






重构: 改善既有代码设计 - 第二版 第1–5章
下载地址:https://wwbf.lanzouw.com/iKbPZ2dpsxmj
作者: Martin Fowler
从前,有位咨询顾问造访客户调研其开发项目。该系统的核心是一个类继承体系,顾问看了开发人员所写的一些代码。他发现整个体系相当凌乱,上层超类对系统的工作方式做了一些假设,下层子类实现这些假设。但是这些假设并不适合所有子类,导致覆写(override)工作非常繁重。只要在超类做点修改,就可以减少许多覆写工作。在另一些地方,超类的某些意图并未被良好理解,因此其中某些行为在子类内重复出现。还有一些地方,好几个子类做相同的事情,其实可以把它们搬到继承体系的上层去做。
这位顾问于是建议项目经理看看这些代码,把它们整理一下,但是项目经理并不热衷于此,毕竟程序看上去还可以运行,而且项目面临很大的进度压力。于是项目经理说,晚些时候再抽时间做这些整理工作。
顾问也把他的想法告诉了在这个继承体系上工作的程序员,告诉他们可能发生的事情。程序员都很敏锐,马上就看出问题的严重性。他们知道这并不全是他们的错,有时候的确需要借助外力才能发现问题。程序员立刻用了一两天的时间整理好这个继承体系,并删掉了其中一半代码,功能毫发无损。他们对此十分满意,而且发现在继承体系中加入新的类或使用系统中的其他类都更快、更容易了。
项目经理并不高兴。进度排得很紧,有许多工作要做。系统必须在几个月之后发布,而这些程序员却白白耗费了两天时间,做的工作与未来几个月要交付的大量功能毫不相干。原先的代码运行起来还算正常。的确,新的设计更加“纯粹”、更加“整洁”。但项目要交付给客户的,是可以有效运行的代码,不是用以取悦学究的代码。顾问接下来又建议应该在系统的其他核心部分进行这样的整理工作,这会使整个项目停顿一至两个星期。所有这些工作只是为了让代码看起来更漂亮,并不能给系统添加任何新功能。
你对这个故事有什么感想?你认为这个顾问的建议(更进一步整理程序)是对的吗?你会遵循那句古老的工程谚语吗:“如果它还可以运行,就不要动它。”
我必须承认自己有某些偏见,因为我就是那个顾问。6个月之后这个项目宣告失败,很大的原因是代码太复杂,无法调试,也无法将性能调优到可接受的水平。
后来,这个项目重新启动,几乎从头开始编写整个系统,Kent Beck受邀做了顾问。他做了几件迥异以往的事,其中最重要的一件就是坚持以持续不断的重构行为来整理代码。这个团队效能的提升,以及重构在其中扮演的角色,启发了我撰写本书的第1版,如此一来我就能够把Kent和其他一些人已经学会的“以重构方式改进软件质量”的知识,传播给所有读者。
自本书第1版问世至今,读者的反馈甚佳,重构的理念已经被广泛接纳,成为编程的词汇表中不可或缺的部分。然而,对于一本与编程相关的书而言,18年已经太漫长,因此我感到,是时候回头重新修订这本书了。我几乎重写了全书的每一页,但从其内涵而言,整本书又几乎没有改变。重构的精髓仍然一如既往,大部分关键的重构手法也大体不变。我希望这次修订能帮助更多的读者学会如何有效地进行重构。
什么是重构
所谓重构(refactoring)是这样一个过程:在不改变代码外在行为的前提下,对代码做出修改,以改进程序的内部结构。重构是一种经千锤百炼形成的有条不紊的程序整理方法,可以最大限度地减小整理过程中引入错误的概率。本质上说,重构就是在代码写好之后改进它的设计。
“在代码写好之后改进它的设计”这种说法有点儿奇怪。在软件开发的大部分历史时期,大部分人相信应该先设计而后编码:首先得有一个良好的设计,然后才能开始编码。但是,随着时间流逝,人们不断修改代码,于是根据原先设计所得的系统,整体结构逐渐衰弱。代码质量慢慢沉沦,编码工作从严谨的工程堕落为胡砍乱劈的随性行为。
“重构”正好与此相反。哪怕手上有一个糟糕的设计,甚至是一堆混乱的代码,我们也可以借由重构将它加工成设计良好的代码。重构的每个步骤都很简单,甚至显得有些过于简单:只需要把某个字段从一个类移到另一个类,把某些代码从一个函数拉出来构成另一个函数,或是在继承体系中把某些代码推上推下就行了。但是,聚沙成塔,这些小小的修改累积起来就可以根本改善设计质量。这和一般常见的“软件会慢慢腐烂”的观点恰恰相反。
有了重构以后,工作的平衡点开始发生变化。我发现设计不是在一开始完成的,而是在整个开发过程中逐渐浮现出来。在系统构筑过程中,我学会了如何不断改进设计。这个“构筑-设计”的反复互动,可以让一个程序在开发过程中持续保有良好的设计。
本书有什么
本书是一本为专业程序员编写的重构指南。我的目的是告诉你如何以一种可控且高效的方式进行重构。你将学会如何有条不紊地改进程序结构,而且不会引入错误,这就是正确的重构方式。
按照传统,图书应该以概念介绍开头。尽管我也同意这个原则,但是我发现以概括性的讨论或定义来介绍重构,实在不是一件容易的事。因此,我决定用一个实例作为开路先锋。第1章展示了一个小程序,其中有些常见的设计缺陷,我把它重构得更容易理解和修改。其间你可以看到重构的过程,以及几个很有用的重构手法。如果你想知道重构到底是怎么回事,这一章不可不读。
第2章讨论重构的一般性原则、定义,以及进行重构的原因,我也大致介绍了重构面临的一些挑战。第3章由Kent Beck介绍如何嗅出代码中的“坏味道”,以及如何运用重构清除这些“坏味道”。测试在重构中扮演着非常重要的角色,第4章介绍如何在代码中构筑测试。
从第5章往后的篇幅就是本书的核心部分——重构名录。尽管不能说是一份巨细靡遗的列表,却足以覆盖大多数开发者可能用到的关键重构手法。这份重构名录的源头是20世纪90年代后期我开始学习重构时的笔记,直到今天我仍然不时查阅这些笔记,作为对我不甚可靠的记忆力的补充。每当我想做点什么——例如拆分阶段(154)——的时候,这份列表就会提醒我如何一步一步安全前进。我希望这是值得你日后一再回顾的部分。
JavaScript代码范例
与软件开发中的大多数技术性领域一样,代码范例对于概念的阐释至关重要。不过,即使在不同的编程语言中,重构手法看上去也是大同小异的。虽然会有一些值得留心的语言特性,但重构手法的核心要素都是一样的。
我选择了用JavaScript来展现本书中的重构手法,因为我感到大多数读者都能看懂这种语言。不过,即便你眼下正在使用的是别的编程语言,采用这些重构手法也应该不困难。我尽量不使用JavaScript任何复杂的特性,这样即便你对这门编程语言只有粗浅的了解,应该也能跟上重构的过程。另外,使用JavaScript展示重构手法,并不代表我推荐这门编程语言。
使用JavaScript展示代码范例,也不意味着本书介绍的技巧只适用于JavaScript。本书的第1版采用了Java,但很多从未写过任何Java代码的程序员也同样认为这些技巧很有用。我曾经尝试过用十多种不同的编程语言来呈现这些范例,以此展示重构手法的通用性,不过这对普通读者而言只会带来困惑。本书是为所有编程语言背景的程序员所作,除了阅读“范例”小节时需要一些基本的JavaScript知识,本书的其余部分都不特定于任何具体的编程语言。我希望读者能汲取本书的内容,并将其应用于自己日常使用的编程语言。具体而言,我希望读者能先理解本书中的JavaScript范例代码,然后再将其适配到自己习惯的编程语言。
因此,除了在特殊情况下,当我谈到“类”“模块”“函数”等词汇时,我都按照它们在程序设计领域的一般含义来使用这些词,而不是以其在JavaScript语言模型中的特殊含义来使用。
我只把JavaScript用作一种示例语言,因此我也会尽量避免使用其他程序员可能不太熟悉的编程风格。这不是一本“用JavaScript进行重构”的书,而是一本关于重构的通用书籍,只是采用了JavaScript作为示例。有很多JavaScript特有的重构手法很有意思(如将回调重构成promise或async/await),但这些不是本书要讨论的内容。
谁该阅读本书
本书的目标读者是专业程序员,也就是那些以编写软件为生的人。书中的范例和讨论,涉及大量需要详细阅读和理解的代码。这些例子都用JavaScript写成,不过这些重构手法应该适用于大部分编程语言。为了理解书中的内容,读者需要有一定的编程经验,但需要的知识并不多。
本书的首要目标读者群是想要学习重构的软件开发者,同时对于已经理解重构的人也有价值——本书可以作为一本教学辅助书。在本书中,我用了大量篇幅详细解释各个重构手法的过程和原理,因此有经验的开发人员可以用本书来指导同事。
尽管本书的关注对象是代码,但重构对于系统设计也有巨大影响。资深设计师和架构师也很有必要了解重构原理,并在自己的项目中运用重构技术。最好是由有威望的、经验丰富的开发人员来引入重构技术,因为这样的人最能够透彻理解重构背后的原理,并根据情况加以调整,使之适用于特定工作领域。如果你使用的不是JavaScript而是其他编程语言,这一点尤其重要,因为你必须把我给出的范例用其他编程语言改写。
下面我要告诉你,如何能够在不通读全书的情况下充分用好它。
- 如果你想知道重构是什么 ,请阅读第1章,其中的示例会让你弄清楚重构的过程。
- 如果你想知道为什么应该重构 ,请阅读前两章,它们会告诉你重构是什么以及为什么应该重构。
- 如果你想知道该在什么地方重构 ,请阅读第3章,它会告诉你一些代码特征,这些特征指出“这里需要重构”。
- 如果你想着手进行重构 ,请完整阅读前四章,然后选择性地阅读重构名录。一开始只需概略浏览列表,看看其中有些什么,不必理解所有细节。一旦真正需要实施某个重构手法,再详细阅读它,从中获取帮助。列表部分是供查阅的参考性内容,你不必一次就把它全部读完。
给形形色色的重构手法命名是编写本书的重要部分。合适的词汇能帮助我们彼此沟通。当一名开发者向另一名开发者提出建议,将一段代码提取成为一个函数,或者将计算逻辑拆分成几个阶段,双方都能理解提炼函数(106)和拆分阶段(154)是什么意思。这份词汇表也能帮助开发者选择自动化的重构手法。
站在前人的肩膀上
就在本书一开始的此时此刻,我必须说:这本书让我欠了一大笔人情债,欠那些在20世纪90年代做了大量研究工作并开创重构领域的人一大笔债。学习他们的经验启发了我撰写本书第1版,尽管已经过去了很多年,我仍然必须感谢他们打下的基础。这本书原本应该由他们之中的某个人来写,但最后却让我这个有时间、有精力的人捡了便宜。
重构技术的两位最早倡导者是 Ward Cunningham 和Kent Beck。他们很早就把重构作为软件开发过程的一块基石,并且在自己的开发过程中运用它。尤其需要说明的是,正因为和Kent合作,我才真正看到了重构的重要性,并直接受到激励写了这本书。
Ralph Johnson在UIUC(伊利诺伊大学厄巴纳-香槟分校)领导了一个小组,这个小组因其在对象技术方面的实用贡献而声名远扬。Ralph很早就是重构的拥护者,他的一些学生也在重构领域的发展前期做出重要研究。Bill Opdyke的博士论文是重构研究的第一份详细的书面成果。John Brant和Don Roberts则早已不满足于写文章了,他们创造了第一个自动化的重构工具,这个叫作Refactoring Browser(重构浏览器)的工具可以用于重构Smalltalk程序。
自本书第1版问世以来,很多人推动了重构领域的发展。尤其是,开发工具中的自动化重构功能,让程序员的生活轻松了许多。如今我只要简单地敲几下键盘就可以给一个被大量使用的函数改名,对此我已经习以为常,但在这快捷的操作背后,离不开IDE开发团队的辛勤劳动。
致谢
尽管有这些研究成果可以借鉴,我还是需要很多协助才能写成本书。本书的第1版极大地得益于Kent Beck的经验与鼓励。起初向我介绍重构的是他,鼓励我开始书面记录重构手法的是他,帮助我把重构手法组织成型的也是他,提出“代码味道”这个概念的还是他。我常常感觉,他本可以把本书的第1版写得更好——如果当时他不是在忙着撰写极限编程的奠基之作《解析极限编程》的话。
我认识的所有技术图书作者都会提到,技术审稿人提供了巨大的帮助。我们的作品都会有巨大的缺陷,只有同行审稿人能发现这些缺陷。我自己并不常做技术审稿,部分原因是我认为自己并不擅长,所以我对优秀的技术审稿人总是满怀敬意。帮别人审稿所得的报酬微不足道,所以这完全是一项慷慨之举。
正式开始写这本书时,我建了一个邮件列表,其中都是能给我提供反馈的建议者。随着写作的进展,我不断把新的草稿发到这个小组里,请他们给我反馈。我要感谢这些人在邮件列表中提供的反馈:Arlo Belshee、Avdi Grimm、Beth Anders-Beck、Bill Wake、Brian Guthrie、Brian Marick、Chad Wathington、Dave Farley、David Rice、Don Roberts、Fred George、Giles Alexander、Greg Doench、Hugo Corbucci、Ivan Moore、James Shore、Jay Fields、Jessica Kerr、Joshua Kerievsky、Kevlin Henney、Luciano Ramalho、Marcos Brizeno、Michael Feathers、Patrick Kua、Pete Hodgson、Rebecca Parsons和Trisha Gee。
在这群人中,我要特别感谢Beth Anders-Beck、James Shore和Pete Hodgson在JavaScript方面给我的帮助。
有了一个比较完整的初稿之后,我将它发送出去,寻求更多的审阅意见,因为我希望有一些全新的眼光来纵览全书。William Chargin和Michael Hunger提供了极其详尽的审阅意见。我还从Bob Martin和Scott Davis那里得到了很多有用的意见。Bill Wake也对本书初稿做了完整的审阅,并在邮件列表中给出了他的意见。
我在ThoughtWorks的同事一直给我的写作提供想法和反馈。数不胜数的问题、评论和观点推动了本书的思考与写作。作为ThoughtWorks员工最好的一件事,就是这家公司允许我花大量时间来写作。我尤其要感谢Rebecca Parsons(我们的CTO)经常与我交流,给了我很多想法。
在培生出版集团,Greg Doench是负责本书的策划编辑,他解决了无数的问题,最终使本书得以出版;Julie Nahil是责任编辑;Dmitry Kirsanov负责文字编辑工作;Alina Kirsanova负责排版和制作索引。我也很高兴与他们合作。
第 1 章 重构,第一个示例
我该从何说起呢?按照传统做法,一开始介绍某样东西时应该先大致讲讲它的历史、主要原理等。可是每当有人在会场上介绍这些东西,总是诱发我的瞌睡虫。我的思绪开始游荡,我的眼神开始迷离,直到主讲人秀出示例,我才能够提起精神。
示例之所以可以拯救我于太虚之中,因为它让我看见事情在真正进行。谈原理,很容易流于泛泛,又很难说明如何实际应用。给出一个示例,就可以帮助我把事情认识清楚。
因此,我决定从一个示例说起。在此过程中我会谈到很多重构的工作方式,并且让你对重构过程有一点点感觉。然后在下一章中我才能向你展开通常的原理介绍。
但是,面对这个介绍性示例,我遇到了一个大问题。如果我选择一个大型程序,那么对程序自身的描述和对整个重构过程的描述就太复杂了,任何读者都不忍卒读(我试了一下,哪怕稍微复杂一点的例子都会超过 100 页)。如果我选择一个容易理解的小程序,又恐怕看不出重构的价值。
和任何立志要介绍“应用于真实世界的程序中的有用技术”的人一样,我陷入了一个十分典型的两难困境。我只能带你看看如何在一个我选择的小程序中进行重构,然而坦白说,那个程序的规模根本不值得我们这么做。但是,如果我给你看的代码是大系统的一部分,重构技术很快就变得重要起来。所以请你一边观赏这个小例子,一边想象它身处于一个大得多的系统。
1.1 起点
在本书第 1 版中,我使用的示例程序是为影片出租店的顾客打印一张详单。放到今天,很多人可能要问了:“影片出租店是什么?”为了避免过多回答这个问题,我翻新了一下示例,将其包装成一个仍有古典韵味又尚未消亡的现代示例。
设想有一个戏剧演出团,演员们经常要去各种场合表演戏剧。通常客户(customer)会指定几出剧目,而剧团则根据观众(audience)人数及剧目类型来向客户收费。该团目前出演两种戏剧:悲剧(tragedy)和喜剧(comedy)。给客户发出账单时,剧团还会根据到场观众的数量给出“观众量积分”(volume credit)优惠,下次客户再请剧团表演时可以使用积分获得折扣——你可以把它看作一种提升客户忠诚度的方式。
该剧团将剧目的数据存储在一个简单的 JSON 文件中。
plays.json…
{
"hamlet": { "name": "Hamlet", "type": "tragedy" },
"as-like": { "name": "As You Like It", "type": "comedy" },
"othello": { "name": "Othello", "type": "tragedy" }
}
他们开出的账单也存储在一个 JSON 文件里。
invoices.json…
[
{
"customer": "BigCo",
"performances": [
{
"playID": "hamlet",
"audience": 55
},
{
"playID": "as-like",
"audience": 35
},
{
"playID": "othello",
"audience": 40
}
]
}
]
下面这个简单的函数用于打印账单详情。
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
const play = plays[perf.playID];
let thisAmount = 0;
switch (play.type) {
case "tragedy":
thisAmount = 40000;
if (perf.audience > 30) {
thisAmount += 1000 * (perf.audience - 30);
}
break;
case "comedy":
thisAmount = 30000;
if (perf.audience > 20) {
thisAmount += 10000 + 500 * (perf.audience - 20);
}
thisAmount += 300 * perf.audience;
break;
default:
throw new Error(`unknown type: ${play.type}`);
}
// add volume credits
volumeCredits += Math.max(perf.audience - 30, 0);
// add extra credit for every ten comedy attendees
if ("comedy" === play.type) volumeCredits += Math.floor(perf.audience / 5);
// print line for this order
result += ` ${play.name}: ${format(thisAmount/100)} (${perf.audience} seats)\n`;
totalAmount += thisAmount;
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
}
用上面的数据文件(invoices.json 和 plays.json)作为测试输入,运行这段代码,会得到如下输出:
Statement for BigCo
Hamlet: $650.00 (55 seats)
As You Like It: $580.00 (35 seats)
Othello: $500.00 (40 seats)
Amount owed is $1,730.00
You earned 47 credits
1.2 对此起始程序的评价
你觉得这个程序设计得怎么样?我的第一感觉是,代码组织不甚清晰,但这还在可忍受的限度内。这样小的程序,不做任何深入的设计,也不会太难理解。但我前面讲过,这是因为要保证例子足够小的缘故。如果这段代码身处于一个更大规模——也许是几百行——的程序中,把所有代码放到一个函数里就很难理解了。
尽管如此,这个程序还是能正常工作。那么是不是说,对其结构“不甚清晰”的评价只是美学意义上的判断,只是对所谓丑陋代码的反感呢?毕竟编译器也不会在乎代码好不好看。但是,当我们需要修改系统时,就涉及了人,而人在乎这些。差劲的系统是很难修改的,因为很难找到修改点,难以了解做出的修改与现有代码如何协作实现我想要的行为。如果很难找到修改点,我就很有可能犯错,从而引入 bug。
因此,如果我需要修改一个有几百行代码的程序,我会期望它有良好的结构,并且已经被分解成一系列函数和其他程序要素,这能帮我更易于清楚地了解这段代码在做什么。如果程序杂乱无章,先为它整理出结构来,再做需要的修改,通常来说更加简单。
Tip
如果你要给程序添加一个特性,但发现代码因缺乏良好的结构而不易于进行更改,那就先重构那个程序,使其比较容易添加该特性,然后再添加该特性。
在这个例子里,我们的用户希望对系统做几个修改。首先,他们希望以 HTML 格式输出详单。现在请你想一想,这个变化会带来什么影响。对于每处追加字符串到 result 变量的地方我都得为它们添加分支逻辑。这会为函数引入更多复杂度。遇到这种需求时,很多人会选择直接复制整个方法,在其中修改输出 HTML 的部分。复制一遍代码似乎不算太难,但却给未来留下各种隐患:一旦计费逻辑发生变化,我就得同时修改两个地方,以保证它们逻辑相同。如果你编写的是一个永不需要修改的程序,这样剪剪贴贴就还好。但如果程序要保存很长时间,那么重复的逻辑就会造成潜在的威胁。
现在,第二个变化来了:演员们尝试在表演类型上做更多突破,无论是历史剧、田园剧、田园喜剧、田园史剧、历史悲剧还是历史田园悲喜剧,无论一成不变的正统戏,还是千变万幻的新派戏,他们都希望有所尝试,只是还没有决定试哪种以及何时试演。这对戏剧场次的计费方式、积分的计算方式都有影响。作为一个经验丰富的开发者,我可以肯定:不论最终提出什么方案,他们一定会在 6 个月之内再次修改它。毕竟,需求通常不来则已,一来便会接踵而至。
为了应对分类规则和计费规则的变化,程序必须对 statement 函数做出修改。但如果我把 statement 内的代码复制到用以打印 HTML 详单的函数中,就必须确保将来的任何修改在这两个地方保持一致。随着各种规则变得越来越复杂,适当的修改点将越来越难找,不犯错的机会也越来越少。
我再强调一次,是需求的变化使重构变得必要。如果一段代码能正常工作,并且不会再被修改,那么完全可以不去重构它。能改进之当然很好,但若没人需要去理解它,它就不会真正妨碍什么。如果确实有人需要理解它的工作原理,并且觉得理解起来很费劲,那你就需要改进一下代码了。
1.3 重构的第一步
每当我要进行重构的时候,第一个步骤永远相同:我得确保即将修改的代码拥有一组可靠的测试。这些测试必不可少,因为尽管遵循重构手法可以使我避免绝大多数引入 bug 的情形,但我毕竟是人,毕竟有可能犯错。程序越大,我的修改不小心破坏其他代码的可能性就越大——在数字时代,软件的名字就是脆弱。
statement 函数的返回值是一个字符串,我做的就是创建几张新的账单(invoice),假设每张账单收取了几出戏剧的费用,然后使用这几张账单作为输入调用 statement 函数,生成对应的对账单(statement)字符串。我会拿生成的字符串与我已经手工检查过的字符串做比对。我会借助一个测试框架来配置好这些测试,只要在开发环境中输入一行命令就可以把它们运行起来。运行这些测试只需几秒钟,所以你会看到我经常运行它们。
测试过程中很重要的一部分,就是测试程序对于结果的报告方式。它们要么变绿,表示所有新字符串都和参考字符串一样,要么就变红,然后列出失败清单,显示问题字符串的出现行号。这些测试都能够自我检验。使测试能自我检验至关重要,否则就得耗费大把时间来回比对,这会降低开发速度。现代的测试框架都提供了丰富的设施,支持编写和运行能够自我检验的测试。
Tip
重构前,先检查自己是否有一套可靠的测试集。这些测试必须有自我检验能力。
进行重构时,我需要依赖测试。我将测试视为 bug 检测器,它们能保护我不被自己犯的错误所困扰。把我想要达成的目标写两遍——代码里写一遍,测试里再写一遍——我就得犯两遍同样的错误才能骗过检测器。这降低了我犯错的概率,因为我对工作进行了二次确认。尽管编写测试需要花费时间,但却为我节省下可观的调试时间。构筑测试体系对重构来说实在太重要了,因此我将用第 4 章一整章的笔墨来详细讨论它。
1.4 分解 statement 函数
每当看到这样长长的函数,我便下意识地想从整个函数中分离出不同的关注点。第一个引起我注意的就是中间那段 switch 语句。
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
const play = plays[perf.playID];
let thisAmount = 0;
switch (play.type) {
case "tragedy":
thisAmount = 40000;
if (perf.audience > 30) {
thisAmount += 1000 * (perf.audience - 30);
}
break;
case "comedy":
thisAmount = 30000;
if (perf.audience > 20) {
thisAmount += 10000 + 500 * (perf.audience - 20);
}
thisAmount += 300 * perf.audience;
break;
default:
throw new Error(`unknown type: ${play.type}`);
}
// add volume credits
volumeCredits += Math.max(perf.audience - 30, 0);
// add extra credit for every ten comedy attendees
if ("comedy" === play.type) volumeCredits += Math.floor(perf.audience / 5);
// print line for this order
result += ` ${play.name}: ${format(thisAmount/100)} (${perf.audience} seats)\n`;
totalAmount += thisAmount;
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
}
看着这块代码,我就知道它在计算一场戏剧演出的费用。这是我的直觉。不过正如 Ward Cunningham 所说,这种理解只是我脑海中转瞬即逝的灵光。我需要梳理这些灵感,将它们从脑海中搬回到代码里去,以免忘记。这样当我回头看时,代码就能告诉我它在干什么,我不需要重新思考一遍。
要将我的理解转化到代码里,得先将这块代码抽取成一个独立的函数,按它所干的事情给它命名,比如叫 amountFor(performance)。每次想将一块代码抽取成一个函数时,我都会遵循一个标准流程,最大程度减少犯错的可能。我把这个流程记录了下来,并将它命名为提炼函数(106),以便日后可以方便地引用。
首先,我需要检查一下,如果我将这块代码提炼到自己的一个函数里,有哪些变量会离开原本的作用域。在此示例中,是 perf、play 和 thisAmount 这 3 个变量。前两个变量会被提炼后的函数使用,但不会被修改,那么我就可以将它们以参数方式传递进来。我更关心那些会被修改的变量。这里只有唯一一个——thisAmount,因此可以将它从函数中直接返回。我还可以将其初始化放到提炼后的函数里。修改后的代码如下所示。
function statement…
function amountFor(perf, play) {
let thisAmount = 0;
switch (play.type) {
case "tragedy":
thisAmount = 40000;
if (perf.audience > 30) {
thisAmount += 1000 * (perf.audience - 30);
}
break;
case "comedy":
thisAmount = 30000;
if (perf.audience > 20) {
thisAmount += 10000 + 500 * (perf.audience - 20);
}
thisAmount += 300 * perf.audience;
break;
default:
throw new Error(`unknown type: ${play.type}`);
}
return thisAmount;
}
当我在代码块上方使用了斜体(中文对应为楷体)标记的题头“ function xxx ”时,表明该代码块位于题头所在函数、文件或类的作用域内。通常该作用域内还有其他的代码,但由于不是讨论重点,因此把它们隐去不展示。
现在原 statement 函数可以直接调用这个新函数来初始化 thisAmount。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
const play = plays[perf.playID];
let thisAmount = amountFor(perf, play);
// add volume credits
volumeCredits += Math.max(perf.audience - 30, 0);
// add extra credit for every ten comedy attendees
if ("comedy" === play.type) volumeCredits += Math.floor(perf.audience / 5);
// print line for this order
result += ` ${play.name}: ${format(thisAmount/100)} (${perf.audience} seats)\n`;
totalAmount += thisAmount;
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
做完这个改动后,我会马上编译并执行一遍测试,看看有无破坏了其他东西。无论每次重构多么简单,养成重构后即运行测试的习惯非常重要。犯错误是很容易的——至少我知道我是很容易犯错的。做完一次修改就运行测试,这样在我真的犯了错时,只需要考虑一个很小的改动范围,这使得查错与修复问题易如反掌。这就是重构过程的精髓所在:小步修改,每次修改后就运行测试。如果我改动了太多东西,犯错时就可能陷入麻烦的调试,并为此耗费大把时间。小步修改,以及它带来的频繁反馈,正是防止混乱的关键。
Tip
这里我使用的“编译”一词,指的是将 JavaScript 变为可执行代码之前的所有步骤。虽然 JavaScript 可以直接执行,有时可能不需任何步骤,但有时可能需要将代码移动到一个输出目录,或使用 Babel 这样的代码处理器等。
因为是 JavaScript,我可以直接将 amountFor 提炼成为 statement 的一个内嵌函数。这个特性十分有用,因为我就不需要再把外部作用域中的数据传给新提炼的函数。这个示例中可能区别不大,但也是少了一件要操心的事。
Tip
重构技术就是以微小的步伐修改程序。如果你犯下错误,很容易便可发现它。
做完上面的修改,测试是通过的,因此下一步我要把代码提交到本地的版本控制系统。我会使用诸如 git 或 mercurial 这样的版本控制系统,因为它们可以支持本地提交。每次成功的重构后我都会提交代码,如果待会不小心搞砸了,我便能轻松回滚到上一个可工作的状态。把代码推送(push)到远端仓库前,我会把零碎的修改压缩成一个更有意义的提交(commit)。
提炼函数(106)是一个常见的可自动完成的重构。如果我是用 Java 编程,我会本能地使用 IDE 的快捷键来完成这项重构。在我撰写本书时,JavaScript 工具对此重构的支持仍不是很健壮,因此我必须手动重构。这不是很难,当然我还是需要小心处理那些局部作用域的变量。
完成提炼函数(106)手法后,我会看看提炼出来的函数,看是否能进一步提升其表达能力。一般我做的第一件事就是给一些变量改名,使它们更简洁,比如将 thisAmount 重命名为 result。
function statement…
function amountFor(perf, play) {
let result = 0;
switch (play.type) {
case "tragedy":
result = 40000;
if (perf.audience > 30) {
result += 1000 * (perf.audience - 30);
}
break;
case "comedy":
result = 30000;
if (perf.audience > 20) {
result += 10000 + 500 * (perf.audience - 20);
}
result += 300 * perf.audience;
break;
default:
throw new Error(`unknown type: ${play.type}`);
}
return result;
}
这是我个人的编码风格:永远将函数的返回值命名为“result”,这样我一眼就能知道它的作用。然后我再次编译、测试、提交代码。接着,我前往下一个目标——函数参数。
function statement…
function amountFor(aPerformance, play) {
let result = 0;
switch (play.type) {
case "tragedy":
result = 40000;
if (aPerformance.audience > 30) {
result += 1000 * (aPerformance.audience - 30);
}
break;
case "comedy":
result = 30000;
if (aPerformance.audience > 20) {
result += 10000 + 500 * (aPerformance.audience - 20);
}
result += 300 * aPerformance.audience;
break;
default:
throw new Error(`unknown type: ${play.type}`);
}
return result;
}
这是我的另一个编码风格。使用一门动态类型语言(如 JavaScript)时,跟踪变量的类型很有意义。因此,我为参数取名时都默认带上其类型名。一般我会使用不定冠词修饰它,除非命名中另有解释其角色的相关信息。这个习惯是从 Kent Beck 那里学的[Beck SBPP],到现在我还一直觉得很有用。
Tip
傻瓜都能写出计算机可以理解的代码。唯有能写出人类容易理解的代码的,才是优秀的程序员。
