










还是老规矩,大家可能对凡哥不是很了解这里先和大家来个自我介绍
凡哥我已经有着十二年互联网自动化测试和测试开发工程师,拥有丰富的自动化测试平台及测试开发经验,擅长接口测试、Python自动化全栈,测试开发平台等,参与过亿级用户金融系统测试开发平台架构以及开发,曾主导过多家一线互联网公司自动化测试平台或自动化测试框架的搭建,参与项目涵盖金融、电商、教育等多个行业。好就介绍这么多,接下来就开始正题废话少说让我们开始把

然后基础篇到今天算是完结了,后续凡哥打算出python高阶:没对象 哦不是。是【面向对象编程】,透露一下python高阶:面向对象编程后面就准备出【python高阶:自动化相关技能持续更新中!】
各位觉得能学到些东西就麻烦大家点赞关注收藏三连

废话不多说!现在开始正文!
目录
函数的定义:1、数学意义的函数:两个变量:自变量x和因变量y,二者的关系
定义面向过程:过程 def ( 在Python中,过程是没有返回值的函数)
【第四节:Python函数值传递和引用传递(包括形式参数和实际参数的区别)】
,一个文件就是整个程序,用来被执行(比如你之前写的模拟博客园登录那个作业等) 二:模块
【第八节:人生苦短我用Python,本文助你快速入门】
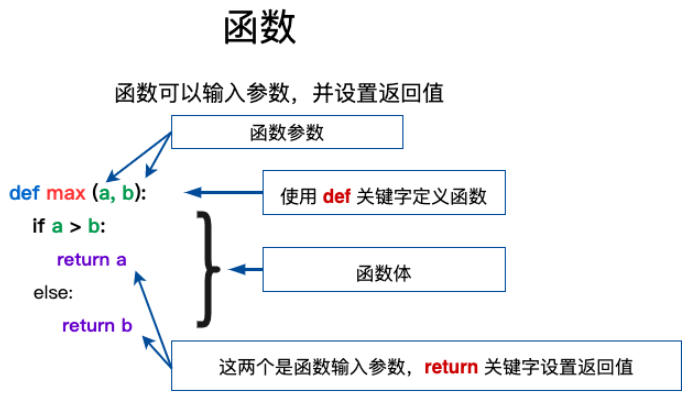
【第一节:python函数(def)以及函数分类】
定义函数
- 函数的定义
- 函数的分类
- 函数的创建方法
- 函数的返回return
函数的定义
- 将一件事情的步骤封装在一起并得到最终结果
- 函数名代表了这个函数要做的事情
- 函数体是实现函数功能的流程
- 函数可以帮助我们重复使用功能,通过函数名我们可以知道函数的作用
函数的分类
- 内置函数:print、id、int、max、min、type....等
- 自定义函数:def 创建函数
函数的创建方法
通过关键字def来创建函数,def的作用是实现python中函数的创建
函数定义过程:
def 函数名(参数列表): 函数体
# coding:utf-8 def say_Hello(): print("Hello Python")
函数的调用
函数名+()小括号执行函数
# coding:utf-8 # 定义函数 def say_Hello(): print("Hello Python") # 执行函数 say_Hello() # 执行结果:Hello Python
函数的返回return
- return-将函数结果返回的关键字
- return只能在函数体内使用
- return支持返回所有的python类型
- 有返回值的函数可以赋值给一个变量
- return也有退出函数的作用
# coding:utf-8 def add(a,b): c=a+b return c result=add(1,2) print(result) # 输出结果:3
函数的参数
- 必传参数
- 默认参数
- 不确定参数
- 参数规则
必传参数
- 函数中定义的参数没有默认值,在调用函数时如果不传入则会报错
- 在定义函数的时候,参数后边没有等号与默认值
- 在定义函数的时候,没有默认值且必须在函数执行的时候传递进去的参数,且顺序与参数的顺序相同,就是必传参数
# coding:utf-8 def add(a,b): c=a+b return c result=add(1,2) print(result) # 输出结果:3
默认参数
- 在定义函数的时候,定义的参数含有默认值,通过赋值语句给他是一个默认值
- 如果默认参数在调用函数的时候传递了新的值,函数将会优先使用后传入的值进行工作
# coding:utf-8 def add(a,b=1): c=a+b return c print(add(1)) # 输出结果:2 print(add(1,3)) # 输出结果:4
不确定参数-可变参数
- 没有固定的参数名和数量(不知道要传的参数名具体是什么)
- *args代表:将无参数的值合并成元组
- **kwargs代表:将有参数与默认值的赋值语句合并成字典
# coding:utf-8 def test_args(*args,**kwargs): print(args,type(args)) print(kwargs,type(kwargs)) test_args(1,2,3,4,5,6,name="zhangsan",age=22,top=175) # 输出结果: # (1, 2, 3, 4, 5, 6) <class 'tuple'> # {'name': 'zhangsan', 'age': 22, 'top': 175} <class 'dict'>
# coding:utf-8 #参数是变量传递时,需要在变量前面加上*和**来区分传递的是元组还是字典,否则一律按元组*args处理 def test_args(*args,**kwargs): print(args,type(args)) print(kwargs,type(kwargs)) a=('python','java') b={"name":"zhangsan","age":22,"top":175} test_args(a,b) # 输出结果: # (('python', 'java'), {'name': 'zhangsan', 'age': 22, 'top': 175}) <class 'tuple'> # {} <class 'dict'> test_args(*a,**b) # 输出结果: # ('python', 'java') <class 'tuple'> # {'name': 'zhangsan', 'age': 22, 'top': 175} <class 'dict'>
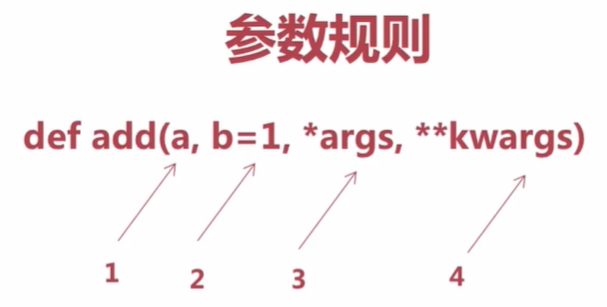
参数规则
- 参数的定义从左到右依次是:必传参数、默认参数、可变元组参数、可变字典参数
- 函数的参数传递非常灵活
- 必传参数与默认参数的传参多样化
- 传递的参数与函数定义时的参数顺序不一致时,使用赋值语句的方式传参
# coding:utf-8 def test(a,b=1,*args): print(a,b,args) s=(1,2) test(1,2,*s) #1 2 (1, 2) # test(a=1,b=2,*s) ''' Traceback (most recent call last): File "D:/WorkSpace/Python_Study/test01.py", line 8, in <module> test(a=1,b=2,*s) TypeError: test() got multiple values for argument 'a' ''' # 报错原因:当我们必选参数、默认参数与可选的元组类型参数在一起的时候,如果需要采取赋值的形式传参,则在定义函数的时候需要将可变的元组参数放在第一位,之后是必传、默认参数;这是一个特例!!! def test2(*args,a,b=1): print(a,b,args) test2(a=1,b=2,*s) #1 2 (1, 2)
# coding:utf-8 def test(a,b=1,**kwargs): print(a,b,kwargs) test(1,2,name="zhangsan") # 1 2 {'name': 'zhangsan'} test(a=1,b=2,name="zhangsan") # 1 2 {'name': 'zhangsan'} test(name="zhangsan",age=33,b=2,a=1) # 1 2 {'name': 'zhangsan', 'age': 33}

函数的参数类型
- 参数类型的定义在python3.7之后可用
- 函数不会对参数类型进行验证,只是看的作用
- 函数的参数类型具体是什么,还得看方法中对参数的操作
# coding:utf-8 def test(a:int,b:int=3,*args:int,**kwargs:str): print(a,b,args,kwargs) test(1,2,3,'4',name='zhangsan') # 1 2 (3, '4') {'name': 'zhangsan'}

全局变量与局部变量
- 全局变量
- 局部变量
- global
全局变量
函数体内对全局变量只能读取,不能修改
# coding:utf-8 name="法外狂徒张三" age=22 def test(): name="李四" print(name) print(age) test() #李四 22 print(name) #法外狂徒张三
局部变量
局部变量,无法在函数体外使用
# coding:utf-8 def test(): name="李四" print(name) #报错
global
- 将全局变量可以在函数体内进行修改
- global只支持str,int,float,tuple,bool,None类型。
- 对于list,dict不需要global声明即可应用自带方法在函数体内修改。
- 不建议使用global对全局变量进行修改
# coding:utf-8 name="法外狂徒张三" age=22 source={"数学":"100","英语":99,"语文":80} like=["足球","篮球","乒乓球"] drink=("雪碧","可乐") eat={"汉堡","薯条"} def test(): global name,age name="zhangsan" age=18 source["英语"]=60 like[2]="羽毛球" # drink[0]="百事" 元组不可变,报错 eat.update("鸡翅") test() print("%s,%s,%s,%s,%s,%s"%(name,age,source,like,drink,eat)) # 输出结果:zhangsan,18,{'数学': '100', '英语': 60, '语文': 80},['足球', '篮球', '羽毛球'],('雪碧', '可乐'),{'薯条', '翅', '汉堡', '鸡'}


递归函数
- 递归是一种常见的数学和编程概念。它意味着函数调用自身。这样做的好处是可以循环访问数据以达成结果,类似while和for循环
- 通过return返回def()自身,即可实现递归效果
# coding:utf-8 count=0 def test(): global count if count<=5: count +=1 return test() else: print("当前计数为:{}".format(count)) test() # 输出结果为:当前计数为:6
匿名函数
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- 自带return
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
# coding:utf-8 f=lambda x,y:x+y print(f(1,2)) #3 user=[{"name":"zhangsan"}, {"name":"lisi"}, {"name":"wangwu"}] user.sort(key=lambda x:x["name"]) print(user) #[{'name': 'lisi'}, {'name': 'wangwu'}, {'name': 'zhangsan'}]

【第二节:Python函数分类及操作】
为什么使用函数?
答:函数的返回值可以确切知道整个函数执行的结果
函数的定义:1、数学意义的函数:两个变量:自变量x和因变量y,二者的关系
2、Python中函数的定义:函数是逻辑结构化过程化得编程方法
定义面向过程:过程 def ( 在Python中,过程是没有返回值的函数)
1 #定义函数
2 def func1():
3 """testing"""
4 print('in the func1')
5 return 0
6
7 #定义过程
8 def func2():
9 """testing2"""
10 print("in the func2")
11
12 #调用函数
13 x=func1()
14
15 #调用过程
16 y=func2()
17 print("from func1 return is %s "%x)
18 print("from func2 return is %s "%y)
传参:
1.默认参数特点
:调用函数时,默认参数可有可无,非必须传递。传递后可以修改默认值,不传递则按照默认值输出
用途:1.默认安装 2.数据库连接,默认端口号
1 def test(x,y=2): 2 print(x) 3 print(y) 4 test(1,3) 此处设置y默认为2,调用时可以不传值。
2.关键字调用 print(y=2,x=1)
输出结果 1,2 与形参位置无关。 与形参数量必须匹配
3.位置参数调用:与形参的位置一一对应赋值print(1,2) 1,2
4.二者混用,按照位置参数调用来
关键参数不可以写在位置参数前面
5.(非固定参数)参数组:调用时,超过或少于形参的的数量个数,则报错
#实参的数量不固定的情况下,则形参如何定义?
