









本期导读:
1 Spark源码定制选择从SparkStreaming入手;
2 Spark Streaming另类在线实验;
3 瞬间理解Spark Streaming本质。
今天是Spark定制班的第1课,这一课将成为我们未来发布Spark源码定制版本的引路石。
注:我们当前课程内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
1 Spark源码定制选择从Spark Streaming入手
我们从第一课就选择Spark子框架中的SparkStreaming。
那么,我们为什么要选择从SparkStreaming入手开始我们的Spark源码版本定制之路?
有下面几个方面的理由:
1)Spark大背景
Spark 最开始没有我们今天看到的Spark Streaming、GraphX、Machine Learning、Spark SQL和Spark R等相关子框架内容,最开始就只有很原始的Spark Core。我们要做Spark源码定制,做自己的发行版本,以SparkStreaming为切入点,Spark Streaming本身是 Spark Core上的一个子框架,所以我们透过一个子框架的彻底研究,肯定可以精通Spark力量的源泉和所有问题的解决之道;
2)为什么不选Spark SQL?
我们知道,Spark有很多子框架,现在除了基于Spark Core编程之外,用得最多的就是SparkSQL。Spark SQL由于涉及了太多的SQL语法细节的解析或者说优化,其实这些解析或优化,对于我们集 中精力去研究Spark而言,它是一件重要的事情,但其实不是最重要的一件事情。由于它有太多的SQL语法解析,这个不是一个合适的子框架来让我们研究。
3)为什么不选Spark R?
Spark R现在很不成熟,而且支持功能有限,这个也从我们的候选列表中删除掉。
4)为什么不选Spark GraphX(图计算)?
如果大家关注了Spark的演进或发展的话,Spark最近发布的几个版本,Spark图计算基本没有改进。如果按照这个趋势的话,Spark官方机构似乎 在透露一个信号,图计算已经发展到尽头了。所以说,我们如果要研究的话,肯定不会去做一个看上去发展到尽头的东西。另外,至于图计算而言,它有很多数学级 别的算法,而我们是要把Spark做到极致,这样的话,数学这件事情很重要,但对我们来说却不是最重要的。
5)为什么不选Spark MLlib(机器学习)?
Spark机器学习在封装了Vector(向量)和Metrics基础之上,加上Spark的RDD,构建了它的众多的库。这个也由于涉及到了太多的数学的知识,所以我们选机器学习其实也不是一个太好的选择。
综上所述,我们筛选之下,Spark Streaming是我们唯一的选择。
我 们回顾过去,2015年是Spark最火的一年,最火的国家主要是美国。其实,2015年也是流式处理最火的一年。从从业人员的待遇上看,不论2015年 还是2016年,在搞大数据开发的公司中,以Spark岗位招聘的待遇一定是最高的。2016上半年,据StackOverflow开展的一项调查结果显 示,在大数据领域,Spark从业人员的待遇是最高的。在调查中,50%以上的人认为,Spark中最吸引人的是Spark Streaming。总之,大家考虑用Spark,主要是因为Spark Streaming。
Spark Streaming到底有什么魔力?