这次改名是否值得我大费周章呢?当然值得。好代码应能清楚地表明它在做什么,而变量命名是代码清晰的关键。只要改名能够提升代码的可读性,那就应该毫不犹豫去做。有好的查找替换工具在手,改名通常并不困难;此外,你的测试以及语言本身的静态类型支持,都可以帮你揪出漏改的地方。如今有了自动化的重构工具,即便要给一个被大量调用的函数改名,通常也不在话下。
本来下一个要改名的变量是 play,但我对这个参数另有安排。
移除 play 变量
观察 amountFor 函数时,我会看看它的参数都从哪里来。aPerformance 是从循环变量中来,所以自然每次循环都会改变,但 play 变量是由 performance 变量计算得到的,因此根本没必要将它作为参数传入,我可以在 amountFor 函数中重新计算得到它。当我分解一个长函数时,我喜欢将 play 这样的变量移除掉,因为它们创建了很多具有局部作用域的临时变量,这会使提炼函数更加复杂。这里我要使用的重构手法是以查询取代临时变量(178)。
我先从赋值表达式的右边部分提炼出一个函数来。
function statement…
function playFor(aPerformance) {
return plays[aPerformance.playID];
}
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
const play = playFor(perf);
let thisAmount = amountFor(perf, play);
// add volume credits
volumeCredits += Math.max(perf.audience - 30, 0);
// add extra credit for every ten comedy attendees
if ("comedy" === play.type) volumeCredits += Math.floor(perf.audience / 5);
// print line for this order
result += ` ${play.name}: ${format(thisAmount/100)} (${perf.audience} seats)\n`;
totalAmount += thisAmount;
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
编译、测试、提交,然后使用内联变量(123)手法内联 play 变量。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
const play = playFor(perf);
let thisAmount = amountFor(perf, playFor(perf));
// add volume credits
volumeCredits += Math.max(perf.audience - 30, 0);
// add extra credit for every ten comedy attendees
if ("comedy" === playFor(perf).type) volumeCredits += Math.floor(perf.audience / 5);
// print line for this order
result += ` ${playFor(perf).name}: ${format(thisAmount/100)} (${perf.audience} seats)\n`;
totalAmount += thisAmount;
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
编译、测试、提交。完成变量内联后,我可以对 amountFor 函数应用改变函数声明(124),移除 play 参数。我会分两步走。首先在 amountFor 函数内部使用新提炼的函数。
function statement…
function amountFor(aPerformance, play) {
let result = 0;
switch (playFor(aPerformance).type) {
case "tragedy":
result = 40000;
if (aPerformance.audience > 30) {
result += 1000 * (aPerformance.audience - 30);
}
break;
case "comedy":
result = 30000;
if (aPerformance.audience > 20) {
result += 10000 + 500 * (aPerformance.audience - 20);
}
result += 300 * aPerformance.audience;
break;
default:
throw new Error(`unknown type: ${playFor(aPerformance).type}`);
}
return result;
}
编译、测试、提交,最后将参数删除。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
let thisAmount = amountFor(perf , playFor(perf) );
// add volume credits
volumeCredits += Math.max(perf.audience - 30, 0);
// add extra credit for every ten comedy attendees
if ("comedy" === playFor(perf).type) volumeCredits += Math.floor(perf.audience / 5);
// print line for this order
result += ` ${playFor(perf).name}: ${format(thisAmount/100)} (${perf.audience} seats)\n`;
totalAmount += thisAmount;
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
function statement…
function amountFor(aPerformance , play ) {
let result = 0;
switch (playFor(aPerformance).type) {
case "tragedy":
result = 40000;
if (aPerformance.audience > 30) {
result += 1000 * (aPerformance.audience - 30);
}
break;
case "comedy":
result = 30000;
if (aPerformance.audience > 20) {
result += 10000 + 500 * (aPerformance.audience - 20);
}
result += 300 * aPerformance.audience;
break;
default:
throw new Error(`unknown type: ${playFor(aPerformance).type}`);
}
return result;
}
然后再一次编译、测试、提交。
这次重构可能在一些程序员心中敲响警钟:重构前,查找 play 变量的代码在每次循环中只执行了 1 次,而重构后却执行了 3 次。我会在后面探讨重构与性能之间的关系,但现在,我认为这次改动还不太可能对性能有严重影响,即便真的有所影响,后续再对一段结构良好的代码进行性能调优,也容易得多。
移除局部变量的好处就是做提炼时会简单得多,因为需要操心的局部作用域变少了。实际上,在做任何提炼前,我一般都会先移除局部变量。
处理完 amountFor 的参数后,我回过头来看一下它的调用点。它被赋值给一个临时变量,之后就不再被修改,因此我又采用内联变量(123)手法内联它。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
// add volume credits
volumeCredits += Math.max(perf.audience - 30, 0);
// add extra credit for every ten comedy attendees
if ("comedy" === playFor(perf).type) volumeCredits += Math.floor(perf.audience / 5);
// print line for this order
result += ` ${playFor(perf).name}: ${format(amountFor(perf)/100)} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
提炼计算观众量积分的逻辑
现在 statement 函数的内部实现是这样的。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
// add volume credits
volumeCredits += Math.max(perf.audience - 30, 0);
// add extra credit for every ten comedy attendees
if ("comedy" === playFor(perf).type) volumeCredits += Math.floor(perf.audience / 5);
// print line for this order
result += ` ${playFor(perf).name}: ${format(amountFor(perf)/100)} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
这会儿我们就看到了移除 play 变量的好处,移除了一个局部作用域的变量,提炼观众量积分的计算逻辑又更简单一些。
我仍需要处理其他两个局部变量。perf 同样可以轻易作为参数传入,但 volumeCredits 变量则有些棘手。它是一个累加变量,循环的每次迭代都会更新它的值。因此最简单的方式是,将整块逻辑提炼到新函数中,然后在新函数中直接返回 volumeCredits。
function statement…
function volumeCreditsFor(perf) {
let volumeCredits = 0;
volumeCredits += Math.max(perf.audience - 30, 0);
if ("comedy" === playFor(perf).type)
volumeCredits += Math.floor(perf.audience / 5);
return volumeCredits;
}
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
volumeCredits += volumeCreditsFor(perf);
// print line for this order
result += ` ${playFor(perf).name}: ${format(amountFor(perf)/100)} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
我还顺便删除了多余(并且会引起误解)的注释。
编译、测试、提交,然后对新函数里的变量改名。
function statement…
function volumeCreditsFor(aPerformance) {
let result = 0;
result += Math.max(aPerformance.audience - 30, 0);
if ("comedy" === playFor(aPerformance).type)
result += Math.floor(aPerformance.audience / 5);
return result;
}
这里我只展示了一步到位的改名结果,不过实际操作时,我还是一次只将一个变量改名,并在每次改名后执行编译、测试、提交。
移除 format 变量
我们再看一下 statement 这个主函数。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
const format = new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format;
for (let perf of invoice.performances) {
volumeCredits += volumeCreditsFor(perf);
// print line for this order
result += ` ${playFor(perf).name}: ${format(amountFor(perf)/100)} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
正如我上面所指出的,临时变量往往会带来麻烦。它们只在对其进行处理的代码块中有用,因此临时变量实质上是鼓励你写长而复杂的函数。因此,下一步我要替换掉一些临时变量,而最简单的莫过于从 format 变量入手。这是典型的“将函数赋值给临时变量”的场景,我更愿意将其替换为一个明确声明的函数。
function statement…
function format(aNumber) {
return new Intl.NumberFormat("en-US", {
style: "currency",
currency: "USD",
minimumFractionDigits: 2,
}).format(aNumber);
}
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
volumeCredits += volumeCreditsFor(perf);
// print line for this order
result += ` ${playFor(perf).name}: ${format(amountFor(perf)/100)} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
result += `Amount owed is ${format(totalAmount/100)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
Tip
尽管将函数变量改变成函数声明也是一种重构手法,但我既未为此手法命名,也未将它纳入重构名录。还有很多的重构手法我都觉得没那么重要。我觉得上面这个函数改名的手法既十分简单又不太常用,不值得在重构名录中占有一席之地。
我对提炼得到的函数名称不很满意——format 未能清晰地描述其作用。formatAsUSD 很表意,但又太长,特别它仅是小范围地被用在一个字符串模板中。我认为这里真正需要强调的是,它格式化的是一个货币数字,因此我选取了一个能体现此意图的命名,并应用了改变函数声明(124)手法。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
volumeCredits += volumeCreditsFor(perf);
// print line for this order
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
result += `Amount owed is ${usd(totalAmount)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
function statement…
function usd(aNumber) {
return new Intl.NumberFormat("en-US", {
style: "currency",
currency: "USD",
minimumFractionDigits: 2,
}).format(aNumber / 100);
}
好的命名十分重要,但往往并非唾手可得。只有恰如其分地命名,才能彰显出将大函数分解成小函数的价值。有了好的名称,我就不必通过阅读函数体来了解其行为。但要一次把名取好并不容易,因此我会使用当下能想到最好的那个。如果稍后想到更好的,我就会毫不犹豫地换掉它。通常你需要花几秒钟通读更多代码,才能发现最好的名称是什么。
重命名的同时,我还将重复的除以 100 的行为也搬移到函数里。将钱以美分为单位作为正整数存储是一种常见的做法,可以避免使用浮点数来存储货币的小数部分,同时又不影响用数学运算符操作它。不过,对于这样一个以美分为单位的整数,我又需要以美元为单位进行展示,因此让格式化函数来处理整除的事宜再好不过。
移除观众量积分总和
我的下一个重构目标是 volumeCredits。处理这个变量更加微妙,因为它是在循环的迭代过程中累加得到的。第一步,就是应用拆分循环(227)将 volumeCredits 的累加过程分离出来。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let volumeCredits = 0;
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
// print line for this order
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
for (let perf of invoice.performances) {
volumeCredits += volumeCreditsFor(perf);
}
result += `Amount owed is ${usd(totalAmount)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
完成这一步,我就可以使用移动语句(223)手法将变量声明挪动到紧邻循环的位置。
top level…
function statement (invoice, plays) {
let totalAmount = 0;
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
// print line for this order
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
let volumeCredits = 0;
for (let perf of invoice.performances) {
volumeCredits += volumeCreditsFor(perf);
}
result += `Amount owed is ${usd(totalAmount)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
把与更新 volumeCredits 变量相关的代码都集中到一起,有利于以查询取代临时变量(178)手法的施展。第一步同样是先对变量的计算过程应用提炼函数(106)手法。
function statement…
function totalVolumeCredits() {
let volumeCredits = 0;
for (let perf of invoice.performances) {
volumeCredits += volumeCreditsFor(perf);
}
return volumeCredits;
}
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
// print line for this order
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
let volumeCredits = totalVolumeCredits();
result += `Amount owed is ${usd(totalAmount)}\n`;
result += `You earned ${volumeCredits} credits\n`;
return result;
完成函数提炼后,我再应用内联变量(123)手法内联 totalVolumeCredits 函数。
顶层作用域…
function statement (invoice, plays) {
let totalAmount = 0;
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
// print line for this order
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
totalAmount += amountFor(perf);
}
result += `Amount owed is ${usd(totalAmount)}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
重构至此,让我先暂停一下,谈谈刚刚完成的修改。首先,我知道有些读者会再次对此修改可能带来的性能问题感到担忧,我知道很多人本能地警惕重复的循环。但大多数时候,重复一次这样的循环对性能的影响都可忽略不计。如果你在重构前后进行计时,很可能甚至都注意不到运行速度的变化——通常也确实没什么变化。许多程序员对代码实际的运行路径都所知不足,甚至经验丰富的程序员有时也未能避免。在聪明的编译器、现代的缓存技术面前,我们很多直觉都是不准确的。软件的性能通常只与代码的一小部分相关,改变其他的部分往往对总体性能贡献甚微。
当然,“大多数时候”不等同于“所有时候”。有时,一些重构手法也会显著地影响性能。但即便如此,我通常也不去管它,继续重构,因为有了一份结构良好的代码,回头调优其性能也容易得多。如果我在重构时引入了明显的性能损耗,我后面会花时间进行性能调优。进行调优时,可能会回退我早先做的一些重构——但更多时候,因为重构我可以使用更高效的调优方案。最后我得到的是既整洁又高效的代码。
因此对于重构过程的性能问题,我总体的建议是:大多数情况下可以忽略它。如果重构引入了性能损耗,先完成重构,再做性能优化。
其次,我希望你能注意到:我们移除 volumeCredits 的过程是多么小步。整个过程一共有 4 步,每一步都伴随着一次编译、测试以及向本地代码库的提交:
- 使用拆分循环(227)分离出累加过程;
- 使用移动语句(223)将累加变量的声明与累加过程集中到一起;
- 使用提炼函数(106)提炼出计算总数的函数;
- 使用内联变量(123)完全移除中间变量。
我得坦白,我并非总是如此小步——但在事情变复杂时,我的第一反应就是采用更小的步子。怎样算变复杂呢,就是当重构过程有测试失败而我又无法马上看清问题所在并立即修复时,我就会回滚到最后一次可工作的提交,然后以更小的步子重做。这得益于我如此频繁地提交。特别是与复杂代码打交道时,细小的步子是快速前进的关键。
接着我要重复同样的步骤来移除 totalAmount。我以拆解循环开始(编译、测试、提交),然后下移累加变量的声明语句(编译、测试、提交),最后再提炼函数。这里令我有点头疼的是:最好的函数名应该是 totalAmount,但它已经被变量名占用,我无法起两个同样的名字。因此,我在提炼函数时先给它随便取了一个名字(然后编译、测试、提交)。
function statement…
function appleSauce() {
let totalAmount = 0;
for (let perf of invoice.performances) {
totalAmount += amountFor(perf);
}
return totalAmount;
}
顶层作用域…
function statement (invoice, plays) {
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
}
let totalAmount = appleSauce();
result += `Amount owed is ${usd(totalAmount)}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
接着我将变量内联(编译、测试、提交),然后将函数名改回 totalAmount(编译、测试、提交)。
顶层作用域…
function statement (invoice, plays) {
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
}
result += `Amount owed is ${usd(totalAmount())}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
function statement…
function totalAmount() {
let totalAmount = 0;
for (let perf of invoice.performances) {
totalAmount += amountFor(perf);
}
return totalAmount;
}
趁着给新提炼的函数改名的机会,我顺手一并修改了函数内部的变量名,以便保持我一贯的编码风格。
function statement…
function totalAmount() {
let result = 0;
for (let perf of invoice.performances) {
result += amountFor(perf);
}
return result;
}
function totalVolumeCredits() {
let result = 0;
for (let perf of invoice.performances) {
result += volumeCreditsFor(perf);
}
return result;
}
1.5 进展:大量嵌套函数
重构至此,是时候停下来欣赏一下代码的全貌了。
function statement (invoice, plays) {
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
}
result += `Amount owed is ${usd(totalAmount())}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
function totalAmount() {
let result = 0;
for (let perf of invoice.performances) {
result += amountFor(perf);
}
return result;
}
function totalVolumeCredits() {
let result = 0;
for (let perf of invoice.performances) {
result += volumeCreditsFor(perf);
}
return result;
}
function usd(aNumber) {
return new Intl.NumberFormat("en-US",
{ style: "currency", currency: "USD",
minimumFractionDigits: 2 }).format(aNumber/100);
}
function volumeCreditsFor(aPerformance) {
let result = 0;
result += Math.max(aPerformance.audience - 30, 0);
if ("comedy" === playFor(aPerformance).type) result += Math.floor(aPerformance.audience / 5);
return result;
}
function playFor(aPerformance) {
return plays[aPerformance.playID];
}
function amountFor(aPerformance) {
let result = 0;
switch (playFor(aPerformance).type) {
case "tragedy":
result = 40000;
if (aPerformance.audience > 30) {
result += 1000 * (aPerformance.audience - 30);
}
break;
case "comedy":
result = 30000;
if (aPerformance.audience > 20) {
result += 10000 + 500 * (aPerformance.audience - 20);
}
result += 300 * aPerformance.audience;
break;
default:
throw new Error(`unknown type: ${playFor(aPerformance).type}`);
}
return result;
}
}
现在代码结构已经好多了。顶层的 statement 函数现在只剩 7 行代码,而且它处理的都是与打印详单相关的逻辑。与计算相关的逻辑从主函数中被移走,改由一组函数来支持。每个单独的计算过程和详单的整体结构,都因此变得更易理解了。
1.6 拆分计算阶段与格式化阶段
到目前为止,我的重构主要是为原函数添加足够的结构,以便我能更好地理解它,看清它的逻辑结构。这也是重构早期的一般步骤。把复杂的代码块分解为更小的单元,与好的命名一样都很重要。现在,我可以更多关注我要修改的功能部分了,也就是为这张详单提供一个 HTML 版本。不管怎么说,现在改起来更加简单了。因为计算代码已经被分离出来,我只需要为顶部的 7 行代码实现一个 HTML 的版本。问题是,这些分解出来的函数嵌套在打印文本详单的函数中。无论嵌套函数组织得多么良好,我总不想将它们全复制粘贴到另一个新函数中。我希望同样的计算函数可以被文本版详单和 HTML 版详单共用。
要实现复用有许多种方法,而我最喜欢的技术是拆分阶段(154)。这里我的目标是将逻辑分成两部分:一部分计算详单所需的数据,另一部分将数据渲染成文本或 HTML。第一阶段会创建一个中转数据结构,再把它传递给第二阶段。
要开始拆分阶段(154),我会先对组成第二阶段的代码应用提炼函数(106)。在这个例子中,这部分代码就是打印详单的代码,其实也就是 statement 函数的全部内容。我要把它们与所有嵌套的函数一起抽取到一个新的顶层函数中,并将其命名为 renderPlainText。
function statement (invoice, plays) {
return renderPlainText(invoice, plays);
}
function renderPlainText(invoice, plays) {
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
}
result += `Amount owed is ${usd(totalAmount())}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
function totalAmount() {...}
function totalVolumeCredits() {...}
function usd(aNumber) {...}
function volumeCreditsFor(aPerformance) {...}
function playFor(aPerformance) {...}
function amountFor(aPerformance) {...}
编译、测试、提交,接着创建一个对象,作为在两个阶段间传递的中转数据结构,然后将它作为第一个参数传递给 renderPlainText(然后编译、测试、提交)。
function statement (invoice, plays) {
const statementData = {};
return renderPlainText(statementData, invoice, plays);
}
function renderPlainText(data, invoice, plays) {
let result = `Statement for ${invoice.customer}\n`;
for (let perf of invoice.performances) {
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
}
result += `Amount owed is ${usd(totalAmount())}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
function totalAmount() {...}
function totalVolumeCredits() {...}
function usd(aNumber) {...}
function volumeCreditsFor(aPerformance) {...}
function playFor(aPerformance) {...}
function amountFor(aPerformance) {...}
现在我要检查一下 renderPlainText 用到的其他参数。我希望将它们挪到这个中转数据结构里,这样所有计算代码都可以被挪到 statement 函数中,让 renderPlainText 只操作通过 data 参数传进来的数据。
第一步是将顾客(customer)字段添加到中转对象里(编译、测试、提交)。
function statement (invoice, plays) {
const statementData = {};
statementData.customer = invoice.customer;
return renderPlainText(statementData, invoice, plays);
}
function renderPlainText(data, invoice, plays) {
let result = `Statement for ${data.customer}\n`;
for (let perf of invoice.performances) {
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