共有两种方式
元祖形式及混合形式:
1 #实参的数量不固定的情况下,则形参如何定义? 2 #方法一 3 def test(*args): 4 print(args) 5 test(1,2,3,4,5) 6 #方法二 7 test(*[1,2,3,4,5])#*args=*[1,2,3,4,5] *args 接受n个位置参数,结果以元祖形式输出 8 #位置参数和参数组结合起来定义 9 def test(x,*args): 10 print(x) 11 print(args) 12 test(1,2,3,4,5,6,7)
位置参数和参数组结合,输出结果是1,(2,3,4,5,6,7).按照定义类型进行传参
test(tuple[1,2,3,4,5]) 报错:'type' object is not subscriptable “类型”对象不可下标 语法错误。
字典形式及混合形式:
1 #**kwargs 把关键字参数转换成字典的形式输出,接受n个关键字参数
2 def test(**kwargs):
3 print(kwargs)
4 #结果从字典中只取出值来打印
5 print(kwargs['name'])
6 print(kwargs['age'])
7 test(name='zhang',age=1,sex='women')#此处使用位置参数
8 #直接以字典的形式输出
9 '''**kargs test(name='zhang',age=1,sex='women')==
10 test({name='zhang',age=1,sex='women'})#关键字的方式去赋值'''
11 #字典和位置参数共用
12 def test(name,age=1,**kwargs):#关键参数放到参数组前面
13 #结果从字典中只取出值来打印
14 print(name)
15 print(age)
16 print(kwargs)
(二)函数递归:函数在内部调用自己
1.必须有明确的结束条件
报错: maximum recursion depth exceeded in comparison 超过最大递归次数(999)
2.每次进入更深一层的递归时,问题的规模较上次都要有所减少
3.递归的效率不高,递归的层次过多会导致溢出。(在计算机中,函数调用时通过栈这种数据结构实现的,每当进入一个函数调用,栈就会增加一层栈帧,每当退出一层函数调用,栈就会减少一层栈帧。由于栈的大小不是无限的,,所以函数调用次数越多,会导致栈溢出。)
函数分类:
函数式编程:纯函数式编程,无变量,只要输入是确定的,输出就是确定的
高阶函数:
变量可以指向参数,函数的参数能接收变量,那么一个函数就能够接收另一个函数作为参数,这种函数就成为高阶函数。
内置函数;
b=eval(b) 通过内置函数eval转成字典
附:
Python的回收机制是解释器执行的,Python解释器中有引用计数。固定时间内会即时刷新,清空掉没有引用的内容。释放内存
变量的内存回收机制:没有引用(定义了语句del,删除值的变量名),立马回收。否则直到程序结束才会回收。
【第三节:Python匿名函数、回调函数和高阶函数】
1、定义匿名或内联函数
如果我们想提供一个短小的回调函数供sort()这样的函数用,但不想用def这样的语句编写一个单行的函数,我们可以借助lambda表达式来编写“内联”式的函数。如下图所示:
add = lambda x, y: x + y
print(add(2, 3)) # 5
print(add("hello", "world!")) # helloworld
可以看到,这里用到的lambda表达式和普通的函数定义有着相同的功能。lambda表达式常常做为回调函数使用,有在排序以及对数据进行预处理时有许多用武之地,如下所示:
names = [ 'David Beazley', 'Brian Jones', 'Reymond Hettinger', 'Ned Batchelder']
sorted_names = sorted(names, key=lambda name: name.split()[-1].lower())
print(sorted_names)
# ['Ned Batchelder', 'David Beazley', 'Reymond Hettinger', 'Brian Jones']
lambda虽然灵活易用,但是局限性也大,相当于其函数体中只能定义一条语句,不能执行条件分支、迭代、异常处理等操作。
2、在匿名函数中绑定变量的值
现在我们想在匿名函数定义时完成对特定变量(一般是常量)的绑定,以便后期使用。如果我们这样写:
x = 10
a = lambda y: x + y
x = 20
b = lambda y: x + y
然后计算a(10)和b(10)。你可能希望结果是20和30,然而实际程序的运行结果会出人意料:结果是30和30。
这个问题的关键在于lambda表达式中的x是个自由变量(未绑定到本地作用域的变量),在运行时绑定而不是定义的时候绑定(其实普通函数中使用自由变量同理),而这里执行a(10)的时候x已经变成了20,故最终a(10)的值为30。如果希望匿名函数在定义的时候绑定变量,而之后绑定值不再变化,那我们可以将想要绑定的变量做为默认参数,如下所示:
x = 10
a = lambda y, x=x: x + y
x = 20
b = lambda y, x=x: x + y
print(a(10)) # 20
print(b(10)) # 30
上面我们提到的这个陷阱常见于一些对lambda函数过于“聪明”的应用中。比如我们想用列表推导式来创建一个列表的lambda函数并期望lambda函数能记住迭代变量。
funcs = [lambda x: x + n for n in range(5)]
for f in funcs:
print(f(0))
# 4
# 4
# 4
# 4
# 4
可以看到与我们期望的不同,所有lambda函数都认为n是4。如上所述,我们修改成以下代码即可:
funcs = [lambda x, n=n: x + n for n in range(5)]
for f in funcs:
print(f(0))
# 0
# 1
# 2
# 3
# 4
2、让带有n个参数的可调用对象以较少的参数调用
假设我们现在有个n个参数的函数做为回调函数使用,但这个函数需要的参数过多,而回调函数只能有个参数。如果需要减少函数的参数数量,需要时用functools包。functools这个包内的函数全部为高阶函数。高阶函数即参数或(和)返回值为其他函数的函数。通常来说,此模块的功能适用于所有可调用对象。
比如functools.partial()就是一个高阶函数, 它的原型如下:
functools.partial(func, /, *args, **keywords)
它接受一个func函数做为参数,并且它会返回一个新的newfunc对象,这个新的newfunc对象已经附带了位置参数args和关键字参数keywords,之后在调用newfunc时就可以不用再传已经设定好的参数了。如下所示:
def spam(a, b, c, d):
print(a, b, c, d)
from functools import partial
s1 = partial(spam, 1) # 设定好a = 1(如果没指定参数名,默认按顺序设定)
s1(2, 3, 4) # 1 2 3 4
s2 = partial(spam, d=42) # 设定好d为42
s2(1, 2, 3) # 1 2 3 42
s3 = partial(spam, 1, 2, d=42) #设定好a = 1, b = 2, d = 42
s3(3) # 1 2 3 42
上面提到的技术常常用于将不兼容的代码“粘”起来,尤其是在你调用别人的轮子,而别人写好的函数不能修改的时候。比如我们有以下一组元组表示的点的坐标:
points = [(1, 2), (3, 4), (5, 6), (7, 8)]
有已知的一个distance()函数可供使用,假设这是别人造的轮子不能修改。
import math
def distance(p1, p2):
x1, y1 = p1
x2, y2 = p2
return math.hypot(x2 - x1, y2 - y1)
接下来我们想根据列表中这些点到一个定点pt=(4, 3)的距离来排序。我们知道列表的sort()方法
可以接受一个key参数(传入一个回调函数)来做自定义的排序处理。但传入的回调函数只能有一个参数,这里的distance()函数有两个参数,显然不能直接做为回调函数使用。下面我们用partical()来解决这个问题:
pt = (4, 3)
points.sort(key=partial(distance, pt)) # 先指定好一个参数为pt=(4,3)
print(points)
# [(3, 4), (1, 2), (5, 6), (7, 8)]
可以看到,排序正确运行。还有一种方法要臃肿些,那就是将回调函数distance嵌套进另一个只有一个参数的lambda函数中:
pt = (4, 3)
points.sort(key=lambda p: distance(p, pt))
print(points)
# [(3, 4), (1, 2), (5, 6), (7, 8)]
这种方法一来臃肿,二来仍然存在我们上面提到过的一个毛病,如果我们定义回调函数后对pt有所修改,就会发生我们上面所说的不愉快的事情:
pt = (4, 3)
func_key = lambda p: distance(p ,pt)
pt = (0, 0) # 像这样,后面pt变了就GG
points.sort(key=func_key)
print(points)
# [(1, 2), (3, 4), (5, 6), (7, 8)]
可以看到,最终排序的结果由于后面pt的改变而变得完全不同了。所以我们还是建议大家采用使用functools.partial()函数来达成目的。
下面这段代码也是用partial()函数来调整函数签名的例子。这段代码利用multiprocessing模块以异步方式计算某个结果,然后用一个回调函数来打印该结果,该回调函数可接受这个结果和一个事先指定好的日志参数。
# result:回调函数本身该接受的参数, log是我想使其扩展的参数
def output_result(result, log=None):
if log is not None:
log.debug('Got: %r', result)
def add(x, y):
return x + y
if __name__ == '__main__':
import logging
from multiprocessing import Pool
from functools import partial
logging.basicConfig(level=logging.DEBUG)
log = logging.getLogger('test')
p = Pool()
p.apply_async(add, (3, 4), callback=partial(output_result, log=log))
p.close()
p.join()
# DEBUG:test:Got: 7
下面这个例子则源于一个在编写网络服务器中所面对的问题。比如我们在socketServer模块的基础上,编写了下面这个简单的echo服务程序:
from socketserver import StreamRequestHandler, TCPServer
class EchoHandler(StreamRequestHandler):
def handle(self):
for line in self.rfile:
self.wfile.write(b'GoT:' + line)
serv = TCPServer(('', 15000), EchoHandler)
serv.serve_forever()
现在,我们想在EchoHandler类中增加一个__init__()方法,它接受额外的一个配置参数,用于事先指定ack。即:
class EchoHandler(StreamRequestHandler):
def __init__(self, *args, ack, **kwargs):
self.ack = ack
super().__init__(*args, **kwargs)
def handle(self) -> None:
for line in self.rfile:
self.wfile.write(self.ack + line)
假如我们就这样直接改动,就会发现后面会提示__init__()函数缺少keyword-only参数ack(这里调用EchoHandler()初始化对象的时候会隐式调用__init__()函数)。 我们用partical()也能轻松解决这个问题,即为EchoHandler()事先提供好ack参数。
from functools import partial
serv = TCPServer(('', 15000), partial(EchoHandler, ack=b'RECEIVED'))
serv.serve_forever()
3、在回调函数中携带额外的状态
我们知道,我们调用回调函数后,就会跳转到一个全新的环境,此时会丢失我们原本的环境状态。接下来我们讨论如何在回调函数中携带额外的状态以便在回调函数内部使用。
因为对回调函数的应用在与异步处理相关的库和框架中比较常见,我们下面的例子也多和异步处理相关。现在我们定义了一个异步处理函数,它会调用一个回调函数。
def apply_async(func, args, *, callback):
# 计算结果
result = func(*args)
# 将结果传给回调函数
callback(result)
下面展示上述代码如何使用:
# 要回调的函数
def print_result(result):
print("Got: ", result)
def add(x, y):
return x + y
apply_async(add, (2, 3), callback=print_result)
# Got: 5
apply_async(add, ('hello', 'world'), callback=print_result)
# Got: helloworld
现在我们希望回调函数print_reuslt()能够接受更多的参数,比如其他变量或者环境状态信息。比如我们想让print_result()函数每次的打印信息都包括一个序列号,以表示这是第几次被调用,如[1] ...、[2] ...这样。首先我们想到,可以用额外的参数在回调函数中携带状态,然后用partial()来处理参数个数问题:
class SequenceNo:
def __init__(self) -> None:
self.sequence = 0
def handler(result, seq):
seq.sequence += 1
print("[{}] Got: {}".format(seq.sequence, result))
seq = SequenceNo()
from functools import partial
apply_async(add, (2, 3), callback=partial(handler, seq=seq))
# [1] Got: 5
apply_async(add, ('hello', 'world'), callback=partial(handler, seq=seq))
# [2] Got: helloworld
看起来整个代码有点松散繁琐,我们有没有什么更简洁紧凑的方法能够处理这个问题呢?答案是直接使用和其他类绑定的方法(bound-method)。比如面这段代码就将print_result做为一个类的方法,这个类保存了计数用的ack序列号,每当调用print_reuslt()打印一个结果时就递增1:
class ResultHandler:
def __init__(self) -> None:
self.sequence = 0
def handler(self, result):
self.sequence += 1
print("[{}] Got: {}".format(self.sequence, result))
apply_async(add, (2, 3), callback=r.handler)
# [1] Got: 5
apply_async(add, ('hello', 'world'), callback=r.handler)
# [2] Got: helloworld
还有一种实现方法是使用闭包,这种方法和使用类绑定方法相似。但闭包更简洁优雅,运行速度也更快:
def make_handler():
sequence = 0
def handler(result):
nonlocal sequence # 在闭包中编写函数来修改内层变量,需要用nonlocal声明
sequence += 1
print("[{}] Got: {}".format(sequence, result))
return handler
handler = make_handler()
apply_async(add, (2, 3), callback=handler)
# [1] Got: 5
apply_async(add, ('hello', 'world'), callback=handler)
# [2] Got: helloworld
最后一种方法,则是利用协程(coroutine)来完成同样的任务:
def make_handler_cor():
sequence = 0
while True:
result = yield
sequence += 1
print("[{}] Got: {}".format(sequence, result))
handler = make_handler_cor()
next(handler) # 切记在yield之前一定要加这一句
apply_async(add, (2, 3), callback=handler.send) #对于协程来说,可以使用它的send()方法来做为回调函数
# [1] Got: 5
apply_async(add, ('hello', 'world'), callback=handler.send)
# [2] Got: helloworld【第四节:Python函数值传递和引用传递(包括形式参数和实际参数的区别)】
通常情况下,定义函数时都会选择有参数的函数形式,函数参数的作用是传递数据给函数,令其对接收的数据做具体的操作处理。
在使用函数时,经常会用到形式参数(简称“形参”)和实际参数(简称“实参”),二者都叫参数,之间的区别是:
- 形式参数:在定义函数时,函数名后面括号中的参数就是形式参数,例如:大理石平台构件_矿物铸件_大理石组装_花岗岩维修-[富瑞华]
-
#定义函数时,这里的函数参数 obj 就是形式参数
-
def demo(obj)
-
print(obj)
-
- 实际参数:在调用函数时,函数名后面括号中的参数称为实际参数,也就是函数的调用者给函数的参数。例如:
- a = "C语言中文网"
- #调用已经定义好的 demo 函数,此时传入的函数参数 a 就是实际参数
- demo(a)
实参和形参的区别,就如同剧本选主角,剧本中的角色相当于形参,而演角色的演员就相当于实参。
明白了什么是形参和实参后,再来想一个问题,那就是实参是如何传递给形参的呢?
