






对于有2张以上手机卡的用户来说,如何在一部手机上就能完成短信接收,这难到了不少英雄,因为现在的手机最多只能插2张卡,炎炎夏日,如果不想多带一部手机,那就只能随身备个卡针来物理换卡
那有没有这样一个方法,只带一部手机的情况下,还能实现多卡多待,完成多个手机卡的短信接收操作,这就是今天我要给大家介绍的软件 —— 短信转发器,这是一款完全面免费开源的安卓应用,所以在安全性方面大家可以放心

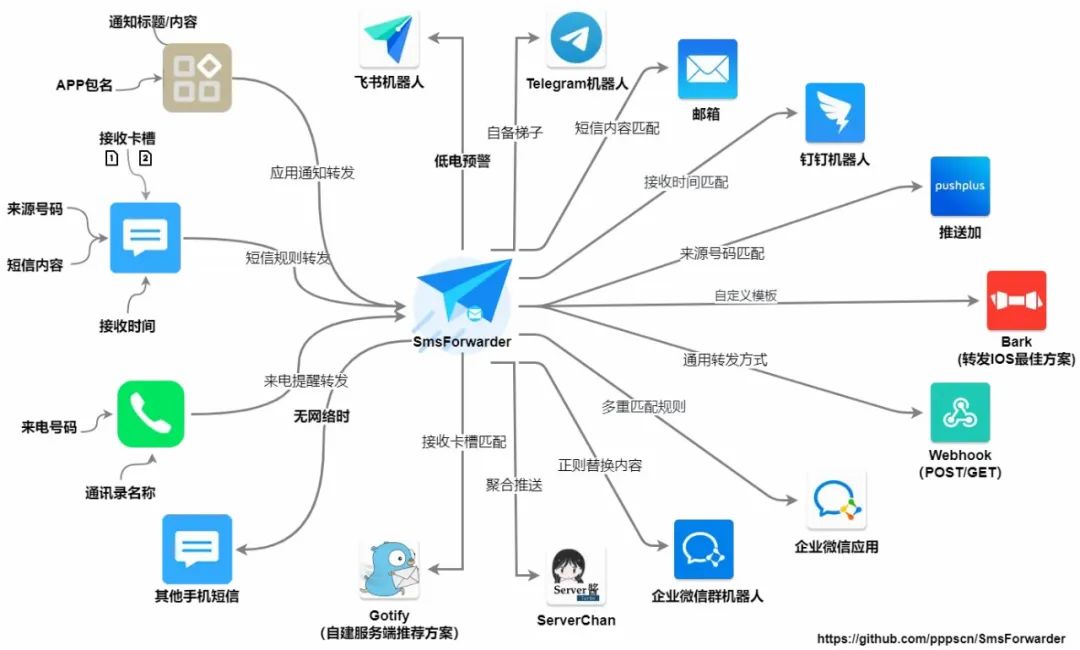
短信转发器工作流程图
官方制作了这么一张软件的工作流程图,可以清楚的知道这软件是怎么运行的,都有哪些功能,如果这张图看起来很吃力的话,那没有关系,因为它使用起来是很简单的,下面跟着我一起来看看怎么用的吧