}
result += `Amount owed is ${usd(totalAmount())}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
我将 performances 字段也搬移过去,这样我就可以移除掉 renderPlainText 的 invoice 参数(编译、测试、提交)。
顶层作用域…
function statement (invoice, plays) {
const statementData = {};
statementData.customer = invoice.customer;
statementData.performances = invoice.performances;
return renderPlainText(statementData, plays);
}
function renderPlainText(data, plays) {
let result = `Statement for ${data.customer}\n`;
for (let perf of data.performances) {
result += ` ${playFor(perf).name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
}
result += `Amount owed is ${usd(totalAmount())}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
function renderPlainText…
function totalAmount() {
let result = 0;
for (let perf of data.performances) {
result += amountFor(perf);
}
return result;
}
function totalVolumeCredits() {
let result = 0;
for (let perf of data.performances) {
result += volumeCreditsFor(perf);
}
return result;
}
现在,我希望“剧目名称”信息也从中转数据中获得。为此,需要使用 play 中的数据填充 aPerformance 对象(记得编译、测试、提交)。
function statement (invoice, plays) {
const statementData = {};
statementData.customer = invoice.customer;
statementData.performances = invoice.performances.map(enrichPerformance);
return renderPlainText(statementData, plays);
function enrichPerformance(aPerformance) {
const result = Object.assign({}, aPerformance);
return result;
}
}
现在我只是简单地返回了一个 aPerformance 对象的副本,但马上我就会往这条记录中添加新的数据。返回副本的原因是,我不想修改传给函数的参数,我总是尽量保持数据不可变(immutable)——可变的状态会很快变成烫手的山芋。
Tip
在不熟悉 JavaScript 的人看来,result = Object.assign({}, aPerformance)的写法可能十分奇怪。它返回的是一个浅副本。虽然我更希望有个函数来完成此功能,但这个用法已经约定俗成,如果我自己写个函数,在 JavaScript 程序员看来反而会格格不入。 :::
现在我们已经有了安放 play 字段的地方,可以把数据放进去。我需要对 playFor 和 statement 函数应用搬移函数(198)(然后编译、测试、提交)。
function statement…
function enrichPerformance(aPerformance) {
const result = Object.assign({}, aPerformance);
result.play = playFor(result);
return result;
}
function playFor(aPerformance) {
return plays[aPerformance.playID];
}
然后替换 renderPlainText 中对 playFor 的所有引用点,让它们使用新数据(编译、测试、提交)。
function renderPlainText…
let result = `Statement for ${data.customer}\n`;
for (let perf of data.performances) {
result += ` ${perf.play.name}: ${usd(amountFor(perf))} (${perf.audience} seats)\n`;
}
result += `Amount owed is ${usd(totalAmount())}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
function volumeCreditsFor(aPerformance) {
let result = 0;
result += Math.max(aPerformance.audience - 30, 0);
if ("comedy" === aPerformance.play.type) result += Math.floor(aPerformance.audience / 5);
return result;
}
function amountFor(aPerformance){
let result = 0;
switch (aPerformance.play.type) {
case "tragedy":
result = 40000;
if (aPerformance.audience > 30) {
result += 1000 * (aPerformance.audience - 30);
}
break;
case "comedy":
result = 30000;
if (aPerformance.audience > 20) {
result += 10000 + 500 * (aPerformance.audience - 20);
}
result += 300 * aPerformance.audience;
break;
default:
throw new Error(`unknown type: ${aPerformance.play.type}`);
}
return result;
}
接着我使用类似的手法搬移 amountFor 函数(编译、测试、提交)。
function statement…
function enrichPerformance(aPerformance) {
const result = Object.assign({}, aPerformance);
result.play = playFor(result);
result.amount = amountFor(result);
return result;
}
function amountFor(aPerformance) {...}
function renderPlainText…
let result = `Statement for ${data.customer}\n`;
for (let perf of data.performances) {
result += ` ${perf.play.name}: ${usd(perf.amount)} (${
perf.audience
} seats)\n`;
}
result += `Amount owed is ${usd(totalAmount())}\n`;
result += `You earned ${totalVolumeCredits()} credits\n`;
return result;
function totalAmount() {
let result = 0;
for (let perf of data.performances) {
result += perf.amount;
}
return result;
}
接下来搬移观众量积分的计算(编译、测试、提交)。
function statement…
function enrichPerformance(aPerformance) {
const result = Object.assign({}, aPerformance);
result.play = playFor(result);
result.amount = amountFor(result);
result.volumeCredits = volumeCreditsFor(result);
return result;
}
function volumeCreditsFor(aPerformance) {...}
function renderPlainText…
function totalVolumeCredits() {
let result = 0;
for (let perf of data.performances) {
result += perf.volumeCredits;
}
return result;
}
最后,我将两个计算总数的函数搬移到 statement 函数中。
function statement…
const statementData = {};
statementData.customer = invoice.customer;
statementData.performances = invoice.performances.map(enrichPerformance);
statementData.totalAmount = totalAmount(statementData);
statementData.totalVolumeCredits = totalVolumeCredits(statementData);
return renderPlainText(statementData, plays);
function totalAmount(data) {...}
function totalVolumeCredits(data) {...}
function renderPlainText…
let result = `Statement for ${data.customer}\n`;
for (let perf of data.performances) {
result += ` ${perf.play.name}: ${usd(perf.amount)} (${
perf.audience
} seats)\n`;
}
result += `Amount owed is ${usd(data.totalAmount)}\n`;
result += `You earned ${data.totalVolumeCredits} credits\n`;
return result;
尽管我可以修改函数体,让这些计算总数的函数直接使用 statementData 变量(反正它在作用域内),但我更喜欢显式地传入函数参数。
等到搬移完成,编译、测试、提交也做完,我便忍不住以管道取代循环(231)对几个地方进行重构。
function renderPlainText…
function totalAmount(data) {
return data.performances
.reduce((total, p) => total + p.amount, 0);
}
function totalVolumeCredits(data) {
return data.performances
.reduce((total, p) => total + p.volumeCredits, 0);
}
现在我可以把第一阶段的代码提炼到一个独立的函数里了(编译、测试、提交)。
顶层作用域…
function statement (invoice, plays) {
return renderPlainText(createStatementData(invoice, plays));
}
function createStatementData(invoice, plays) {
const statementData = {};
statementData.customer = invoice.customer;
statementData.performances = invoice.performances.map(enrichPerformance);
statementData.totalAmount = totalAmount(statementData);
statementData.totalVolumeCredits = totalVolumeCredits(statementData);
return statementData;
由于两个阶段已经彻底分离,我干脆把它搬移到另一个文件里去(并且修改了返回结果的变量名,与我一贯的编码风格保持一致)。
statement.js…
import createStatementData from "./createStatementData.js";
createStatementData.js…
export default function createStatementData(invoice, plays) {
const result = {};
result.customer = invoice.customer;
result.performances = invoice.performances.map(enrichPerformance);
result.totalAmount = totalAmount(result);
result.totalVolumeCredits = totalVolumeCredits(result);
return result;
function enrichPerformance(aPerformance) {...}
function playFor(aPerformance) {...}
function amountFor(aPerformance) {...}
function volumeCreditsFor(aPerformance) {...}
function totalAmount(data) {...}
function totalVolumeCredits(data) {...}
最后再做一次编译、测试、提交,接下来,要编写一个 HTML 版本的对账单就很简单了。
statement.js…
function htmlStatement (invoice, plays) {
return renderHtml(createStatementData(invoice, plays));
}
function renderHtml (data) {
let result = `<h1>Statement for ${data.customer}</h1>\n`;
result += "<table>\n";
result += "<tr><th>play</th><th>seats</th><th>cost</th></tr>";
for (let perf of data.performances) {
result += ` <tr><td>${perf.play.name}</td><td>${perf.audience}</td>`;
result += `<td>${usd(perf.amount)}</td></tr>\n`;
}
result += "</table>\n";
result += `<p>Amount owed is <em>${usd(data.totalAmount)}</em></p>\n`;
result += `<p>You earned <em>${data.totalVolumeCredits}</em> credits</p>\n`;
return result;
}
function usd(aNumber) {...}
(我把 usd 函数也搬移到顶层作用域中,以便 renderHtml 也能访问它。)
1.7 进展:分离到两个文件(和两个阶段)
现在正是停下来重新回顾一下代码的好时机,思考一下重构的进展。现在我有了两个代码文件。
statement.js
import createStatementData from "./createStatementData.js";
function statement(invoice, plays) {
return renderPlainText(createStatementData(invoice, plays));
}
function renderPlainText(data, plays) {
let result = `Statement for ${data.customer}\n`;
for (let perf of data.performances) {
result += ` ${perf.play.name}: ${usd(perf.amount)} (${
perf.audience
} seats)\n`;
}
result += `Amount owed is ${usd(data.totalAmount)}\n`;
result += `You earned ${data.totalVolumeCredits} credits\n`;
return result;
}
function htmlStatement(invoice, plays) {
return renderHtml(createStatementData(invoice, plays));
}
function renderHtml(data) {
let result = `<h1>Statement for ${data.customer}</h1>\n`;
result += "<table>\n";
result +=
"<tr><th>play</th><th>seats</th><th>cost</th></tr>";
for (let perf of data.performances) {
result += ` <tr><td>${perf.play.name}</td><td>${perf.audience}</td>`;
result += `<td>${usd(perf.amount)}</td></tr>\n`;
}
result += "</table>\n";
result += `<p>Amount owed is <em>${usd(
data.totalAmount
)}</em></p>\n`;
result += `<p>You earned <em>${data.totalVolumeCredits}</em> credits</p>\n`;
return result;
}
function usd(aNumber) {
return new Intl.NumberFormat("en-US", {
style: "currency",
currency: "USD",
minimumFractionDigits: 2,
}).format(aNumber / 100);
}
createStatementData.js
export default function createStatementData(invoice, plays) {
const result = {};
result.customer = invoice.customer;
result.performances = invoice.performances.map(enrichPerformance);
result.totalAmount = totalAmount(result);
result.totalVolumeCredits = totalVolumeCredits(result);
return result;
function enrichPerformance(aPerformance) {
const result = Object.assign({}, aPerformance);
result.play = playFor(result);
result.amount = amountFor(result);
result.volumeCredits = volumeCreditsFor(result);
return result;
}
function playFor(aPerformance) {
return plays[aPerformance.playID]
}
function amountFor(aPerformance) {
let result = 0;
switch (aPerformance.play.type) {
case "tragedy":
result = 40000;
if (aPerformance.audience > 30) {
result += 1000 * (aPerformance.audience - 30);
}
break;
case "comedy":
result = 30000;
if (aPerformance.audience > 20) {
result += 10000 + 500 * (aPerformance.audience - 20);
}
result += 300 * aPerformance.audience;
break;
default:
throw new Error(`unknown type: ${aPerformance.play.type}`);
}
return result;
}
function volumeCreditsFor(aPerformance) {
let result = 0;
result += Math.max(aPerformance.audience - 30, 0);
if ("comedy" === aPerformance.play.type) result += Math.floor(aPerformance.audience / 5);
return result;
}
function totalAmount(data) {
return data.performances
.reduce((total, p) => total + p.amount, 0);
}
function totalVolumeCredits(data) {
return data.performances
.reduce((total, p) => total + p.volumeCredits, 0);
}
代码行数由我开始重构时的 44 行增加到了 70 行(不算 htmlStatement),这主要是将代码抽取到函数里带来的额外包装成本。虽然代码的行数增加了,但重构也带来了代码可读性的提高。额外的包装将混杂的逻辑分解成可辨别的部分,分离了详单的计算逻辑与样式。这种模块化使我更容易辨别代码的不同部分,了解它们的协作关系。虽说言以简为贵,但可演化的软件却以明确为贵。通过增强代码的模块化,我可以轻易地添加 HTML 版本的代码,而无须重复计算部分的逻辑。
Tip
编程时,需要遵循营地法则:保证你离开时的代码库一定比来时更健康。
其实打印逻辑还可以进一步简化,但当前的代码也够用了。我经常需要在所有可做的重构与添加新特性之间寻找平衡。在当今业界,大多数人面临同样的选择时,似乎多以延缓重构而告终——当然这也是一种选择。我的观点则与营地法则无异:保证离开时的代码库一定比你来时更加健康。完美的境界很难达到,但应该时时都勤加拂拭。
1.8 按类型重组计算过程
接下来我将注意力集中到下一个特性改动:支持更多类型的戏剧,以及支持它们各自的价格计算和观众量积分计算。对于现在的结构,我只需要在计算函数里添加分支逻辑即可。amountFor 函数清楚地体现了,戏剧类型在计算分支的选择上起着关键的作用——但这样的分支逻辑很容易随代码堆积而腐坏,除非编程语言提供了更基础的编程语言元素来防止代码堆积。
要为程序引入结构、显式地表达出“计算逻辑的差异是由类型代码确定”有许多途径,不过最自然的解决办法还是使用面向对象世界里的一个经典特性——类型多态。传统的面向对象特性在 JavaScript 世界一直备受争议,但新的 ECMAScript 2015 规范有意为类和多态引入了一个相当实用的语法糖。这说明,在合适的场景下使用面向对象是合理的——显然我们这个就是一个合适的使用场景。
我的设想是先建立一个继承体系,它有“喜剧”(comedy)和“悲剧”(tragedy)两个子类,子类各自包含独立的计算逻辑。调用者通过调用一个多态的 amount 函数,让语言帮你分发到不同的子类的计算过程中。volumeCredits 函数的处理也是如法炮制。为此我需要用到多种重构方法,其中最核心的一招是以多态取代条件表达式(272),将多个同样的类型码分支用多态取代。但在施展以多态取代条件表达式(272)之前,我得先创建一个基本的继承结构。我需要先创建一个类,并将价格计算函数和观众量积分计算函数放进去。
我先从检查计算代码开始。(之前的重构带来的一大好处是,现在我大可以忽略那些格式化代码,只要不改变中转数据结构就行。我可以进一步添加测试来保证中转数据结构不会被意外修改。)
createStatementData.js…
export default function createStatementData(invoice, plays) {
const result = {};
result.customer = invoice.customer;
result.performances = invoice.performances.map(enrichPerformance);
result.totalAmount = totalAmount(result);
result.totalVolumeCredits = totalVolumeCredits(result);
return result;
function enrichPerformance(aPerformance) {
const result = Object.assign({}, aPerformance);
result.play = playFor(result);
result.amount = amountFor(result);
result.volumeCredits = volumeCreditsFor(result);
return result;
}
function playFor(aPerformance) {
return plays[aPerformance.playID]
}
function amountFor(aPerformance) {
let result = 0;
switch (aPerformance.play.type) {
case "tragedy":
result = 40000;
if (aPerformance.audience > 30) {
result += 1000 * (aPerformance.audience - 30);
}
break;
case "comedy":
result = 30000;
if (aPerformance.audience > 20) {
result += 10000 + 500 * (aPerformance.audience - 20);
}
result += 300 * aPerformance.audience;
break;
default:
throw new Error(`unknown type: ${aPerformance.play.type}`);
}
return result;
}
function volumeCreditsFor(aPerformance) {
let result = 0;
result += Math.max(aPerformance.audience - 30, 0);
if ("comedy" === aPerformance.play.type) result += Math.floor(aPerformance.audience / 5);
return result;
}
function totalAmount(data) {
return data.performances
.reduce((total, p) => total + p.amount, 0);
}
function totalVolumeCredits(data) {
return data.performances
.reduce((total, p) => total + p.volumeCredits, 0);
}
创建演出计算器
enrichPerformance 函数是关键所在,因为正是它用每场演出的数据来填充中转数据结构。目前它直接调用了计算价格和观众量积分的函数,我需要创建一个类,通过这个类来调用这些函数。由于这个类存放了与每场演出相关数据的计算函数,于是我把它称为演出计算器(performance calculator)。
function createStatementData…
function enrichPerformance(aPerformance) {
const calculator = new PerformanceCalculator(aPerformance);
const result = Object.assign({}, aPerformance);
result.play = playFor(result);
result.amount = amountFor(result);
result.volumeCredits = volumeCreditsFor(result);
return result;
}
顶层作用域…
class PerformanceCalculator {
constructor(aPerformance) {
this.performance = aPerformance;
}
}
到目前为止,这个新对象还没做什么事。我希望将函数行为搬移进来,这可以从最容易搬移的东西——play 字段开始。严格来讲,我不需要搬移这个字段,因为它并未体现出多态性,但这样可以把所有数据转换集中到一处地方,保证了代码的一致性和清晰度。
为此,我将使用改变函数声明(124)手法将 performance 的 play 字段传给计算器。
function createStatementData…
function enrichPerformance(aPerformance) {
const calculator = new PerformanceCalculator(
aPerformance,
playFor(aPerformance)
);
const result = Object.assign({}, aPerformance);
result.play = calculator.play;
result.amount = amountFor(result);
result.volumeCredits = volumeCreditsFor(result);
return result;
}
class PerformanceCalculator…
class PerformanceCalculator {
constructor(aPerformance, aPlay) {
this.performance = aPerformance;
this.play = aPlay;
}
}
(以下行文中我将不再特别提及“编译、测试、提交”循环,我猜你也已经读得有些厌烦了。但我仍会不断重复这个循环。的确,有时我也会厌烦,直到错误又跳出来咬我一下,我才又学会进入小步的节奏。)
将函数搬移进计算器
我要搬移的下一块逻辑,对计算一场演出的价格(amount)来说就尤为重要了。在调整嵌套函数的层级时,我经常将函数挪来挪去,但接下来需要改动到更深入的函数上下文,因此我将小心使用搬移函数(198)来重构它。首先,将 amount 函数的逻辑复制一份到新的上下文中,也就是 PerformanceCalculator 类中。然后微调一下代码,将 aPerformance 改为 this.performance,将 playFor(aPerformance)改为 this.play,使代码适应这个新家。
class PerformanceCalculator…
get amount() {
let result = 0;
switch (this.play.type) {
case "tragedy":
result = 40000;
if (this.performance.audience > 30) {
result += 1000 * (this.performance.audience - 30);
}
break;
case "comedy":
result = 30000;
if (this.performance.audience > 20) {
result += 10000 + 500 * (this.performance.audience - 20);
}
result += 300 * this.performance.audience;
break;
default:
throw new Error(`unknown type: ${this.play.type}`);
}
return result;
}
搬移完成后可以编译一下,看看是否有编译错误。我在本地开发环境运行代码时,编译会自动发生,我实际需要做的只是运行一下 Babel。编译能帮我发现新函数中潜在的语法错误,语法之外的就帮不上什么忙了。尽管如此,这一步还是很有用。
使新函数适应新家后,我会将原来的函数改造成一个委托函数,让它直接调用新函数。
function createStatementData…
function amountFor(aPerformance) {
return new PerformanceCalculator(aPerformance, playFor(aPerformance)).amount;
}
现在,我可以执行一次编译、测试、提交,确保代码搬到新家后也能如常工作。之后,我应用内联函数(115),让引用点直接调用新函数(然后编译、测试、提交)。
function createStatementData…