1)它是流式计算
这是一个流处理的时代,一切数据如果不是流式的处理或者跟流式的处理不相关的话,都是无效的数据。这句话会不断地被社会的发展所证实。
2)流式处理才是真正的我们对大数据的初步印象
一方面,数据流进来,立即给我们一个反馈,这不是批处理或者数据挖掘能做到的。另一方面,Spark非常强大的地方在于它的流式处理可以在线的利用机器学习、图计算、Spark SQL或者Spark R的成果,这得益于Spark多元化、一体化的基础架构设计。也就是说,在Spark技术堆栈中,Spark Streaming可以调用任何的API接口,不需要做任何的设置。这是Spark无可匹敌之处,也是Spark Streaming必将一统天下的根源。这个时代的流处理单打独斗已经不行了,Spark Streaming必然会跟多个Spark子框架联合起来,称霸大数据领域。
3)流式处理“魅力和复杂”的双重体
如果你精通SparkStreaming,你就知道Spark Streaming以及它背后的兄弟框架,展示了Spark和大数据的无穷魅力。不过,在Spark的所有程序中,肯定是基于SparkStreaming的应用程序最容易出问题。为什么?因为数据不断流进来,它要动态控制数据的流入,作业的切分还有数据的处理。这些都会带来极大的复杂性。
4)与其他Spark子框架的巨大区别
如果你仔细观察,你会发现,Spark Streaming很像是基于Spark Core之上的一个应用程序。不像其他子框架,比如机器学习是把数学算法直接应用在Spark的RDD之上,Spark Streaming更像一般的应用程序那样,感知流进来的数据并进行相应的处理。
所以如果要做Spark的定制开发,Spark Streaming则提供了最好的参考,掌握了Spark Streaming也就容易开发任意其他的程序。当然想掌握SparkStreaming,但不去精通Spark Core的话,那是不可能的。Spark Core加Spark Streaming更是双剑合璧,威力无穷。