







一、背景
有时候看到某一个微信公众号中的文章,觉得写的非常不错,有种当时就想把该公众号所有的文章都看完的冲动,但是使用手机看不是特别方便,就想把文章全部下载下来到电脑上面看。
二、爬虫实现步骤
使用python爬取微信公众号文章,总共分为如下几步:
第一步:获取微信公众号的文章地址和入参规则;
第二步:将爬取的文章标题和url保存到数据库;
第三步:针对微信公众号连续爬取超过60次会提示访问太频繁而拒绝响应(记录当前爬取到的页码及异常情况处理)【{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}】
三、爬虫实现过程
第一步:需要有一个个人微信公众号,订阅号也是可以的。
第二步:进入微信公众平台,新建图文素材,在界面上方有一个“超链接”的按钮,点击进入。
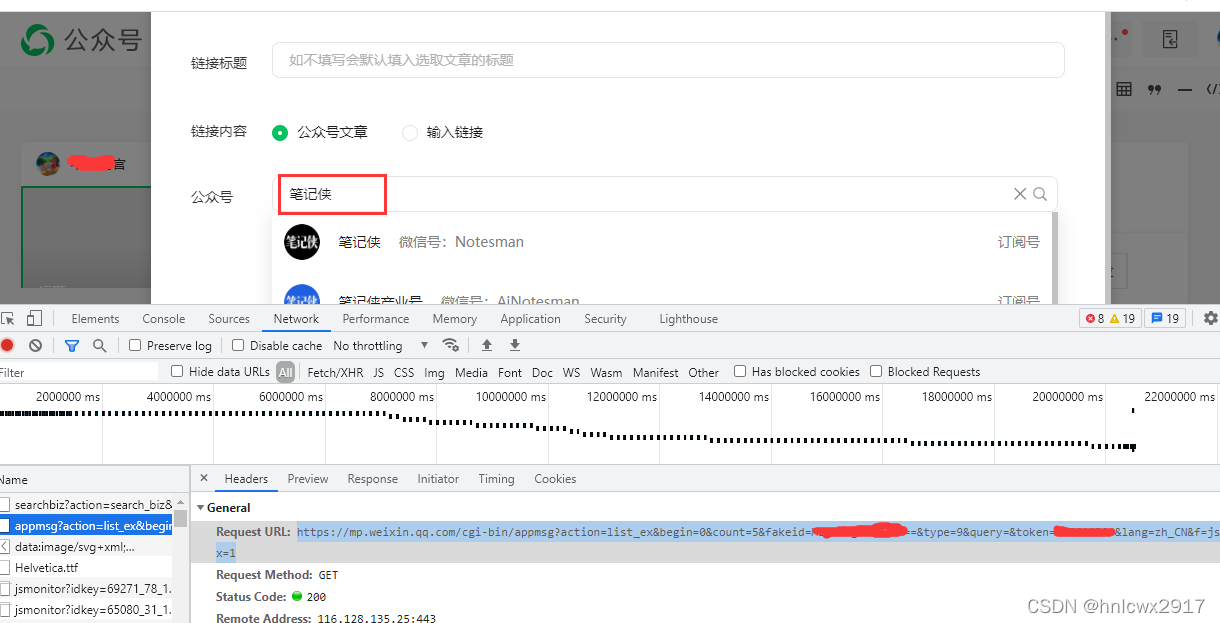
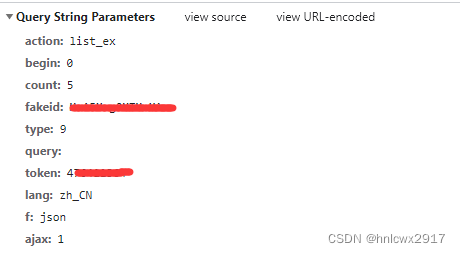
第三步:输入公众号名称进行检索,按F12,如下图显示公众号的文章请求地址、cookie、user-agent、请求参数。
# -*- coding: utf-8 -*-
import requests
import time
import csv
import pandas as pd
import traceback
import mymysql
import uuid
# 目标url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
headers = {
"Cookie": "appmsglist_action_3202723363=card; pgv_pvid=532343460; ua_id=OlRastLitDwq627TAAAAAJzUEREVZq7JaMyyQMxMEIw=; wxuin=42623452127; mm_lang=zh_CN; uuid=2702030d23431cc966563362; rand_info=CAESIKyltjg5bkliwmXupK/rdnCAEv5Nymy4o9rKsv12DRqR; slave_bizuin=3202723363; data_bizuin=3202723363; bizuin=3204433363; data_ticket=3JEz+aeGoOMeIRs/DjEPhZnKfqzismwik5LzOk6uXt+Z7CBkXJ+taoQJdCFeb8bJ; slave_sid=Zk5zbFBjODBTT3ZHVGR4ZzRWSTRMZnlPY2tTN2pjVnI5MFdyZzRxX2NNWTRNVV9aUHFjdlZ4Y0xrallmQ2c0WmcxWWFoaGZJVGlPVUJzOTBRNzhWSGpKT216a2lOS2c1VHF4YkVVa0drR2R0VlRqR01tMEoyM2dLMXhIb2M5TGZNOHNJQXRPaTl0SGpZMzd2; slave_user=gh_968271d6ce85; xid=81ded7b144cd53195323432e6e776",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
}
data = {
"token": "474544364",
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": "0",
"count": "5",
"query": "",
"fakeid": "MzA5MzMA==",
"type": "9",
}
#时间转日期格式
def timetoDate(timeStamp):
#timeStamp = 1643275175
timeArray = time.localtime(timeStamp)
otherStyleTime = time.strftime("%Y-%m-%d", timeArray)
return otherStyleTime
#抓取公众号文章
def grapArtile():
# 计数器
counter = 0
# 页数
page = 0
content_list = []
# for i in range(20):
content_json = []
# 查询最新的页码
mysqlConn = mymysql.MYMYSQL()
mysqlConn.query()
page = mysqlConn.page_no
try:
while 1:
data["begin"] = page*5
# 使用get方法进行提交
content_json = requests.get(url, headers=headers, params=data).json()
msglen = len(content_json["app_msg_list"]);
