







Uniform Blending(均匀融合)
这一部分从误差的角度介绍最基本的Uniform Blending(均匀融合)的一些理论依据,Uniform Blending的分类的模型如下,实际上就是少数服从多数的原则:
G(x)=sign(∑t=1T1⋅gt(x))G(x)=sign(∑t=1T1⋅gt(x))
回归模型如下,直接求T个模型g的结果的平均值:
G(x)=1T∑t=1T1⋅gt(x)G(x)=1T∑t=1T1⋅gt(x)
下面以回归问题分析误差。
预期g1,g2,⋯,gTg1,g2,⋯,gT的效果应该参差不齐,比如一些g(x)<f(x)g(x)<f(x),还有一些g(x)>f(x)g(x)>f(x),这里的f(x)f(x)是理想的未知的函数,这样通过融合平均下来得到的结果会更加准确。反过来,如果每个gg的结果都差不多,那就没有必要做融合了。下面来分析融合前后的误差比较。
比较gtgt与ff的均方误差与融合之后的GG与ff的均方误差:

关于上述式子的展开有几个细节需要注意:
- avg(gt)=1T∑gt=Gavg(gt)=1T∑gt=G
- f与avg无关
这样我们就可以得到下面的结论,(如果没有看过基石课程的话,这里的EoutEout可以理解为g与f的差距平方):
avg(Eout(gt))≥Eout(G)avg(Eout(gt))≥Eout(G)
可以看出gtgt的平均误差比融合之后的GG要大,也就是说融合模型效果应该会更好。
基于上述的证明,现在考虑一个假想的极限情况,假设我们每次从数据分布中拿出N个数据tDt,然后通过演算法(t)A(Dt)得到gtgt,(因为每次的数据DtDt都不一样,因此每个gg的差别也就会变大,这也正是我们所期望的,得到不同给的模型)。如果数量T趋向于无穷大,我们就可以得到一个理想的g⎯⎯⎯g¯,它可以被认为在所有的数据得到的模型,可以体现出演算法A的在所有的D中的表现了
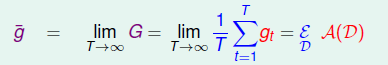
应用上面的结论,有:
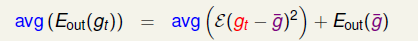
其中g⎯⎯⎯g¯可以代表一堆gtgt的达成的共识(consensus)。式子的第一部分称为我们的演算法A的在不同的数据集上D1,...DTD1,...DT的平均表现,右边式子Eout(g⎯⎯⎯)Eout(g¯)的第二部分就是共识的误差,一般称为 bias,描述的是共识与理想函数f的差距;第一部分avgavg则描述的是一种方差,gtgt与g⎯⎯⎯g¯的平均差别,一般叫做variance, 因此衡量一个演算法的表现,就是bias+varience。 那么我们的Uniform Blending其实就是减少varience的过程。
关于这部分,,gA,D,g等概念,请见机器学习基石笔记
Linear Blending(线性融合)
上面的均匀融合每个g的作用相同,最后的模型可能会变得中庸一些,稍加改变,如果每个g都一个不同的投票权重,效果应该就会更好,这就是线性融合(Linear Blending):
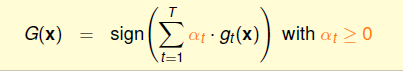
假设我们已经得到了T个gtgt,那么应该如何确定αtαt呢,思路就是minEinminEin,这个式子之前其实遇到过,回想在Linear Regression+Transformation的情况,使用均方误差:
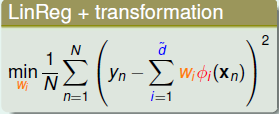
再看看Linear Blending的做回归时候的目标函数:

二者其实是很类似的,我们也可以将gt(x)gt(x)作为一种feature transform,这样我们将原始数据转换为: (zn,yn),zn=(g1(xn),...,gT(xn))(zn,yn),zn=(g1(xn),...,gT(xn)),从这个角度来看与Linear Regression就完全一样了,这时候就可以直接用线性回归的方式来求解αα
然而有一点需要注意的是,Linear Blending有一个约束αt≥0αt≥0,因为每个模型的投票数不能为负数,而Linear Regression则没有这个约束。其实可以从这角度考虑,来去掉这个限制。对于那些αt<0αt<0,我们可以认为是αtgt=|αt|(−gt)αtgt=|αt|(−gt),这样就没有问题了,在物理意义上也可以解释,比如在一个分类问题中,对于那些效果很差的g,我们取其相反数,那么就可以得到一个好的g。到此,Linear Blending 与 Linear Regression + Feature Transform 等价了。
求出了αα,我们还需要注意下如何选择一堆的gtgt:
g1∈1,g2∈2...gT∈Tg1∈H1,g2∈H2...gT∈HT
一种思路是求出每个tHt中EinEin最小的gg,第二种则是EvalEval最小的g−g−,显然为了防止过拟合,应该使用g−g−。
注: g−g−就是使用总数据的N-K个数据做训练,然后用K个数据做验证,选择验证中err最小的g,而非训练误差最小的g。
简单总结下Linear Blending的流程:
- 通过minEvalminEval的方式训练得到T个g−g−
- “特征转化”: zn=ϕ−(xn)=(g−1(xn),g−2(xn)...g−T(xn))zn=ϕ−(xn)=(g1−(xn),g2−(xn)...gT−(xn)),数据变为(zn,yn)(zn,yn)
- Blengding: 计算αα, 现在是一个很简单的线性问题了,通过之前的线性回归,逻辑回归等方法得到投票权重
- 最终的模型: G(x)=LinearModel(∑n=1NαTϕ(x))G(x)=LinearModel(∑n=1NαTϕ(x))
注: 最后的ϕ=(g1,g2....)ϕ=(g1,g2....)而非g−g−,因为通常,使用N-K个数据训练得到minEvalminEval得到最好的g−g−,之后,一般再用全部的N个数据重新训练一遍,得到gg,因为一般数据量越大,模型泛化性能就好.
其实除了Linear Blending之外,在得到(zn,yn)(zn,yn)之后,完全可以用一些其它的非线性的模型去解决这个分类或者回归问题,这样可能更加Powerful,但是也就更容易过拟合,因此还是那句话: Linear First。















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