function enrichPerformance(aPerformance) {
const calculator = new PerformanceCalculator(
aPerformance,
playFor(aPerformance)
);
const result = Object.assign({}, aPerformance);
result.play = calculator.play;
result.amount = calculator.amount;
result.volumeCredits = volumeCreditsFor(result);
return result;
}
搬移观众量积分计算也遵循同样的流程。
function createStatementData…
function enrichPerformance(aPerformance) {
const calculator = new PerformanceCalculator(
aPerformance,
playFor(aPerformance)
);
const result = Object.assign({}, aPerformance);
result.play = calculator.play;
result.amount = calculator.amount;
result.volumeCredits = calculator.volumeCredits;
return result;
}
class PerformanceCalculator…
get volumeCredits() {
let result = 0;
result += Math.max(this.performance.audience - 30, 0);
if ("comedy" === this.play.type) result += Math.floor(this.performance.audience / 5);
return result;
}
使演出计算器表现出多态性
我已将全部计算逻辑搬移到一个类中,是时候将它多态化了。第一步是应用以子类取代类型码(362)引入子类,弃用类型代码。为此,我需要为演出计算器创建子类,并在 createStatementData 中获取对应的子类。要得到正确的子类,我需要将构造函数调用替换为一个普通的函数调用,因为 JavaScript 的构造函数里无法返回子类。于是我使用以工厂函数取代构造函数(334)。
function createStatementData…
function enrichPerformance(aPerformance) {
const calculator = createPerformanceCalculator(
aPerformance,
playFor(aPerformance)
);
const result = Object.assign({}, aPerformance);
result.play = calculator.play;
result.amount = calculator.amount;
result.volumeCredits = calculator.volumeCredits;
return result;
}
顶层作用域…
function createPerformanceCalculator(aPerformance, aPlay) {
return new PerformanceCalculator(aPerformance, aPlay);
}
改造成普通函数后,我就可以在里面创建演出计算器的子类,然后由创建函数决定返回哪一个子类的实例。
顶层作用域…
function createPerformanceCalculator(aPerformance, aPlay) {
switch (aPlay.type) {
case "tragedy":
return new TragedyCalculator(aPerformance, aPlay);
case "comedy":
return new ComedyCalculator(aPerformance, aPlay);
default:
throw new Error(`unknown type: ${aPlay.type}`);
}
}
class TragedyCalculator extends PerformanceCalculator {}
class ComedyCalculator extends PerformanceCalculator {}
准备好实现多态的类结构后,我就可以继续使用以多态取代条件表达式(272)手法了。
我先从悲剧的价格计算逻辑开始搬移。
class TragedyCalculator…
get amount() {
let result = 40000;
if (this.performance.audience > 30) {
result += 1000 * (this.performance.audience - 30);
}
return result;
}
虽说子类有了这个方法已足以覆盖超类对应的条件分支,但要是你也和我一样偏执,你也许还想在超类的分支上抛一个异常。
class PerformanceCalculator…
get amount() {
let result = 0;
switch (this.play.type) {
case "tragedy":
throw 'bad thing';
case "comedy":
result = 30000;
if (this.performance.audience > 20) {
result += 10000 + 500 * (this.performance.audience - 20);
}
result += 300 * this.performance.audience;
break;
default:
throw new Error(`unknown type: ${this.play.type}`);
}
return result;
}
虽然我也可以直接删掉处理悲剧的分支,将错误留给默认分支去抛出,但我更喜欢显式地抛出异常——何况这行代码只能再活个几分钟了(这也是我直接抛出一个字符串而不用更好的错误对象的原因)。
再次进行编译、测试、提交。之后,将处理喜剧类型的分支也下移到子类中去。
class ComedyCalculator…
get amount() {
let result = 30000;
if (this.performance.audience > 20) {
result += 10000 + 500 * (this.performance.audience - 20);
}
result += 300 * this.performance.audience;
return result;
}
理论上讲,我可以将超类的 amount 方法一并移除了,反正它也不应再被调用到。但不删它,给未来的自己留点纪念品也是极好的,顺便可以提醒后来者记得实现这个函数。
class PerformanceCalculator…
get amount() {
throw new Error('subclass responsibility');
}
下一个要替换的条件表达式是观众量积分的计算。我回顾了一下前面关于未来戏剧类型的讨论,发现大多数剧类在计算积分时都会检查观众数是否达到 30,仅一小部分品类有所不同。因此,将更为通用的逻辑放到超类作为默认条件,出现特殊场景时按需覆盖它,听起来十分合理。于是我将一部分喜剧的逻辑下移到子类。
class PerformanceCalculator…
get volumeCredits() {
return Math.max(this.performance.audience - 30, 0);
}
class ComedyCalculator…
get volumeCredits() {
return super.volumeCredits + Math.floor(this.performance.audience / 5);
}
1.9 进展:使用多态计算器来提供数据
又到了观摩代码的时刻,让我们来看看,为计算器引入多态会对代码库有什么影响。
createStatementData.js
export default function createStatementData(invoice, plays) {
const result = {};
result.customer = invoice.customer;
result.performances = invoice.performances.map(enrichPerformance);
result.totalAmount = totalAmount(result);
result.totalVolumeCredits = totalVolumeCredits(result);
return result;
function enrichPerformance(aPerformance) {
const calculator = createPerformanceCalculator(aPerformance, playFor(aPerformance));
const result = Object.assign({}, aPerformance);
result.play = calculator.play;
result.amount = calculator.amount;
result.volumeCredits = calculator.volumeCredits;
return result;
}
function playFor(aPerformance) {
return plays[aPerformance.playID]
}
function totalAmount(data) {
return data.performances
.reduce((total, p) => total + p.amount, 0);
}
function totalVolumeCredits(data) {
return data.performances
.reduce((total, p) => total + p.volumeCredits, 0);
}
}
function createPerformanceCalculator(aPerformance, aPlay) {
switch(aPlay.type) {
case "tragedy": return new TragedyCalculator(aPerformance, aPlay);
case "comedy" : return new ComedyCalculator(aPerformance, aPlay);
default:
throw new Error(`unknown type: ${aPlay.type}`);
}
}
class PerformanceCalculator {
constructor(aPerformance, aPlay) {
this.performance = aPerformance;
this.play = aPlay;
}
get amount() {
throw new Error('subclass responsibility');
}
get volumeCredits() {
return Math.max(this.performance.audience - 30, 0);
}
}
class TragedyCalculator extends PerformanceCalculator {
get amount() {
let result = 40000;
if (this.performance.audience > 30) {
result += 1000 * (this.performance.audience - 30);
}
return result;
}
}
class ComedyCalculator extends PerformanceCalculator {
get amount() {
let result = 30000;
if (this.performance.audience > 20) {
result += 10000 + 500 * (this.performance.audience - 20);
}
result += 300 * this.performance.audience;
return result;
}
get volumeCredits() {
return super.volumeCredits + Math.floor(this.performance.audience / 5);
}
}
代码量仍然有所增加,因为我再次整理了代码结构。新结构带来的好处是,不同戏剧种类的计算各自集中到了一处地方。如果大多数修改都涉及特定类型的计算,像这样按类型进行分离就很有意义。当添加新剧种时,只需要添加一个子类,并在创建函数中返回它。
这个示例还揭示了一些关于此类继承方案何时适用的洞见。上面我将条件分支的查找从两个不同的函数(amountFor 和 volumeCreditsFor)搬移到一个集中的构造函数 createPerformanceCalculator 中。有越多的函数依赖于同一套类型进行多态,这种继承方案就越有益处。
除了这样设计,还有另一种可能的方案,那就是让 createStatementData 返回计算器实例本身,而非自己拿到计算器来填充中转数据结构。JavaScript 的类设计有不少好特性,例如,取值函数用起来就像普通的数据存取。我在考量是“直接返回实例本身”还是“返回计算好的中转数据”时,主要看数据的使用者是谁。在这个例子中,我更想通过中转数据结构来展示如何以此隐藏计算器背后的多态设计。
1.10 结语
这是一个简单的例子,但我希望它能让你对“重构怎么做”有一点感觉。例中我已经示范了数种重构手法,包括提炼函数(106)、内联变量(123)、搬移函数(198)和以多态取代条件表达式(272)等。
本章的重构有 3 个较为重要的节点,分别是:将原函数分解成一组嵌套的函数、应用拆分阶段(154)分离计算逻辑与输出格式化逻辑,以及为计算器引入多态性来处理计算逻辑。每一步都给代码添加了更多的结构,以便我能更好地表达代码的意图。
一般来说,重构早期的主要动力是尝试理解代码如何工作。通常你需要先通读代码,找到一些感觉,然后再通过重构将这些感觉从脑海里搬回到代码中。清晰的代码更容易理解,使你能够发现更深层次的设计问题,从而形成积极正向的反馈环。当然,这个示例仍有值得改进的地方,但现在测试仍能全部通过,代码相比初见时已经有了巨大的改善,所以我已经可以满足了。
我谈论的是如何改善代码,但什么样的代码才算好代码,程序员们有很多争论。我偏爱小的、命名良好的函数,也知道有些人反对这个观点。如果我们说这只关乎美学,只是各花入各眼,没有好坏高低之分,那除了诉诸个人品味,就没有任何客观事实依据了。但我坚信,这不仅关乎个人品味,而且是有客观标准的。我认为,好代码的检验标准就是人们是否能轻而易举地修改它。好代码应该直截了当:有人需要修改代码时,他们应能轻易找到修改点,应该能快速做出更改,而不易引入其他错误。一个健康的代码库能够最大限度地提升我们的生产力,支持我们更快、更低成本地为用户添加新特性。为了保持代码库的健康,就需要时刻留意现状与理想之间的差距,然后通过重构不断接近这个理想。
Tip
好代码的检验标准就是人们是否能轻而易举地修改它。
这个示例告诉我们最重要的一点就是重构的节奏感。无论何时,当我向人们展示我如何重构时,无人不讶异于我的步子之小,并且每一步都保证代码处于编译通过和测试通过的可工作状态。20 年前,当 Kent Beck 在底特律的一家宾馆里向我展示同样的手法时,我也报以同样的震撼。开展高效有序的重构,关键的心得是:小的步子可以更快前进,请保持代码永远处于可工作状态,小步修改累积起来也能大大改善系统的设计。这几点请君牢记,其余的我已无需多言。
第 2 章 重构的原则
前一章所举的例子应该已经让你对重构有了一个良好的感觉。现在,我们应该回头看看重构的一些大原则。
2.1 何谓重构
一线的实践者们经常很随意地使用“重构”这个词——软件开发领域的很多词汇都有此待遇。我使用这个词的方式比较严谨,并且我发现这种严谨的方式很有好处。(下列定义与本书第 1 版中给出的定义一样。)“重构”这个词既可以用作名词也可以用作动词。名词形式的定义是:
重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
这个定义适用于我在前面的例子中提到的那些有名字的重构,例如提炼函数(106)和以多态取代条件表达式(272)。
动词形式的定义是:
重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
所以,我可能会花一两个小时进行重构(动词),其间我会使用几十个不同的重构(名词)。
过去十几年,这个行业里的很多人用“重构”这个词来指代任何形式的代码清理,但上面的定义所指的是一种特定的清理代码的方式。重构的关键在于运用大量微小且保持软件行为的步骤,一步步达成大规模的修改。每个单独的重构要么很小,要么由若干小步骤组合而成。因此,在重构的过程中,我的代码很少进入不可工作的状态,即便重构没有完成,我也可以在任何时刻停下来。
Tip
如果有人说他们的代码在重构过程中有一两天时间不可用,基本上可以确定,他们在做的事不是重构。
我会用“结构调整”(restructuring)来泛指对代码库进行的各种形式的重新组织或清理,重构则是特定的一类结构调整。刚接触重构的人看我用很多小步骤完成似乎可以一大步就能做完的事,可能会觉得这样很低效。但小步前进能让我走得更快,因为这些小步骤能完美地彼此组合,而且——更关键的是——整个过程中我不会花任何时间来调试。
在上述定义中,我用了“可观察行为”的说法。它的意思是,整体而言,经过重构之后的代码所做的事应该与重构之前大致一样。这个说法并非完全严格,并且我是故意保留这点儿空间的:重构之后的代码不一定与重构前行为完全一致。比如说,提炼函数(106)会改变函数调用栈,因此程序的性能就会有所改变;改变函数声明(124)和搬移函数(198)等重构经常会改变模块的接口。不过就用户应该关心的行为而言,不应该有任何改变。如果我在重构过程中发现了任何 bug,重构完成后同样的 bug 应该仍然存在(不过,如果潜在的 bug 还没有被任何人发现,也可以当即把它改掉)。
重构与性能优化有很多相似之处:两者都需要修改代码,并且两者都不会改变程序的整体功能。两者的差别在于其目的:重构是为了让代码“更容易理解,更易于修改”。这可能使程序运行得更快,也可能使程序运行得更慢。在性能优化时,我只关心让程序运行得更快,最终得到的代码有可能更难理解和维护,对此我有心理准备。
2.2 两顶帽子
Kent Beck 提出了“两顶帽子”的比喻。使用重构技术开发软件时,我把自己的时间分配给两种截然不同的行为:添加新功能和重构。添加新功能时,我不应该修改既有代码,只管添加新功能。通过添加测试并让测试正常运行,我可以衡量自己的工作进度。重构时我就不能再添加功能,只管调整代码的结构。此时我不应该添加任何测试(除非发现有先前遗漏的东西),只在绝对必要(用以处理接口变化)时才修改测试。
软件开发过程中,我可能会发现自己经常变换帽子。首先我会尝试添加新功能,然后会意识到:如果把程序结构改一下,功能的添加会容易得多。于是我换一顶帽子,做一会儿重构工作。程序结构调整好后,我又换上原先的帽子,继续添加新功能。新功能正常工作后,我又发现自己的编码造成程序难以理解,于是又换上重构帽子……整个过程或许只花 10 分钟,但无论何时我都清楚自己戴的是哪一顶帽子,并且明白不同的帽子对编程状态提出的不同要求。
2.3 为何重构
我不想把重构说成是包治百病的万灵丹,它绝对不是所谓的“银弹”。不过它的确很有价值,尽管它不是一颗“银弹”,却可以算是一把“银钳子”,可以帮你始终良好地控制自己的代码。重构是一个工具,它可以(并且应该)用于以下几个目的。
重构改进软件的设计
如果没有重构,程序的内部设计(或者叫架构)会逐渐腐败变质。当人们只为短期目的而修改代码时,他们经常没有完全理解架构的整体设计,于是代码逐渐失去了自己的结构。程序员越来越难通过阅读源码来理解原来的设计。代码结构的流失有累积效应。越难看出代码所代表的设计意图,就越难保护其设计,于是设计就腐败得越快。经常性的重构有助于代码维持自己该有的形态。
完成同样一件事,设计欠佳的程序往往需要更多代码,这常常是因为代码在不同的地方使用完全相同的语句做同样的事,因此改进设计的一个重要方向就是消除重复代码。代码量减少并不会使系统运行更快,因为这对程序的资源占用几乎没有任何明显影响。然而代码量减少将使未来可能的程序修改动作容易得多。代码越多,做正确的修改就越困难,因为有更多代码需要理解。我在这里做了点儿修改,系统却不如预期那样工作,因为我没有修改另一处——那里的代码做着几乎完全一样的事情,只是所处环境略有不同。消除重复代码,我就可以确定所有事物和行为在代码中只表述一次,这正是优秀设计的根本。
重构使软件更容易理解
所谓程序设计,很大程度上就是与计算机对话:我编写代码告诉计算机做什么事,而它的响应是按照我的指示精确行动。一言以蔽之,我所做的就是填补“我想要它做什么”和“我告诉它做什么”之间的缝隙。编程的核心就在于“准确说出我想要的”。然而别忘了,除了计算机外,源码还有其他读者:几个月之后可能会有另一位程序员尝试读懂我的代码并对其做一些修改。我们很容易忘记这这位读者,但他才是最重要的。计算机是否多花了几个时钟周期来编译,又有什么关系呢?如果一个程序员花费一周时间来修改某段代码,那才要命呢——如果他理解了我的代码,这个修改原本只需一小时。
问题在于,当我努力让程序运转的时候,我不会想到未来出现的那个开发者。是的,我们应该改变一下开发节奏,让代码变得更易于理解。重构可以帮我让代码更易读。开始进行重构前,代码可以正常运行,但结构不够理想。在重构上花一点点时间,就可以让代码更好地表达自己的意图——更清晰地说出我想要做的。
关于这一点,我没必要表现得多么无私。很多时候那个未来的开发者就是我自己。此时重构就显得尤其重要了。我是一个很懒惰的程序员,我的懒惰表现形式之一就是:总是记不住自己写过的代码。事实上,对于任何能够立刻查阅的东西,我都故意不去记它,因为我怕把自己的脑袋塞爆。我总是尽量把该记住的东西写进代码里,这样我就不必记住它了。这么一来,下班后我还可以喝上两杯 Maudite 啤酒,不必太担心它杀光我的脑细胞。
重构帮助找到 bug
对代码的理解,可以帮我找到 bug。我承认我不太擅长找 bug。有些人只要盯着一大段代码就可以找出里面的 bug,我不行。但我发现,如果对代码进行重构,我就可以深入理解代码的所作所为,并立即把新的理解反映在代码当中。搞清楚程序结构的同时,我也验证了自己所做的一些假设,于是想不把 bug 揪出来都难。
这让我想起了 Kent Beck 经常形容自己的一句话:“我不是一个特别好的程序员,我只是一个有着一些特别好的习惯的还不错的程序员。”重构能够帮助我更有效地写出健壮的代码。
重构提高编程速度
最后,前面的一切都归结到了这一点:重构帮我更快速地开发程序。
听起来有点儿违反直觉。当我谈到重构时,人们很容易看出它能够提高质量。改善设计、提升可读性、减少 bug,这些都能提高质量。但花在重构上的时间,难道不是在降低开发速度吗?
当我跟那些在一个系统上工作较长时间的软件开发者交谈时,经常会听到这样的故事:一开始他们进展很快,但如今想要添加一个新功能需要的时间就要长得多。他们需要花越来越多的时间去考虑如何把新功能塞进现有的代码库,不断蹦出来的 bug 修复起来也越来越慢。代码库看起来就像补丁摞补丁,需要细致的考古工作才能弄明白整个系统是如何工作的。这份负担不断拖慢新增功能的速度,到最后程序员恨不得从头开始重写整个系统。
下面这幅图可以描绘他们经历的困境。
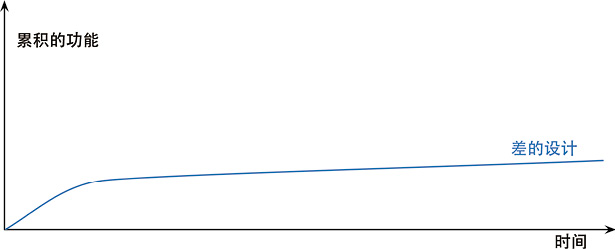
但有些团队的境遇则截然不同。他们添加新功能的速度越来越快,因为他们能利用已有的功能,基于已有的功能快速构建新功能。
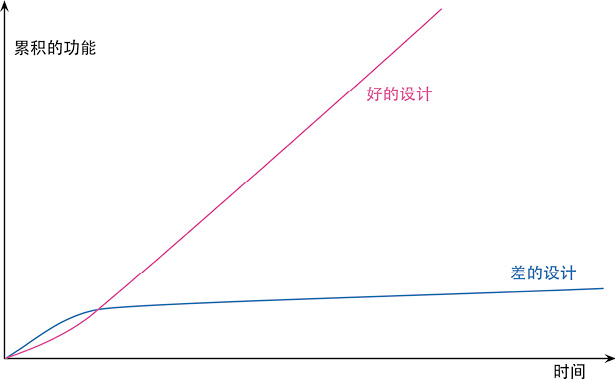
两种团队的区别就在于软件的内部质量。需要添加新功能时,内部质量良好的软件让我可以很容易找到在哪里修改、如何修改。良好的模块划分使我只需要理解代码库的一小部分,就可以做出修改。如果代码很清晰,我引入 bug 的可能性就会变小,即使引入了 bug,调试也会容易得多。理想情况下,我的代码库会逐步演化成一个平台,在其上可以很容易地构造与其领域相关的新功能。
我把这种现象称为“设计耐久性假说”:通过投入精力改善内部设计,我们增加了软件的耐久性,从而可以更长时间地保持开发的快速。我还无法科学地证明这个理论,所以我说它是一个“假说”。但我的经验,以及我在职业生涯中认识的上百名优秀程序员的经验,都支持这个假说。
20 年前,行业的陈规认为:良好的设计必须在开始编程之前完成,因为一旦开始编写代码,设计就只会逐渐腐败。重构改变了这个图景。现在我们可以改善已有代码的设计,因此我们可以先做一个设计,然后不断改善它,哪怕程序本身的功能也在不断发生着变化。由于预先做出良好的设计非常困难,想要既体面又快速地开发功能,重构必不可少。
2.4 何时重构
在我编程的每个小时,我都会做重构。有几种方式可以把重构融入我的工作过程里。
Tip
三次法则
Don Roberts 给了我一条准则:第一次做某件事时只管去做;第二次做类似的事会产生反感,但无论如何还是可以去做;第三次再做类似的事,你就应该重构。
正如老话说的:事不过三,三则重构。
预备性重构:让添加新功能更容易
重构的最佳时机就在添加新功能之前。在动手添加新功能之前,我会看看现有的代码库,此时经常会发现:如果对代码结构做一点微调,我的工作会容易得多。也许已经有个函数提供了我需要的大部分功能,但有几个字面量的值与我的需要略有冲突。如果不做重构,我可能会把整个函数复制过来,修改这几个值,但这就会导致重复代码——如果将来我需要做修改,就必须同时修改两处(更麻烦的是,我得先找到这两处)。而且,如果将来我还需要一个类似又略有不同的功能,就只能再复制粘贴一次,这可不是个好主意。所以我戴上重构的帽子,使用函数参数化(310)。做完这件事以后,接下来我就只需要调用这个函数,传入我需要的参数。
Tip
这就好像我要往东去 100 公里。我不会往东一头把车开进树林,而是先往北开 20 公里上高速,然后再向东开 100 公里。后者的速度比前者要快上 3 倍。如果有人催着你“赶快直接去那儿”,有时你需要说:“等等,我要先看看地图,找出最快的路径。”这就是预备性重构于我的意义。
——Jessica Kerr
修复 bug 时的情况也是一样。在寻找问题根因时,我可能会发现:如果把 3 段一模一样且都会导致错误的代码合并到一处,问题修复起来会容易得多。或者,如果把某些更新数据的逻辑与查询逻辑分开,会更容易避免造成错误的逻辑纠缠。用重构改善这些情况,在同样场合再次出现同样 bug 的概率也会降低。
帮助理解的重构:使代码更易懂
我需要先理解代码在做什么,然后才能着手修改。这段代码可能是我写的,也可能是别人写的。一旦我需要思考“这段代码到底在做什么”,我就会自问:能不能重构这段代码,令其一目了然?我可能看见了一段结构糟糕的条件逻辑,也可能希望复用一个函数,但花费了几分钟才弄懂它到底在做什么,因为它的函数命名实在是太糟糕了。这些都是重构的机会。
看代码时,我会在脑海里形成一些理解,但我的记性不好,记不住那么多细节。正如 Ward Cunningham 所说,通过重构,我就把脑子里的理解转移到了代码本身。随后我运行这个软件,看它是否正常工作,来检查这些理解是否正确。如果把对代码的理解植入代码中,这份知识会保存得更久,并且我的同事也能看到。
重构带来的帮助不仅发生在将来——常常是立竿见影。我会先在一些小细节上使用重构来帮助理解,给一两个变量改名,让它们更清楚地表达意图,以方便理解,或是将一个长函数拆成几个小函数。当代码变得更清晰一些时,我就会看见之前看不见的设计问题。如果不做前面的重构,我可能永远都看不见这些设计问题,因为我不够聪明,无法在脑海中推演所有这些变化。Ralph Johnson 说,这些初步的重构就像扫去窗上的尘埃,使我们得以看到窗外的风景。在研读代码时,重构会引领我获得更高层面的理解,如果只是阅读代码很难有此领悟。有些人以为这些重构只是毫无意义地把玩代码,他们没有意识到,缺少了这些细微的整理,他们就无法看到隐藏在一片混乱背后的机遇。
捡垃圾式重构
帮助理解的重构还有一个变体:我已经理解代码在做什么,但发现它做得不好,例如逻辑不必要地迂回复杂,或者两个函数几乎完全相同,可以用一个参数化的函数取而代之。这里有一个取舍:我不想从眼下正要完成的任务上跑题太多,但我也不想把垃圾留在原地,给将来的修改增加麻烦。如果我发现的垃圾很容易重构,我会马上重构它;如果重构需要花一些精力,我可能会拿一张便笺纸把它记下来,完成当下的任务再回来重构它。
当然,有时这样的垃圾需要好几个小时才能解决,而我又有更紧急的事要完成。不过即便如此,稍微花一点工夫做一点儿清理,通常都是值得的。正如野营者的老话所说:至少要让营地比你到达时更干净。如果每次经过这段代码时都把它变好一点点,积少成多,垃圾总会被处理干净。重构的妙处就在于,每个小步骤都不会破坏代码——所以,有时一块垃圾在好几个月之后才终于清理干净,但即便每次清理并不完整,代码也不会被破坏。
有计划的重构和见机行事的重构
上面的例子——预备性重构、帮助理解的重构、捡垃圾式重构——都是见机行事的:我并不专门安排一段时间来重构,而是在添加功能或修复 bug 的同时顺便重构。这是我自然的编程流的一部分。不管是要添加功能还是修复 bug,重构对我当下的任务有帮助,而且让我未来的工作更轻松。这是一件很重要而又常被误解的事:重构不是与编程割裂的行为。你不会专门安排时间重构,正如你不会专门安排时间写 if 语句。我的项目计划上没有专门留给重构的时间,绝大多数重构都在我做其他事的过程中自然发生。
Tip
肮脏的代码必须重构,但漂亮的代码也需要很多重构。
还有一种常见的误解认为,重构就是人们弥补过去的错误或者清理肮脏的代码。当然,如果遇上了肮脏的代码,你必须重构,但漂亮的代码也需要很多重构。在写代码时,我会做出很多权衡取舍:参数化需要做到什么程度?函数之间的边界应该划在哪里?对于昨天的功能完全合理的权衡,在今天要添加新功能时可能就不再合理。好在,当我需要改变这些权衡以反映现实情况的变化时,整洁的代码重构起来会更容易。
Tip
每次要修改时,首先令修改很容易(警告:这件事有时会很难),然后再进行这次容易的修改。
——Kent Beck
长久以来,人们认为编写软件是一个累加的过程:要添加新功能,我们就应该增加新代码。但优秀的程序员知道,添加新功能最快的方法往往是先修改现有的代码,使新功能容易被加入。所以,软件永远不应该被视为“完成”。每当需要新能力时,软件就应该做出相应的改变。越是在已有代码中,这样的改变就越显重要。
不过,说了这么多,并不表示有计划的重构总是错的。如果团队过去忽视了重构,那么常常会需要专门花一些时间来优化代码库,以便更容易添加新功能。在重构上花一个星期的时间,会在未来几个月里发挥价值。有时,即便团队做了日常的重构,还是会有问题在某个区域逐渐累积长大,最终需要专门花些时间来解决。但这种有计划的重构应该很少,大部分重构应该是不起眼的、见机行事的。
我听过的一条建议是:将重构与添加新功能在版本控制的提交中分开。这样做的一大好处是可以各自独立地审阅和批准这些提交。但我并不认同这种做法。重构常常与新添功能紧密交织,不值得花工夫把它们分开。并且这样做也使重构脱离了上下文,使人看不出这些“重构提交”的价值。每个团队应该尝试并找出适合自己的工作方式,只是要记住:分离重构提交并不是毋庸置疑的原则,只有当你真的感到有益时,才值得这样做。
长期重构
大多数重构可以在几分钟——最多几小时——内完成。但有一些大型的重构可能要花上几个星期,例如要替换一个正在使用的库,或者将整块代码抽取到一个组件中并共享给另一支团队使用,再或者要处理一大堆混乱的依赖关系,等等。
即便在这样的情况下,我仍然不愿让一支团队专门做重构。可以让整个团队达成共识,在未来几周时间里逐步解决这个问题,这经常是一个有效的策略。每当有人靠近“重构区”的代码,就把它朝想要改进的方向推动一点。这个策略的好处在于,重构不会破坏代码——每次小改动之后,整个系统仍然照常工作。例如,如果想替换掉一个正在使用的库,可以先引入一层新的抽象,使其兼容新旧两个库的接口。一旦调用方已经完全改为使用这层抽象,替换下面的库就会容易得多。(这个策略叫作 Branch By Abstraction[mf-bba]。)
复审代码时重构
一些公司会做常规的代码复审(code review),因为这种活动可以改善开发状况。代码复审有助于在开发团队中传播知识,也有助于让较有经验的开发者把知识传递给比较欠缺经验的人,并帮助更多人理解大型软件系统中的更多部分。代码复审对于编写清晰代码也很重要。我的代码也许对我自己来说很清晰,对他人则不然。这是无法避免的,因为要让开发者设身处地为那些不熟悉自己所作所为的人着想,实在太困难了。代码复审也让更多人有机会提出有用的建议,毕竟我在一个星期之内能够想出的好点子很有限。如果能得到别人的帮助,我的生活会滋润得多,所以我总是期待更多复审。
我发现,重构可以帮助我复审别人的代码。开始重构前我可以先阅读代码,得到一定程度的理解,并提出一些建议。一旦想到一些点子,我就会考虑是否可以通过重构立即轻松地实现它们。如果可以,我就会动手。这样做了几次以后,我可以更清楚地看到,当我的建议被实施以后,代码会是什么样。我不必想象代码应该是什么样,我可以真实看见。于是我可以获得更高层次的认识。如果不进行重构,我永远无法得到这样的认识。
重构还可以帮助代码复审工作得到更具体的结果。不仅获得建议,而且其中许多建议能够立刻实现。最终你将从实践中得到比以往多得多的成就感。
至于如何在代码复审的过程中加入重构,这要取决于复审的形式。在常见的 pull request 模式下,复审者独自浏览代码,代码的作者不在旁边,此时进行重构效果并不好。如果代码的原作者在旁边会好很多,因为作者能提供关于代码的上下文信息,并且充分认同复审者进行修改的意图。对我个人而言,与原作者肩并肩坐在一起,一边浏览代码一边重构,体验是最佳的。这种工作方式很自然地导向结对编程:在编程的过程中持续不断地进行代码复审。
怎么对经理说
“该怎么跟经理说重构的事?”这是我最常被问到的一个问题。毋庸讳言,我见过一些场合,“重构”被视为一个脏词——经理(和客户)认为重构要么是在弥补过去犯下的错误,要么是不增加价值的无用功。如果团队又计划了几周时间专门做重构,情况就更糟糕了——如果他们做的其实还不是重构,而是不加小心的结构调整,然后又对代码库造成了破坏,那可就真是糟透了。
如果这位经理懂技术,能理解“设计耐久性假说”,那么向他说明重构的意义应该不会很困难。这样的经理应该会鼓励日常的重构,并主动寻找团队日常重构做得不够的征兆。虽然“团队做了太多重构”的情况确实也发生过,但比起做得不够的情况要罕见得多了。
当然,很多经理和客户不具备这样的技术意识,他们不理解代码库的健康对生产率的影响。这种情况下我会给团队一个较有争议的建议:不要告诉经理!