软件界面图
界面设计相对简洁,有些词看起来可能很陌生,但不要紧,因为用到的并不多,只需要设置一下发送通道和转发规则,手机有电,软件在运行就可以了
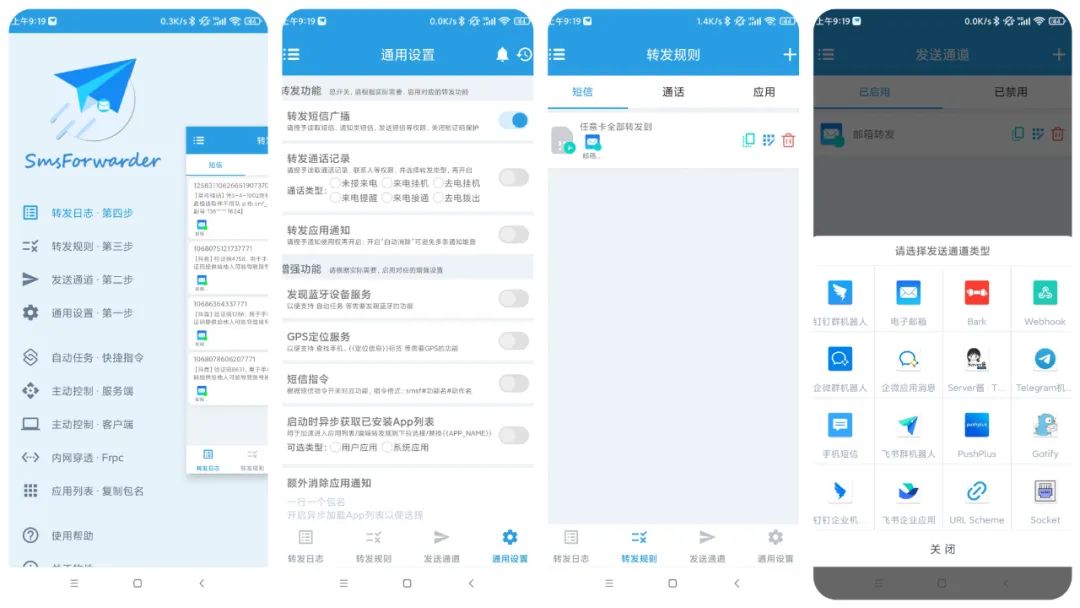
转发到手机短信
发送通道的类型非常多,有十几种,最适合小白用的还是手机短信和邮箱,像企业微信、钉钉这些,你要注册企业,tg又要魔法,总之就是阻碍非常多
手机短信的设置是最简单的,但是如果手机卡没有包含免费短信套餐的话,那发1条短信就是1毛钱,就算有免费短信套餐,也承受不了那么大的转发量,所以不是很划算
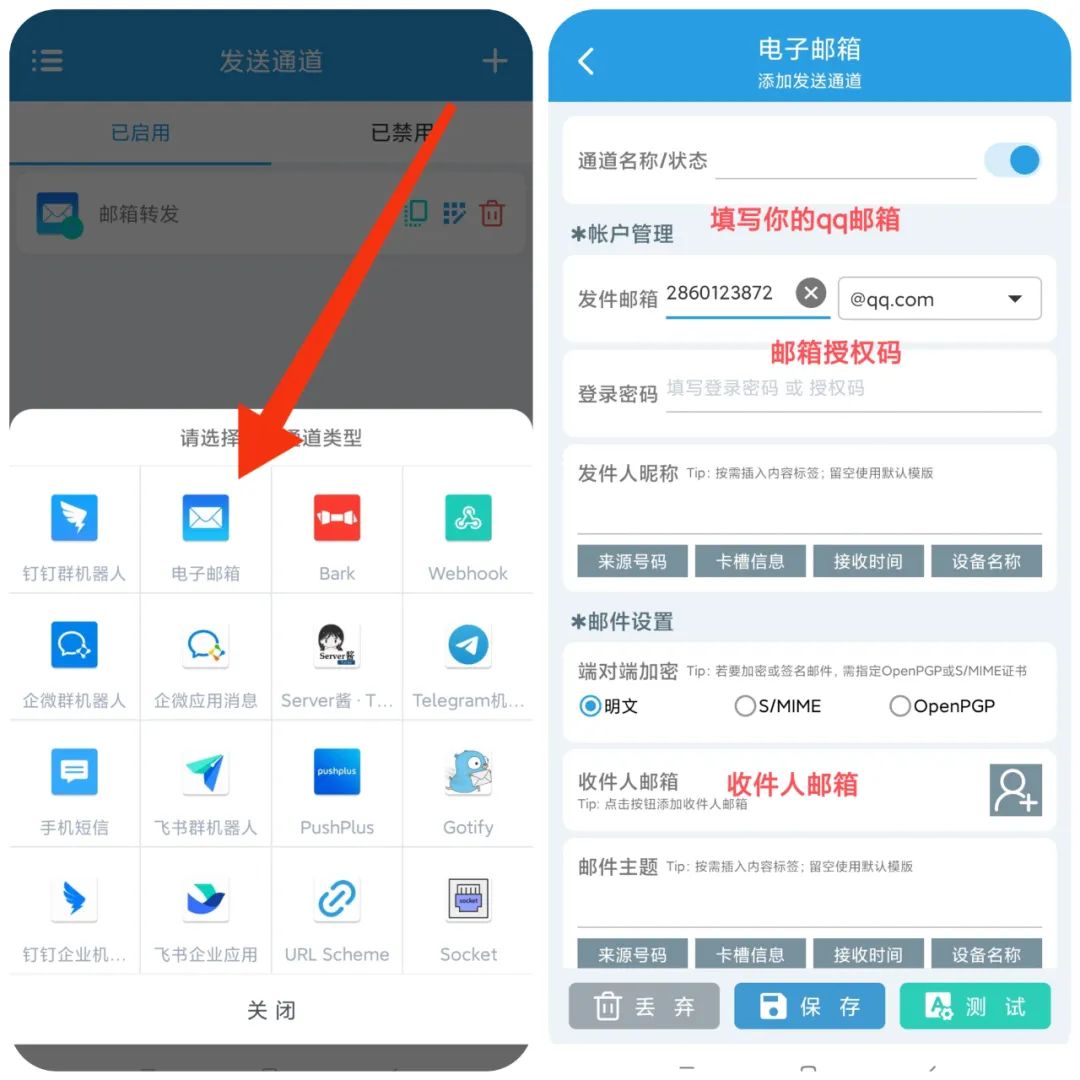
转发到邮箱