Python 中,根据实际参数的类型不同,函数参数的传递方式可分为 2 种,分别为值传递和引用(地址)传递:
- 值传递:适用于实参类型为不可变类型(字符串、数字、元组);
- 引用(地址)传递:适用于实参类型为可变类型(列表,字典);
值传递和引用传递的区别是,函数参数进行值传递后,若形参的值发生改变,不会影响实参的值;而函数参数继续引用传递后,改变形参的值,实参的值也会一同改变。
例如,定义一个名为 demo 的函数,分别为传入一个字符串类型的变量(代表值传递)和列表类型的变量(代表引用传递):
- def demo(obj) :
- obj += obj
- print("形参值为:",obj)
- print("-------值传递-----")
- a = "C语言中文网"
- print("a的值为:",a)
- demo(a)
- print("实参值为:",a)
- print("-----引用传递-----")
- a = [1,2,3]
- print("a的值为:",a)
- demo(a)
- print("实参值为:",a)
运行结果为:
-------值传递-----
a的值为: C语言中文网
形参值为: C语言中文网C语言中文网
实参值为: C语言中文网
-----引用传递-----
a的值为: [1, 2, 3]
形参值为: [1, 2, 3, 1, 2, 3]
实参值为: [1, 2, 3, 1, 2, 3]
分析运行结果不难看出,在执行值传递时,改变形式参数的值,实际参数并不会发生改变;而在进行引用传递时,改变形式参数的值,实际参数也会发生同样的改变。
【第五节:python的模块定义及分类】
一、什么是模块?
储着很多常用的功能的py文件,就是模块。 模块就是文件,存放一堆常用的函数。
一个函数就是一个功能,那么把一些常用的函数放在一个py文件中,这个文件就称之为模块,模块就是一些常用功能的集合体。
二、为什么要使用模块?
1、从文件级别组织程序,更方便管理。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用。
2、拿来主义,提升开发效率。
同样的原理,我们也可以下载别人写好的模块然后导入到自己的项目中使用,这种拿来主义,可以极大地提升我们的开发效率,避免重复造轮子。
三、模块的分类
Python语言中,模块分为三类:
第一类:内置模块,也叫做标准库。此类模块就是python解释器给你提供的,比如我们之前见过的time模块,os模块。标准库的模块非常多(200多个,每个模块又有很多功能)。
第二类:第三方模块,第三方库。一些python大神写的非常好用的模块,必须通过pip install 指令安装的模块,比如BeautfulSoup, Django,等等。大概有6000多个。
第三类:自定义模块。我们自己在项目中定义的一些模块。
四、import与from....import的区别
import:中文就是导入的意思
例如:import os
from...import..:从某个模块(文件)中导入某个函数
例如:from view import Book
如何解决重复导入:
针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句。
五、py文件的功能
python模块的文件名后缀就是py。例如:test.py
编写好的一个python文件可以有两种用途:
一:脚本
,一个文件就是整个程序,用来被执行(比如你之前写的模拟博客园登录那个作业等)
二:模块
,文件中存放着一堆功能,用来被导入使用
python为我们内置了全局变量__name__,
当文件被当做脚本执行时:__name__ 等于'__main__'
当文件被当做模块导入时:__name__等于模块名
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
六、模块的应用规则
Python中引用模块是按照一定的规则以及顺序去寻找的。
这个查询顺序为:先从内存中已经加载的模块进行寻找找不到再从内置模块中寻找,内置模块如果也没有,最后去sys.path中路径包含的模块中寻找。
它只会按照这个顺序从这些指定的地方去寻找,如果最终都没有找到,那么就会报错。
内存中已经加载的模块->内置模块->sys.path路径中包含的模块
模块的查找顺序
-
在第一次导入某个模块时(比如tbjx),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用(ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看)
-
如果没有,解释器则会查找同名的内置模块
-
如果还没有找到就从sys.path给出的目录列表中依次寻找tbjx.py文件。
特别注意的是:我们自定义的模块名不应该与系统内置模块重名。
【第六节:python模块导入】
python中模块导入
在此之前先说一个方法和一个变量:sys.path 和内置变量 __name__
我的文件目录
导入 |||a |||||||||b ||||||||||||||||||-__init__ ||||||||||||||||||c1.py ||||||||||||||||||c2.py |||||||||__init__ |||||||||b1.py |||||||||b2.py |||__init__ |||a1.py |||a2.py
sys.path:python搜索模块的路径集,返回结果是一个list集合
# a1.py import sys print(sys.path) # 运行结果 ''' F:\python\学习\学习demo\导入 F:\python\学习 D:\python\pycharm-3.2\PyCharm 2020.3.2\plugins\python\helpers\pycharm_display F:\python\学习\venv\Scripts\python36.zip D:\python\python-3.6\DLLs D:\python\python-3.6\lib D:\python\python-3.6 F:\python\学习\venv F:\python\学习\venv\lib\site-packages F:\python\学习\venv\lib\site-packages\setuptools-40.8.0-py3.6.egg F:\python\学习\venv\lib\site-packages\pip-19.0.3-py3.6.egg D:\python\pycharm-3.2\PyCharm 2020.3.2\plugins\python\helpers\pycharm_matplotlib_backend ''' # c1.py import sys print(sys.path) # 运行结果 ''' F:\python\学习\学习demo\导入\a\b F:\python\学习 D:\python\pycharm-3.2\PyCharm 2020.3.2\plugins\python\helpers\pycharm_display F:\python\学习\venv\Scripts\python36.zip D:\python\python-3.6\DLLs D:\python\python-3.6\lib D:\python\python-3.6 F:\python\学习\venv F:\python\学习\venv\lib\site-packages F:\python\学习\venv\lib\site-packages\setuptools-40.8.0-py3.6.egg F:\python\学习\venv\lib\site-packages\pip-19.0.3-py3.6.egg D:\python\pycharm-3.2\PyCharm 2020.3.2\plugins\python\helpers\pycharm_matplotlib_backend '''
_ _name_ _ : 当前模块执行过程中的名称 。如果运行的就是此模块则_ _name_ _就是_ _main_ _
如果是调用此模块这表示模块的路径名称,其中最顶级的路径层级就是所运行的模块所在的路径层级
# a1.py
from a.b import c2
print(__name__)
# c2.py
print('这里是c2.py:', __name__)
# 运行结果
"""
这里是c2.py: a.b.c2 #其中a1.py是运行的模块,a包是和a1.py同级的文件结果,所以这里a就是顶级名称
__main__
"""
python中的导入方式分为两种 import导入和from import两种
import导入的最小单位是 .py文件而 from import导入的最小单位是.py文件下的变量、函数、
from import导入分为相对导入和绝对导入
绝对导入:
# a1.py
from a.b import c2 #绝对导入路径参照sys.path 其中a就是F:\python\学习\学习demo\导入 下的根路径
#所以绝对路径就是 a.b
# 运行结果
"""
这里是c2.py: a.b.c2
"""
相对导入:
相对导入就是根据——name——所表示的目录在from 和import之间加上小黑点 . 加一个表示上一级目录,两个上上级目录,依次类推,不过最高不能超过顶级目录,否则或报错ValueError: attempted relative import beyond top-level package 而根据——name——的性质如果在所运行的模块中使用相对调用则会报错ModuleNotFoundError: No module named 'main.模块'; 'main' is not a package 所以相对导入是在被调用的模块中使用的
# b1.py 运行模块
from .b import c2
# c2.py 被调用模块
print('这里是c2.py:', __name__)
# 运行结果
"""
Traceback (most recent call last):
File "F:/python/学习/学习demo/导入/a/b1.py", line 19, in <module>
from .b import c2
ModuleNotFoundError: No module named '__main__.b'; '__main__' is not a package
"""
# b1.py 运行模块
from b import c2
# c2.py 被调用模块
from . import c1
print('这里是c2.py:', __name__)
# c1.py 被c2.py调用的模块
print("这里是c1.py")
# 运行结果
"""
当from和import之间的点为一个点时运行结果为:
这里是c1.py
这里是c2.py: b.c2
当from和import之间的点为两个点时运行结果为:
Traceback (most recent call last):
File "F:/python/学习/学习demo/导入/a/b1.py", line 19, in <module>
from b import c2
File "F:\python\学习\学习demo\导入\a\b\c2.py", line 6, in <module>
from .. import c1
ValueError: attempted relative import beyond top-level package
"""
import 导入:
python3之前的版本相当与相对导入,类似于隐式相对导入 from ... import 模块,而python3以后改为了绝对路径导入绝对路径导入是根据sys.path的路径集查找的
# a1.py 运行模块
from a import b1
# b1.py 被a1调用的模块
print('这里是b1')
import b2
# b2.py 被b1调用的模块
print('这里是b2.py')
# 运行结果
# python2:
"""
D:\python\python-2.7\python.exe F:/python/学习/学习demo/导入/a1.py
这里是b1
这里是b2.py
"""
# python3: 根据sys.path绝对路径导入F:\python\学习\学习demo\导入,所以显示找不到模块b2
"""
D:\python\python-3.6\python.exe F:/python/学习/学习demo/导入/a1.py
这里是b1
Traceback (most recent call last):
File "F:/python/学习/学习demo/导入/a1.py", line 7, in <module>
from a import b1
File "F:\python\学习\学习demo\导入\a\b1.py", line 20, in <module>
import b2
ModuleNotFoundError: No module named 'b2'
"""
python3版本以前import是相对引用存在当自己定义的模块和内置模块定义同名的情况,内置模块无法被引用的问题。所以python3中import变成了绝对引用。那么在python2中遇到了自定义模块和内置模块同名的情况,要怎么办了? 这里可以在import导入之前加入 from future import absolute_import 这段代码,代码的意思大概就是 加入绝对引入这个新特性 。
# a1.py 运行模块
from a import b1
# b1.py 被a1调用的模块
from __future__ import absolute_import # 加入绝对引入这个新特性,运行结果和python3一致
print('这里是b1')
import b2
# b2.py 被b1调用的模块
print('这里是b2.py')
# 运行结果
# python2:
"""
D:\python\python-2.7\python.exe F:/python/学习/学习demo/导入/a1.py
这里是b1
Traceback (most recent call last):
File "F:/python/学习/学习demo/导入/a1.py", line 7, in <module>
from a import b1
File "F:\python\学习\学习demo\导入\a\b1.py", line 20, in <module>
import b2
ModuleNotFoundError: No module named 'b2'
"""
【第七节:Python 标准库]
简述
Python 语言参考 描述了 Python 语言的具体语法和语义,这份库参考则介绍了与 Python 一同发行的标准库。
它还描述了通常包含在 Python 发行版中的一些可选组件。
Python 标准库非常庞大,所提供的组件涉及范围十分广泛,正如以下内容目录所显示的。这个库包含了多个内置模块
(以 C 编写),Python 程序员必须依靠它们来实现系统级功能,例如文件 I/O,此外还有大量以 Python 编写的模块,
提供了日常编程中许多问题的标准解决方案。其中有些模块经过专门设计,通过将特定平台功能抽象化为平台中立的 API
来鼓励和加强 Python 程序的可移植性。
Windows 版本的 Python 安装程序通常包含整个标准库,往往还包含许多额外组件。对于类 Unix 操作系统,Python
通常会分成一系列的软件包,因此可能需要使用操作系统所提供的包管理工具来获取部分或全部可选组件。
在这个标准库以外还存在成千上万并且不断增加的其他组件 (从单独的程序、模块、软件包直到完整的应用开发框架),
访问 Python 包索引 即可获取这些第三方包。
可用性注释
如果出现“可用性:Unix”注释,意味着相应函数通常存在于 Unix 系统中。 但这并不保证其存在于某个特定的操作系统中。
如果没有单独说明,所有注明 “可用性:Unix” 的函数都支持基于 Unix 核心构建的 Mac OS X 系统。
内置函数
内置常量
内置类型
- 逻辑值检测
- 布尔运算 --- and, or, not
- 比较
- 数字类型 --- int, float, complex
- 迭代器类型
- 序列类型 --- list, tuple, range
- 文本序列类型 --- str
- 二进制序列类型 --- bytes, bytearray, memoryview
- 集合类型 --- set, frozenset
- 映射类型 --- dict
- 上下文管理器类型
- 其他内置类型
- 特殊属性
内置异常
文本处理服务
- string --- 常见的字符串操作
