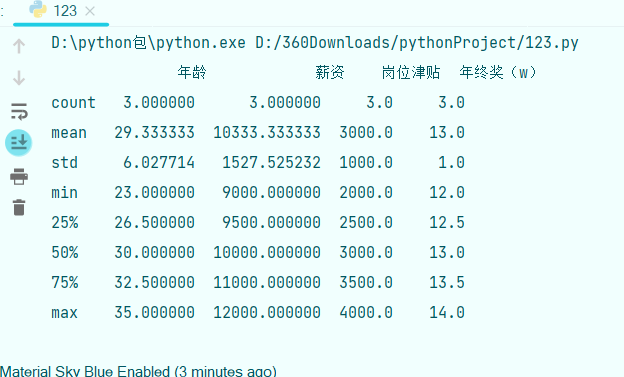
计算相关系数:
a=data.corr()分类汇总数据:
a=data.groupby()#括号内设置的参数为依据哪一列数据进行分组创建数据透视表 数据透视表可对数据表中的数据进行快速分组和计算,pandas模块中的pivot_table()函数可以制作,演示代码如下:
import pandas as qw
data=qw.read_excel('D:/shujufenxi/qwe1.xlsx')
a=qw.pivot_table(data,values='年龄',index='姓名',aggfunc='sum')# 参数values用于指定要计算的列;index用于指定一个列作为数据透视表的行标签,aggfunc用于指定参数values的计算类型
print(a)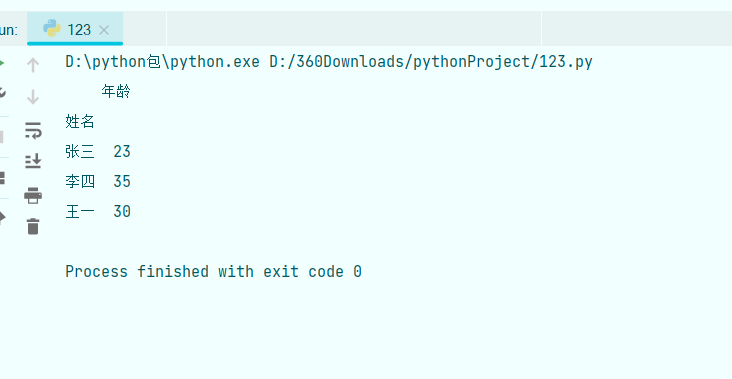
















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