这里以QQ邮箱举例,在发送通道这里添加电子邮箱通道,名称就随便写了,然后填写你的QQ邮箱和授权码(我会在下面告诉你怎么获取),最后再填写一个收件的邮箱即可,点击保存
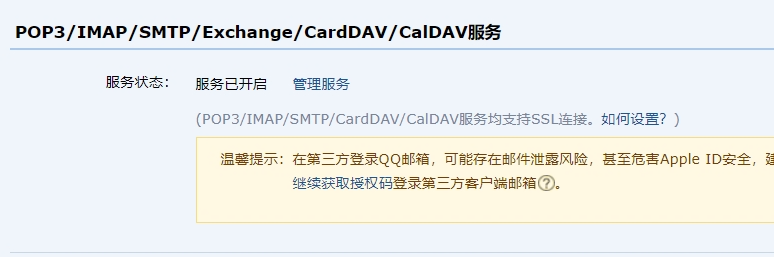
邮箱授权码获取
登录网页版的QQ邮箱,点击设置-账号,下拉找到POP3/IMAP服务,跟着他的提示一步步走去开启SMTP并获取授权码,获取到的授权码再填写到密码那一栏
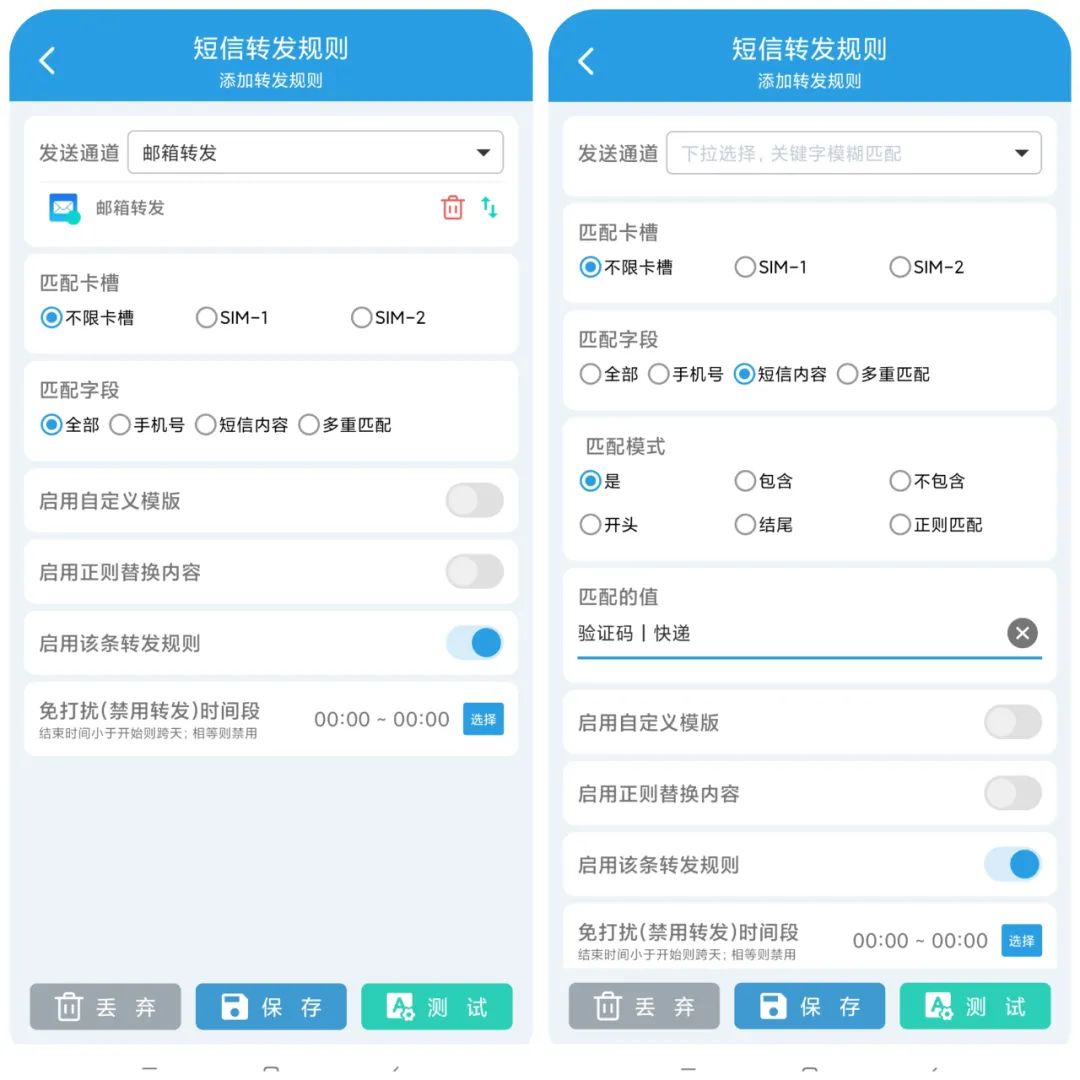
转发规则设置
发送通道选择刚刚创建的,如果不想折腾,那就和我一样,卡槽和匹配字段这里选择全部,如果只想转发某些特定的短信,那就可以在短信内容这里匹配相应的关键词,比如 验证码/快递之类的,点击保存,那么恭喜你,看到这里,短信转发你已经学会了