- re --- 正则表达式操作
- difflib --- 计算差异的辅助工具
- textwrap --- 文本自动换行与填充
- unicodedata --- Unicode 数据库
- stringprep --- 因特网字符串预备
- readline --- GNU readline 接口
- rlcompleter --- GNU readline 的补全函数
二进制数据服务
数据类型
- datetime --- 基本的日期和时间类型
- calendar --- 日历相关函数
- collections --- 容器数据类型
- collections.abc --- 容器的抽象基类
- heapq --- 堆队列算法
- bisect --- 数组二分查找算法
- array --- 高效的数值数组
- weakref --- 弱引用
- types --- 动态类型创建和内置类型名称
- copy --- 浅层 (shallow) 和深层 (deep) 复制操作
- pprint --- 数据美化输出
- reprlib --- 另一种 repr() 实现
- enum --- 对枚举的支持
数字和数学模块
- numbers --- 数字的抽象基类
- math --- 数学函数
- cmath --- 关于复数的数学函数
- decimal --- 十进制定点和浮点运算
- fractions --- 分数
- random --- 生成伪随机数
- statistics --- 数学统计函数
函数式编程模块
文件和目录访问
- pathlib --- 面向对象的文件系统路径
- os.path --- 常用路径操作
- fileinput --- 迭代来自多个输入流的行
- stat --- 解析 stat() 结果
- filecmp --- 文件及目录的比较
- tempfile --- 生成临时文件和目录
- glob --- Unix 风格路径名模式扩展
- fnmatch --- Unix 文件名模式匹配
- linecache --- 随机读写文本行
- shutil --- 高阶文件操作
数据持久化
- pickle --- Python 对象序列化
- copyreg --- 注册配合 pickle 模块使用的函数
- shelve --- Python 对象持久化
- marshal --- 内部 Python 对象序列化
- dbm --- Unix "数据库" 接口
- sqlite3 --- SQLite 数据库 DB-API 2.0 接口模块
数据压缩和存档
- zlib --- 与 gzip 兼容的压缩
- gzip --- 对 gzip 格式的支持
- bz2 --- 对 bzip2 压缩算法的支持
- lzma --- 用 LZMA 算法压缩
- zipfile --- 使用ZIP存档
- tarfile --- 读写tar归档文件
文件格式
- csv --- CSV 文件读写
- configparser --- 配置文件解析器
- netrc --- netrc 文件处理
- xdrlib --- 编码与解码 XDR 数据
- plistlib --- 生成与解析 Mac OS X .plist 文件
加密服务
通用操作系统服务
- os --- 多种操作系统接口
- io --- 处理流的核心工具
- time --- 时间的访问和转换
- argparse --- 命令行选项、参数和子命令解析器
- getopt --- C-style parser for command line options
- logging --- Python 的日志记录工具
- logging.config --- 日志记录配置
- logging.handlers --- 日志处理
- getpass --- 便携式密码输入工具
- curses --- 终端字符单元显示的处理
- curses.textpad --- Text input widget for curses programs
- curses.ascii --- Utilities for ASCII characters
- curses.panel --- A panel stack extension for curses
- platform --- 获取底层平台的标识数据
- errno --- Standard errno system symbols
- ctypes --- Python 的外部函数库
并发执行
-
contextvars--- Context Variables
网络和进程间通信
- asyncio --- 异步 I/O
- socket --- 底层网络接口
- ssl --- 套接字对象的TLS/SSL封装
- select --- 等待 I/O 完成
- selectors --- 高级 I/O 复用库
- asyncore --- 异步socket处理器
- asynchat --- 异步 socket 指令/响应 处理器
- signal --- 设置异步事件处理程序
- mmap --- 内存映射文件支持
互联网数据处理
- email --- 电子邮件与 MIME 处理包
- json --- JSON 编码和解码器
- mailcap --- Mailcap 文件处理
- mailbox --- Manipulate mailboxes in various formats
- mimetypes --- Map filenames to MIME types
- base64 --- Base16, Base32, Base64, Base85 数据编码
- binhex --- 对binhex4文件进行编码和解码
- binascii --- 二进制和 ASCII 码互转
- quopri --- 编码与解码经过 MIME 转码的可打印数据
- uu --- 对 uuencode 文件进行编码与解码
结构化标记处理工具
- html --- 超文本标记语言支持
- html.parser --- 简单的 HTML 和 XHTML 解析器
- html.entities --- HTML 一般实体的定义
- XML处理模块
- xml.etree.ElementTree --- ElementTree XML API
- xml.dom --- The Document Object Model API
- xml.dom.minidom --- Minimal DOM implementation
- xml.dom.pulldom --- Support for building partial DOM trees
- xml.sax --- Support for SAX2 parsers
- xml.sax.handler --- Base classes for SAX handlers
- xml.sax.saxutils --- SAX 工具集
- xml.sax.xmlreader --- Interface for XML parsers
- xml.parsers.expat --- Fast XML parsing using Expat
互联网协议和支持
- webbrowser --- 方便的Web浏览器控制器
- cgi --- Common Gateway Interface support
- cgitb --- 用于 CGI 脚本的回溯管理器
- wsgiref --- WSGI Utilities and Reference Implementation
- urllib --- URL 处理模块
- urllib.request --- 用于打开 URL 的可扩展库
- urllib.response --- urllib 使用的 Response 类
- urllib.parse --- Parse URLs into components
- urllib.error --- urllib.request 引发的异常类
- urllib.robotparser --- robots.txt 语法分析程序
- http --- HTTP 模块
- http.client --- HTTP 协议客户端
- ftplib --- FTP 协议客户端
- poplib --- POP3 protocol client
- imaplib --- IMAP4 protocol client
- nntplib --- NNTP protocol client
- smtplib ---SMTP协议客户端
- smtpd --- SMTP 服务器
- telnetlib --- Telnet client
- uuid --- UUID objects according to RFC 4122
- socketserver --- A framework for network servers
- http.server --- HTTP 服务器
- http.cookies --- HTTP状态管理
- http.cookiejar —— HTTP 客户端的 Cookie 处理
- xmlrpc --- XMLRPC 服务端与客户端模块
- xmlrpc.client --- XML-RPC client access
- xmlrpc.server --- Basic XML-RPC servers
- ipaddress --- IPv4/IPv6 manipulation library
多媒体服务
- audioop --- Manipulate raw audio data
- aifc --- Read and write AIFF and AIFC files
- sunau --- 读写 Sun AU 文件
- wave --- 读写WAV格式文件
- chunk --- 读取 IFF 分块数据
- colorsys --- 颜色系统间的转换
- imghdr --- 推测图像类型
- sndhdr --- 推测声音文件的类型
- ossaudiodev --- Access to OSS-compatible audio devices
国际化
程序框架
Tk图形用户界面(GUI)
- tkinter --- Tcl/Tk的Python接口
- tkinter.ttk --- Tk主题小部件
- tkinter.tix --- Extension widgets for Tk
- tkinter.scrolledtext --- 滚动文字控件
IDLE
其他图形用户界面(GUI)包
开发工具
- typing --- 类型标注支持
- pydoc --- Documentation generator and online help system
- doctest --- 测试交互性的Python示例
- unittest --- 单元测试框架
- unittest.mock --- mock对象库
- unittest.mock 上手指南
- 2to3 - 自动将 Python 2 代码转为 Python 3 代码
- test --- Regression tests package for Python
- test.support --- Utilities for the Python test suite
- test.support.script_helper --- Utilities for the Python execution tests
调试和分析
- 审计事件表
- bdb --- Debugger framework
- faulthandler --- Dump the Python traceback
- pdb --- Python的调试器
- Python Profilers 分析器
- timeit --- 测量小代码片段的执行时间
- trace --- Trace or track Python statement execution
- tracemalloc --- 跟踪内存分配
软件打包和分发
- distutils --- 构建和安装 Python 模块
- ensurepip --- Bootstrapping the pip installer
- venv --- 创建虚拟环境
- zipapp --- Manage executable Python zip archives
Python运行时服务
- sys --- 系统相关的参数和函数
- sysconfig --- Provide access to Python's configuration information
- builtins --- 内建对象
- __main__ --- 顶层脚本环境
- warnings --- Warning control
- dataclasses --- 数据类
- contextlib --- Utilities for with-statement contexts
- abc --- 抽象基类
- atexit --- 退出处理器
- traceback --- 打印或检索堆栈回溯
- __future__ --- Future 语句定义
- gc --- 垃圾回收器接口
- inspect --- 检查对象
- site —— 指定域的配置钩子
自定义 Python 解释器
导入模块
- zipimport --- 从 Zip 存档中导入模块
- pkgutil --- 包扩展工具
- modulefinder --- 查找脚本使用的模块
- runpy --- Locating and executing Python modules
- importlib --- import 的实现
- Using importlib.metadata
Python 语言服务
- parser --- Access Python parse trees
- ast --- 抽象语法树
- symtable --- Access to the compiler's symbol tables
- symbol --- 与 Python 解析树一起使用的常量
- token --- 与Python解析树一起使用的常量
- keyword --- 检验Python关键字
- tokenize --- 对 Python 代码使用的标记解析器
- tabnanny --- 模糊缩进检测
- pyclbr --- Python module browser support
- py_compile --- Compile Python source files
- compileall --- Byte-compile Python libraries
- dis --- Python 字节码反汇编器
- pickletools --- pickle 开发者工具集
杂项服务
Windows系统相关模块
- msilib --- Read and write Microsoft Installer files
- msvcrt --- Useful routines from the MS VC++ runtime
- winreg --- Windows 注册表访问
- winsound --- Sound-playing interface for Windows
Unix 专有服务
- posix --- 最常见的 POSIX 系统调用
- pwd --- 用户密码数据库
- spwd --- The shadow password database
- grp --- The group database
- crypt --- Function to check Unix passwords
- termios --- POSIX 风格的 tty 控制
- tty --- 终端控制功能
- pty --- 伪终端工具
- fcntl --- The fcntl and ioctl system calls
- pipes --- Interface to shell pipelines
- resource --- Resource usage information
- nis --- Sun 的 NIS (黄页) 接口
- Unix syslog 库例程
被取代的模块
未创建文档的模块
【第八节:人生苦短我用Python,本文助你快速入门】
友情提示:本文针对的是非编程零基础的朋友,可以帮助我们快速了解Python语法,接着就可以快乐的投入到实战环节了。如果是零基础,还是老老实实看书最为稳妥。
前言
偶然在知乎上看到了一些好玩的Python项目(学 Python 都用来干嘛的?),让我对Python产生了些许兴趣。距离北漂实习还有两个月时间,正好可以在这段空闲时间里学一学。如果能做出些小工具,说不定对工作还有帮助,何乐而不为呢?