这是在搞破坏吗?我不这样想。软件开发者都是专业人士。我们的工作就是尽可能快速创造出高效软件。我的经验告诉我,对于快速创造软件,重构可带来巨大帮助。如果需要添加新功能,而原本设计却又使我无法方便地修改,我发现先重构再添加新功能会更快些。如果要修补错误,就得先理解软件的工作方式,而我发现重构是理解软件的最快方式。受进度驱动的经理要我尽可能快速完成任务,至于怎么完成,那就是我的事了。我领这份工资,是因为我擅长快速实现新功能;我认为最快的方式就是重构,所以我就重构。
何时不应该重构
听起来好像我一直在提倡重构,但确实有一些不值得重构的情况。
如果我看见一块凌乱的代码,但并不需要修改它,那么我就不需要重构它。如果丑陋的代码能被隐藏在一个 API 之下,我就可以容忍它继续保持丑陋。只有当我需要理解其工作原理时,对其进行重构才有价值。
另一种情况是,如果重写比重构还容易,就别重构了。这是个困难的决定。如果不花一点儿时间尝试,往往很难真实了解重构一块代码的难度。决定到底应该重构还是重写,需要良好的判断力与丰富的经验,我无法给出一条简单的建议。
2.5 重构的挑战
每当有人大力推荐一种技术、工具或者架构时,我总是会观察这东西会遇到哪些挑战,毕竟生活中很少有晴空万里的好事。你需要了解一件事背后的权衡取舍,才能决定何时何地应用它。我认为重构是一种很有价值的技术,大多数团队都应该更多地重构,但它也不是完全没有挑战的。有必要充分了解重构会遇到的挑战,这样才能做出有效应对。
延缓新功能开发
如果你读了前面一小节,我对这个挑战的回应便已经很清楚了。尽管重构的目的是加快开发速度,但是,仍旧很多人认为,花在重构的时间是在拖慢新功能的开发进度。“重构会拖慢进度”这种看法仍然很普遍,这可能是导致人们没有充分重构的最大阻力所在。
Tip
重构的唯一目的就是让我们开发更快,用更少的工作量创造更大的价值。
有一种情况确实需要权衡取舍。我有时会看到一个(大规模的)重构很有必要进行,而马上要添加的功能非常小,这时我会更愿意先把新功能加上,然后再做这次大规模重构。做这个决定需要判断力——这是我作为程序员的专业能力之一。我很难描述决定的过程,更无法量化决定的依据。
我清楚地知道,预备性重构常会使修改更容易,所以如果做一点儿重构能让新功能实现更容易,我一定会做。如果一个问题我已经见过,此时我也会更倾向于重构它——有时我就得先看见一块丑陋的代码几次,然后才能提起劲头来重构它。也就是说,如果一块代码我很少触碰,它不会经常给我带来麻烦,那么我就倾向于不去重构它。如果我还没想清楚究竟应该如何优化代码,那么我可能会延迟重构;当然,有的时候,即便没想清楚优化的方向,我也会先做些实验,试试看能否有所改进。
我从同事那里听到的证据表明,在我们这个行业里,重构不足的情况远多于重构过度的情况。换句话说,绝大多数人应该尝试多做重构。代码库的健康与否,到底会对生产率造成多大的影响,很多人可能说不出来,因为他们没有太多在健康的代码库上工作的经历——轻松地把现有代码组合配置,快速构造出复杂的新功能,这种强大的开发方式他们没有体验过。
虽然我们经常批评管理者以“保障开发速度”的名义压制重构,其实程序员自己也经常这么干。有时他们自己觉得不应该重构,其实他们的领导还挺希望他们做一些重构的。如果你是一支团队的技术领导,一定要向团队成员表明,你重视改善代码库健康的价值。合理判断何时应该重构、何时应该暂时不重构,这样的判断力需要多年经验积累。对于重构缺乏经验的年轻人需要有意的指导,才能帮助他们加速经验积累的过程。
有些人试图用“整洁的代码”“良好的工程实践”之类道德理由来论证重构的必要性,我认为这是个陷阱。重构的意义不在于把代码库打磨得闪闪发光,而是纯粹经济角度出发的考量。我们之所以重构,因为它能让我们更快——添加功能更快,修复 bug 更快。一定要随时记住这一点,与别人交流时也要不断强调这一点。重构应该总是由经济利益驱动。程序员、经理和客户越理解这一点,“好的设计”那条曲线就会越经常出现。
代码所有权
很多重构手法不仅会影响一个模块内部,还会影响该模块与系统其他部分的关系。比如我想给一个函数改名,并且我也能找到该函数的所有调用者,那么我只需运用改变函数声明(124),在一次重构中修改函数声明和调用者。但即便这么简单的一个重构,有时也无法实施:调用方代码可能由另一支团队拥有,而我没有权限写入他们的代码库;这个函数可能是一个提供给客户的 API,这时我根本无法知道是否有人使用它,至于谁在用、用得有多频繁就更是一无所知。这样的函数属于已发布接口(published interface):接口的使用者(客户端)与声明者彼此独立,声明者无权修改使用者的代码。
代码所有权的边界会妨碍重构,因为一旦我自作主张地修改,就一定会破坏使用者的程序。这不会完全阻止重构,我仍然可以做很多重构,但确实会对重构造成约束。为了给一个函数改名,我需要使用函数改名(124),但同时也得保留原来的函数声明,使其把调用传递给新的函数。这会让接口变复杂,但这就是为了避免破坏使用者的系统而不得不付出的代价。我可以把旧的接口标记为“不推荐使用”(deprecated),等一段时间之后最终让其退休;但有些时候,旧的接口必须一直保留下去。
由于这些复杂性,我建议不要搞细粒度的强代码所有制。有些组织喜欢给每段代码都指定唯一的所有者,只有这个人能修改这段代码。我曾经见过一支只有三个人的团队以这种方式运作,每个程序员都要给另外两人发布接口,随之而来的就是接口维护的种种麻烦。如果这三个人都直接去代码库里做修改,事情会简单得多。我推荐团队代码所有制,这样一支团队里的成员都可以修改这个团队拥有的代码,即便最初写代码的是别人。程序员可能各自分工负责系统的不同区域,但这种责任应该体现为监控自己责任区内发生的修改,而不是简单粗暴地禁止别人修改。
这种较为宽容的代码所有制甚至可以应用于跨团队的场合。有些团队鼓励类似于开源的模型:B 团队的成员也可以在一个分支上修改 A 团队的代码,然后把提交发送给 A 团队去审核。这样一来,如果团队想修改自己的函数,他们就可以同时修改该函数的客户端的代码;只要客户端接受了他们的修改,就可以删掉旧的函数声明了。对于涉及多个团队的大系统开发,在“强代码所有制”和“混乱修改”两个极端之间,这种类似开源的模式常常是一个合适的折中。
分支
很多团队采用这样的版本控制实践:每个团队成员各自在代码库的一条分支上工作,进行相当大量的开发之后,才把各自的修改合并回主线分支(这条分支通常叫 master 或 trunk),从而与整个团队分享。常见的做法是在分支上开发完整的功能,直到功能可以发布到生产环境,才把该分支合并回主线。这种做法的拥趸声称,这样能保持主线不受尚未完成的代码侵扰,能保留清晰的功能添加的版本记录,并且在某个功能出问题时能容易地撤销修改。
这样的特性分支有其缺点。在隔离的分支上工作得越久,将完成的工作集成(integrate)回主线就会越困难。为了减轻集成的痛苦,大多数人的办法是频繁地从主线合并(merge)或者变基(rebase)到分支。但如果有几个人同时在各自的特性分支上工作,这个办法并不能真正解决问题,因为合并与集成是两回事。如果我从主线合并到我的分支,这只是一个单向的代码移动——我的分支发生了修改,但主线并没有。而“集成”是一个双向的过程:不仅要把主线的修改拉(pull)到我的分支上,而且要把我这里修改的结果推(push)回到主线上,两边都会发生修改。假如另一名程序员 Rachel 正在她的分支上开发,我是看不见她的修改的,直到她将自己的修改与主线集成;此时我就必须把她的修改合并到我的特性分支,这可能需要相当的工作量。其中困难的部分是处理语义变化。现代版本控制系统都能很好地合并程序文本的复杂修改,但对于代码的语义它们一无所知。如果我修改了一个函数的名字,版本控制工具可以很轻松地将我的修改与 Rachel 的代码集成。但如果在集成之前,她在自己的分支里新添调用了这个被我改名的函数,集成之后的代码就会被破坏。
分支合并本来就是一个复杂的问题,随着特性分支存在的时间加长,合并的难度会指数上升。集成一个已经存在了 4 个星期的分支,较之集成存在了 2 个星期的分支,难度可不止翻倍。所以很多人认为,应该尽量缩短特性分支的生存周期,比如只有一两天。还有一些人(比如我本人)认为特性分支的生命还应该更短,我们采用的方法叫作持续集成(Continuous Integration,CI),也叫“基于主干开发”(Trunk-Based Development)。在使用 CI 时,每个团队成员每天至少向主线集成一次。这个实践避免了任何分支彼此差异太大,从而极大地降低了合并的难度。不过 CI 也有其代价:你必须使用相关的实践以确保主线随时处于健康状态,必须学会将大功能拆分成小块,还必须使用特性开关(feature toggle,也叫特性旗标,feature flag)将尚未完成又无法拆小的功能隐藏掉。
CI 的粉丝之所以喜欢这种工作方式,部分原因是它降低了分支合并的难度,不过最重要的原因还是 CI 与重构能良好配合。重构经常需要对代码库中的很多地方做很小的修改(例如给一个广泛使用的函数改名),这样的修改尤其容易造成合并时的语义冲突。采用特性分支的团队常会发现重构加剧了分支合并的困难,并因此放弃了重构,这种情况我们曾经见过多次。CI 和重构能够良好配合,所以 Kent Beck 在极限编程中同时包含了这两个实践。
我并不是在说绝不应该使用特性分支。如果特性分支存在的时间足够短,它们就不会造成大问题。(实际上,使用 CI 的团队往往同时也使用分支,但他们会每天将分支与主线合并。)对于开源项目,特性分支可能是合适的做法,因为不时会有你不熟悉(因此也不信任)的程序员偶尔提交修改。但对全职的开发团队而言,特性分支对重构的阻碍太严重了。即便你没有完全采用 CI,我也一定会催促你尽可能频繁地集成。而且,用上 CI 的团队在软件交付上更加高效,我真心希望你认真考虑这个客观事实[Forsgren et al]。
测试
不会改变程序可观察的行为,这是重构的一个重要特征。如果仔细遵循重构手法的每个步骤,我应该不会破坏任何东西,但万一我犯了个错误怎么办?(呃,就我这个粗心大意的性格来说,请去掉“万一”两字。)人总会有出错的时候,不过只要及时发现,就不会造成大问题。既然每个重构都是很小的修改,即便真的造成了破坏,我也只需要检查最后一步的小修改——就算找不到出错的原因,只要回滚到版本控制中最后一个可用的版本就行了。
这里的关键就在于“快速发现错误”。要做到这一点,我的代码应该有一套完备的测试套件,并且运行速度要快,否则我会不愿意频繁运行它。也就是说,绝大多数情况下,如果想要重构,我得先有可以自测试的代码[mf-stc]。
有些读者可能会觉得,“自测试的代码”这个要求太高,根本无法实现。但在过去 20 年中,我看到很多团队以这种方式构造软件。的确,团队必须投入时间与精力在测试上,但收益是绝对划算的。自测试的代码不仅使重构成为可能,而且使添加新功能更加安全,因为我可以很快发现并干掉新近引入的 bug。这里的关键在于,一旦测试失败,我只需要查看上次测试成功运行之后修改的这部分代码;如果测试运行得很频繁,这个查看的范围就只有几行代码。知道必定是这几行代码造成 bug 的话,排查起来会容易得多。
这也回答了“重构风险太大,可能引入 bug”的担忧。如果没有自测试的代码,这种担忧就是完全合理的,这也是为什么我如此重视可靠的测试。
缺乏测试的问题可以用另一种方式来解决。如果我的开发环境很好地支持自动化重构,我就可以信任这些重构,不必运行测试。这时即便没有完备的测试套件,我仍然可以重构,前提是仅仅使用那些自动化的、一定安全的重构手法。这会让我损失很多好用的重构手法,不过剩下可用的也不少,我还是能从中获益。当然,我还是更愿意有自测试的代码,但如果没有,自动化重构的工具包也很好。
缺乏测试的现状还催生了另一种重构的流派:只使用一组经过验证是安全的重构手法。这个流派要求严格遵循重构的每个步骤,并且可用的重构手法是特定于语言的。使用这种方法,团队得以在测试覆盖率很低的大型代码库上开展一些有用的重构。这个重构流派比较新,涉及一些很具体、特定于编程语言的技巧与做法,行业里对这种方法的介绍和了解都还不足,因此本书不对其多做介绍。(不过我希望未来在我自己的网站上多讨论这个主题。感兴趣的读者可以查看 Jay Bazuzi 关于如何在 C++中安全地运用提炼函数(106)的描述[Bazuzi],借此获得一点儿对这个重构流派的了解。)
毫不意外,自测试代码与持续集成紧密相关——我们仰赖持续集成来及时捕获分支集成时的语义冲突。自测试代码是极限编程的另一个重要组成部分,也是持续交付的关键环节。
遗留代码
大多数人会觉得,有一大笔遗产是件好事,但从程序员的角度来看就不同了。遗留代码往往很复杂,测试又不足,而且最关键的是,是别人写的(瑟瑟发抖)。
重构可以很好地帮助我们理解遗留系统。引人误解的函数名可以改名,使其更好地反映代码用途;糟糕的程序结构可以慢慢理顺,把程序从一块顽石打磨成美玉。整个故事都很棒,但我们绕不开关底的恶龙:遗留系统多半没测试。如果你面对一个庞大而又缺乏测试的遗留系统,很难安全地重构清理它。
对于这个问题,显而易见的答案是“没测试就加测试”。这事听起来简单(当然工作量必定很大),操作起来可没那么容易。一般来说,只有在设计系统时就考虑到了测试,这样的系统才容易添加测试——可要是如此,系统早该有测试了,我也不用操这份心了。
这个问题没有简单的解决办法,我能给出的最好建议就是买一本《修改代码的艺术》[Feathers],照书里的指导来做。别担心那本书太老,尽管已经出版十多年,其中的建议仍然管用。一言以蔽之,它建议你先找到程序的接缝,在接缝处插入测试,如此将系统置于测试覆盖之下。你需要运用重构手法创造出接缝——这样的重构很危险,因为没有测试覆盖,但这是为了取得进展必要的风险。在这种情况下,安全的自动化重构简直就是天赐福音。如果这一切听起来很困难,因为它确实很困难。很遗憾,一旦跌进这个深坑,没有爬出来的捷径,这也是我强烈倡导从一开始就写能自测试的代码的原因。
就算有了测试,我也不建议你尝试一鼓作气把复杂而混乱的遗留代码重构成漂亮的代码。我更愿意随时重构相关的代码:每次触碰一块代码时,我会尝试把它变好一点点——至少要让营地比我到达时更干净。如果是一个大系统,越是频繁使用的代码,改善其可理解性的努力就能得到越丰厚的回报。
数据库
在本书的第 1 版中,我说过数据库是“重构经常出问题的一个领域”。然而在第 1 版问世之后仅仅一年,情况就发生了改变:我的同事 Pramod Sadalage 发展出一套渐进式数据库设计[mf-evodb]和数据库重构[Ambler & Sadalage]的办法,如今已经被广泛使用。这项技术的精要在于:借助数据迁移脚本,将数据库结构的修改与代码相结合,使大规模的、涉及数据库的修改可以比较容易地开展。
假设我们要对一个数据库字段(列)改名。和改变函数声明(124)一样,我要找出结构的声明处和所有调用处,然后一次完成所有修改。但这里的复杂之处在于,原来基于旧字段的数据,也要转为使用新字段。我会写一小段代码来执行数据转化的逻辑,并把这段代码放进版本控制,跟数据结构声明与使用代码的修改一并提交。此后如果我想把数据库迁移到某个版本,只要执行当前数据库版本与目标版本之间的所有迁移脚本即可。
跟通常的重构一样,数据库重构的关键也是小步修改并且每次修改都应该完整,这样每次迁移之后系统仍然能运行。由于每次迁移涉及的修改都很小,写起来应该容易;将多个迁移串联起来,就能对数据库结构及其中存储的数据做很大的调整。
与常规的重构不同,很多时候,数据库重构最好是分散到多次生产发布来完成,这样即便某次修改在生产数据库上造成了问题,也比较容易回滚。比如,要改名一个字段,我的第一次提交会新添一个字段,但暂时不使用它。然后我会修改数据写入的逻辑,使其同时写入新旧两个字段。随后我就可以修改读取数据的地方,将它们逐个改为使用新字段。这步修改完成之后,我会暂停一小段时间,看看是否有 bug 冒出来。确定没有 bug 之后,我再删除已经没人使用的旧字段。这种修改数据库的方式是并行修改(Parallel Change,也叫扩展协议/expand-contract)[mf-pc]的一个实例。
2.6 重构、架构和 YAGNI
重构极大地改变了人们考虑软件架构的方式。在我的职业生涯早期,我被告知:在任何人开始写代码之前,必须先完成软件的设计和架构。一旦代码写出来,架构就固定了,只会因为程序员的草率对待而逐渐腐败。
重构改变了这种观点。有了重构技术,即便是已经在生产环境中运行了多年的软件,我们也有能力大幅度修改其架构。正如本书的副标题所指出的,重构可以改善既有代码的设计。但我在前面也提到了,修改遗留代码经常很有挑战,尤其当遗留代码缺乏恰当的测试时。
重构对架构最大的影响在于,通过重构,我们能得到一个设计良好的代码库,使其能够优雅地应对不断变化的需求。“在编码之前先完成架构”这种做法最大的问题在于,它假设了软件的需求可以预先充分理解。但经验显示,这个假设很多时候甚至可以说大多数时候是不切实际的。只有真正使用了软件、看到了软件对工作的影响,人们才会想明白自己到底需要什么,这样的例子不胜枚举。
应对未来变化的办法之一,就是在软件里植入灵活性机制。在编写一个函数时,我会考虑它是否有更通用的用途。为了应对我预期的应用场景,我预测可以给这个函数加上十多个参数。这些参数就是灵活性机制——跟大多数“机制”一样,它不是免费午餐。把所有这些参数都加上的话,函数在当前的使用场景下就会非常复杂。另外,如果我少考虑了一个参数,已经加上的这一堆参数会使新添参数更麻烦。而且我经常会把灵活性机制弄错——可能是未来的需求变更并非以我期望的方式发生,也可能我对机制的设计不好。考虑到所有这些因素,很多时候这些灵活性机制反而拖慢了我响应变化的速度。
有了重构技术,我就可以采取不同的策略。与其猜测未来需要哪些灵活性、需要什么机制来提供灵活性,我更愿意只根据当前的需求来构造软件,同时把软件的设计质量做得很高。随着对用户需求的理解加深,我会对架构进行重构,使其能够应对新的需要。如果一种灵活性机制不会增加复杂度(比如添加几个命名良好的小函数),我可以很开心地引入它;但如果一种灵活性会增加软件复杂度,就必须先证明自己值得被引入。如果不同的调用者不会传入不同的参数值,那么就不要添加这个参数。当真的需要添加这个参数时,运用函数参数化(310)也很容易。要判断是否应该为未来的变化添加灵活性,我会评估“如果以后再重构有多困难”,只有当未来重构会很困难时,我才考虑现在就添加灵活性机制。我发现这是一个很有用的决策方法。
这种设计方法有很多名字:简单设计、增量式设计或者 YAGNI[mf-yagni]——“你不会需要它”(you arenʼt going to need it)的缩写。YAGNI 并不是“不做架构性思考”的意思,不过确实有人以这种欠考虑的方式做事。我把 YAGNI 视为将架构、设计与开发过程融合的一种工作方式,这种工作方式必须有重构作为基础才可靠。
采用 YAGNI 并不表示完全不用预先考虑架构。总有一些时候,如果缺少预先的思考,重构会难以开展。但两者之间的平衡点已经发生了很大的改变:如今我更倾向于等一等,待到对问题理解更充分,再来着手解决。演进式架构[Ford et al.]是一门仍在不断发展的学科,架构师们在不断探索有用的模式和实践,充分发挥迭代式架构决策的能力。
2.7 重构与软件开发过程
读完前面“重构的挑战”一节,你大概已经有这个印象:重构是否有效,与团队采用的其他软件开发实践紧密相关。重构起初是作为极限编程(XP)[mf-xp]的一部分被人们采用的,XP 本身就融合了一组不太常见而又彼此关联的实践,例如持续集成、自测试代码以及重构(后两者融汇成了测试驱动开发)。
极限编程是最早的敏捷软件开发方法[mf-nm]之一。在一段历史时期,极限编程引领了敏捷的崛起。如今已经有很多项目使用敏捷方法,甚至敏捷的思维已经被视为主流,但实际上大部分“敏捷”项目只是徒有其名。要真正以敏捷的方式运作项目,团队成员必须在重构上有能力、有热情,他们采用的开发过程必须与常规的、持续的重构相匹配。
重构的第一块基石是自测试代码。我应该有一套自动化的测试,我可以频繁地运行它们,并且我有信心:如果我在编程过程中犯了任何错误,会有测试失败。这块基石如此重要,我会专门用一章篇幅来讨论它。
如果一支团队想要重构,那么每个团队成员都需要掌握重构技能,能在需要时开展重构,而不会干扰其他人的工作。这也是我鼓励持续集成的原因:有了 CI,每个成员的重构都能快速分享给其他同事,不会发生这边在调用一个接口那边却已把这个接口删掉的情况;如果一次重构会影响别人的工作,我们很快就会知道。自测试的代码也是持续集成的关键环节,所以这三大实践——自测试代码、持续集成、重构——彼此之间有着很强的协同效应。
有这三大实践在手,我们就能运用前一节介绍的 YAGNI 设计方法。重构和 YAGNI 交相呼应、彼此增效,重构(及其前置实践)是 YAGNI 的基础,YAGNI 又让重构更易于开展:比起一个塞满了想当然的灵活性的系统,当然是修改一个简单的系统要容易得多。在这些实践之间找到合适的平衡点,你就能进入良性循环,你的代码既牢固可靠又能快速响应变化的需求。
有这三大核心实践打下的基础,才谈得上运用敏捷思想的其他部分。持续交付确保软件始终处于可发布的状态,很多互联网团队能做到一天多次发布,靠的正是持续交付的威力。即便我们不需要如此频繁的发布,持续集成也能帮我们降低风险,并使我们做到根据业务需要随时安排发布,而不受技术的局限。有了可靠的技术根基,我们能够极大地压缩“从好点子到生产代码”的周期时间,从而更好地服务客户。这些技术实践也会增加软件的可靠性,减少耗费在 bug 上的时间。
这一切说起来似乎很简单,但实际做起来毫不容易。不管采用什么方法,软件开发都是一件复杂而微妙的事,涉及人与人之间、人与机器之间的复杂交互。我在这里描述的方法已经被证明可以应对这些复杂性,但——就跟其他所有方法一样——对使用者的实践和技能有要求。
2.8 重构与性能
关于重构,有一个常被提出的问题:它对程序的性能将造成怎样的影响?为了让软件易于理解,我常会做出一些使程序运行变慢的修改。这是一个重要的问题。我并不赞成为了提高设计的纯洁性而忽视性能,把希望寄托于更快的硬件身上也绝非正道。已经有很多软件因为速度太慢而被用户拒绝,日益提高的机器速度也只不过略微放宽了速度方面的限制而已。但是,换个角度说,虽然重构可能使软件运行更慢,但它也使软件的性能优化更容易。除了对性能有严格要求的实时系统,其他任何情况下“编写快速软件”的秘密就是:先写出可调优的软件,然后调优它以求获得足够的速度。
我看过 3 种编写快速软件的方法。其中最严格的是时间预算法,这通常只用于性能要求极高的实时系统。如果使用这种方法,分解你的设计时就要做好预算,给每个组件预先分配一定资源,包括时间和空间占用。每个组件绝对不能超出自己的预算,就算拥有组件之间调度预配时间的机制也不行。这种方法高度重视性能,对于心律调节器一类的系统是必需的,因为在这样的系统中迟来的数据就是错误的数据。但对其他系统(例如我经常开发的企业信息系统)而言,如此追求高性能就有点儿过分了。
第二种方法是持续关注法。这种方法要求任何程序员在任何时间做任何事时,都要设法保持系统的高性能。这种方式很常见,感觉上很有吸引力,但通常不会起太大作用。任何修改如果是为了提高性能,通常会使程序难以维护,继而减缓开发速度。如果最终得到的软件的确更快了,那么这点损失尚有所值,可惜通常事与愿违,因为性能改善一旦被分散到程序各个角落,每次改善都只不过是从对程序行为的一个狭隘视角出发而已,而且常常伴随着对编译器、运行时环境和硬件行为的误解。
Tip
劳而无获
克莱斯勒综合薪资系统的支付过程太慢了。虽然我们的开发还没结束,这个问题却已经开始困扰我们,因为它已经拖累了测试速度。
Kent Beck、Martin Fowler 和我决定解决这个问题。等待大伙儿会合的时间里,凭着对这个系统的全盘了解,我开始推测:到底是什么让系统变慢了?我想到数种可能,然后和伙伴们谈了几种可能的修改方案。最后,我们就“如何让这个系统运行更快”,提出了一些真正的好点子。
然后,我们拿 Kent 的工具度量了系统性能。我一开始所想的可能性竟然全都不是问题肇因。我们发现:系统把一半时间用来创建“日期”实例(instance)。更有趣的是,所有这些实例都有相同的几个值。
于是我们观察日期对象的创建逻辑,发现有机会将它优化。这些日期对象在创建时都经过了一个字符串转换过程,然而这里并没有任何外部数据输入。之所以使用字符串转换方式,完全只是因为代码写起来简单。好,也许我们可以优化它。
然后,我们观察这些日期对象是如何被使用的。我们发现,很多日期对象都被用来产生“日期区间”实例——由一个起始日期和一个结束日期组成的对象。仔细追踪下去,我们发现绝大多数日期区间是空的!