#如果没有文章了,退出
if msglen == 0:
break
items = []
# 返回了一个json,里面是每一页的数据
for item in content_json["app_msg_list"]:
# 提取每页文章的标题及对应的url
wzid = uuid.uuid1().hex
yz = (wzid, item["title"], item["link"], timetoDate(item["create_time"]))
items.append(yz)
counter += 1
print("爬取第" + str(page + 1) + "页,第" + str(counter) + "条")
mysqlConn.batchInsert(items)
page = page + 1
time.sleep(3)
except:
print("出现【KeyError】异常,文件保存,原因")
print(content_json)
traceback.print_exc()
mysqlConn.update(page)
time.sleep(30*60)
grapArtile()
else:
print("出现【KeyError】异常,文件保存")
print(content_json)
#saveFile(content_list)
mysqlConn.update(page)
time.sleep(30*60)
grapArtile()
grapArtile()
第五步:将文章标题和url保存到数据库
import pymysql
import traceback
import uuid
class MYMYSQL():
def __init__(self,):
# 打开数据库连接
conn = pymysql.connect("127.0.0.1", "user", "password", "python_pc", charset='utf8')
self.conn = conn
# 查询
def query(self):
self.conn.select_db('python_pc')
# 获取游标
cur = self.conn.cursor()
cur.execute("select * from t_record where sno=1")
while 1:
res = cur.fetchone()
if res is None:
# 表示已经取完结果集
break
print(res[1])
self.page_no = res[1]
cur.close()
#更新
def update(self,cur_no):
self.conn.select_db('python_pc')
# 获取游标
cur = self.conn.cursor()
nums = cur.execute("update t_record set page_no="+str(cur_no)+",update_time=now() where sno=1")
print("更新的数据条数:"+str(nums))
cur.close()
self.conn.commit()
def batchInsert(self, list):
self.conn.select_db('python_pc')
# 获取游标
cur = self.conn.cursor()
# 另一种插入数据的方式,通过字符串传入值
sql = "insert into t_article values(%s,%s,%s,%s)"
insert = cur.executemany(sql, list)
cur.close()
self.conn.commit()
if __name__ == "__main__":
try:
me = MYMYSQL()
# me.query()
# me.update(3)
# me.query()
# list = []
# for i in range(0,5):
# wzid = uuid.uuid1().hex
# yz = (wzid,'111','222')
# list.append(yz)
# print(list)
# me.batchInsert(list)
except:
traceback.print_exc() 参考资料:
https://blog.csdn.net/jingyoushui/article/details/100109164
--python操作mysql数据库
https://blog.csdn.net/kongsuhongbaby/article/details/84948205

















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