关于环境的安装和IDE就不多说了,网上有很多教程。这里贴出一篇博客,大家按里面的步骤安装就行:VSCode搭建Python开发环境。使用VSCode主要是因为免费,而且有大量插件可以下载,大家可以尽情的定制自己的IDE。如果曾经没有使用过VSCode,最好多了解下哪些必须的插件,优化自己的Coding体验。比如:Python插件推荐。
环境搭建好后,就可以愉快地敲代码了。VSCode需要自己创建Python文件,以.py为后缀。Ctrl+F5运行程序,F5调试程序。
Python基础
注释
单行注释:#
多行注释:''' (三个英文单引号开头,三个英文单引号结尾)
# 这是单行注释
'''
这是多行注释
'''
变量
Python的变量定义不需要显式指明数据类型,直接【变量名=值】即可。注意变量名分大小写,如Name和name不是同一个变量。
name = "小王"
print(name) # 输出 小王
数据类型
Python提供6种基础的数据类型:数字类型(number)、字符串类型(string)、列表(list)、元组(tuple)、字典(dictionary)、集合(set)。其中数字类型还包括三种数值类型:整型(int)、浮点型(float)、复数类型(complex)。
列表、元组那些我们留在容器那一节里面讲,先看看数字类型。
浮点型
浮点型表示小数,我们创建一个浮点型变量,再通过type函数看一看它的类型:
pi = 3.1415926
print(type(pi)) # 输出<class 'float'>
int整数型就不说了,其为Integer的缩写。
复数类型
复数类型,所谓复数就是我们中学学的,实数+虚数,比如:
x = 10+1.2j # 虚数以j或J结尾
print(type(x)) # 输出<class 'complex'>
刚开始接触复数时,很纳闷为啥会有这种类型,到底有啥实际作用,遂百度了一番:
mzy0324:微电子方面的运算基本全部都是复数运算。
hilevel:至少复数用来计算向量的旋转要比矩阵方便多了。科学计算和物理应该会用得到吧。PS:我经常把Python当带编程功能的计算器用,用来调试纯粹的数学算法挺方便的。
morris88:Python 的一大应用领域,主要是科学计算,主要用于太空宇航、银行等。
联想到Python平时在算法、科学研究等领域应用颇多,所以也就明白了,只是自己没使用的需求而已。
字符串
字符串类型的变量定义用一对双引号或者单引号括起来。如:
x = "Hello Python"
y = 'Hello Python'
print(x,y) # 输出Hello Python Hello Python
字符串内置函数:
| 函数 | 作用 |
|---|---|
| find(str[,start,end]) | 在字符串中查找子串str,可选参数start和end可以限定范围 |
| count(str[,start,end]) | 在字符串中统计子串str的个数,可选参数start和end可以限定范围 |
| replace(old,new[,count]) | 在字符串中用new子串替换old子串,可选参数count代表替换个数,默认全部替换 |
| split(sep[,maxsplit]) | 用指定分隔符sep分割字符,返回一个列表,可选参数maxsplit代表分割几次,默认全部 |
| upper()、lower() | 转换大小写 |
| join(序列) | 把序列中的元素用指定字符隔开并生成一个字符串。 |
| startwith(prefix[,start,end]) | 判断字符串中是否以prefix开头,返回bool类型。还有一个endwith,判断结尾的。 |
| strip([,str]) | 去掉字符串开头和结尾的空白字符(包括\n、\t这些),可选参数代表可以去掉指定字符 |
布尔类型
顺便再说一下布尔类型,不过与Java不同的是,布尔类型的True和False,首字母必须大写:
x = True
print(type(x)) # 输出<class 'bool'>
类型转换
说完几个基本的数据类型,不免要提到类型转换。Python内置一些类型转换的函数:
| 函数名 | 作用 |
|---|---|
| int(x) | 将x转换为整型(小数转整型会去掉小数部分) |
| float(x) | 将x转换为浮点型 |
| str(x) | 将x转换为字符串 |
| tuple(x) | 将x转换为元组 |
| list(x) | 将x转换为列表 |
| set(x) | 将x转换为集合,并去重 |
输入与输出
输入函数为input。input函数返回用户输入的信息为字符串类型。所以如果你输入的是数字类型,记得类型转换。
x = input("请输入数字")
print(type(x),x) # 输出<class 'str'> 10
输出前面已经演示了很多次了,函数为print,可以直接输出变量与值。一次输出多个变量可以用逗号隔开,就想上面的演示一样,既要输出类型,也要输出值。不换行输出,可以在print函数里加上end=""这个参数,因为print默认end="\n",\n就是换行的意思。如果想输出特殊字符,可能需要用到转义字符:\。
x = 10
y = 20
print(x,y,end="") # 输出10 20 加上end="" 不换行
print("Hello \\n Python") # 输出 Hello \n Python
在输出时,还可以格式化输出内容:%s代表字符串格式、%d代表整型、%f代表浮点型
z = 1.2
print("%f"%z) # 输出 1.200000
除了格式化,%d等还可以当作占位符:
name = "小明"
age = 18
print("姓名:%s,年龄:%d"%(name,age)) # 姓名:小明,年龄:18
如果你闲这个占位符麻烦,还可以使用format函数,占位符只用写一对{}:
print("姓名:{},年龄:{}".format(name,age)) # 姓名:小明,年龄:18
运算符
算术运算符
除了加减乘除,还有幂(**)、取模(%)、取整(//)
x = 3 ** 2 # x=9 即3的2次方
y = 5 % 3 # y=2 即5除以3余2
z = 5 // 2 # z=2 即5除以2,整数部分为2
比较运算符
和其他常用编程语言基本一模一样,不等于(!=)、大于等于(>=)、等于(==)。
赋值运算符
Python也支持+=、*=等形式的赋值运算。除此之外,当然也支持前面说到的幂、取模等算术运算符,如取整并赋值(//=)、取模并赋值(%=)。
x = 10
x %= 3
print(x) # 输出1 ,x%=3 意为 x = x%3
逻辑运算符
非(not)、与(and)、或(or)
x = True
print(not x) # 输出 False
if、while、for
这三个和其他编程语言基本没差,就是写法上有点区别。首先没了大括号,条件语句后以冒号开头;代码快有严格的缩进要求,因为没了大括号,缩进就是条件语句判断自己代码快范围的依据。其他的基本一样,比如continue跳过当次循环,break跳出整个循环体。下面看三个简单的例子就明白了:
a = 10
# if或else后面是冒号,代码块还需要缩进
if a >= 10:
print("你好啊老大")
else:
print("滚蛋")
# 同样的while后面也需要冒号,代码块必须缩进。(Python没有num++,得写成num+=1)
# print想不换行打印,最后得加个end="",因为默认有一个end="\n"
# " "*(j-i),代表j-i个空格
i = 1
j = 4
while i <= j:
print(" "*(j-i), end="")
n = 1
while n <= 2*i-1:
print("*", end="")
n += 1
print("")
i += 1
# 语法:for 变量 in 序列 ,还没讲序列,暂时用range表示,代表1-21的序列
# continue略过当次循环,break跳出整个循环
for i in range(1, 21):
if i % 2 == 0:
if(i % 10 == 0):
continue
if(i >= 15):
break
print(i)
容器
列表
列表使用一对[]定义,每个元素用逗号隔开,元素类型不强求相同,通过索引获取列表元素。具体的我们看下面的代码:
info_list = ["小红", 18, "男"] #可以不是同一类型
info_list[2] = "女" # 修改指定索引位置的元素
del info_list[1] # 删除指定索引位置的元素
info_list.remove("女") # 删除列表中指定的值
for att in info_list: # 遍历元素
print(att)
上面的示例代码演示了部分列表的用法,下面再列出一些其他的常用函数或语法:
| 函数或语法 | 作用 |
|---|---|
| list.append(element) | 向列表list结尾添加元素(这个元素也可以是个列表) |
| list.insert(index,element) | 向列表指定位置添加元素 |
| list.extend(new_list) | 向列表list添加new_list的所有元素 |
| list.pop([,index]) | 弹出最后一个元素,可选参数index,弹出指定位置元素 |
| list.sort([,reverse=True]) | 对列表排序,可选参数reverse=True表示降序 |
| list[start:end] | 对列表分片,start和end代表起始结束索引 |
| list1+list2 | 拼接两个列表 |
元组
元组用一对()定义。元组也是有序的,它和列表的区别就是,列表可以修改元素,元组不行。正是因为这个特点,元组占用的内存也比列表小。
name_list=("小红","小王")
字典
字典使用一对{}定义,元素是键值对。用法示例如下:
user_info_dict = {"name": "小王", "age": "18", "gender": "男"}
name = user_info_dict["name"] # 直接用key获取value
age = user_info_dict.get("age") # 也可以用get(key)获取value
user_info_dict["tel"] = "13866663333" # 当key不存在,就是往字典添加键值对,如果存在就是修改value
del user_info_dict["tel"] # 删除指定键值对
以上就是常用语法和函数。字典也可以遍历,只是遍历时,需要指定遍历的是key还是value,比如:
for k in dict.keys(): # 遍历所有key
for v in dict.values(): # 遍历所有value
for item in dict.items(): # 也可以直接遍历键值对
集合
集合是无序的,也用一对{}定义,但不是键值对了,是单独且不重复的元素。部分用法如下:
user_id_set = {"1111","22222","3333"} # 元素不重复
print(type(user_id_set)) # 输出<class 'set'>
# 除了直接用{}定义,还可以用set函数传入一个序列,其会为list去重,并返回一个集合(如果是字符串,字符串会被拆成字符)
new_user_id_set = set(list)
上面演示了部分用法,下面我们用一个表格展示一些常用的函数或语法:
| 函数或语法 | 作用 |
|---|---|
| element in set | 判断元素是否在集合中,返回布尔类型 |
| element not in set | 判断元素是否不在集合中 |
| set.add(element) | 向集合添加元素 |
| set.update(list,.....) | 将序列中的每个元素去重并添加到集合中,如果有多个序列,用逗号隔开 |
| set.remove(element) | 删除指定元素,如果元素不存在就会报错 |
| set.discard(element) | 删除指定元素,如果元素不存在也不会报错 |
| set.pop() | 随机删除集合中的元素,并返回被删除的元素 |
| set1 & set2 或set1 intersection set2 | 求两个集合的交集,两种用法结果一样 |
| set1 | set2 或set1 union set2 | 求两个集合的并集 |
| set1 - set2 或set1.difference(set2) | 求两个集合的差集,注意顺序。set1-set2代表set1有set2没有的元素 |
函数
函数的定义
Python中函数用def定义,格式为:
def function_name(参数列表): # 参数可为空,多个参数用逗号隔开
函数体
return 返回值 #可选
# 函数的调用
function_name(参数列表)
缺省参数
和循环体一样的,因为没有了大括号,所以缩进是严格要求的。除了上面那种比较常见的格式,Python函数的参数中,还有一种缺省参数,即带有默认值的参数。调用带有缺省参数的函数时,可以不用传入缺省参数的值,如果传入了缺省参数的值,则会使用传入的值。
def num_add(x,y=10): # y为缺省函数,如果调用这个函数只传入了x的值,那么y默认为10
命名参数
一般情况下,调用函数传入实参时,都会遵循参数列表的顺序。而命名参数的意思就是,调用函数时,通过参数名传入实参,这样可以不用按照参数定义的顺序传入实参。
def num_add(x, y):
print("x:{},y:{}".format(x, y))
return x+y
# 输出:
# x:10,y:5
# 15
print(num_add(y=5, x=10))
不定长参数
不定长参数可以接收任意多个参数,Python中有两种方法接收:1.在参数前加一个*,传入的参数会放到元组里;2.在参数前加两个**,代表接收的是键值对形式的参数。
# 一个*
def eachNum(*args):
print(type(args))
for num in args:
print(num)
# 输出:
# <class 'tuple'>‘
# (1, 2, 3, 4, 5)
eachNum(1,2,3,4,5)
## 两个**。这个other是想告诉你,在使用不定长参数时,也可以搭配普通的参数
def user_info(other,**info):
print(type(info))
print("其他信息:{}".format(other))
for key in info.keys():
print("{} : {}".format(key,info[key]))