处理日期区间时我们遵循这样一个规则:如果结束日期在起始日期之前,这个日期区间就该是空的。这是一条很好的规则,完全符合这个类的需要。采用此规则后不久,我们意识到,创建一个“起始日期在结束日期之后”的日期区间,仍然不算是清晰的代码,于是我们把这个行为提炼成一个工厂函数,由它专门创建“空的日期区间”。
我们做了上述修改,使代码更加清晰,也意外得到了一个惊喜:可以创建一个固定不变的“空日期区间”对象,并让上述调整后的工厂函数始终返回该对象,而不再每次都创建新对象。这一修改把系统速度提升了几乎一倍,足以让测试速度达到可接受的程度。这只花了我们大约五分钟。
我和团队成员(Kent 和 Martin 谢绝参加)认真推测过:我们了若指掌的这个程序中可能有什么错误?我们甚至凭空做了些改进设计,却没有先对系统的真实情况进行度量。
我们完全错了。除了一场很有趣的交谈,我们什么好事都没做。
教训是:哪怕你完全了解系统,也请实际度量它的性能,不要臆测。臆测会让你学到一些东西,但十有八九你是错的。
——Ron Jeffries
关于性能,一件很有趣的事情是:如果你对大多数程序进行分析,就会发现它把大半时间都耗费在一小半代码身上。如果你一视同仁地优化所有代码,90%的优化工作都是白费劲的,因为被你优化的代码大多很少被执行。你花时间做优化是为了让程序运行更快,但如果因为缺乏对程序的清楚认识而花费时间,那些时间就都被浪费掉了。
第三种性能提升法就是利用上述的 90%统计数据。采用这种方法时,我编写构造良好的程序,不对性能投以特别的关注,直至进入性能优化阶段——那通常是在开发后期。一旦进入该阶段,我再遵循特定的流程来调优程序性能。
在性能优化阶段,我首先应该用一个度量工具来监控程序的运行,让它告诉我程序中哪些地方大量消耗时间和空间。这样我就可以找出性能热点所在的一小段代码。然后我应该集中关注这些性能热点,并使用持续关注法中的优化手段来优化它们。由于把注意力都集中在热点上,较少的工作量便可显现较好的成果。即便如此,我还是必须保持谨慎。和重构一样,我会小幅度进行修改。每走一步都需要编译、测试,再次度量。如果没能提高性能,就应该撤销此次修改。我会继续这个“发现热点,去除热点”的过程,直到获得客户满意的性能为止。
一个构造良好的程序可从两方面帮助这一优化方式。首先,它让我有比较充裕的时间进行性能调整,因为有构造良好的代码在手,我能够更快速地添加功能,也就有更多时间用在性能问题上(准确的度量则保证我把这些时间投在恰当地点)。其次,面对构造良好的程序,我在进行性能分析时便有较细的粒度。度量工具会把我带入范围较小的代码段中,而性能的调整也比较容易些。由于代码更加清晰,因此我能够更好地理解自己的选择,更清楚哪种调整起关键作用。
我发现重构可以帮助我写出更快的软件。短期看来,重构的确可能使软件变慢,但它使优化阶段的软件性能调优更容易,最终还是会得到好的效果。
2.9 重构起源何处
我曾经努力想找出“重构”(refactoring)一词的真正起源,但最终失败了。优秀程序员肯定至少会花一些时间来清理自己的代码。这么做是因为,他们知道整洁的代码比杂乱无章的代码更容易修改,而且他们知道自己几乎无法一开始就写出整洁的代码。
重构不止如此。本书中我把重构看作整个软件开发过程的一个关键环节。最早认识重构重要性的两个人是 Ward Cunningham 和 Kent Beck,他们早在 20 世纪 80 年代就开始使用 Smalltalk,那是一个特别适合重构的环境。Smalltalk 是一个十分动态的环境,用它可以很快写出功能丰富的软件。Smalltalk 的“编译-链接-执行”周期非常短,因此很容易快速修改代码——要知道,当时很多编程环境做一次编译就需要整晚时间。它支持面向对象,也有强大的工具,最大限度地将修改的影响隐藏于定义良好的接口背后。Ward 和 Kent 努力探索出一套适合这类环境的软件开发过程(如今,Kent 把这种风格叫作极限编程)。他们意识到:重构对于提高生产力非常重要。从那时起他们就一直在工作中运用重构技术,在正式的软件项目中使用它,并不断精炼重构的过程。
Ward 和 Kent 的思想对 Smalltalk 社区产生了极大影响,重构概念也成为 Smalltalk 文化中的一个重要元素。Smalltalk 社区的另一位领袖是 Ralph Johnson,伊利诺伊大学厄巴纳-香槟分校教授,著名的 GoF[gof]之一。Ralph 最大的兴趣之一就是开发软件框架。他揭示了重构有助于灵活高效框架的开发。
Bill Opdyke 是 Ralph 的博士研究生,对框架也很感兴趣。他看到了重构的潜在价值,并看到重构应用于 Smalltalk 之外的其他语言的可能性。他的技术背景是电话交换系统的开发。在这种系统中,大量的复杂情况与日俱增,而且非常难以修改。Bill 的博士研究就是从工具构筑者的角度来看待重构。Bill 对 C++的框架开发中用得上的重构手法特别感兴趣。他也研究了极有必要的“语义保持的重构” (semantics-preserving refactoring),并阐明了如何证明这些重构是语义保持的,以及如何用工具实现重构。Bill 的博士论文[Opdyke]是重构领域中第一部丰硕的研究成果。
我还记得 1992 年 OOPSLA 大会上见到 Bill 的情景。我们坐在一间咖啡厅里,Bill 跟我谈起他的研究成果,我还记得自己当时的想法:“有趣,但并非真的那么重要。”唉,我完全错了。
John Brant 和 Don Roberts 将“重构工具”的构想发扬光大,开发了一个名为 Refactoring Browser (重构浏览器)的重构工具。这是第一个自动化的重构工具,多亏 Smalltalk 提供了适合重构的编程环境。
那么,我呢?我一直有清理代码的倾向,但从来没有想到这会如此重要。后来我和 Kent 一起做一个项目,看到他使用重构手法,也看到重构对开发效能和质量带来的影响。这份体验让我相信:重构是一门非常重要的技术。但是,在重构的学习和推广过程中我遇到了挫折,因为我拿不出任何一本书给程序员看,也没有任何一位专家打算写这样一本书。所以,在这些专家的帮助下,我写下了这本书的第 1 版。
幸运的是,重构的概念被行业广泛接受了。本书第 1 版销量不错,“重构”一词也走进了大多数程序员的词汇库。更多的重构工具涌现出来,尤其是在 Java 世界里。重构的流行也带来了负面效应:很多人随意地使用“重构”这个词,而他们真正做的却是不严谨的结构调整。尽管如此,重构终归成了一项主流的软件开发实践。
2.10 自动化重构
过去 10 年中,重构领域最大的变化可能就是出现了一批支持自动化重构的工具。如果我想给一个 Java 的方法改名,在 IntelliJ IDEA 或者 Eclipse 这样的开发环境中,我只需要从菜单里点选对应的选项,工具会帮我完成整个重构过程,而且我通常都可以相信,工具完成的重构是可靠的,所以用不着运行测试套件。
第一个自动化重构工具是 Smalltalk 的 Refactoring Browser,由 John Brandt 和 Don Roberts 开发。在 21 世纪初,Java 世界的自动化重构工具如雨后春笋般涌现。在 JetBrains 的 IntelliJ IDEA 集成开发环境(IDE)中,自动化重构是最亮眼的特性之一。IBM 也紧随其后,在 VisualAge 的 Java 版中也提供了重构工具。VisualAge 的影响力有限,不过其中很多能力后来被 Eclipse 继承,包括对重构的支持。
重构也进入了 C#世界,起初是通过 JetBrains 的 Resharper,这是一个 Visual Studio 插件。后来 Visual Studio 团队直接在 IDE 里提供了一些重构能力。
如今的编辑器和开发工具中常能找到一些对重构的支持,不过真实的重构能力各有高低。重构能力的差异既有工具的原因,也受限于不同语言对自动化重构的支持程度。在这里,我不打算分析各种工具的能力,不过谈谈重构工具背后的原则还是有点儿意思的。
一种粗糙的自动化重构方式是文本操作,比如用查找/替换的方式给函数改名,或者完成提炼变量(119)所需的简单结构调整。这种方法太粗糙了,做完之后必须重新运行测试,否则不能信任。但这可以是一个便捷的起步。在用 Emacs 编程时,没有那些更完善的重构支持,我也会用类似的文本操作宏来加速重构。
要支持体面的重构,工具只操作代码文本是不行的,必须操作代码的语法树,这样才能更可靠地保持代码行为。所以,今天的大多数重构功能都依附于强大的 IDE,因为这些 IDE 原本就在语法树上实现了代码导航、静态检查等功能,自然也可以用于重构。不仅能处理文本,还能处理语法树,这是 IDE 相比于文本编辑器更先进的地方。
重构工具不仅需要理解和修改语法树,还要知道如何把修改后的代码写回编辑器视图。总而言之,实现一个体面的自动化重构手法,是一个很有挑战的编程任务。尽管我一直开心地使用重构工具,对它们背后的实现却知之甚少。
在静态类型语言中,很多重构手法会更加安全。假设我想做一次简单的函数改名(124):在 Salesman 类和 Server 类中都有一个叫作 addClient 的函数,当然两者各有其用途。我想对 Salesman 中的 addClient 函数改名,Server 类中的函数则保持不变。如果不是静态类型,工具很难识别调用 addClient 的地方到底是在使用哪个类的函数。Smalltalk 的 Refactoring Browser 会列出所有调用点,我需要手工决定修改哪些调用点。这个重构是不安全的,我必须重新运行所有测试。这样的工具仍然有用,但在 Java 中的函数改名(124)重构则可以是完全安全、完全自动的,因为在静态类型的帮助下,工具可以识别函数所属的类,所以它只会修改应该修改的那些函数调用点,对此我可以完全放心。
一些重构工具走得更远。如果我给一个变量改名,工具会提醒我修改使用了旧名字的注释。如果我使用提炼函数(106),工具会找出与新函数体重复的代码片段,建议代之以对新函数的调用。在编程时可以使用如此强大的重构功能,这就是为什么我们要使用一个体面的 IDE,而不是固执于熟悉的文本编辑器。我个人很喜欢用 Emacs,但在使用 Java 时,我更愿意用 IntelliJ IDEA 或者 Eclipse,很大程度上就是为了获得重构支持。
尽管这些强大的重构工具有着魔法般的能力,可以安全地重构代码,但还是会有闪失出现。通过反射进行的调用(例如 Java 中的 Method.invoke)会迷惑不够成熟的重构工具,但比较成熟的工具则可以很好地应对。所以,即便是最安全的重构,也应该经常运行测试套件,以确保没有什么东西在不经意间被破坏。我经常会间杂进行自动重构和手动重构,所以运行测试的频度是足够的。
能借助语法树来分析和重构程序代码,这是 IDE 与普通文本编辑器相比具有的一大优势。但很多程序员又喜欢用得顺手的文本编辑器的灵活性,希望鱼与熊掌兼得。语言服务器(Language Server)是一种正在引起关注的新技术:用软件生成语法树,给文本编辑器提供 API。语言服务器可以支持多种文本编辑器,并且为强大的代码分析和重构操作提供了命令。
2.11 延展阅读
在第 2 章就开始谈延展阅读,这似乎有点儿奇怪。不过,有大量关于重构的材料已经超出了本书的范围,早些让读者知道这些材料的存在也是件好事。
本书的第 1 版教很多人学会了重构,不过我的关注点是组织一本重构的参考书,而不是带领读者走过学习过程。如果你需要一本面向入门者的教材,我推荐 Bill Wake 的《重构手册》[Wake],其中包含了很多有用的重构练习。
很多重构的先行者同时也活跃于软件模式社区。Josh Kerievsky 在《重构与模式》[Kerievsky]一书中紧密连接了这两个世界。他审视了影响巨大的 GoF[gof]书中一些最有价值的模式,并展示了如何通过重构使代码向这些模式的方向演化。
本书聚焦讨论通用编程语言中的重构技巧。还有一些专门领域的重构,例如已经引起关注的《数据库重构》[Ambler & Sadalage](由 Scott Ambler 和 Pramod Sadalage 所著)和《重构 HTML》[Harold](由 Elliotte Rusty Harold 所著)。
尽管标题中没有“重构”二字,Michael Feathers 的《修改代码的艺术》[Feathers]也不得不提。这本书主要讨论如何在缺乏测试覆盖的老旧代码库上开展重构。
本书(及其前一版)对读者的编程语言背景没有要求。也有人写专门针对特定语言的重构书籍。我的两位前同事 Jay Fields 和 Shane Harvey 就撰写了 Ruby 版的《重构》[Fields et al.]。
在本书的 Web 版和重构网站(refactoring.com)[ref.com]上都可以找到更多相关材料的更新。
第 3 章 代码的坏味道
——Kent Beck 和 Martin Fowler
“如果尿布臭了,就换掉它。”
——语出 Beck 奶奶,论保持小孩清洁的哲学
现在,对于重构如何运作,你已经有了相当好的理解。但是知道“如何”不代表知道“何时”。决定何时重构及何时停止和知道重构机制如何运转一样重要。
难题来了!解释“如何删除一个实例变量”或“如何产生一个继承体系”很容易,因为这些都是很简单的事情,但要解释“该在什么时候做这些动作”就没那么顺理成章了。除了露几手含混的编程美学(说实话,这就是咱们这些顾问常做的事),我还希望让某些东西更具说服力一些。
撰写本书的第 1 版时,我正在为这个微妙的问题大伤脑筋。去苏黎世拜访 Kent Beck 的时候,也许是因为受到刚出生的女儿的气味影响吧,他提出用味道来形容重构的时机。
“味道,”你可能会说,“真的比含混的美学理论要好吗?”好吧,是的。我们看过很多很多代码,它们所属的项目从大获成功到奄奄一息都有。观察这些代码时,我们学会了从中找寻某些特定结构,这些结构指出(有时甚至就像尖叫呼喊)重构的可能性。(本章主语换成“我们”,是为了反映一个事实:Kent 和我共同撰写本章。你应该可以看出我俩的文笔差异——插科打诨的部分是我写的,其余都是他写的。)
我们并不试图给你一个何时必须重构的精确衡量标准。从我们的经验看来,没有任何量度规矩比得上见识广博者的直觉。我们只会告诉你一些迹象,它会指出“这里有一个可以用重构解决的问题”。你必须培养自己的判断力,学会判断一个类内有多少实例变量算是太大、一个函数内有多少行代码才算太长。
如果你无法确定该采用哪一种重构手法,请阅读本章内容和书后附的“重构列表”来寻找灵感。你可以阅读本章或快速浏览书后附的“坏味道与重构手法速查表”来判断自己闻到的是什么味道,然后再看看我们所建议的重构手法能否帮到你。也许这里所列的“坏味道条款”和你所检测的不尽相符,但愿它们能够为你指引正确方向。
3.1 神秘命名(Mysterious Name)
读侦探小说时,透过一些神秘的文字猜测故事情节是一种很棒的体验;但如果是在阅读代码,这样的体验就不怎么好了。我们也许会幻想自己是《王牌大贱谍》中的国际特工 1,但我们写下的代码应该直观明了。整洁代码最重要的一环就是好的名字,所以我们会深思熟虑如何给函数、模块、变量和类命名,使它们能清晰地表明自己的功能和用法。
然而,很遗憾,命名是编程中最难的两件事之一[mf-2h]。正因为如此,改名可能是最常用的重构手法,包括改变函数声明(124)(用于给函数改名)、变量改名(137)、字段改名(244)等。很多人经常不愿意给程序元素改名,觉得不值得费这个劲,但好的名字能节省未来用在猜谜上的大把时间。
改名不仅仅是修改名字而已。如果你想不出一个好名字,说明背后很可能潜藏着更深的设计问题。为一个恼人的名字所付出的纠结,常常能推动我们对代码进行精简。
1《王牌大贱谍》(International Man of Mystery)是 1997 年杰伊·罗奇执导的一部喜剧谍战片。——译者注
3.2 重复代码(Duplicated Code)
如果你在一个以上的地点看到相同的代码结构,那么可以肯定:设法将它们合而为一,程序会变得更好。一旦有重复代码存在,阅读这些重复的代码时你就必须加倍仔细,留意其间细微的差异。如果要修改重复代码,你必须找出所有的副本来修改。
最单纯的重复代码就是“同一个类的两个函数含有相同的表达式”。这时候你需要做的就是采用提炼函数(106)提炼出重复的代码,然后让这两个地点都调用被提炼出来的那一段代码。如果重复代码只是相似而不是完全相同,请首先尝试用移动语句(223)重组代码顺序,把相似的部分放在一起以便提炼。如果重复的代码段位于同一个超类的不同子类中,可以使用函数上移(350)来避免在两个子类之间互相调用。
3.3 过长函数(Long Function)
据我们的经验,活得最长、最好的程序,其中的函数都比较短。初次接触到这种代码库的程序员常常会觉得“计算都没有发生”——程序里满是无穷无尽的委托调用。但和这样的程序共处几年之后,你就会明白这些小函数的价值所在。间接性带来的好处——更好的阐释力、更易于分享、更多的选择——都是由小函数来支持的。
早在编程的洪荒年代,程序员们就已认识到:函数越长,就越难理解。在早期的编程语言中,子程序调用需要额外开销,这使得人们不太乐意使用小函数。现代编程语言几乎已经完全免除了进程内的函数调用开销。固然,小函数也会给代码的阅读者带来一些负担,因为你必须经常切换上下文,才能看明白函数在做什么。但现代的开发环境让你可以在函数的调用处与声明处之间快速跳转,或是同时看到这两处,让你根本不用来回跳转。不过说到底,让小函数易于理解的关键还是在于良好的命名。如果你能给函数起个好名字,阅读代码的人就可以通过名字了解函数的作用,根本不必去看其中写了些什么。
最终的效果是:你应该更积极地分解函数。我们遵循这样一条原则:每当感觉需要以注释来说明点什么的时候,我们就把需要说明的东西写进一个独立函数中,并以其用途(而非实现手法)命名。我们可以对一组甚至短短一行代码做这件事。哪怕替换后的函数调用动作比函数自身还长,只要函数名称能够解释其用途,我们也该毫不犹豫地那么做。关键不在于函数的长度,而在于函数“做什么”和“如何做”之间的语义距离。
百分之九十九的场合里,要把函数变短,只需使用提炼函数(106)。找到函数中适合集中在一起的部分,将它们提炼出来形成一个新函数。
如果函数内有大量的参数和临时变量,它们会对你的函数提炼形成阻碍。如果你尝试运用提炼函数(106),最终就会把许多参数传递给被提炼出来的新函数,导致可读性几乎没有任何提升。此时,你可以经常运用以查询取代临时变量(178)来消除这些临时元素。引入参数对象(140)和保持对象完整(319)则可以将过长的参数列表变得更简洁一些。
如果你已经这么做了,仍然有太多临时变量和参数,那就应该使出我们的杀手锏——以命令取代函数(337)。
如何确定该提炼哪一段代码呢?一个很好的技巧是:寻找注释。它们通常能指出代码用途和实现手法之间的语义距离。如果代码前方有一行注释,就是在提醒你:可以将这段代码替换成一个函数,而且可以在注释的基础上给这个函数命名。就算只有一行代码,如果它需要以注释来说明,那也值得将它提炼到独立函数中去。
条件表达式和循环常常也是提炼的信号。你可以使用分解条件表达式(260)处理条件表达式。对于庞大的 switch 语句,其中的每个分支都应该通过提炼函数(106)变成独立的函数调用。如果有多个 switch 语句基于同一个条件进行分支选择,就应该使用以多态取代条件表达式(272)。
至于循环,你应该将循环和循环内的代码提炼到一个独立的函数中。如果你发现提炼出的循环很难命名,可能是因为其中做了几件不同的事。如果是这种情况,请勇敢地使用拆分循环(227)将其拆分成各自独立的任务。
3.4 过长参数列表(Long Parameter List)
刚开始学习编程的时候,老师教我们:把函数所需的所有东西都以参数的形式传递进去。这可以理解,因为除此之外就只能选择全局数据,而全局数据很快就会变成邪恶的东西。但过长的参数列表本身也经常令人迷惑。
如果可以向某个参数发起查询而获得另一个参数的值,那么就可以使用以查询取代参数(324)去掉这第二个参数。如果你发现自己正在从现有的数据结构中抽出很多数据项,就可以考虑使用保持对象完整(319)手法,直接传入原来的数据结构。如果有几项参数总是同时出现,可以用引入参数对象(140)将其合并成一个对象。如果某个参数被用作区分函数行为的标记(flag),可以使用移除标记参数(314)。
使用类可以有效地缩短参数列表。如果多个函数有同样的几个参数,引入一个类就尤为有意义。你可以使用函数组合成类(144),将这些共同的参数变成这个类的字段。如果戴上函数式编程的帽子,我们会说,这个重构过程创造了一组部分应用函数(partially applied function)。
3.5 全局数据(Global Data)
刚开始学软件开发时,我们就听说过关于全局数据的惊悚故事——它们是如何被来自地狱第四层的恶魔发明出来,胆敢使用它们的程序员如今在何处安息。就算这些烈焰与硫黄的故事不那么可信,全局数据仍然是最刺鼻的坏味道之一。全局数据的问题在于,从代码库的任何一个角落都可以修改它,而且没有任何机制可以探测出到底哪段代码做出了修改。一次又一次,全局数据造成了那些诡异的 bug,而问题的根源却在遥远的别处,想要找到出错的代码难于登天。全局数据最显而易见的形式就是全局变量,但类变量和单例(singleton)也有这样的问题。
首要的防御手段是封装变量(132),每当我们看到可能被各处的代码污染的数据,这总是我们应对的第一招。你把全局数据用一个函数包装起来,至少你就能看见修改它的地方,并开始控制对它的访问。随后,最好将这个函数(及其封装的数据)搬移到一个类或模块中,只允许模块内的代码使用它,从而尽量控制其作用域。
可以被修改的全局数据尤其可憎。如果能保证在程序启动之后就不再修改,这样的全局数据还算相对安全,不过得有编程语言提供这样的保证才行。
全局数据印证了帕拉塞尔斯的格言:良药与毒药的区别在于剂量。有少量的全局数据或许无妨,但数量越多,处理的难度就会指数上升。即便只是少量的数据,我们也愿意将它封装起来,这是在软件演进过程中应对变化的关键所在。
3.6 可变数据(Mutable Data)
对数据的修改经常导致出乎意料的结果和难以发现的 bug。我在一处更新数据,却没有意识到软件中的另一处期望着完全不同的数据,于是一个功能失效了——如果故障只在很罕见的情况下发生,要找出故障原因就会更加困难。因此,有一整个软件开发流派——函数式编程——完全建立在“数据永不改变”的概念基础上:如果要更新一个数据结构,就返回一份新的数据副本,旧的数据仍保持不变。
不过这样的编程语言仍然相对小众,大多数程序员使用的编程语言还是允许修改变量值的。即便如此,我们也不应该忽视不可变性带来的优势——仍然有很多办法可以用于约束对数据的更新,降低其风险。
可以用封装变量(132)来确保所有数据更新操作都通过很少几个函数来进行,使其更容易监控和演进。如果一个变量在不同时候被用于存储不同的东西,可以使用拆分变量(240)将其拆分为各自不同用途的变量,从而避免危险的更新操作。使用移动语句(223)和提炼函数(106)尽量把逻辑从处理更新操作的代码中搬移出来,将没有副作用的代码与执行数据更新操作的代码分开。设计 API 时,可以使用将查询函数和修改函数分离(306)确保调用者不会调到有副作用的代码,除非他们真的需要更新数据。我们还乐于尽早使用移除设值函数(331)——有时只是把设值函数的使用者找出来看看,就能帮我们发现缩小变量作用域的机会。
如果可变数据的值能在其他地方计算出来,这就是一个特别刺鼻的坏味道。它不仅会造成困扰、bug 和加班,而且毫无必要。消除这种坏味道的办法很简单,使用以查询取代派生变量(248)即可。
如果变量作用域只有几行代码,即使其中的数据可变,也不是什么大问题;但随着变量作用域的扩展,风险也随之增大。可以用函数组合成类(144)或者函数组合成变换(149)来限制需要对变量进行修改的代码量。如果一个变量在其内部结构中包含了数据,通常最好不要直接修改其中的数据,而是用将引用对象改为值对象(252)令其直接替换整个数据结构。
3.7 发散式变化(Divergent Change)
我们希望软件能够更容易被修改——毕竟软件本来就该是“软”的。一旦需要修改,我们希望能够跳到系统的某一点,只在该处做修改。如果不能做到这一点,你就嗅出两种紧密相关的刺鼻味道中的一种了。
如果某个模块经常因为不同的原因在不同的方向上发生变化,发散式变化就出现了。当你看着一个类说:“呃,如果新加入一个数据库,我必须修改这 3 个函数;如果新出现一种金融工具,我必须修改这 4 个函数。”这就是发散式变化的征兆。数据库交互和金融逻辑处理是两个不同的上下文,将它们分别搬移到各自独立的模块中,能让程序变得更好:每当要对某个上下文做修改时,我们只需要理解这个上下文,而不必操心另一个。“每次只关心一个上下文”这一点一直很重要,在如今这个信息爆炸、脑容量不够用的年代就愈发紧要。当然,往往只有在加入新数据库或新金融工具后,你才能发现这个坏味道。在程序刚开发出来还在随着软件系统的能力不断演进时,上下文边界通常不是那么清晰。
如果发生变化的两个方向自然地形成了先后次序(比如说,先从数据库取出数据,再对其进行金融逻辑处理),就可以用拆分阶段(154)将两者分开,两者之间通过一个清晰的数据结构进行沟通。如果两个方向之间有更多的来回调用,就应该先创建适当的模块,然后用搬移函数(198)把处理逻辑分开。如果函数内部混合了两类处理逻辑,应该先用提炼函数(106)将其分开,然后再做搬移。如果模块是以类的形式定义的,就可以用提炼类(182)来做拆分。
3.8 霰弹式修改(Shotgun Surgery)
霰弹式修改类似于发散式变化,但又恰恰相反。如果每遇到某种变化,你都必须在许多不同的类内做出许多小修改,你所面临的坏味道就是霰弹式修改。如果需要修改的代码散布四处,你不但很难找到它们,也很容易错过某个重要的修改。
这种情况下,你应该使用搬移函数(198)和搬移字段(207)把所有需要修改的代码放进同一个模块里。如果有很多函数都在操作相似的数据,可以使用函数组合成类(144)。如果有些函数的功能是转化或者充实数据结构,可以使用函数组合成变换(149)。如果一些函数的输出可以组合后提供给一段专门使用这些计算结果的逻辑,这种时候常常用得上拆分阶段(154)。
面对霰弹式修改,一个常用的策略就是使用与内联(inline)相关的重构——如内联函数(115)或是内联类(186)——把本不该分散的逻辑拽回一处。完成内联之后,你可能会闻到过长函数或者过大的类的味道,不过你总可以用与提炼相关的重构手法将其拆解成更合理的小块。即便如此钟爱小型的函数和类,我们也并不担心在重构的过程中暂时创建一些较大的程序单元。
3.9 依恋情结(Feature Envy)
所谓模块化,就是力求将代码分出区域,最大化区域内部的交互、最小化跨区域的交互。但有时你会发现,一个函数跟另一个模块中的函数或者数据交流格外频繁,远胜于在自己所处模块内部的交流,这就是依恋情结的典型情况。无数次经验里,我们看到某个函数为了计算某个值,从另一个对象那儿调用几乎半打的取值函数。疗法显而易见:这个函数想跟这些数据待在一起,那就使用搬移函数(198)把它移过去。有时候,函数中只有一部分受这种依恋之苦,这时候应该使用提炼函数(106)把这一部分提炼到独立的函数中,再使用搬移函数(198)带它去它的梦想家园。
当然,并非所有情况都这么简单。一个函数往往会用到几个模块的功能,那么它究竟该被置于何处呢?我们的原则是:判断哪个模块拥有的此函数使用的数据最多,然后就把这个函数和那些数据摆在一起。如果先以提炼函数(106)将这个函数分解为数个较小的函数并分别置放于不同地点,上述步骤也就比较容易完成了。
有几个复杂精巧的模式破坏了这条规则。说起这个话题,GoF[gof]的策略(Strategy)模式和访问者(Visitor)模式立刻跳入我的脑海,Kent Beck 的 Self Delegation 模式[Beck SBPP]也在此列。使用这些模式是为了对抗发散式变化这一坏味道。最根本的原则是:将总是一起变化的东西放在一块儿。数据和引用这些数据的行为总是一起变化的,但也有例外。如果例外出现,我们就搬移那些行为,保持变化只在一地发生。策略模式和和访问者模式使你得以轻松修改函数的行为,因为它们将少量需被覆写的行为隔离开来——当然也付出了“多一层间接性”的代价。
3.10 数据泥团(Data Clumps)
数据项就像小孩子,喜欢成群结队地待在一块儿。你常常可以在很多地方看到相同的三四项数据:两个类中相同的字段、许多函数签名中相同的参数。这些总是绑在一起出现的数据真应该拥有属于它们自己的对象。首先请找出这些数据以字段形式出现的地方,运用提炼类(182)将它们提炼到一个独立对象中。然后将注意力转移到函数签名上,运用引入参数对象(140)或保持对象完整(319)为它瘦身。这么做的直接好处是可以将很多参数列表缩短,简化函数调用。是的,不必在意数据泥团只用上新对象的一部分字段,只要以新对象取代两个(或更多)字段,就值得这么做。