我们选择SparkStreaming来入手,等于是找到了关键点。如果对照风水学的说法,对于Spark,我们算是已经幸运地找到了龙脉。如果要寻龙点穴,那么Spark Streaming就是龙穴之所在。找到了穴位,我们就能一日千里。
2 Spark Streaming另类在线实验
我们在研究Spark Streaming的过程中,会有困惑的事情:如何清晰的看到数据的流入、被处理的过程?
<pre name="code" class="html">package com.dt.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
/**
* <span style="font-family:Times New Roman;">使用Scala开发集群运行的Spark在线黑名单过滤程序</span>
* 新浪微博: http://weibo.com/ilovepains/
*/启动Spark集群:start-all.sh
启动Spark的History Server:start-history-server.sh
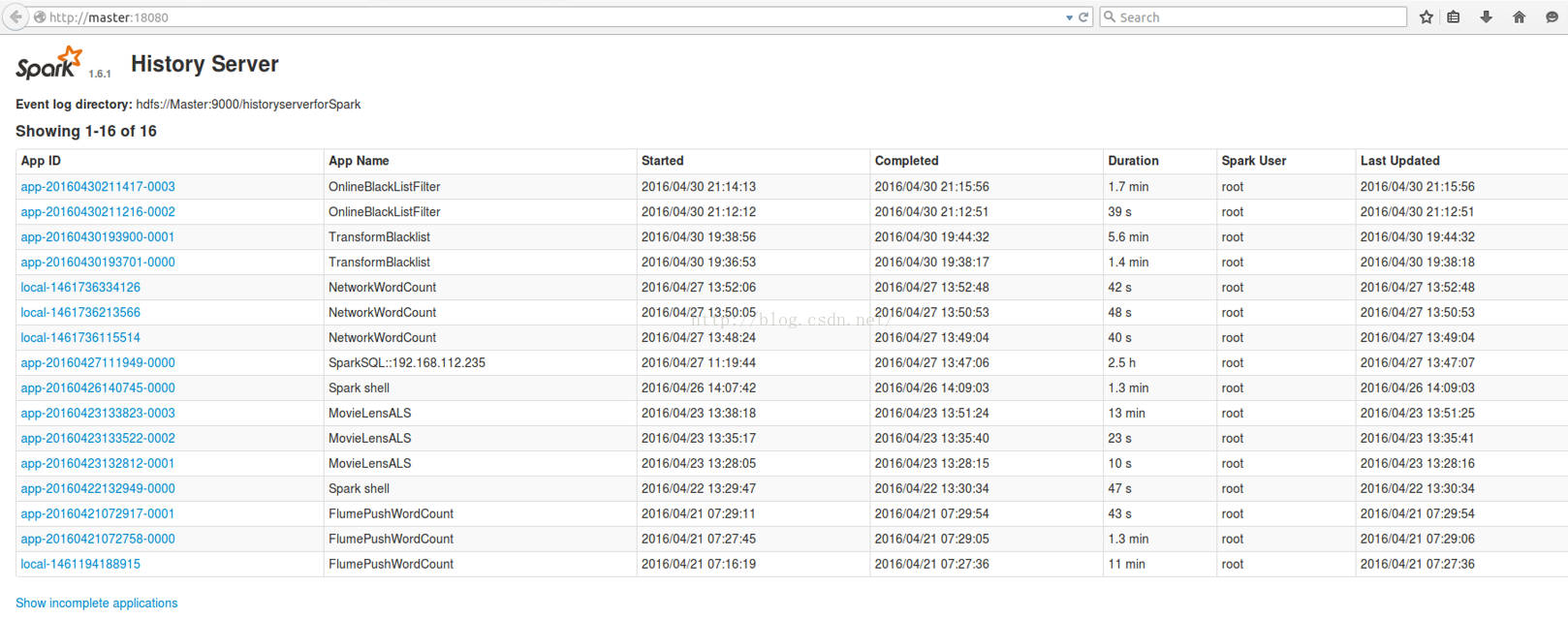
点击最新的应用,看我们目前运行的应用程序中有些什么Job:
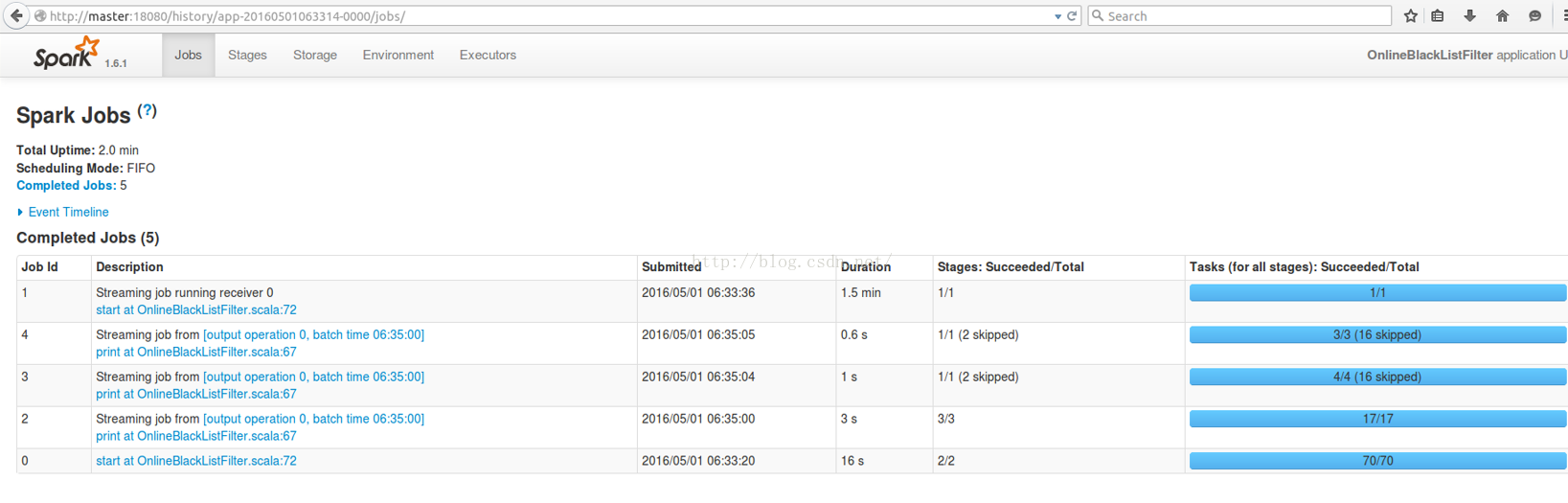
总共竟然有5个Job。这完全不是我们此前做Spark SQL之类的应用程序时看到的样子。
我们接下来看一看这些Job的内容,主要揭示一些现象,不会做完全深入的剖析,只是为了先让大家进行一些思考。
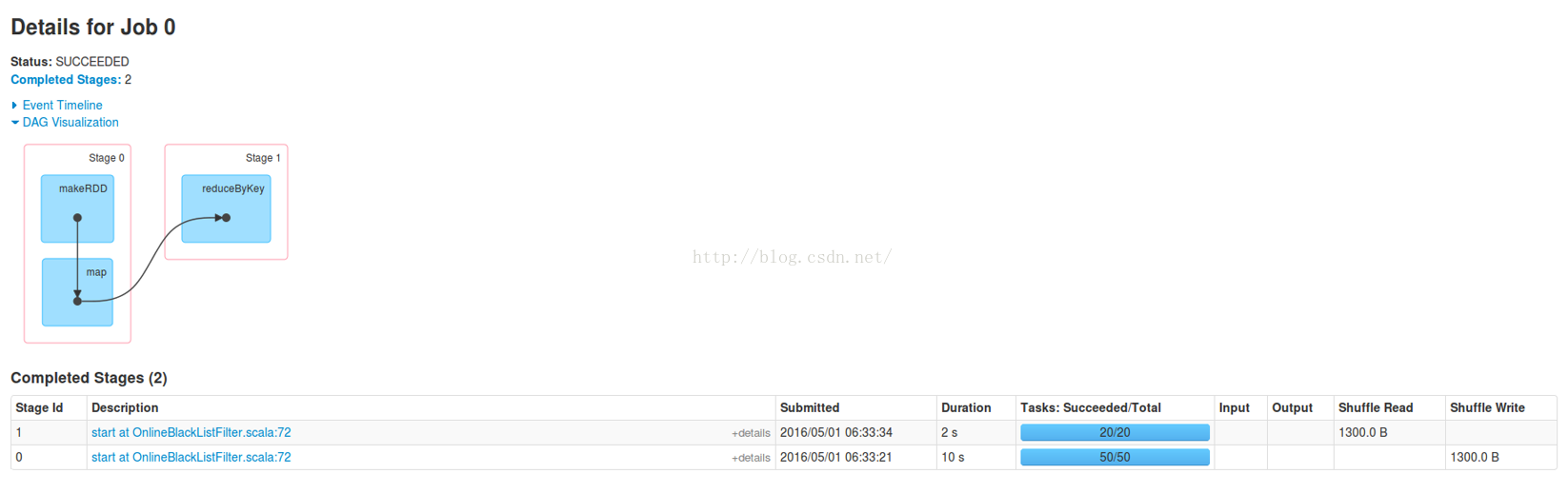
Job 0包含有Stage 0、Stage 1。随便看一个Stage,比如Stage 1。看看其中的Aggregated Metrics by Executor部分:

发现此Stage在所有Executor上都存在。