# 传入参数时,不用像定义字典一样,加个大括号再添加键值对,直接当命名参数传入即可
# 输出:
# <class 'dict'>
# 其他信息:管理员
# 略...
user_info("管理员",name="赵四",age=18,gender="男")
上面示例代码中的注释说到了,当使用不定长参数时,不用像字典或者元组的定义那样,直接传入参数即可。但有时候,可能会遇到想把字典、元组等容器中的元素传入到不定长参数的函数中,这个时候就需要用到拆包了。
所谓拆包,其实就是在传入参数时,在容器前面加上一个或两个*。还是以上面的user_info函数为例:
user_info_dict={"name":"赵四","age":18,"gender":"男"}
user_info("管理员",**user_info_dict) # 效果和上面一样
注意,如果接收方的不定长参数只用了一个 * 定义,那么传入实参时,也只能用一个 *。
匿名函数
匿名函数,即没有名字的函数。在定义匿名函数时,既不需要名称,也不需要def关键字。语法如下:
lambda 参数列表: 表达式
多个参数用逗号隔开,匿名函数会自动把表达式的结果return。在使用时,一般会用一个变量接收匿名函数,或者直接把匿名函数当参数传入。
sum = lambda x,y : x+y
print(sum(1,2)) # 输出3
闭包和装饰器
在Python中,函数内还可以定义函数,外面这个函数我们就称为外部函数,里面的函数我们就称为内部函数。而外部函数的返回值是内部函数的引用,这种表达方式就是闭包。内部函数可以调用外部函数的变量,我们看一个示例:
# 外部函数
def sum_closure(x):
# 内部函数
def sum_inner(y):
return x+y
return sum_inner # 返回内部函数
# 获取了内部函数
var1 = sum_closure(1)
print(var1) # 输出<function sum_closure.<locals>.sum_inner at 0x000001D82900E0D0>,是个函数类型
print(var1(2)) # 输出3
说完闭包的用法,接着了解一下装饰器。不知道大家了解过AOP没,即面向切面编程。说人话就是在目标函数前后加上一些公共函数,比如记录日志、权限判断等。Python中当然也提供了实现切面编程的方法,那就是装饰器。装饰器和闭包一起,可以很灵活的实现类似功能,下面看示例:
import datetime #如果没有这个包,在终端里输入pip3 install datetime
# 外部函数,其参数是目标函数
def log(func):
#内部函数,参数得和目标函数一致。也可以使用不定长参数,进一步提升程序灵活性
def do(x, y):
# 假装记录日志,执行切面函数。(第一次datetime是模块、第二个是类、now是方法。在下一节讲到模块)
print("时间:{}".format(datetime.datetime.now()))
print("记录日志")
# 执行目标函数
func(x, y)
return do
# @就是装饰器的语法糖,log外部函数
@ log
def something(x, y):
print(x+y)
# 调用目标函数
# 输出:
# 时间:2021-01-06 16:17:00.677198
# 记录日志
# 30
something(10, 20)
函数相关的就说到这里了,其实还有一些知识没说到,比如变量的作用域、返回值等。这部分内容和其他语言几乎无异,一点区别无非就是返回值不用在乎类型了,毕竟定义函数时也没指定函数返回值类型,这一点各位老司机应该也会想到。
包和模块
包
Python中包与普通文件夹的区别就是,包内要创建一个__init__.py文件,来标识它是一个包。这个文件可以是空白的,也可以定义一些初始化操作。当其他包下的模块调用本包下的模块时,会自动的执行__init__.py文件的内容。
模块
一个Python文件就是一个模块,不同包下的模块可以重名,在使用的时候以“包名.模块名”区别。导入其他模块用import关键字,前面的示例代码中也演示过一次。导入多个模块可以用逗号隔开,也可以直接分开写。除了导入整个模块,还可以导入模块中指定的函数或类:
from model_name import func_name(or class_name)
导入函数或类后,就不要使用模块名了,直接调用导入的类或函数即可。
面向对象
类和对象
Python是一种面向对象的解释型编程语言。面向对象的关键就在于类和对象。Python中类的定义用class关键字,如下:
class 类名:
def 方法名(self[,参数列表])
...
定义在类里面的函数叫做方法,只是与类外部的函数做个区分,不用在意叫法。类里面的方法,参数列表中会有一个默认的参数,表示当前对象,你可以当作Java中的this。因为一个类可以创建多个对象,有了self,Python就知道自己在操作哪个对象了。我们在调用这个方法时,不需要手动传入self。示例代码:
class Demo:
def do(self):
print(self)
# 创建两个Demmo类型的对象
demo1=Demo()
demo1.do() # 输出<__main__.Demo object at 0x0000019C78106FA0>
demo2=Demo()
demo2.do() # 输出<__main__.Demo object at 0x0000019C77FE8640>
print(type(demo1)) # <class '__main__.Demo'>
构造方法
构造方法的作用是在创建一个类的对象时,对对象进行初始化操作。Python中类的构造方法的名称是__init__(两边分别两个下划线)。在创建对象时,__init__方法自动执行。和普通方法一样的,如果你想自定义构造方法,也要接收self参数。示例代码:
class Demo:
# 构造方法,还可以传入其他参数化
def __init__(self,var1,var2):
# 把参数设置到当前对象上,即使类中没有属性也可以设置
self.var1=var1
self.var2=var2
print("初始化完成")
def do(self):
print("Working...")
# 通过构造方法传入实参
demo1=Demo(66,77)
demo1.do()
# 通过当前对象,获取刚刚设置的参数
print(demo1.var1)
print(demo1.var2)
访问权限
Java或C#中有好几种访问权限,在Python中,属性和方法前添加两个下划线即为私有,反之就是共公有。具有私有访问权限的属性和方法,只能在类的内部方法,外部无法访问。和其他语言一样,私有的目的是为了保证属性的准确性和安全性,示例代码如下:
class Demo:
# 为了方便理解,我们显示的设置一个私有属性
__num = 10
# 公有的操作方法,里面加上判断,保证数据的准确性
def do(self, temp):
if temp > 10:
self.__set(temp)
# 私有的设置方法,不让外部直接设置属性
def __set(self, temp):
self.__num = temp
# 公有的get方法
def get(self):
print(self.__num)
demo1 = Demo()
demo1.do(11)
demo1.get() # 输出 11
一堆self.刚开始看时还有点晕乎,把它当作this就好。
继承
继承是面向对象编程里另一大利器,好处之一就是代码重用。子类只能继承父类的公有属性和方法,Python的语法如下:
class SonClass(FatherClass):
当我们创建一个SonClass对象时,直接可以用该对象调用FatherClass的公有方法。Python还支持多继承,如果是多继承就在小括号里把父类用逗号隔开。
如果想在子类里面调用父类的方法,一般有两种方式:1.父类名.方法名(self[,参数列表])。此时的self是子类的self,且需要显示传入;2.super().方法名()。第二种方式因为没有指定父类,所以在多继承的情况下,如果调用了这些父类中同名的方法,Python实际会执行小括号里写在前面的父类中的方法。
如果子类定义了与父类同名的方法,子类的方法就会覆盖父类的方法,这就是重写。
异常处理
捕获异常
捕获异常的语法如下:
try:
代码快 # 可能发生异常的代码
except (异常类型,...) as err: # 多个异常类型用逗号隔开,如果只有一个异常类型可以不要小括号。err是取的别名
异常处理
finally:
代码快 # 无论如何都会执行
在try代码块中,错误代码之后的代码是不会执行的,但不会影响到try ... except之外的代码。看个示例代码:
try:
open("123.txt") #打开不存在的文件,发生异常
print("hi") # 这行代码不会执行
except FileNotFoundError as err:
print("发生异常:{}".format(err)) # 异常处理
print("我是try except之外的代码") #正常执行
虽然上面的内容和其他语言相差不大,但是刚刚接触Python鬼知道有哪些异常类型,有没有类似Java的Exception异常类型呢?肯定是有的。Python同样提供了Exception异常类型来捕获全部异常。
那如果发生异常的代码没有用try except捕获呢?这种情况要么直接报错,程序停止运行。要么会被外部的try except捕获到,也就是说异常是可以传递的。比如func1发生异常没有捕获,func2调用了func1并用了try except,那么func1的异常会被传递到func2这里。是不是和Java的throws差不多?
