






Assignment 2 : Character level language model - Dinosaurus land
这个作业,是个小项目,很有意思,利用作业一中我们自己构建的RNN,来建立一个字符级别的语言模型。
背景:利用人类已经命名的恐龙名字,作为训练集,让模型知道某个字母(比如D)后面应该接什么字母(比如D-e-c-a-r-u-s),由此生成一系列新的恐龙名字。
当然这个项目看似很小,实则可以发散,在作业的最后,就有一个把任意文本转换成“莎士比亚”风格文本的语言模型。在以后,甚至可以让机器来“写作”,写新闻稿之类的。
1. 数据预处理
dinos.txt内含有人类已命名的恐龙名字,瞥一下,大概是这样:
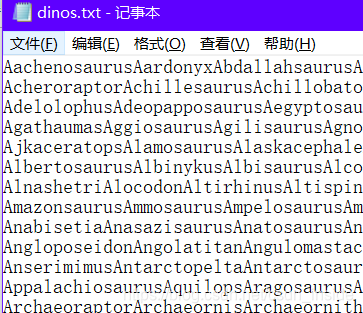
工欲善其事,必先利其器,先看看这个数据集有些什么东西。
import numpy as np
from utils import *
import random
data = open('dinos.txt', 'r').read()
data= data.lower()
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print('There are %d total characters and %d unique characters in your data.' % (data_size, vocab_size))
There are 19909 total characters and 27 unique characters in your data.
有19909个字符,27个唯一字符(a-z + 换行符\n,在这里作为EOS) 。
创立两个dict,一个字符—索引,一个索引—字符,用来把这27个字符索引化。
char_to_ix = { ch:i for i,ch in enumerate(sorted(chars)) }
ix_to_char = { i:ch for i,ch in enumerate(sorted(chars)) }
print(ix_to_char)
{0: '\n', 1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f', 7: 'g', 8: 'h', 9: 'i', 10: 'j', 11: 'k', 12: 'l', 13: 'm',
14: 'n', 15: 'o', 16: 'p', 17: 'q', 18: 'r', 19: 's', 20: 't', 21: 'u', 22: 'v', 23: 'w', 24: 'x', 25: 'y', 26: 'z'}
2. 模型总览
·初始化参数
·进行参数优化循环
·FP计算Loss
·BP计算梯度
·利用Gradient Clip解决梯度爆炸
·利用梯度更新参数
·返回达到条件的参数
在这个模型里面,y<t>=x<t+1>。就是某个时间的x<t>,其经过RNN的预测标记为y-hat<t>,而真实标记y<t>,就是下一个字符x<t+1>。
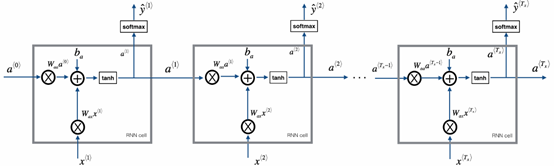
3. 构建模型组件
需要构建两个很重要的模型组件
·Gradient Clip 梯度切割,用来解决梯度爆炸。
·Sampling 采样,用来生成新的恐龙名字。
梯度切割
这个函数,接受一个梯度字典,返回一个切割后的梯度字典。
梯度切割,就是设定一个梯度的范围—[minValue,maxValue],如果梯度大于maxValue则置为maxValue,小于minValue则置为minValue。
梯度切割带来的好处,就是解决梯度爆炸,让优化能够更快收敛。
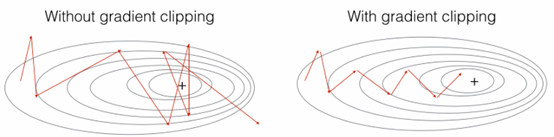
def clip(gradients, maxValue):
'''
Arguments:
gradients -- a dictionary containing the gradients "dWaa", "dWax", "dWya", "db", "dby"
maxValue -- everything above this number is set to this number, and everything less than -maxValue is set to -maxValue
Returns:
gradients -- a dictionary with the clipped gradients.