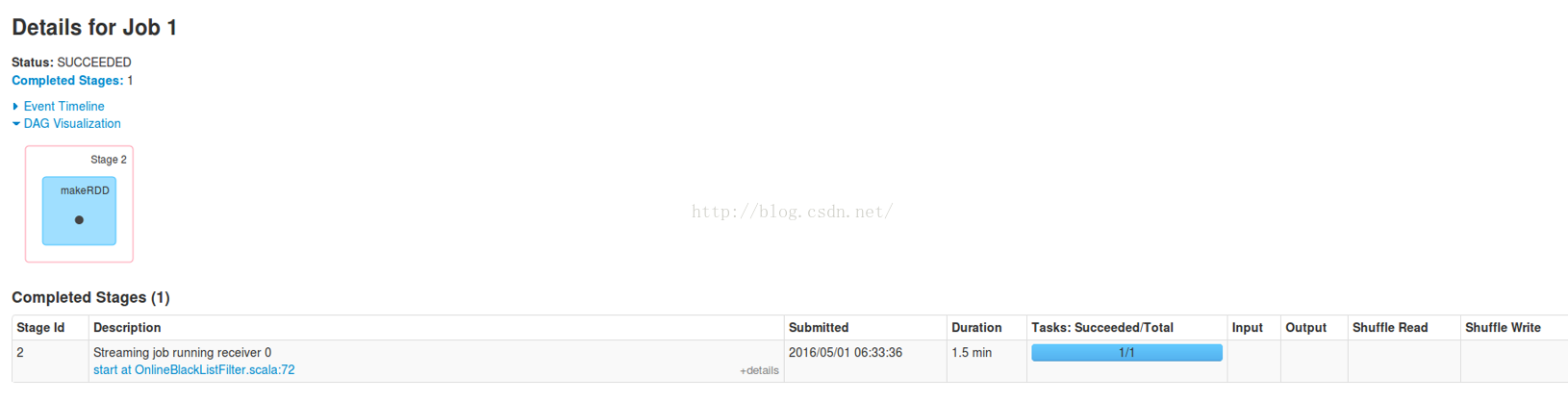
点击Stage 2的链接,进去看看Aggregated Metrics By Executor部分:

可以知道,Stage 2只在Worker4上的一个Executor执行,而且执行了1.5分钟。

原来Receiver是通过一个Job来启动的。那肯定有一个Action来触发它。

只有一个Worker运行此Job。是用于接收数据。
看来,Spark Streaming应用程序启动后,自己会启动一些Job。默认启动了一个Job来接收数据,为后续处理做准备。
重要启示:一个Spark应用程序中可以启动很多Job,而这些不同的Job之间可以相互配合。这一认识为我们写复杂Spark程序奠定了良好的基础。
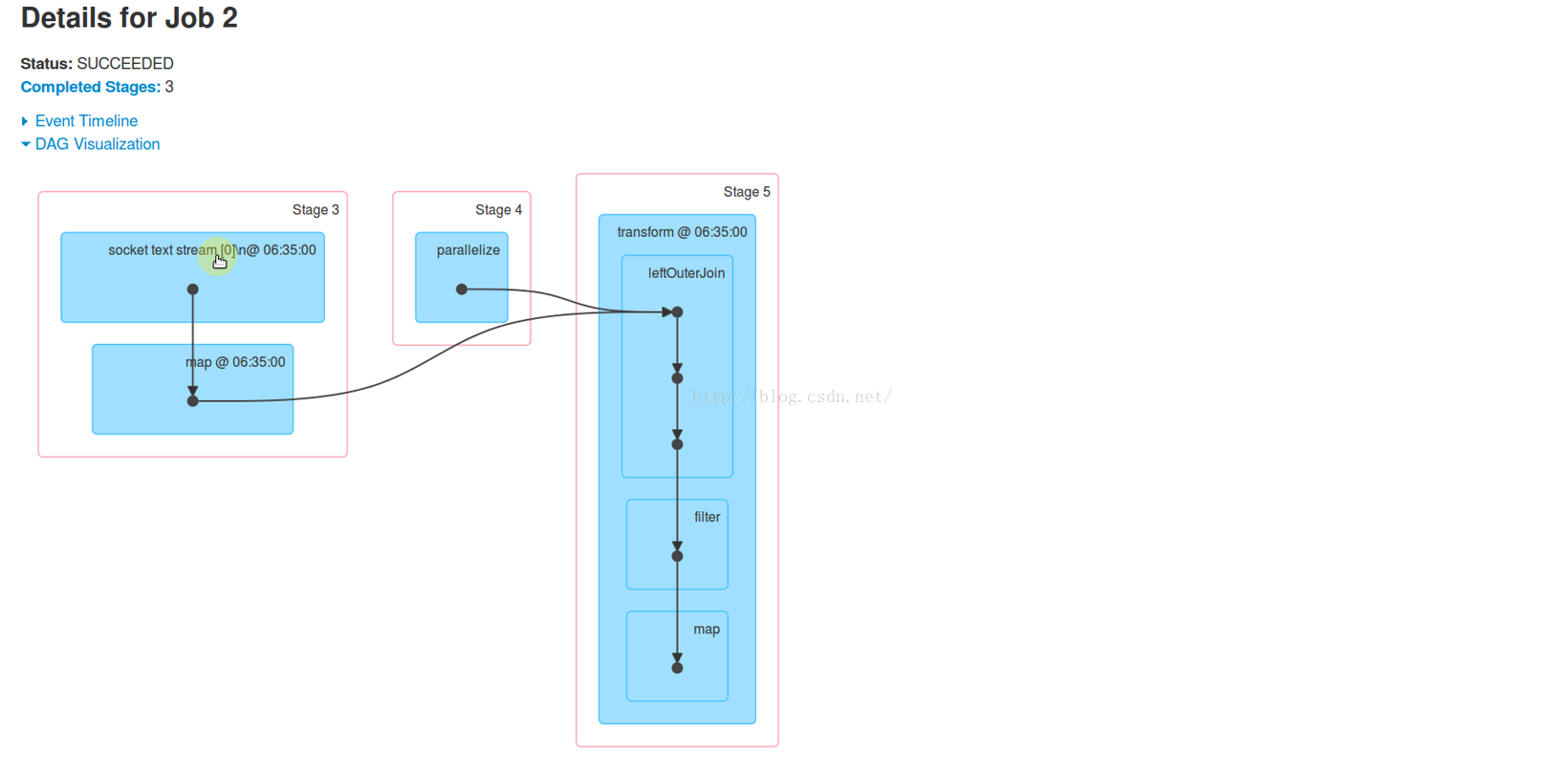
我们看Stag3、Stage4的详情,可以知道这2个Stage都是用4个Executor执行的。所有数据处理是在4台机器上进行的。