抛出异常
Python中抛出异常的关键字是raise,其作用和Java的throw new差不多。示例代码如下:
def do(x):
if(x>3): # 如果大于3就抛出异常
raise Exception("不能大于3") # 抛出异常,如果你知道具体的异常最好,后面的小括号可以写上异常信息
else:
print(x)
try:
do(4)
except Exception as err:
print("发生异常:{}".format(err)) # 输出 发生异常:不能大于3
文件操作
读写文件
想要操作一个文件,首先得打开它。Python中有个内置的函数:open。使用open打开文件可以有三种模式,分别为:只读(默认的模式,只能读取文件内容,r表示)、只写(会覆盖原文本内容,w表示)、追加(新内容追加到末尾,a表示)。示例如下:
f = open("text.txt","a") # 用追加的方式获取文件对象
因为text.txt和代码在同一目录所以只写了文件名,如果不在同一目录需要写好相对路径或绝对路径。
获取到文件对象后,接下来就可以操作了,反正就是些API,直接看示例:
f = open("text.txt","a",encoding="utf-8") # 以追加的方式打开文件,并设置编码方式,因为接下来要写入中文
f.write("234567\n") # 写入数据,最后的\n是换行符,实现换行
f.writelines(["张三\n","赵四\n","王五\n"]) # write只能写一个字符串,writelines可以写入一列表的字符串
f.close() # 操作完记得关闭
以上是写文件的两个方法。最后记得关闭文件,因为操作系统会把写入的内容缓存起来,万一系统崩溃,写入的数据就会丢失。虽然程序执行完文件会自动关闭,但是实际项目中,肯定不止这点代码。Python也很贴心,防止我们忘了close,提供了一种安全打开文件的方式,语法是 with open() as 别名:,示例如下
with open("test.txt","w") as f: # 安全打开文件,不需要close。
f.write("123")
写完了,该读一读了。示例如下:
f = open("text.txt","r",encoding="utf-8")
data = f.read() # read会一次性读出所有内容
print(data)
f.close()
除了一次性读取完,还可以按行的方式返回全部内容,并用一个列表装起来,这样我们就可以进行遍历了。方法是readlines,示例如下:
f = open("text.txt","r",encoding="utf-8")
lines = f.readlines() # lines是个列表
for line in lines:
print(line)
f.close()
文件管理
在操作文件的时候,肯定不止读写这么简单,可能还会涉及文件的删除、重命名、创建等等。在用Python的函数操作文件之前,需要导入os模式:import os 。下面简单的演示一下重命名的函数,其他的函数我们以表格的形式展现。
import os
os.rename("text.txt","123.txt") # 把text.txt改名为123.txt
| 函数 | 作用 |
|---|---|
| os.remove(path) | 删除指定文件 |
| os.mkdir(path) | 在指定路径下创建新文件 |
| os.getcwd() | 获取程序运行的绝对路径 |
| os.listdir(path) | 获取指定路径下的文件列表,包含文件和文件夹 |
| os.redir(path) | 删除指定路径下的空文件夹(如果不是空文件夹就会报错) |
操作JSON
学了前面的容器,会发现JSON的格式和Python的字典有点像,都是键值对形式的。虽然格式很像,但还是有点小区别,比如:Python的元组和列表在JSON中都是列表、Python的True和Flase会被转换成小写、空类型None会被转换成null。下面我们来看一些具体的函数把。
在Python中操作JSON格式的数据需要导入json模块。同样的,我这里只演示一个函数,其他常用的用表格列出来。
import json
user_info={"name":"张三","age":18,"gender":"男","hobby":("唱歌","跳舞","打篮球"),"other":None} # 创建一个字典
json_str=json.dumps(user_info,ensure_ascii=False) # dumps函数会把字典转换为json字符串
# 输出 {"name": "张三", "age": 18, "gender": "男", "hobby": ["唱歌", "跳舞", "打篮球"], "other": null}
print(json_str)
需要注意如果数据存在中文,需要在dumps函数加上ensure_ascii=False。
| 函数 | 作用 |
|---|---|
| json.loads(json_str) | 把json字符串转换为Python数据结构 |
| json.dump(user_info,file) | 把Python数据写入到json文件,要先获取文件,那个file就是文件对象 |
| json.load(file) | 把json文件中的数据转为成Python数据结构,同样需要获取文件 |
关于JSON的操作就说这些。通用的数据格式不止JSON一种,比如还有xml、csv等。为了节约篇幅,就不再赘述了,大家可以根据自己的需求查对应的API即可。
正则表达式
最后一节讲正则表达式,一是因为这也算个基础知识,在很多地方都有可能用到。二是因为后面的爬虫实战,肯定会用到正则表达式来解析各种数据。
Python中内置了re模块来处理正常表达式,有了这个模块我们就可以很方便的对字符串进行各种规则匹配检查。不过正则表达式真正难的是表达式的书写,函数主要就一个:re.match(pattern,string),其中pattren就是正则表达式,stirng就是待匹配字符串。如果匹配成功就会返回一个Match对象,否则就返回None。匹配是从左往右,如果不匹配就直接返回None,不会接着匹配下去。示例如下:
import re
res=re.match("asd","asdabcqwe") # 匹配字符串中是否有asd(如果asd不在开头就会返回None)
print(res) # 输出 <re.Match object; span=(0, 3), match='asd'>
print(res.group()) # 输出 asd 如果想获取匹配的子字符就用这个函数
秉着帮人帮到底的精神,下面就简单的介绍下正则表达式的一些规则。
单字符匹配
单字符匹配,顾名思义就是匹配一个字符。除了直接使用某个具体的字符,还可以使用以下符号来进行匹配:
| 符号 | 作用 |
|---|---|
| . | 匹配除”\n“以外的任意单个字符 |
| \d | 匹配0-9之间的一个数字,等价于[0-9] |
| \D | 匹配一个非数字字符,等价于[^0-9] |
| \s | 匹配任意空白字符,如空格、\t、\n等 |
| \S | 匹配任意非空白字符 |
| \w | 匹配单词字符,包括字母、数字、下划线 |
| \W | 匹配非单词字符 |
| [] | 匹配[]中列举的字符,比如[abc],只要出现这三个字母中的一个即可匹配 |
以防有的朋友从未接触过正则表达式,不知道怎么用,下面我来做个简答的演示。假如我想匹配三个字符:第一个是数字、第二个是空格、第三个是字母,一起来看看怎么写这个正则表达式吧:
import re
pattern = "\d\s\w" # \d匹配数字、\s匹配空格、\w匹配字母(切记是从左往右依次匹配的,只要有一个字符匹配不上就直接返回None)
string = "2 z你好"
res=re.match(pattern,string)
print(res.group()) # 输出:2 z
看到这你可能会想,非得一个个字符匹配,那多麻烦啊,有没有更灵活的规则?当然有了,接着看。
数量表示
如果我们只想匹配字母,但不限制有多少个,该怎么写呢?看下面的表格就知道了:
| 符号 | 作用 |
|---|---|
| * | 匹配一个字符出现0次或多次 |
| + | 匹配一个字符至少出现一次,等价于{,1} |
| ? | 匹配一个字符出现0次或1次,等价于{1,2} |
| {m} | 匹配一个字符出现m次 |
| {m,} | 匹配一个字符至少出现m次 |
| {m,n} | 匹配一个字符出现m到n次 |
数量匹配的符号后面如果加上?,就会尽可能少的去匹配字符,在Python里面叫非贪婪模式,反之默认的就是贪婪模式。比如{m,}会尽可能多的去匹配字符,而{m,}?在满足至少有m个的情况下尽可能少的去匹配字符。其他的同理。
来看一个例子,我想匹配开头是任意个小写字母,接着是1到5个2-6的数字,最后是至少一个空格:
import re
pat = r"[a-z]*[2-6]{1,5}\s+"
str = "abc423 你好"
res=re.match(pat,str)
print(res) #输出 abc423
我们来解析下这个正则表达式,pat字符串开头的r是告诉Python这是个正则表达式,不要转义里面的\,建议写表达式时都加上。[a-z]代表任意小写字母,不用\w的原因是,\w还包括数字、下划线,没有严格符合我们的要求。加上个*就代表任意数量。这里强调一下单字符匹配和数量表示之间的逻辑关系,以[a-z]*为例,其表达的是任意个[a-z],而不是某个字母有任意个。明白了这个逻辑后,其他的也好理解了。
前面的例子都是我随意编的,其实学了这些,已经可以写出一个有实际作用的表达式了,比如我们来匹配一个手机号。首先手机号只有11位,第一个数字必须是1,第二个是3、5、7、8中的一个。知道了这三个个规律,我们来写一下表达式:1[3578]\d{9}。看上去好像可以,但是仔细一想,前面不是说了正则表达式是从左往右匹配,只要符合了就会返回结果,也不会管字符串匹配完全没有。如果最后有10个数字,这个表达式也会匹配成功。关于这个问题我们接着看。
边界表示
边界表示符有两个:开头^和结尾$。使用起来也很简单,还是以上面的手机号为例,我们再来完善一下:^1[3578]\d{9}$。其中^1表示以1开头,\d{9}$表示以9个数字结尾。其实这个^1可有可无,毕竟是从左往右的,字符串不是1开头的话直接就会返回None,但是这个结尾符是必须的。
转义字符
假如我们想匹配的字符与正则表达式规定的这些字符一样该怎么办?比如我们想单纯的匹配.这个字符,但是这个字符在正则表达式中表示的是任意字符。这时候就要用到转义字符\了。其实这个转义字符在很多语言里都是一样的。那么前面的例子就可以写出\.。我们再演示个匹配邮箱的例子:
import re
pat = r"^\w{4,10}@qq\.com" # 如果.前面不加\,就代表任意字符了
str = "1234@qq.com"
res=re.match(pat,str)
print(res)
匹配分组
看到上面的匹配邮箱例子,是不是有个疑问,如果我想不止匹配QQ邮箱该怎么办呢。那就要用到分组了,其可以实现匹配多种情况。分组符号如下:
| 符号 | 作用 |
|---|---|
| () | 将括号里的内容当作一个分组,每个分组会有一个编号,从1开始 |
| | | 连接多个表达式,表达式之间是“或”的关系,可与()一起使用 |
| \num | 引用分组,num代表分组编号 |
| (?P...) | 给分组取别名,别名写在表达式前面,name不用打引号 |
| (?P=name) | 根据别名使用分组中的正则表达式 |
那么我们把上面的例子稍微修改下:^\w{4,10}@(qq|163|outlook|gmail)\.com。这样就可以匹配多种邮箱了。
简单的演示了下|的用法,大家可能对其他的分组符号还有点疑惑,下面我们再来演示一下这些符号:
import re
pat = r"<(.+)><(.+)>.*<(/\2)><(/\1)>"
str = "<body><div></div></body>"
res=re.match(pat,str)
print(res)
这个表达式匹配的是由两个标签组成的html字符串。第一眼看上去有点麻烦,实际很简单。再次强调一下,普通字符也可以当表达式来匹配的,比如上面的< >就是普通字符而已。
我们来分析一下这个表达式,首先一对小括号表示一个分组,里面的.+表示只有一个非\n字符。中间的.*用来匹配标签内的内容。/\2中,第一个斜杠与前面的html标签组成一对,/2表示引用第二个分组的内容。这里为什么要使用分组呢?因为我们还要保证html标签正确匹配。如果后面也使用.+,大家可以试着把/div和/body交换位置,表达式依旧匹配成功,但这显然不符合html的语法。
操作函数
正则表达式的一些规则符号终于讲完了,最后再列举几个Python中操作正则表达式的函数:(re为导入的模块)
| 函数 | 作用 |
|---|---|
| re.compile(patt) | 封装正则表达式,并返回一个表达式对象 |
| re.search(patt,str) | 从左往右搜索第一个配正则表达式匹配的子字符串 |
| re.findall(patt,str) | 在字符串中查找正则表达式匹配到的所有子字符串,并返回一个列表 |
| re.finditer(patt,str) | 在字符串中查找正则表达式匹配到的所有子字符串,并返回一个Iterator对象 |
| re.sub(patt,newstr,str) | 将字符串中被正则表达式匹配到的子字符串替换成newstr,并返回新的字符串,原字符串不变 |
Python的第一篇文章就到这里了。接下来会边学边写,做一些好玩的Python项目,再一起分享出来。如有错误,感谢指出!