在手机上安装邮箱软件,登录你填写的收件邮箱,就可以愉快的收到各种短信了
常见问题
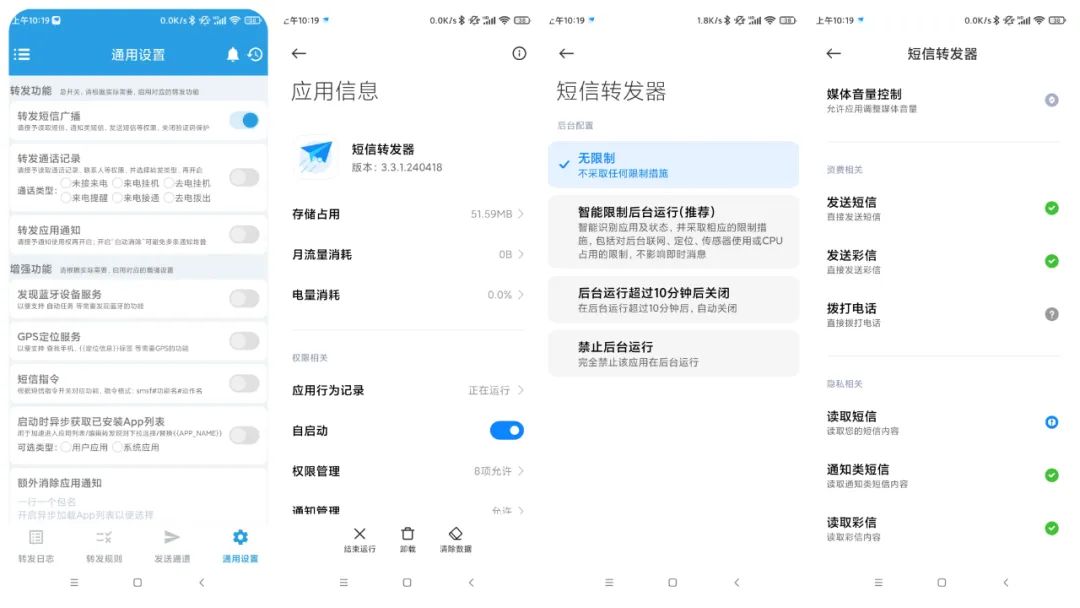
转发短信不成功?软件被杀后台,那是因为你没有开启对应的设置,首先软件自身的转发短信广播要打开,然后软件权限的自启动、省电策略改为无限制,以及读取发送短信的权限都要打开
下载链接
备用链接
https://pan.quark.cn/s/ea1b0e8b4704
以上就是本文的全部内容,我们下期再见,拜拜

















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