一个好的评判办法是:删掉众多数据中的一项。如果这么做,其他数据有没有因而失去意义?如果它们不再有意义,这就是一个明确信号:你应该为它们产生一个新对象。
我们在这里提倡新建一个类,而不是简单的记录结构,因为一旦拥有新的类,你就有机会让程序散发出一种芳香。得到新的类以后,你就可以着手寻找“依恋情结”,这可以帮你指出能够移至新类中的种种行为。这是一种强大的动力:有用的类被创建出来,大量的重复被消除,后续开发得以加速,原来的数据泥团终于在它们的小社会中充分发挥价值。
3.11 基本类型偏执(Primitive Obsession)
大多数编程环境都大量使用基本类型,即整数、浮点数和字符串等。一些库会引入一些小对象,如日期。但我们发现一个很有趣的现象:很多程序员不愿意创建对自己的问题域有用的基本类型,如钱、坐标、范围等。于是,我们看到了把钱当作普通数字来计算的情况、计算物理量时无视单位(如把英寸与毫米相加)的情况以及大量类似 if (a < upper && a > lower)这样的代码。
字符串是这种坏味道的最佳培养皿,比如,电话号码不只是一串字符。一个体面的类型,至少能包含一致的显示逻辑,在用户界面上需要显示时可以使用。“用字符串来代表类似这样的数据”是如此常见的臭味,以至于人们给这类变量专门起了一个名字,叫它们“类字符串类型”(stringly typed)变量。
你可以运用以对象取代基本类型(174)将原本单独存在的数据值替换为对象,从而走出传统的洞窟,进入炙手可热的对象世界。如果想要替换的数据值是控制条件行为的类型码,则可以运用以子类取代类型码(362)加上以多态取代条件表达式(272)的组合将它换掉。
如果你有一组总是同时出现的基本类型数据,这就是数据泥团的征兆,应该运用提炼类(182)和引入参数对象(140)来处理。
3.12 重复的 switch (Repeated Switches)
如果你跟真正的面向对象布道者交谈,他们很快就会谈到 switch 语句的邪恶。在他们看来,任何 switch 语句都应该用以多态取代条件表达式(272)消除掉。我们甚至还听过这样的观点:所有条件逻辑都应该用多态取代,绝大多数 if 语句都应该被扫进历史的垃圾桶。
即便在不知天高地厚的青年时代,我们也从未无条件地反对条件语句。在本书第 1 版中,这种坏味道被称为“switch 语句”(Switch Statements),那是因为在 20 世纪 90 年代末期,程序员们太过于忽视多态的价值,我们希望矫枉过正。
如今的程序员已经更多地使用多态,switch 语句也不再像 15 年前那样有害无益,很多语言支持更复杂的 switch 语句,而不只是根据基本类型值来做条件判断。因此,我们现在更关注重复的 switch:在不同的地方反复使用同样的 switch 逻辑(可能是以 switch/case 语句的形式,也可能是以连续的 if/else 语句的形式)。重复的 switch 的问题在于:每当你想增加一个选择分支时,必须找到所有的 switch,并逐一更新。多态给了我们对抗这种黑暗力量的武器,使我们得到更优雅的代码库。
3.13 循环语句(Loops)
从最早的编程语言开始,循环就一直是程序设计的核心要素。但我们感觉如今循环已经有点儿过时,就像喇叭裤和植绒壁纸那样。其实在撰写本书第 1 版的时候,我们就已经开始鄙视循环语句,但和当时的大多数编程语言一样,当时的 Java 还没有提供更好的替代品。如今,函数作为一等公民已经得到了广泛的支持,因此我们可以使用以管道取代循环(231)来让这些老古董退休。我们发现,管道操作(如 filter 和 map)可以帮助我们更快地看清被处理的元素以及处理它们的动作。
3.14 冗赘的元素(Lazy Element)
程序元素(如类和函数)能给代码增加结构,从而支持变化、促进复用或者哪怕只是提供更好的名字也好,但有时我们真的不需要这层额外的结构。可能有这样一个函数,它的名字就跟实现代码看起来一模一样;也可能有这样一个类,根本就是一个简单的函数。这可能是因为,起初在编写这个函数时,程序员也许期望它将来有一天会变大、变复杂,但那一天从未到来;也可能是因为,这个类原本是有用的,但随着重构的进行越变越小,最后只剩了一个函数。不论上述哪一种原因,请让这样的程序元素庄严赴义吧。通常你只需要使用内联函数(115)或是内联类(186)。如果这个类处于一个继承体系中,可以使用折叠继承体系(380)。
3.15 夸夸其谈通用性(Speculative Generality)
这个令我们十分敏感的坏味道,命名者是 Brian Foote。当有人说“噢,我想我们总有一天需要做这事”,并因而企图以各式各样的钩子和特殊情况来处理一些非必要的事情,这种坏味道就出现了。这么做的结果往往造成系统更难理解和维护。如果所有装置都会被用到,就值得那么做;如果用不到,就不值得。用不上的装置只会挡你的路,所以,把它搬开吧。
如果你的某个抽象类其实没有太大作用,请运用折叠继承体系(380)。不必要的委托可运用内联函数(115)和内联类(186)除掉。如果函数的某些参数未被用上,可以用改变函数声明(124)去掉这些参数。如果有并非真正需要、只是为不知远在何处的将来而塞进去的参数,也应该用改变函数声明(124)去掉。
如果函数或类的唯一用户是测试用例,这就飘出了坏味道“夸夸其谈通用性”。如果你发现这样的函数或类,可以先删掉测试用例,然后使用移除死代码(237)。
3.16 临时字段(Temporary Field)
有时你会看到这样的类:其内部某个字段仅为某种特定情况而设。这样的代码让人不易理解,因为你通常认为对象在所有时候都需要它的所有字段。在字段未被使用的情况下猜测当初设置它的目的,会让你发疯。
请使用提炼类(182)给这个可怜的孤儿创造一个家,然后用搬移函数(198)把所有和这些字段相关的代码都放进这个新家。也许你还可以使用引入特例(289)在“变量不合法”的情况下创建一个替代对象,从而避免写出条件式代码。
3.17 过长的消息链(Message Chains)
如果你看到用户向一个对象请求另一个对象,然后再向后者请求另一个对象,然后再请求另一个对象……这就是消息链。在实际代码中你看到的可能是一长串取值函数或一长串临时变量。采取这种方式,意味客户端代码将与查找过程中的导航结构紧密耦合。一旦对象间的关系发生任何变化,客户端就不得不做出相应修改。
这时候应该使用隐藏委托关系(189)。你可以在消息链的不同位置采用这种重构手法。理论上,你可以重构消息链上的所有对象,但这么做就会把所有中间对象都变成“中间人”。通常更好的选择是:先观察消息链最终得到的对象是用来干什么的,看看能否以提炼函数(106)把使用该对象的代码提炼到一个独立的函数中,再运用搬移函数(198)把这个函数推入消息链。如果还有许多客户端代码需要访问链上的其他对象,同样添加一个函数来完成此事。
有些人把任何函数链都视为坏东西,我们不这样想。我们的冷静镇定是出了名的,起码在这件事上是这样的。
3.18 中间人(Middle Man)
对象的基本特征之一就是封装——对外部世界隐藏其内部细节。封装往往伴随着委托。比如,你问主管是否有时间参加一个会议,他就把这个消息“委托”给他的记事簿,然后才能回答你。很好,你没必要知道这位主管到底使用传统记事簿还是使用电子记事簿抑或是秘书来记录自己的约会。
但是人们可能过度运用委托。你也许会看到某个类的接口有一半的函数都委托给其他类,这样就是过度运用。这时应该使用移除中间人(192),直接和真正负责的对象打交道。如果这样“不干实事”的函数只有少数几个,可以运用内联函数(115)把它们放进调用端。如果这些中间人还有其他行为,可以运用以委托取代超类(399)或者以委托取代子类(381)把它变成真正的对象,这样你既可以扩展原对象的行为,又不必负担那么多的委托动作。
3.19 内幕交易(Insider Trading)
软件开发者喜欢在模块之间建起高墙,极其反感在模块之间大量交换数据,因为这会增加模块间的耦合。在实际情况里,一定的数据交换不可避免,但我们必须尽量减少这种情况,并把这种交换都放到明面上来。
如果两个模块总是在咖啡机旁边窃窃私语,就应该用搬移函数(198)和搬移字段(207)减少它们的私下交流。如果两个模块有共同的兴趣,可以尝试再新建一个模块,把这些共用的数据放在一个管理良好的地方;或者用隐藏委托关系(189),把另一个模块变成两者的中介。
继承常会造成密谋,因为子类对超类的了解总是超过后者的主观愿望。如果你觉得该让这个孩子独立生活了,请运用以委托取代子类(381)或以委托取代超类(399)让它离开继承体系。
3.20 过大的类(Large Class)
如果想利用单个类做太多事情,其内往往就会出现太多字段。一旦如此,重复代码也就接踵而至了。
你可以运用提炼类(182)将几个变量一起提炼至新类内。提炼时应该选择类内彼此相关的变量,将它们放在一起。例如,depositAmount 和 depositCurrency 可能应该隶属同一个类。通常,如果类内的数个变量有着相同的前缀或后缀,这就意味着有机会把它们提炼到某个组件内。如果这个组件适合作为一个子类,你会发现提炼超类(375)或者以子类取代类型码(362)(其实就是提炼子类)往往比较简单。
有时候类并非在所有时刻都使用所有字段。若果真如此,你或许可以进行多次提炼。
和“太多实例变量”一样,类内如果有太多代码,也是代码重复、混乱并最终走向死亡的源头。最简单的解决方案(还记得吗,我们喜欢简单的解决方案)是把多余的东西消弭于类内部。如果有 5 个“百行函数”,它们之中很多代码都相同,那么或许你可以把它们变成 5 个“十行函数”和 10 个提炼出来的“双行函数”。
观察一个大类的使用者,经常能找到如何拆分类的线索。看看使用者是否只用到了这个类所有功能的一个子集,每个这样的子集都可能拆分成一个独立的类。一旦识别出一个合适的功能子集,就试用提炼类(182)、提炼超类(375)或是以子类取代类型码(362)将其拆分出来。
3.21 异曲同工的类(Alternative Classes with Different Interfaces)
使用类的好处之一就在于可以替换:今天用这个类,未来可以换成用另一个类。但只有当两个类的接口一致时,才能做这种替换。可以用改变函数声明(124)将函数签名变得一致。但这往往还不够,请反复运用搬移函数(198)将某些行为移入类中,直到两者的协议一致为止。如果搬移过程造成了重复代码,或许可运用提炼超类(375)补偿一下。
3.22 纯数据类(Data Class)
所谓纯数据类是指:它们拥有一些字段,以及用于访问(读写)这些字段的函数,除此之外一无长物。这样的类只是一种不会说话的数据容器,它们几乎一定被其他类过分细琐地操控着。这些类早期可能拥有 public 字段,若果真如此,你应该在别人注意到它们之前,立刻运用封装记录(162)将它们封装起来。对于那些不该被其他类修改的字段,请运用移除设值函数(331)。
然后,找出这些取值/设值函数被其他类调用的地点。尝试以搬移函数(198)把那些调用行为搬移到纯数据类里来。如果无法搬移整个函数,就运用提炼函数(106)产生一个可被搬移的函数。
纯数据类常常意味着行为被放在了错误的地方。也就是说,只要把处理数据的行为从客户端搬移到纯数据类里来,就能使情况大为改观。但也有例外情况,一个最好的例外情况就是,纯数据记录对象被用作函数调用的返回结果,比如使用拆分阶段(154)之后得到的中转数据结构就是这种情况。这种结果数据对象有一个关键的特征:它是不可修改的(至少在拆分阶段(154)的实际操作中是这样)。不可修改的字段无须封装,使用者可以直接通过字段取得数据,无须通过取值函数。
3.23 被拒绝的遗赠(Refused Bequest)
子类应该继承超类的函数和数据。但如果它们不想或不需要继承,又该怎么办呢?它们得到所有礼物,却只从中挑选几样来玩!
按传统说法,这就意味着继承体系设计错误。你需要为这个子类新建一个兄弟类,再运用函数下移(359)和字段下移(361)把所有用不到的函数下推给那个兄弟。这样一来,超类就只持有所有子类共享的东西。你常常会听到这样的建议:所有超类都应该是抽象(abstract)的。
既然使用“传统说法”这个略带贬义的词,你就可以猜到,我们不建议你这么做,起码不建议你每次都这么做。我们经常利用继承来复用一些行为,并发现这可以很好地应用于日常工作。这也是一种坏味道,我们不否认,但气味通常并不强烈,所以我们说,如果“被拒绝的遗赠”正在引起困惑和问题,请遵循传统忠告。但不必认为你每次都得那么做。十有八九这种坏味道很淡,不值得理睬。
如果子类复用了超类的行为(实现),却又不愿意支持超类的接口,“被拒绝的遗赠”的坏味道就会变得很浓烈。拒绝继承超类的实现,这一点我们不介意;但如果拒绝支持超类的接口,这就难以接受了。既然不愿意支持超类的接口,就不要虚情假意地糊弄继承体系,应该运用以委托取代子类(381)或者以委托取代超类(399)彻底划清界限。
3.24 注释(Comments)
别担心,我们并不是说你不该写注释。从嗅觉上说,注释不但不是一种坏味道,事实上它们还是一种香味呢。我们之所以要在这里提到注释,是因为人们常把它当作“除臭剂”来使用。常常会有这样的情况:你看到一段代码有着长长的注释,然后发现,这些注释之所以存在乃是因为代码很糟糕。这种情况的发生次数之多,实在令人吃惊。
注释可以带我们找到本章先前提到的各种坏味道。找到坏味道后,我们首先应该以各种重构手法把坏味道去除。完成之后我们常常会发现:注释已经变得多余了,因为代码已经清楚地说明了一切。
如果你需要注释来解释一块代码做了什么,试试提炼函数(106);如果函数已经提炼出来,但还是需要注释来解释其行为,试试用改变函数声明(124)为它改名;如果你需要注释说明某些系统的需求规格,试试引入断言(302)。
Tip
当你感觉需要撰写注释时,请先尝试重构,试着让所有注释都变得多余。
如果你不知道该做什么,这才是注释的良好运用时机。除了用来记述将来的打算之外,注释还可以用来标记你并无十足把握的区域。你可以在注释里写下自己“为什么做某某事”。这类信息可以帮助将来的修改者,尤其是那些健忘的家伙。
第 4 章 构筑测试体系
重构是很有价值的工具,但只有重构还不行。要正确地进行重构,前提是得有一套稳固的测试集合,以帮我发现难以避免的疏漏。即便有工具可以帮我自动完成一些重构,很多重构手法依然需要通过测试集合来保障。
我并不把这视为缺点。我发现,编写优良的测试程序,可以极大提高我的编程速度,即使不进行重构也一样如此。这让我很吃惊,也违反许多程序员的直觉,所以我有必要解释一下这个现象。
4.1 自测试代码的价值
如果你认真观察大多数程序员如何分配他们的时间,就会发现,他们编写代码的时间仅占所有时间中很少的一部分。有些时间用来决定下一步干什么,有些时间花在设计上,但是,花费在调试上的时间是最多的。我敢肯定,每一位读者一定都记得自己花数小时调试代码的经历——而且常常是通宵达旦。每个程序员都能讲出一个为了修复一个 bug 花费了一整天(甚至更长时间)的故事。修复 bug 通常是比较快的,但找出 bug 所在却是一场噩梦。当修复一个 bug 时,常常会引起另一个 bug,却在很久之后才会注意到它。那时,你又要花上大把时间去定位问题。
我走上“自测试代码”这条路,源于 1992 年 OOPSLA 大会上的一个演讲。有个人(我记得好像是 Bedarra 公司的 Dave Thomas)提到:“类应该包含它们自己的测试代码。”这让我决定,将测试代码和产品代码一起放到代码库中。
当时,我正在迭代方式开发一个软件,因此,我尝试在每个迭代结束后把测试代码加上。当时我的软件项目很小,我们每周进行一次迭代。所以,运行测试变得相当简单——尽管非常简单,但也非常枯燥。因为每个测试都把测试结果输出到控制台中,我必须逐一检查它们。我是一个很懒的人,所以总是在当下努力工作,以免日后有更多的活儿。我意识到,其实完全不必自己盯着屏幕检验测试输出的信息是否正确,而是让计算机来帮我做检查。我需要做的就是把我所期望的输出放到测试代码中,然后做一个对比就行了。于是,我只要运行所有测试用例,假如一切都没问题,屏幕上就只出现一个“OK”。现在我的代码都能够“自测试”了。
从此,运行测试就像执行编译一样简单。于是,我每次编译时都会运行测试。不久之后,我注意到自己的开发效率大大提高。我意识到,这是因为我没有花太多时间去测试的缘故。如果我不小心引入一个可被现有测试捕捉到的 bug,那么只要运行测试,它就会向我报告这个 bug。由于代码原本是可以正常运行的,所以我知道这个 bug 必定是在前一次运行测试后修改代码引入的。由于我频繁地运行测试,每次测试都在不久之前,因此我知道 bug 的源头就是我刚刚写下的代码。因为代码量很少,我对它也记忆犹新,所以就能轻松找出 bug。从前需要一小时甚至更多时间才能找到的 bug,现在最多只要几分钟就找到了。之所以能够拥有如此强大的 bug 侦测能力,不仅仅是因为我的代码能够自测试,也得益于我频繁地运行它们。
Tip
确保所有测试都完全自动化,让它们检查自己的测试结果。
注意到这一点后,我对测试的积极性更高了。我不再等待每次迭代结尾时再增加测试,而是只要写好一点功能,就立即添加它们。每天我都会添加一些新功能,同时也添加相应的测试。这样,我很少花超过几分钟的时间来追查回归错误。
从我最早的试验开始到现在为止,编写和组织自动化测试的工具已经有了长足的发展。1997 年,Kent Beck 从瑞士飞往亚特兰大去参加当年的 OOPSLA 会议,在飞机上他与 Erich Gamma 结对,把他为 Smalltalk 撰写的测试框架移植到了 Java 上。由此诞生的 JUnit 框架在测试领域影响力非凡,也在不同的编程语言中催生了很多类似的工具[mf-xunit]。
Tip
一套测试就是一个强大的 bug 侦测器,能够大大缩减查找 bug 所需的时间。
我得承认,说服别人也这么做并不容易。编写测试程序,意味着要写很多额外的代码。除非你确实体会到这种方法是如何提升编程速度的,否则自测试似乎就没什么意义。很多人根本没学过如何编写测试程序,甚至根本没考虑过测试,这对于编写自测试也很不利。如果测试需要手动运行,那的确是令人烦闷。但是,如果测试可以自动运行,编写测试代码就会真的很有趣。
事实上,撰写测试代码的最好时机是在开始动手编码之前。当我需要添加特性时,我会先编写相应的测试代码。听起来离经叛道,其实不然。编写测试代码其实就是在问自己:为了添加这个功能,我需要实现些什么?编写测试代码还能帮我把注意力集中于接口而非实现(这永远是一件好事)。预先写好的测试代码也为我的工作安上一个明确的结束标志:一旦测试代码正常运行,工作就可以结束了。
Kent Beck 将这种先写测试的习惯提炼成一门技艺,叫测试驱动开发(Test-Driven Development,TDD)[mf-tdd]。测试驱动开发的编程方式依赖于下面这个短循环:先编写一个(失败的)测试,编写代码使测试通过,然后进行重构以保证代码整洁。这个“测试、编码、重构”的循环应该在每个小时内都完成很多次。这种良好的节奏感可使编程工作以更加高效、有条不紊的方式开展。我就不在这里再做更深入的介绍,但我自己确实经常使用,也非常建议你试一试。
大道理先放在一边。尽管我相信每个人都可以从编写自测试代码中收益,但这并不是本书的重点。本书谈的是重构,而重构需要测试。如果你想重构,就必须编写测试。本章会带你入门,教你如何在 JavaScript 中编写简单的测试,但它不是一本专门讲测试的书,所以我不想讲得太细。但我发现,少许测试往往就足以带来惊人的收益。
和本书其他内容一样,我以示例来介绍测试手法。开发软件的时候,我一边写代码,一边写测试。但有时我也需要重构一些没有测试的代码。在重构之前,我得先改造这些代码,使其能够自测试才行。
4.2 待测试的示例代码
这里我展示了一份有待测试的代码。这份代码来自一个简单的应用,用于支持用户查看并调整生产计划。它的(略显粗糙的)界面长得像下面这张图所示的这样。

每个行省(province)都有一份生产计划,计划中包含需求量(demand)和采购价格(price)。每个行省都有一些生产商(producer),他们各自以不同的成本价(cost)供应一定数量的产品。界面上还会显示,当商家售出所有的商品时,他们可以获得的总收入(full revenue)。页面底部展示了该区域的产品缺额(需求量减去总产量)和总利润(profit)。用户可以在界面上修改需求量及采购价格,以及不同生产商的产量(production)和成本价,以观察缺额和总利润的变化。用户在界面上修改任何数值时,其他的数值都会同时得到更新。
这里我展示了一个用户界面,是为了让你了解该应用的使用方式,但我只会聚焦于软件的业务逻辑部分,也就是那些计算利润和缺额的类,而非那些生成 HTML 或监听页面字段更新的代码。本章只是先带你走进自测试代码世界的大门,因而最好是从最简单的例子开始,也就是那些不涉及用户界面、持久化或外部服务交互的代码。这种隔离的思路其实在任何场景下都适用:一旦业务逻辑的部分开始变复杂,我就会把它与 UI 分离开,以便能更好地理解和测试它。
这块业务逻辑代码涉及两个类:一个代表了单个生产商(Producer),另一个用来描述一个行省(Province)。Province 类的构造函数接收一个 JavaScript 对象,这个对象的内容我们可以想象是由一个 JSON 文件提供的。
下面的代码能从 JSON 文件中构造出一个行省对象。
class Province…
constructor(doc) {
this._name = doc.name;
this._producers = [];
this._totalProduction = 0;
this._demand = doc.demand;
this._price = doc.price;
doc.producers.forEach(d => this.addProducer(new Producer(this, d)));
}
addProducer(arg) {
this._producers.push(arg);
this._totalProduction += arg.production;
}
下面的函数会创建可用的 JSON 数据,我可以用它的返回值来构造一个行省对象,并拿这个对象来做测试。
顶层作用域…
function sampleProvinceData() {
return {
name: "Asia",
producers: [
{ name: "Byzantium", cost: 10, production: 9 },
{ name: "Attalia", cost: 12, production: 10 },
{ name: "Sinope", cost: 10, production: 6 },
],
demand: 30,
price: 20,
};
}
行省类中有许多设值函数和取值函数,它们用于获取各类数据的值。
class Province…
get name() {return this._name;}
get producers() {return this._producers.slice();}
get totalProduction() {return this._totalProduction;}
set totalProduction(arg) {this._totalProduction = arg;}
get demand() {return this._demand;}
set demand(arg) {this._demand = parseInt(arg);}
get price() {return this._price;}
set price(arg) {this._price = parseInt(arg);}
设值函数会被 UI 端调用,接收一个包含数值的字符串。我需要将它们转换成数值,以便在后续的计算中使用。
代表生产商的 Producer 类则基本只是一个存放数据的容器。
class Producer…
constructor(aProvince, data) {
this._province = aProvince;
this._cost = data.cost;
this._name = data.name;
this._production = data.production || 0;
}
get name() {return this._name;}
get cost() {return this._cost;}
set cost(arg) {this._cost = parseInt(arg);}
get production() {return this._production;}
set production(amountStr) {
const amount = parseInt(amountStr);
const newProduction = Number.isNaN(amount) ? 0 : amount;
this._province.totalProduction += newProduction - this._production;
this._production = newProduction;
}
在设值函数 production 中更新派生数据的方式有点丑陋,每当看到这种代码,我便想通过重构帮它改头换面。但在重构之前,我必须记得先为它添加测试。
缺额的计算逻辑也很简单。
class Province…
get shortfall() {
return this._demand - this.totalProduction;
}
计算利润的逻辑则要相对复杂一些。
class Province…
get profit() {
return this.demandValue - this.demandCost;
}
get demandCost() {
let remainingDemand = this.demand;
let result = 0;
this.producers
.sort((a,b) => a.cost - b.cost)
.forEach(p => {
const contribution = Math.min(remainingDemand, p.production);
remainingDemand -= contribution;
result += contribution * p.cost;
});
return result;
}
get demandValue() {
return this.satisfiedDemand * this.price;
}
get satisfiedDemand() {
return Math.min(this._demand, this.totalProduction);
}
4.3 第一个测试
开始测试这份代码前,我需要一个测试框架。JavaScript 世界里这样的框架有很多,这里我选用的是使用度和声誉都还不错的 Mocha。我不打算全面讲解框架的使用,而只会用它写一些测试作为例子。看完之后,你应该能轻松地学会用别的框架来编写类似的测试。
以下是为缺额计算过程编写的一个简单的测试:
describe("province", function () {
it("shortfall", function () {
const asia = new Province(sampleProvinceData());
assert.equal(asia.shortfall, 5);
});
});
Mocha 框架组织测试代码的方式是将其分组,每一组下包含一套相关的测试。测试需要写在一个 it 块中。对于这个简单的例子,测试包含了两个步骤。第一步设置好一些测试夹具(fixture),也就是测试所需要的数据和对象等(就本例而言是一个加载好了的行省对象);第二步则是验证测试夹具是否具备某些特征(就本例而言则是验证算出的缺额应该是期望的值)。
Tip
不同开发者在 describe 和 it 块里撰写的描述信息各有不同。有的人会写一个描述性的句子解释测试的内容,也有人什么都不写,认为所谓描述性的句子跟注释一样,不外乎是重复代码已经表达的东西。我个人不喜欢多写,只要测试失败时足以识别出对应的测试就够了。
如果我在 NodeJS 的控制台下运行这个测试,那么其输出看起来是这样:
''''''''''''''
1 passing (61ms)
它的反馈极其简洁,只包含了已运行的测试数量以及测试通过的数量。
当我为类似的既有代码编写测试时,发现一切正常工作固然是好,但我天然持怀疑精神。特别是有很多测试在运行时,我总会担心测试没有按我期望的方式检查结果,从而没法在实际出错的时候抓到 bug。因此编写测试时,我想看到每个测试都至少失败一遍。我最爱的方式莫过于在代码中暂时引入一个错误,像这样:
Tip
总是确保测试不该通过时真的会失败。
class Province…
get shortfall() {
return this._demand - this.totalProduction * 2;
}
现在控制台的输出就有所改变了:
!