【第九节:Python异常及处理方法总结]
调试Python程序时,经常会报出一些异常,异常的原因一方面可能是写程序时由于疏忽或者考虑不全造成了错误,这时就需要根据异常Traceback到出错点,进行分析改正;另一方面,有些异常是不可避免的,但我们可以对异常进行捕获处理,防止程序终止。
一、Python内置异常
Python的异常处理能力是很强大的,它有很多内置异常,可向用户准确反馈出错信息。
在Python中,异常也是对象,可对它进行操作。BaseException是所有内置异常的基类,但用户定义的类并不直接继承BaseException,所有的异常类都是从Exception继承,且都在exceptions模块中定义。
Python自动将所有异常名称放在内建命名空间中,所以程序不必导入exceptions模块即可使用异常。一旦引发而且没有捕捉SystemExit异常,程序执行就会终止。
例如:如果交互式会话遇到一个未被捕捉的SystemExit异常,会话就会终止。
内置异常类的层次结构如下
BaseException # 所有异常的基类
+-- SystemExit # 解释器请求退出
+-- KeyboardInterrupt # 用户中断执行(通常是输入^C)
+-- GeneratorExit # 生成器(generator)发生异常来通知退出
+-- Exception # 常规异常的基类
+-- StopIteration # 迭代器没有更多的值
+-- StopAsyncIteration # 必须通过异步迭代器对象的__anext__()方法引发以停止迭代
+-- ArithmeticError # 各种算术错误引发的内置异常的基类
| +-- FloatingPointError # 浮点计算错误
| +-- OverflowError # 数值运算结果太大无法表示
| +-- ZeroDivisionError # 除(或取模)零 (所有数据类型)
+-- AssertionError # 当assert语句失败时引发
+-- AttributeError # 属性引用或赋值失败
+-- BufferError # 无法执行与缓冲区相关的操作时引发
+-- EOFError # 当input()函数在没有读取任何数据的情况下达到文件结束条件(EOF)时引发
+-- ImportError # 导入模块/对象失败
| +-- ModuleNotFoundError # 无法找到模块或在在sys.modules中找到None
+-- LookupError # 映射或序列上使用的键或索引无效时引发的异常的基类
| +-- IndexError # 序列中没有此索引(index)
| +-- KeyError # 映射中没有这个键
+-- MemoryError # 内存溢出错误(对于Python 解释器不是致命的)
+-- NameError # 未声明/初始化对象 (没有属性)
| +-- UnboundLocalError # 访问未初始化的本地变量
+-- OSError # 操作系统错误,EnvironmentError,IOError,WindowsError,socket.error,select.error和mmap.error已合并到OSError中,构造函数可能返回子类
| +-- BlockingIOError # 操作将阻塞对象(e.g. socket)设置为非阻塞操作
| +-- ChildProcessError # 在子进程上的操作失败
| +-- ConnectionError # 与连接相关的异常的基类
| | +-- BrokenPipeError # 另一端关闭时尝试写入管道或试图在已关闭写入的套接字上写入
| | +-- ConnectionAbortedError # 连接尝试被对等方中止
| | +-- ConnectionRefusedError # 连接尝试被对等方拒绝
| | +-- ConnectionResetError # 连接由对等方重置
| +-- FileExistsError # 创建已存在的文件或目录
| +-- FileNotFoundError # 请求不存在的文件或目录
| +-- InterruptedError # 系统调用被输入信号中断
| +-- IsADirectoryError # 在目录上请求文件操作(例如 os.remove())
| +-- NotADirectoryError # 在不是目录的事物上请求目录操作(例如 os.listdir())
| +-- PermissionError # 尝试在没有足够访问权限的情况下运行操作
| +-- ProcessLookupError # 给定进程不存在
| +-- TimeoutError # 系统函数在系统级别超时
+-- ReferenceError # weakref.proxy()函数创建的弱引用试图访问已经垃圾回收了的对象
+-- RuntimeError # 在检测到不属于任何其他类别的错误时触发
| +-- NotImplementedError # 在用户定义的基类中,抽象方法要求派生类重写该方法或者正在开发的类指示仍然需要添加实际实现
| +-- RecursionError # 解释器检测到超出最大递归深度
+-- SyntaxError # Python 语法错误
| +-- IndentationError # 缩进错误
| +-- TabError # Tab和空格混用
+-- SystemError # 解释器发现内部错误
+-- TypeError # 操作或函数应用于不适当类型的对象
+-- ValueError # 操作或函数接收到具有正确类型但值不合适的参数
| +-- UnicodeError # 发生与Unicode相关的编码或解码错误
| +-- UnicodeDecodeError # Unicode解码错误
| +-- UnicodeEncodeError # Unicode编码错误
| +-- UnicodeTranslateError # Unicode转码错误
+-- Warning # 警告的基类
+-- DeprecationWarning # 有关已弃用功能的警告的基类
+-- PendingDeprecationWarning # 有关不推荐使用功能的警告的基类
+-- RuntimeWarning # 有关可疑的运行时行为的警告的基类
+-- SyntaxWarning # 关于可疑语法警告的基类
+-- UserWarning # 用户代码生成警告的基类
+-- FutureWarning # 有关已弃用功能的警告的基类
+-- ImportWarning # 关于模块导入时可能出错的警告的基类
+-- UnicodeWarning # 与Unicode相关的警告的基类
+-- BytesWarning # 与bytes和bytearray相关的警告的基类
+-- ResourceWarning # 与资源使用相关的警告的基类。被默认警告过滤器忽略
二、requests模块的相关异常
要调用requests模块的内置异常,只要“from requests.exceptions import xxx”就可以了,比如:
from requests.exceptions import ConnectionError, ReadTimeout
或者直接这样也是可以的:
from requests import ConnectionError, ReadTimeout
requests模块内置异常类的层次结构如下
IOError
+-- RequestException # 处理不确定的异常请求
+-- HTTPError # HTTP错误
+-- ConnectionError # 连接错误
| +-- ProxyError # 代理错误
| +-- SSLError # SSL错误
| +-- ConnectTimeout(+-- Timeout) # (双重继承,下同)尝试连接到远程服务器时请求超时,产生此错误的请求可以安全地重试。
+-- Timeout # 请求超时
| +-- ReadTimeout # 服务器未在指定的时间内发送任何数据
+-- URLRequired # 发出请求需要有效的URL
+-- TooManyRedirects # 重定向太多
+-- MissingSchema(+-- ValueError) # 缺少URL架构(例如http或https)
+-- InvalidSchema(+-- ValueError) # 无效的架构,有效架构请参见defaults.py
+-- InvalidURL(+-- ValueError) # 无效的URL
| +-- InvalidProxyURL # 无效的代理URL
+-- InvalidHeader(+-- ValueError) # 无效的Header
+-- ChunkedEncodingError # 服务器声明了chunked编码但发送了一个无效的chunk
+-- ContentDecodingError(+-- BaseHTTPError) # 无法解码响应内容
+-- StreamConsumedError(+-- TypeError) # 此响应的内容已被使用
+-- RetryError # 自定义重试逻辑失败
+-- UnrewindableBodyError # 尝试倒回正文时,请求遇到错误
+-- FileModeWarning(+-- DeprecationWarning) # 文件以文本模式打开,但Requests确定其二进制长度
+-- RequestsDependencyWarning # 导入的依赖项与预期的版本范围不匹配
Warning
+-- RequestsWarning # 请求的基本警告
下面是一个简单的小例子,python内置了一个ConnectionError异常,这里可以不用再从requests模块import了
import requests
from requests import ReadTimeout
def get_page(url):
try:
response = requests.get(url, timeout=1)
if response.status_code == 200:
return response.text
else:
print('Get Page Failed', response.status_code)
return None
except (ConnectionError, ReadTimeout):
print('Crawling Failed', url)
return None
def main():
url = 'https://www.baidu.com'
print(get_page(url))
if __name__ == '__main__':
main(
三、用户自定义异常
此外,你也可以通过创建一个新的异常类拥有自己的异常,异常应该是通过直接或间接的方式继承自Exception类。下面创建了一个MyError类,基类为Exception,用于在异常触发时输出更多的信息。
在try语句块中,抛出用户自定义的异常后执行except部分,变量 e 是用于创建MyError类的实例
class MyError(Exception):
def __init__(self, msg):
self.msg = msg
def __str__(self):
return self.msg
try:
raise MyError('类型错误')
except MyError as e:
print('My exception occurred', e.msg
except as e中的‘e’的作用:
这个e是异常类的一个实例,如果我们完整地解释这个问题,我觉得还是从Python的自定义异常类说起比较好。 假如,我们现在自定义一个简单的异常类:
class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
我们抛这个异常的时候可以这么写:
try:
raise MyError(2*2)
except MyError as e:
print 'My exception occurred, value:', e.value
我们在捕获这个异常之后假如需要访问TA的一些属性怎么办,这个时候就可以使用as关键字 所以,这里的e是前面MyError异常类的一个实例,我们可以直接访问他的value,也就是你看到的e.value
四、异常捕获
当发生异常时,我们就需要对异常进行捕获,然后进行相应的处理。python的异常捕获常用try…except…结构,把可能发生错误的语句放在try模块里,用except来处理异常,每一个try,都必须至少对应一个except。此外,与python异常相关的关键字主要有:
| 关键字 | 关键字说明 |
|---|---|
| try/except | 捕获异常并处理 |
| pass | 忽略异常 |
| as | 定义异常实例(except MyError as e) |
| else | 如果try中的语句没有引发异常,则执行else中的语句 |
| finally | 无论是否出现异常,都执行的代码 |
| raise | 抛出/引发异常 |
1.捕获所有异常
包括键盘中断和程序退出请求(用sys.exit()就无法退出程序了,因为异常被捕获了),因此慎用
try:
<语句>
except:
print('异常说明')
2.捕获指定异常
try:
<语句>
except <异常名>:
print('异常说明'
3.捕获万能异常
try:
<语句>
except Exception:
print('异常说明'
例如
try:
f = open("file-not-exists", "r")
except IOError as e:
print("open exception: %s: %s" %(e.errno, e.strerror)
4.捕获多个异常
捕获多个异常有两种方式,第一种是一个except同时处理多个异常,不区分优先级:
try:
<语句>
except (<异常名1>, <异常名2>, ...):
print('异常说明'
第二种是区分优先级的:
try:
<语句>
except <异常名1>:
print('异常说明1')
except <异常名2>:
print('异常说明2')
except <异常名3>:
print('异常说明3'
该种异常处理语法的规则是:
执行try下的语句,如果引发异常,则执行过程会跳到第一个except语句。
如果第一个except中定义的异常与引发的异常匹配,则执行该except中的语句。
如果引发的异常不匹配第一个except,则会搜索第二个except,允许编写的except数量没有限制。
如果所有的except都不匹配,则异常会传递到下一个调用本代码的最高层try代码中。
5.异常中的else
如果判断完没有某些异常之后还想做其他事,就可以使用下面这样的else语句。
try:
<语句>
except <异常名1>:
print('异常说明1')
except <异常名2>:
print('异常说明2')
else:
<语句> # try语句中没有异常则执行此段代码
6.异常中的finally
try…finally…语句无论是否发生异常都将会执行最后的代码。
try:
<语句>
finally:
<语句>
看一个示例:
str1 = 'hello world'
try:
int(str1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
else:
print('try内没有异常')
finally:
print('无论异常与否,都会执行我')
7.raise主动触发异常
可以使用raise语句自己触发异常,raise语法格式如下:
raise [Exception [, args [, traceback]]]
语句中Exception是异常的类型(例如ValueError),参数是一个异常参数值。该参数是可选的,如果不提供,异常的参数是"None"。最后一个参数是跟踪异常对象,也是可选的(在实践中很少使用)。
例如
def not_zero(num):
try:
if num == 0:
raise ValueError('参数错误')
return num
except Exception as e:
print(e)
not_zero(0)
五、 采用traceback模块查看异常
发生异常时,Python能“记住”引发的异常以及程序的当前状态。Python还维护着traceback(跟踪)对象,其中含有异常发生时与函数调用堆栈有关的信息。记住,异常可能在一系列嵌套较深的函数调用中引发。程序调用每个函数时,Python会在“函数调用堆栈”的起始处插入函数名。一旦异常被引发,Python会搜索一个相应的异常处理程序。如果当前函数中没有异常处理程序,当前函数会终止执行,Python会搜索当前函数的调用函数,并以此类推,直到发现匹配的异常处理程序,或者Python抵达主程序为止。这一查找合适的异常处理程序的过程就称为“堆栈辗转开解”(StackUnwinding)。解释器一方面维护着与放置堆栈中的函数有关的信息,另一方面也维护着与已从堆栈中“辗转开解”的函数有关的信息。
格式如下:
try:
block
except:
traceback.print_exc()
例如:
try:
1/0
except Exception as e:
print(e)
如果我们这样写的话,程序只会报“division by zero”错误,但是我们并不知道是在哪个文件哪个函数哪一行出的错。
下面使用traceback模块,官方参考文档:28.10. traceback — Print or retrieve a stack traceback — Python 2.7.18 documentation
import traceback
try:
1/0
except Exception as e:
traceback.print_exc()
这样就会帮我们追溯到出错点:
Traceback (most recent call last):
File "E:/PycharmProjects/ProxyPool-master/proxypool/test.py", line 4, in <module>
1/0
ZeroDivisionError: division by zero
另外,traceback.print_exc()跟traceback.format_exc()有什么区别呢?
区别就是:format_exc()返回字符串,print_exc()则直接给打印出来。即traceback.print_exc()与print(traceback.format_exc())效果是一样的。
print_exc()还可以接受file参数直接写入到一个文件。比如可以像下面这样把相关信息写入到tb.txt文件去。
traceback.print_exc(file=open('tb.txt','w+'))


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