Stag 5只在Worker4上。这是因为这个Stage有Shuffle操作。

Job3:有Stage 6、Stage 7、Stage 8。其中Stage 6、Stage 7被跳过。
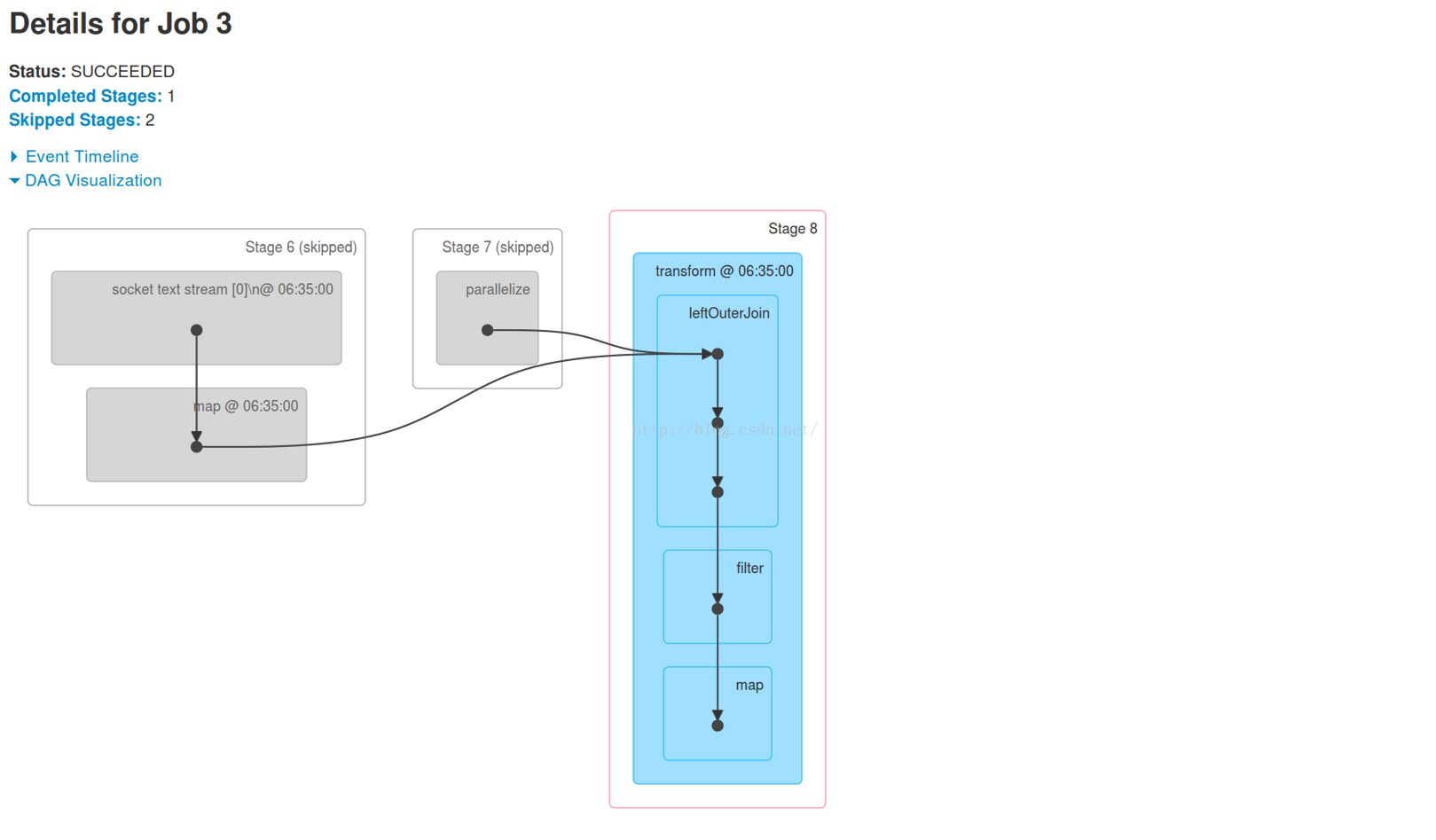
看看Stage 8的Aggregated Metrics by Executor部分。可以看到,数据处理是在4台机器上进行的:

Job4:也体现了我们应用程序中的业务逻辑 。有Stage 9、Stage 10、Stage 11。其中Stage 9、Stage 10被跳过。
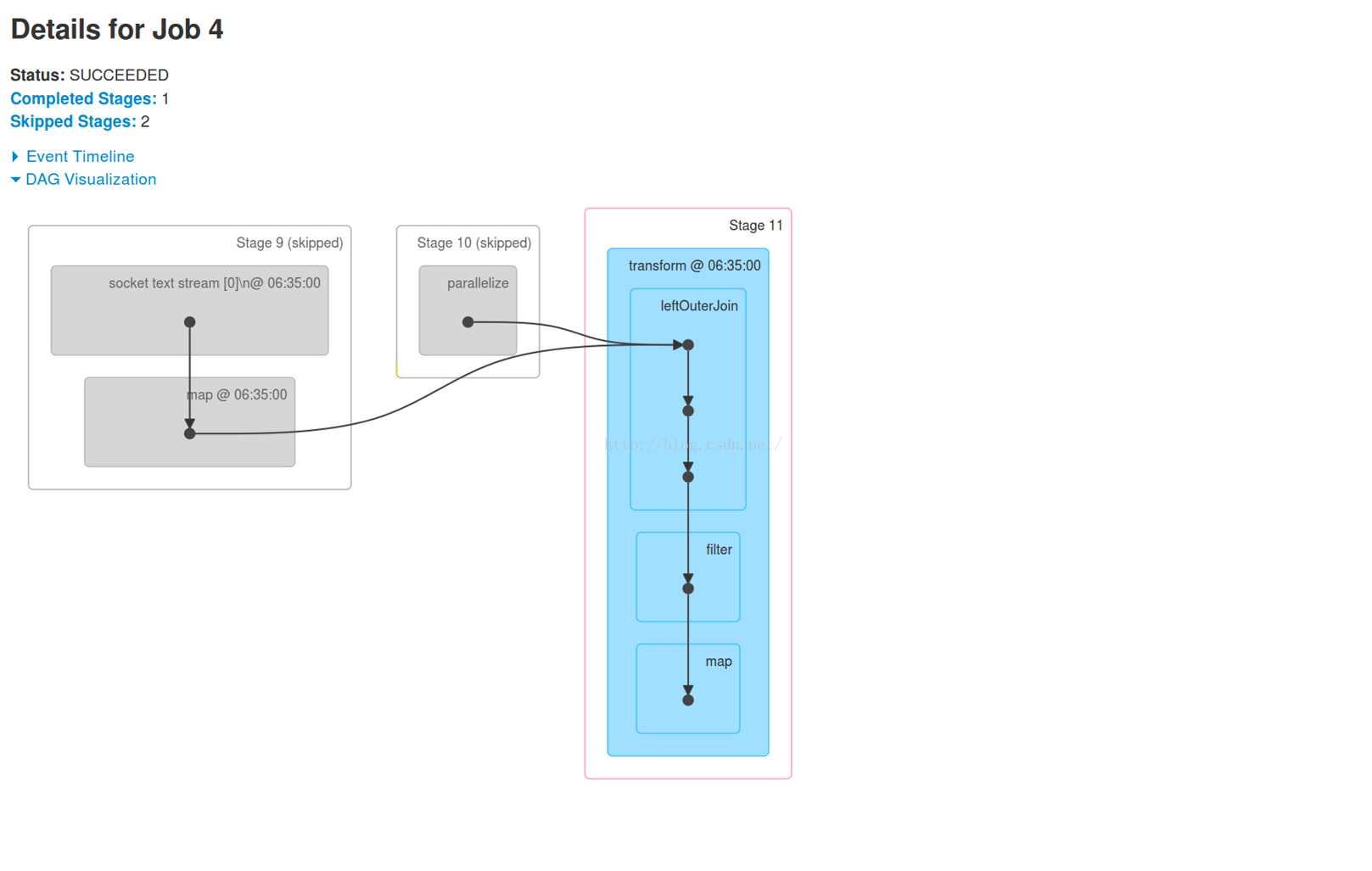
看看Stage 11的详情。可以看到,数据处理是在Worker2之外的其它3台机器上进行的:

综合以上的现象可以知道,Spark Streaming的一个应用中,运行了这么多Job,远不是我们从网络博客或者书籍上看的那么简单。
