







《机器学习实战》系列博客主要是实现并理解书中的代码,相当于读书笔记了。毕竟实战不能光看书。动手就能遇到许多奇奇怪怪的问题。博文比较粗糙,需结合书本。博主边查边学,水平有限,有问题的地方评论区请多指教。书中的代码和数据,网上有很多请自行下载。
KNN算法的应用
2.2.1 从文本文件中解析数据
函数的输入为文件名字符串,输出为训练样本矩阵和类标签向量。
解析程序
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3] #选前三列的数据存到矩阵中
classLabelVector.append(int(listFromLine[-1]))#最后一列转成整数后存到标签向量
index += 1
return returnMat,classLabelVector导入数据成功,检查一下数据
>>> import kNN
>>> datingDataMat,datingLabels = kNN.file2matrix('datingTestSet2.txt')
>>> datingDataMat
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]])
>>> datingLabels[0:20]
[3, 2, 1, 1, 1, 1, 3, 3, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1, 2, 3]相关函数学习
- open 函数
语法:open(name[, mode[, buffering]]) r:读操作;w:写操作;a:添加操作;b:二进制存取操作 如果缺省就是r
例如:在C:\Users\lzw\Desktop\python 目录下新建一个txt文件 test_open.txt
命令行输入,就可以打开这个文件
>>> f=open('C:\\Users\\lzw\\Desktop\\python\\test_open.txt','r+') # "\" 是转义符,要将他再转义
>>> 如果是不加路径,只有一个文件名:f = open (‘test_open.txt’) 则必须保证!!! test_open.txt存储在我们的工作目录中
写文件操作
>>> f = open('test_open.txt', 'w')
>>> f.write('hello,')
>>> f.write('python\n')
>>> f.write('this is a test\n')
>>> f.write('lzw\n')
>>> f.close()
>>> 打开 test_open.txt,可以看到原来空的txt 写入了内容
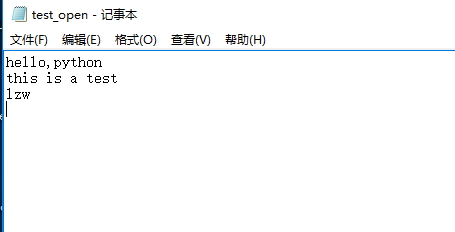
读文件操作
>>> f = open('test_open.txt')
>>> f.read(1)
'h'
>>> f.read(5)
'ello,'
>>> f.read()
'python\nthis is a test\nlzw\n'readlines 逐行读取
>>> f = open('test_open.txt')
>>> f.readlines()
['hello,python\n', 'this is a test\n', 'lzw\n']
>>> - zeros 函数
>>> from numpy import*
>>> zeros(3)
array([ 0., 0., 0.])
>>> zeros((2,3))
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> zeros([2,3]) #和上一种一样
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> zeros(3,int16) #默认的是float型
array([0, 0, 0], dtype=int16)
>>> a=array([[2,3],[3,4]])
>>> zeros_like(a) #返回和输入大小相同,类型相同,用0填满的数组
array([[0, 0],
[0, 0]])- strip 函数 删除头尾字符串函数
>>> a = ' \n123\tabc\r'
>>> a.strip() #删除头尾的字符串,默认为空白符(包括'\n', '\r', '\t', ' ')
'123\tabc'
>>> a.lstrip() #删除开头
'123\tabc\r'
>>> a.rstrip() #删除结尾
' \n123\tabc'
>>> a.strip('12')
' \n123\tabc\r'
>>> a = '12abc'
>>> a.strip('12')#删除字符串12
'abc'
>>> • split 函数拆分字符串。通过指定分隔符对字符串进行切片
>>> u = "www.doiido.com.cn"
>>> print u.split() #使用默认分隔符
['www.doiido.com.cn']
>>> print u.split('.') #以"."为分隔符