0 passing (72ms)
1 failing
1) province shortfall:
AssertionError: expected -20 to equal 5
at Context.<anonymous> (src/tester.js:10:12)
框架会报告哪个测试失败了,并给出失败的根本原因——这里是因为实际算出的值与期望的值不相符。于是我总算见到有什么东西失败了,并且还能马上看到是哪个测试失败,获得一些出错的线索(这个例子中,我还能确认这就是我引入的那个错误)。
一个真实的系统可能拥有数千个测试。好的测试框架应该能帮我简单快速地运行这些测试,一旦出错,我能马上看到。尽管这种反馈非常简单,但对自测试代码来说却尤为重要。工作时我会非常频繁地运行测试,要么是检验新代码的进展,要么是检查重构过程是否出错。
Tip
频繁地运行测试。对于你正在处理的代码,与其对应的测试至少每隔几分钟就要运行一次,每天至少运行一次所有的测试。
Mocha 框架允许使用不同的库(它称之为断言库)来验证测试的正确性。JavaScript 世界的断言库,连在一起都可以绕地球一周了,当你读到这里时,可能有些仍然还没过时。我现在使用的库是 Chai,它可以支持我编写不同类型的断言,比如“assert”风格的:
describe("province", function () {
it("shortfall", function () {
const asia = new Province(sampleProvinceData());
assert.equal(asia.shortfall, 5);
});
});
或者是“expect”风格的:
describe("province", function () {
it("shortfall", function () {
const asia = new Province(sampleProvinceData());
expect(asia.shortfall).equal(5);
});
});
一般来讲我更倾向于使用 assert 风格的断言,但使用 JavaScript 时我倒是更常使用 expect 的风格。
环境不同,运行测试的方式也不同。使用 Java 编程时,我使用 IDE 的图形化测试运行界面。它有一个进度条,所有测试都通过时就会显示绿色;只要有任何测试失败,它就会变成红色。我的同事们经常使用“绿色条”和“红色条”来指代测试的状态。我可能会讲“看到红条时永远不许进行重构”,意思是:测试集合中还有失败的测试时就不应该先去重构。有时我也会讲“回退到绿条”,表示你应该撤销最近一次更改,将测试恢复到上一次全部通过的状态(通常是切回到版本控制的最近一次提交点)。
图形化测试界面的确很棒,但并不是必需的。我通常会在 Emacs 中配置一个运行测试的快捷键,然后在编译窗口中观察纯文本的反馈。要点在于,我必须能快速地知道测试是否全部都通过了。
4.4 再添加一个测试
现在,我将继续添加更多测试。我遵循的风格是:观察被测试类应该做的所有事情,然后对这个类的每个行为进行测试,包括各种可能使它发生异常的边界条件。这不同于某些程序员提倡的“测试所有 public 函数”的风格。记住,测试应该是一种风险驱动的行为,我测试的目标是希望找出现在或未来可能出现的 bug。所以我不会去测试那些仅仅读或写一个字段的访问函数,因为它们太简单了,不太可能出错。
这一点很重要,因为如果尝试撰写过多测试,结果往往反而导致测试不充分。事实上,即使我只做一点点测试,也从中获益良多。测试的重点应该是那些我最担心出错的部分,这样就能从测试工作中得到最大利益。
接下来,我的目光落到了代码的另一个主要输出上,也就是总利润的计算。我同样可以在一开始的测试夹具上,对总利润做一个基本的测试。
Tip
编写未臻完善的测试并经常运行,好过对完美测试的无尽等待。
describe("province", function () {
it("shortfall", function () {
const asia = new Province(sampleProvinceData());
expect(asia.shortfall).equal(5);
});
it("profit", function () {
const asia = new Province(sampleProvinceData());
expect(asia.profit).equal(230);
});
});
这是最终写出来的测试,但我是怎么写出它来的呢?首先我随便给测试的期望值写了一个数,然后运行测试,将程序产生的实际值(230)填回去。当然,我也可以自己手动计算,不过,既然现在的代码是能正常运行的,我就选择暂时相信它。测试可以正常工作后,我又故技重施,在利润的计算过程插入一个假的乘以 2 逻辑来破坏测试。如我所料,测试会失败,这时我才满意地将插入的假逻辑恢复过来。这个模式是我为既有代码添加测试时最常用的方法:先随便填写一个期望值,再用程序产生的真实值来替换它,然后引入一个错误,最后恢复错误。
这个测试随即产生了一些重复代码——它们都在第一行里初始化了同一个测试夹具。正如我对一般的重复代码抱持怀疑,测试代码中的重复同样令我心生疑惑,因此我要试着将它们提到一处公共的地方,以此来消灭重复。一种方案就是把常量提取到外层作用域里。
describe("province", function () {
const asia = new Province(sampleProvinceData()); // DON'T DO THIS
it("shortfall", function () {
expect(asia.shortfall).equal(5);
});
it("profit", function () {
expect(asia.profit).equal(230);
});
});
但正如代码注释所说的,我从不这样做。这样做的确能解决一时的问题,但共享测试夹具会使测试间产生交互,这是滋生 bug 的温床——还是你写测试时能遇见的最恶心的 bug 之一。使用了 JavaScript 中的 const 关键字只表明 asia 的引用不可修改,不表明对象的内容也不可修改。如果未来有一个测试改变了这个共享对象,测试就可能时不时失败,因为测试之间会通过共享夹具产生交互,而测试的结果就会受测试运行次序的影响。测试结果的这种不确定性,往往使你陷入漫长而又艰难的调试,严重时甚至可能令你对测试体系的信心产生动摇。因此,我比较推荐采取下面的做法:
describe("province", function () {
let asia;
beforeEach(function () {
asia = new Province(sampleProvinceData());
});
it("shortfall", function () {
expect(asia.shortfall).equal(5);
});
it("profit", function () {
expect(asia.profit).equal(230);
});
});
beforeEach 子句会在每个测试之前运行一遍,将 asia 变量清空,每次都给它赋一个新的值。这样我就能在每个测试开始前,为它们各自构建一套新的测试夹具,这保证了测试的独立性,避免了可能带来麻烦的不确定性。
对于这样的建议,有人可能会担心,每次创建一个崭新的测试夹具会拖慢测试的运行速度。大多数时候,时间上的差别几乎无法察觉。如果运行速度真的成为问题,我也可以考虑共享测试夹具,但这样我就得非常小心,确保没有测试会去更改它。如果我能够确定测试夹具是百分之百不可变的,那么也可以共享它。但我的本能反应还是要使用独立的测试夹具,可能因为我过去尝过了太多共享测试夹具带来的苦果。
既然我在 beforeEach 里运行的代码会对每个测试生效,那么为何不直接把它挪到每个 it 块里呢?让所有测试共享一段测试夹具代码的原因,是为了使我对公用的夹具代码感到熟悉,从而将眼光聚焦于每个测试的不同之处。beforeEach 块旨在告诉读者,我使用了同一套标准夹具。你可以接着阅读 describe 块里的所有测试,并知道它们都是基于同样的数据展开测试的。
4.5 修改测试夹具
加载完测试夹具后,我编写了一些测试来探查它的一些特性。但在实际应用中,该夹具可能会被频繁更新,因为用户可能在界面上修改数值。
大多数更新都是通过设值函数完成的,我一般也不会测试这些方法,因为它们不太可能出什么 bug。不过 Producer 类中的产量(production)字段,其设值函数行为比较复杂,我觉得它倒是值得一测。
describe('province'...
it('change production', function() {
asia.producers[0].production = 20;
expect(asia.shortfall).equal(-6);
expect(asia.profit).equal(292);
});
这是一个常见的测试模式。我拿到 beforeEach 配置好的初始标准夹具,然后对该夹具进行必要的检查,最后验证它是否表现出我期望的行为。如果你读过测试相关的资料,就会经常听到各种类似的术语,比如配置-检查-验证(setup-exercise-verify)、given-when-then 或者准备-行为-断言(arrange-act-assert)等。有时你能在一个测试里见到所有的步骤,有时那些早期的公用阶段会被提到一些标准的配置步骤里,诸如 beforeEach 等。
Tip
(其实还有第四个阶段,只是不那么明显,一般很少提及,那就是拆除阶段。此阶段可将测试夹具移除,以确保不同测试之间不会产生交互。因为我是在 beforeEach 中配置好数据的,所以测试框架会默认在不同的测试间将我的测试夹具移除,相当于我自动享受了拆除阶段带来的便利。多数测试文献的作者对拆除阶段一笔带过,这可以理解,因为多数时候我们可以忽略它。但有时因为创建缓慢等原因,我们会在不同的测试间共享测试夹具,此时,显式地声明一个拆除操作就是很重要的。)
在这个测试中,我在一个 it 语句里验证了两个不同的特性。作为一个基本规则,一个 it 语句中最好只有一个验证语句,否则测试可能在进行第一个验证时就失败,这通常会掩盖一些重要的错误信息,不利于你了解测试失败的原因。不过,在上面的场景中,我觉得两个断言本身关系非常紧密,写在同一个测试中问题不大。如果稍后需要将它们分离到不同的 it 语句中,我可以到时再做。
4.6 探测边界条件
到目前为止我的测试都聚焦于正常的行为上,这通常也被称为“正常路径”(happy path),它指的是一切工作正常、用户使用方式也最符合规范的那种场景。同时,把测试推到这些条件的边界处也是不错的实践,这可以检查操作出错时软件的表现。
无论何时,当我拿到一个集合(比如说此例中的生产商集合)时,我总想看看集合为空时会发生什么。
describe('no producers', function() {
let noProducers;
beforeEach(function() {
const data = {
name: "No proudcers",
producers: [],
demand: 30,
price: 20
};
noProducers = new Province(data);
});
it('shortfall', function() {
expect(noProducers.shortfall).equal(30);
});
it('profit', function() {
expect(noProducers.profit).equal(0);
});
如果拿到的是数值类型,0 会是不错的边界条件:
describe('province'...
it('zero demand', function() {
asia.demand = 0;
expect(asia.shortfall).equal(-25);
expect(asia.profit).equal(0);
});
负值同样值得一试:
describe('province'...
it('negative demand', function() {
asia.demand = -1;
expect(asia.shortfall).equal(-26);
expect(asia.profit).equal(-10);
});
测试到这里,我不禁有一个想法:对于这个业务领域来讲,提供一个负的需求值,并算出一个负的利润值意义何在?最小的需求量不应该是 0 吗?或许,设值方法需要对负值有些不同的行为,比如抛出错误,或总是将值设置为 0。这些问题都很好,编写这样的测试能帮助我思考代码本应如何应对边界场景。
设值函数接收的字符串是从 UI 上的字段读来的,它已经被限制为只能填入数字,但仍然有可能是空字符串,因此同样需要测试来保证代码对空字符串的处理方式符合我的期望。
Tip
考虑可能出错的边界条件,把测试火力集中在那儿。
describe('province'...
it('empty string demand', function() {
asia.demand = "";
expect(asia.shortfall).NaN;
expect(asia.profit).NaN;
});
可以看到,我在这里扮演“程序公敌”的角色。我积极思考如何破坏代码。我发现这种思维能够提高生产力,并且很有趣——它纵容了我内心中比较促狭的那一部分。
这个测试结果很有意思:
describe('string for producers', function() {
it('', function() {
const data = {
name: "String producers",
producers: "",
demand: 30,
price: 20
};
const prov = new Province(data);
expect(prov.shortfall).equal(0);
});
它并不是抛出一个简单的错误说缺额的值不为 0。控制台的报错输出实际如下:
'''''''''!
9 passing (74ms)
1 failing
1) string for producers :
TypeError: doc.producers.forEach is not a function
at new Province (src/main.js:22:19)
at Context.<anonymous> (src/tester.js:86:18)
Mocha 把这也当作测试失败(failure),但多数测试框架会把它当作一个错误(error),并与正常的测试失败区分开。“失败”指的是在验证阶段中,实际值与验证语句提供的期望值不相等;而这里的“错误”则是另一码事,它是在更早的阶段前抛出的异常(这里是在配置阶段)。它更像代码的作者没有预料到的一种异常场景,因此我们不幸地得到了每个 JavaScript 程序员都很熟悉的错误(“…is not a function”)。
那么代码应该如何处理这种场景呢?一种思路是,对错误进行处理并给出更好的出错响应,比如说抛出更有意义的错误信息,或是直接将 producers 字段设置为一个空数组(最好还能再记录一行日志信息)。但维持现状不做处理也说得通,也许该输入对象是由可信的数据源提供的,比如同个代码库的另一部分。在同一代码库的不同模块之间加入太多的检查往往会导致重复的验证代码,它带来的好处通常不抵害处,特别是你添加的验证可能在其他地方早已做过。但如果该输入对象是由一个外部服务所提供,比如一个返回 JSON 数据的请求,那么校验和测试就显得必要了。不论如何,为边界条件添加测试总能引发这样的思考。
如果这样的测试是在重构前写出的,那么我很可能还会删掉它。重构应该保证可观测的行为不发生改变,而类似的错误已经超越可观测的范畴。删掉这条测试,我就不用担心重构过程改变了代码对这个边界条件的处理方式。
Tip
如果这个错误会导致脏数据在应用中到处传递,或是产生一些很难调试的失败,我可能会用引入断言(302)手法,使代码不满足预设条件时快速失败。我不会为这样的失败断言添加测试,它们本身就是一种测试的形式。
什么时候应该停下来?我相信这样的话你已经听过很多次:“任何测试都不能证明一个程序没有 bug。”确实如此,但这并不影响“测试可以提高编程速度”。我曾经见过好几种测试规则建议,其目的都是保证你能够测试所有情况的一切组合。这些东西值得一看,但是别让它们影响你。当测试数量达到一定程度之后,继续增加测试带来的边际效用会递减;如果试图编写太多测试,你也可能因为工作量太大而气馁,最后什么都写不成。你应该把测试集中在可能出错的地方。观察代码,看哪儿变得复杂;观察函数,思考哪些地方可能出错。是的,你的测试不可能找出所有 bug,但一旦进行重构,你可以更好地理解整个程序,从而找到更多 bug。虽然在开始重构之前我会确保有一个测试套件存在,但前进途中我总会加入更多测试。
Tip
不要因为测试无法捕捉所有的 bug 就不写测试,因为测试的确可以捕捉到大多数 bug。
4.7 测试远不止如此
本章我想讨论的东西到这里就差不多了,毕竟这是一本关于重构而不是测试的书。但测试本身是一个很重要的话题,它既是重构所必要的基础保障,本身也是一个有价值的工具。自本书第 1 版以来,我很高兴看到重构作为一项编程实践在逐步发展,但我更高兴见到业界对测试的态度也在发生转变。之前,测试更多被认为是另一个独立的(所需专业技能也较少的)团队的责任,但现在它愈发成为任何一个软件开发者所必备的技能。如今一个架构的好坏,很大程度要取决于它的可测试性,这是一个好的行业趋势。
这里我展示的测试都属于单元测试,它们负责测试一块小的代码单元,运行足够快速。它们是自测试代码的支柱,是一个系统中占绝大多数的测试类型。同时也有其他种类的测试存在,有的专注于组件之间的集成,有的会检验软件跨越几个层级的运行结果,有的用于查找性能问题,不一而足。(而且,同行们对于如何归类测试的争论,恐怕比繁多的测试种类本身还要多。)
与编程的许多方面类似,测试也是一种迭代式的活动。除非你技能非常纯熟,或者非常幸运,否则你很难第一次就把测试写对。我发觉我持续地在测试集上工作,就与我在主代码库上的工作一样多。很自然,这意味着我在增加新特性时也要同时添加测试,有时还需要回顾已有的测试:它们足够清晰吗?我需要重构它们,以帮助我更好地理解吗?我拥有的测试是有价值的吗?一个值得养成的好习惯是,每当你遇见一个 bug,先写一个测试来清楚地复现它。仅当测试通过时,才视为 bug 修完。只要测试存在一天,我就知道这个错误永远不会再复现。这个 bug 和对应的测试也会提醒我思考:测试集里是否还有这样不被阳光照耀到的犄角旮旯?
一个常见的问题是,“要写多少测试才算足够?”这个问题没有很好的衡量标准。有些人拥护以测试覆盖率[mf-tc]作为指标,但测试覆盖率的分析只能识别出那些未被测试覆盖到的代码,而不能用来衡量一个测试集的质量高低。
Tip
每当你收到 bug 报告,请先写一个单元测试来暴露这个 bug。
一个测试集是否足够好,最好的衡量标准其实是主观的,请你试问自己:如果有人在代码里引入了一个缺陷,你有多大的自信它能被测试集揪出来?这种信心难以被定量分析,盲目自信不应该被计算在内,但自测试代码的全部目标,就是要帮你获得此种信心。如果我重构完代码,看见全部变绿的测试就可以十分自信没有引入额外的 bug,这样,我就可以高兴地说,我已经有了一套足够好的测试。
测试同样可能过犹不及。测试写得太多的一个征兆是,相比要改的代码,我在改动测试上花费了更多的时间——并且我能感到测试就在拖慢我。不过尽管过度测试时有发生,相比测试不足的情况还是稀少得多。
第 5 章 介绍重构名录
本书剩余的篇幅是一份重构的名录。最初这个名录只是我的个人笔记,我用它来提示自己如何以安全且高效的方式进行重构。然后我不断精炼这份名录,对一些重构的深入探索又引出了更多的重构手法。对于不太常用的重构手法,我还是会不断参阅这份名录。
5.1 重构的记录格式
介绍重构时,我采用一种标准格式。每个重构手法都有如下 5 个部分。
- 首先是名称(name)。要建造一个重构词汇表,名称是很重要的。这个名称也就是我将在本书其他地方使用的名称。如今重构经常会有多个名字,所以我会同时列出常见的别名。
- 名称之后是一个简单的速写(sketch)。这部分可以帮助你更快找到你所需要的重构手法。
- 动机(motivation)为你介绍“为什么需要做这个重构”和“什么情况下不该做这个重构”。
- 做法(mechanics)简明扼要地一步一步介绍如何进行此重构。
- 范例(examples)以一个十分简单的例子说明此重构手法如何运作。
速写部分会以代码示例的形式展示重构带来的转变。速写的用意不是解释重构的用途,更不是详细讲解如何操作这个重构;但如果你曾经看过这个重构手法,速写能帮你回忆起它。如果你是第一次接触到这个重构手法,可能最好是先阅读范例部分。我还给每个重构手法画了一幅小图。同样,我也不指望这些小图能说清重构手法的内容,只是提供一点图像记忆的线索。
“做法”出自我自己的笔记。这些笔记是为了让我在一段时间不做某项重构之后还能记得怎么做。它们也颇为简洁,通常不会解释“为什么要这么做那么做”。我会在“范例”中给出更多解释。这么一来,“做法”就成了简短的笔记。如果你知道该使用哪个重构,但记不清具体步骤,可以参考“做法”部分(至少我是这么使用它们的);如果你初次使用某个重构,可能只参考“做法”还不够,你还需要阅读“范例”。
撰写“做法”的时候,我尽量将重构的每个步骤拆得尽可能小。我强调安全的重构方式,所以应该采用非常小的步骤,并且在每个步骤之后进行测试。真正工作时,我通常会采用比这里介绍的“婴儿学步”稍大些的步骤,然而一旦出问题,我就会撤销上一步,换用比较小的步骤。这些步骤还包含一些特殊情况的参考,所以它们也有检查清单的作用。我自己经常忘掉这些该做的事情。
绝大多数时候我只列出了重构的一套做法,但其实一个重构并非只有一套做法。我在本书中选择介绍这些做法,因为它们大多数时候都管用。等你经过练习获得更多重构经验,你可能会调整重构的做法,那完全没问题。只要牢记一点:小步前进,情况越复杂,步子就要越小。
“范例”像是简单而有趣的教科书。我使用这些范例是为了帮助解释重构的基本要素,最大限度地避免其他枝节,所以我希望你能原谅其中的简化工作(它们当然不是优秀的业务建模例子)。不过我敢肯定,你一定能在那些更复杂的情况中使用它们。某些十分简单的重构干脆没有范例,因为我觉得为它们加上一个范例不会有多大意义。
更明确地说,加上范例仅仅是为了阐释当时讨论的重构手法。通常那些代码最终仍有其他问题,但修正那些问题需要用到其他重构手法。某些情况下数个重构经常被一并运用,这时候我会把范例带到另一个重构中继续使用。大部分时候,一个范例只为一项重构而设计,这么做是为了让每一项重构手法自成一体,因为这份重构名录的首要目的还是作为参考工具。
修改后的代码可能被埋没在未修改的代码中,难以一眼看出,所以我使用不同的颜色突出显示修改过的代码。但我并没有突出显示所有修改过的代码,因为一旦修改过的代码太多,全都突出显示反而不能突显重点。
5.2 挑选重构的依据
这不是一份巨细靡遗的重构名录。我只是认为这些重构手法最值得被记录下来。之所以说它们“最值得”,因为这些都是很常用的重构手法,并且值得给它们命名和详细的介绍:其中一些做法很有意思,能帮助读者提高整体重构技能水平,另外一些则对于代码设计质量的提升效果显著。
有些重构没有进入这份名录,因为它们太小、太简单,我觉得没必要多加赘述。例如,在撰写第 1 版时我就曾经考虑过移动语句(223),这个重构我经常使用,但我觉得没必要将它放进名录里(显然我在写第 2 版的时候改变了想法)。以后也许还有类似这样的重构会被加进书里,不过那要看我投入多少精力在新增重构上了。
还有一些没有进入名录的重构,要么是我用得很少,要么是与其他重构非常相似。本书中的每个重构,逻辑上来说,都有一个反向的重构。但我并没有把所有反向重构都写下来,因为我发现很多反向重构没太大意思。例如,封装变量(132)是一个常用又好用的重构,但它的反向重构我几乎从来不会做(而且就算要做也非常简单),所以我觉得没必要将这个反向重构放进名录。

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