3 瞬间理解Spark Streaming本质
我们先看一张图:
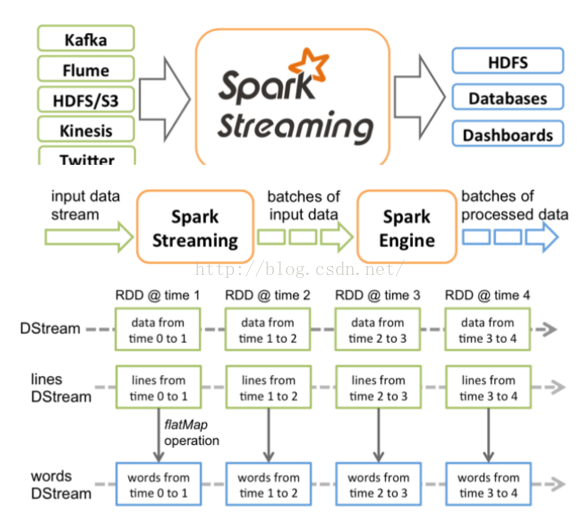
以上的连续4个图,分别对应以下4个段落的描述:
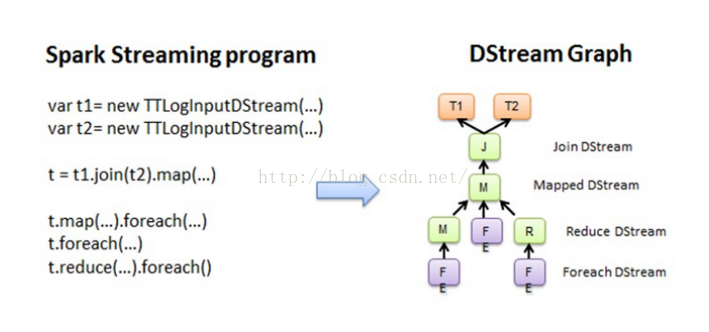
本例中,从每个foreach开始,都会进行回溯。从后往前回溯这些操作之间的依赖关系,也就形成了DStreamGraph。
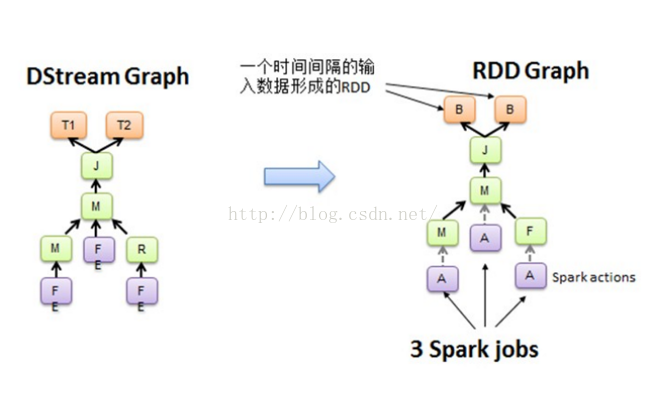
空间维度确定之后,随着时间不断推进,会不断实例化RDD Graph,然后触发Job去执行处理。
看来我们的学习,将从Spark Streaming的现象开始,深入到Spark Core和Spark Streaming的本质。

















 5451
5451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