'''
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
### START CODE HERE ###
# clip to mitigate exploding gradients, loop over [dWax, dWaa, dWya, db, dby]. (≈2 lines)
for gradient in [dWax, dWaa, dWya, db, dby]:
np.clip(gradient,-maxValue,maxValue,out=gradient)
### END CODE HERE ###
gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
采样
一旦模型被训练好,就可以进行采样,来生成新的文本了。
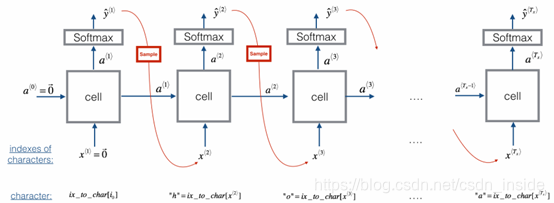
具体过程是:
·Step 1:用全0的x<1>和a<0>作为初始输入。
·Step 2:计算a<t+1>和y-hat<t>。y-hat<t>是一个softmax,所有概率加起来等于1。
·Step 3:在y-hat<t>中选择一个概率,记住其索引,通过一开始的索引—字符,得到这个生成的字符。
·Step 4:让这个生成的字符作为下一次的输入x<t+1>,一直进行,直到遇到\n字符,就结束。
def sample(parameters, char_to_ix, seed):
"""
Arguments:
parameters -- python dictionary containing the parameters Waa, Wax, Wya, by, and b.
char_to_ix -- python dictionary mapping each character to an index.
seed -- used for grading purposes. Do not worry about it.
Returns:
indices -- a list of length n containing the indices of the sampled characters.
"""
# Retrieve parameters and relevant shapes from "parameters" dictionary
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
### START CODE HERE ###
# Step 1: Create the one-hot vector x for the first character (initializing the sequence generation). (≈1 line)
x = np.zeros((vocab_size,1))
# Step 1': Initialize a_prev as zeros (≈1 line)
a_prev = np.zeros((n_a,1))
# Create an empty list of indices, this is the list which will contain the list of indices of the characters to generate (≈1 line)
indices = []
# Idx is a flag to detect a newline character, we initialize it to -1
idx = -1
# Loop over time-steps t. At each time-step, sample a character from a probability distribution and append
# its index to "indices". We'll stop if we reach 50 characters (which should be very unlikely with a well
# trained model), which helps debugging and prevents entering an infinite loop.
counter = 0
newline_character = char_to_ix['\n']
while (idx != newline_character and counter != 50):
# Step 2: Forward propagate x using the equations (1), (2) and (3)
a = np.tanh(Wax.dot(x)+Waa.dot(a_prev)+b)
z = Wya.dot(a)+by
y = softmax(z)
# for grading purposes
np.random.seed(counter+seed)
# Step 3: Sample the index of a character within the vocabulary from the probability distribution y
idx = np.random.choice(np.arange(vocab_size),p=y.ravel())
# Append the index to "indices"
indices.append(idx)
# Step 4: Overwrite the input character as the one corresponding to the sampled index.
x = np.zeros((vocab_size,1))
x[idx] = 1
# Update "a_prev" to be "a"
a_prev = a
# for grading purposes
seed += 1
counter +=1
### END CODE HERE ###
if (counter == 50):
indices.append(char_to_ix['\n'])
return indices
4. 构建语言模型
先构建单次优化。之后一直迭代这个优化就成了最终模型。
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
"""
Arguments:
X -- list of integers, where each integer is a number that maps to a character in the vocabulary.
Y -- list of integers, exactly the same as X but shifted one index to the left.
a_prev -- previous hidden state.
parameters -- python dictionary containing:
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
b -- Bias, numpy array of shape (n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
learning_rate -- learning rate for the model.
Returns:
loss -- value of the loss function (cross-entropy)
gradients -- python dictionary containing:
dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x)
dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a)
dWya -- Gradients of hidden-to-output weights, of shape (n_y, n_a)
db -- Gradients of bias vector, of shape (n_a, 1)
dby -- Gradients of output bias vector, of shape (n_y, 1)
a[len(X)-1] -- the last hidden state, of shape (n_a, 1)
"""
### START CODE HERE ###
# Forward propagate through time (≈1 line)
loss, cache = rnn_forward(X,Y,a_prev,parameters)
# Backpropagate through time (≈1 line)
gradients, a = rnn_backward(X,Y,parameters,cache)
# Clip your gradients between -5 (min) and 5 (max) (≈1 line)
gradients = clip(gradients,5)
# Update parameters (≈1 line)
parameters = update_parameters(parameters,gradients,learning_rate)
### END CODE HERE ###
return loss, gradients, a[len(X)-1]
最终模型:
def model(data, ix_to_char, char_to_ix, num_iterations = 35000,
n_a = 50, dino_names = 7, vocab_size = 27):
"""
Arguments:
data -- text corpus
ix_to_char -- dictionary that maps the index to a character
char_to_ix -- dictionary that maps a character to an index
num_iterations -- number of iterations to train the model for
n_a -- number of units of the RNN cell
dino_names -- number of dinosaur names you want to sample at each iteration.