['www', 'doiido', 'com', 'cn']
>>> print u.split('.',1) #分割一次
['www', 'doiido.com.cn']
>>> print u.split('.',2) #分割两次
['www', 'doiido', 'com.cn']
>>> print u.split('.',2)[1] #分割两次,并取序列为1的项
doiido
>>> u1,u2,u3 = u.split('.',2)#分割两次,并把分割后的三个部分保存到三个文件
>>> print u1
www
>>> print u2
doiido
>>> print u3
com.cn
2.2.2使用Matplotlib画散点图
kNN .py 程序里继续写,注意要import Matplotlib
散点图程序
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()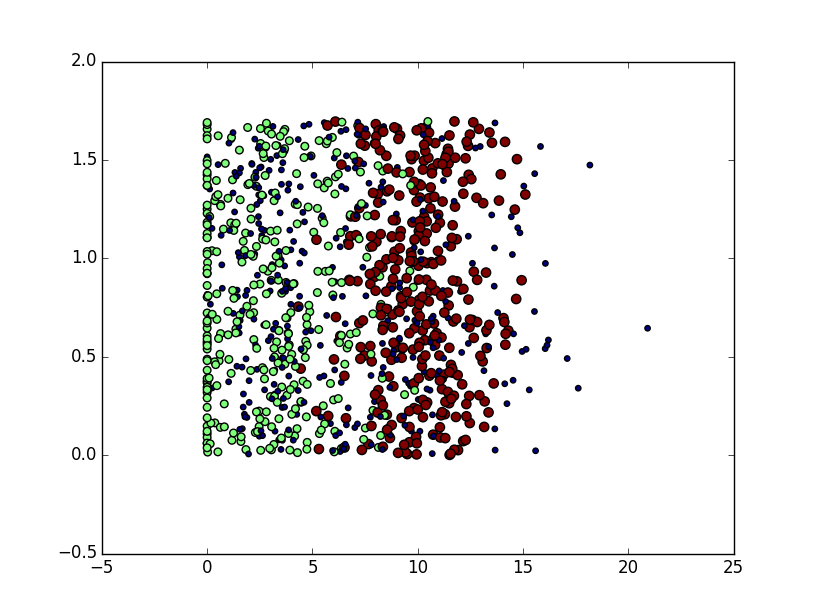
相关函数学习
fig = plt.figure() #绘制一个figure对象
ax = fig.add_subplot(223) #将画布分割成2行2列,图像画在从左到右从上到下的第3块
scatter 画散点图
2.2.3归一化数值
newValue = (oldValue-min)/(max-min)
归一化程序
def autoNorm(dataSet):
minVals = dataSet.min(0) #每一列最小值
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet)) #返回矩阵大小和数据矩阵一样用0填充
m = dataSet.shape[0] #矩阵行数
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
>>> normMat
array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]])
>>> ranges
array([ 9.12730000e+04, 2.09193490e+01, 1.69436100e+00])
>>> minVals
array([ 0. , 0. , 0.001156])
>>> 2.2.4测试算法:用错误率来检测分类器的性能
分离器性能测试程序
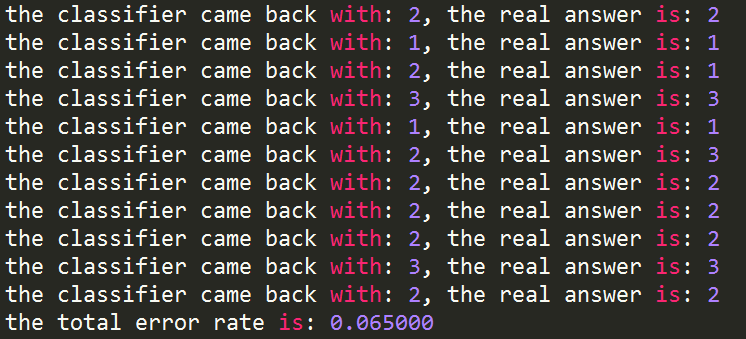
def datingClassTest():
hoRatio = 0.10 #选择10%数据作测试
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount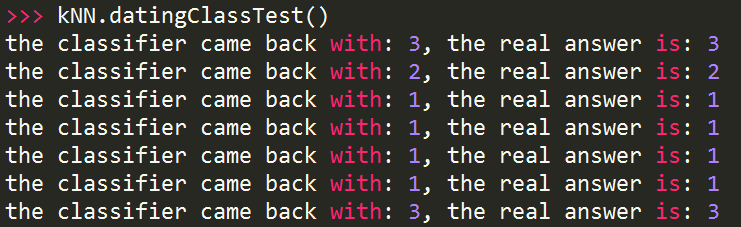
…
2.2.5构建完整可用的系统
预测程序
def classifyPerson():
resultList = ['不喜欢','魅力一般的人','极具魅力的人']
percentTats = float(raw_input("percentgage of time spent playing video game ?"))
ffMile = float(raw_input("frequent flier miles earned per year ?"))
iceCream = float(raw_input("liters of ice Cream consumed per year ?"))
datingDataMat ,datingLabels = file2matrix('datingTestSet2.txt')
normMat ,ranges ,minVals = autoNorm (datingDataMat)
inArr = array([ffMile,percentTats,iceCream])
classifierResult = classify0((inArr - minVals)/ranges, normMat,datingLabels,3)
print "You will probably like this person: ",resultList[classifierResult-1]>>> reload(kNN)
<module 'kNN' from 'kNN.py'>
>>> kNN.classifyPerson()
percentgage of time spent playing video game ? 10
frequent flier miles earned per year ?10000
liters of ice Cream consumed per year ?0.5
You will probably like this person: 魅力一般的人
>>> 相关函数学习
raw_input() 将所有输入作为字符串看待,返回字符串类型














 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