vocab_size -- number of unique characters found in the text, size of the vocabulary
Returns:
parameters -- learned parameters
"""
# Retrieve n_x and n_y from vocab_size
n_x, n_y = vocab_size, vocab_size
# Initialize parameters
parameters = initialize_parameters(n_a, n_x, n_y)
# Initialize loss (this is required because we want to smooth our loss, don't worry about it)
loss = get_initial_loss(vocab_size, dino_names)
# Build list of all dinosaur names (training examples).
with open("dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
# Shuffle list of all dinosaur names
np.random.seed(0)
np.random.shuffle(examples)
# Initialize the hidden state of your LSTM
a_prev = np.zeros((n_a, 1))
# Optimization loop
for j in range(num_iterations):
### START CODE HERE ###
# Use the hint above to define one training example (X,Y) (≈ 2 lines)
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
# Perform one optimization step: Forward-prop -> Backward-prop -> Clip -> Update parameters
# Choose a learning rate of 0.01
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
### END CODE HERE ###
# Use a latency trick to keep the loss smooth. It happens here to accelerate the training.
loss = smooth(loss, curr_loss)
# Every 2000 Iteration, generate "n" characters thanks to sample() to check if the model is learning properly
if j % 2000 == 0:
print('Iteration: %d, Loss: %f' % (j, loss) + '\n')
# The number of dinosaur names to print
seed = 0
for name in range(dino_names):
# Sample indices and print them
sampled_indices = sample(parameters, char_to_ix, seed)
print_sample(sampled_indices, ix_to_char)
seed += 1 # To get the same result for grading purposed, increment the seed by one.
print('\n')
return parameters
训练过程:
Iteration: 0, Loss: 23.087336
Nkzxwtdmfqoeyhsqwasjkjvu
Kneb
Kzxwtdmfqoeyhsqwasjkjvu
Neb
Zxwtdmfqoeyhsqwasjkjvu
Eb
Xwtdmfqoeyhsqwasjkjvu
Iteration: 2000, Loss: 27.884160
Liusskeomnolxeros
Hmdaairus
Hytroligoraurus
Lecalosapaus
Xusicikoraurus
Abalpsamantisaurus
Tpraneronxeros
Iteration: 4000, Loss: 25.901815
Mivrosaurus
Inee
Ivtroplisaurus
Mbaaisaurus
Wusichisaurus
Cabaselachus
Toraperlethosdarenitochusthiamamumamaon
········
Iteration: 30000, Loss: 22.774404
Phytys
Lica
Lysus
Pacalosaurus
Ytrochisaurus
Eiacosaurus
Trochesaurus
Iteration: 32000, Loss: 22.209473
Mawusaurus
Jica
Lustoia
Macaisaurus
Yusolenqtesaurus
Eeaeosaurus
Trnanatrax
Iteration: 34000, Loss: 22.396744
Mavptokekus
Ilabaisaurus
Itosaurus
Macaesaurus
Yrosaurus
Eiaeosaurus
Trodon
可见到后面,生成的文本,越来越像“恐龙名字”了。
5. 莎士比亚化
作业的最后提供了一个训练好的“莎士比亚”模型,输入一段文本,转换成莎士比亚风格的文本。基本原理类似,只不过用了LSTM,兼顾前后联系,而且网络不是单层而是两层的。
比如我输入:
for those who come,i will kill them all,
它就输出了一大串古英语:
port heeshif agay, that bust nake deter cae buth,
of whe cavens that forseds how pusty that stell murling,
on one, my holded wis to rry my creans,
seof ound and woumpren comare sup as norh,
wime the which and hay ineet wond-now thin: and hably carsiand eyes's noir:
then by shoulf they noth con hisfater,
and all my gongess his life heart thine to wilr,
are but metery wakes ow lost excain de.
tha

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









