






 本文介绍如何使用Python解析JSON字符串,统计其中各种元素(如对象、数组等)的数量,并将结果保存到CSV文件中。通过示例代码,展示了从处理CSV特殊字符到生成最终CSV文件的过程。
本文介绍如何使用Python解析JSON字符串,统计其中各种元素(如对象、数组等)的数量,并将结果保存到CSV文件中。通过示例代码,展示了从处理CSV特殊字符到生成最终CSV文件的过程。
原来的csv文件,里面的数据类型简单展示,(由于csv文件会按逗号分列,所以在原数据上做处理,把","变成了"/",但是在python处理时要重新转换回来)。

代码如下
import json
import csv
import pandas as pd
from collections import Counter
dic={}
a=[]
def flatten(jsonObj, result):
# 判断是否是字典
if isinstance(jsonObj, dict):
for key in jsonObj:
if key=='id':
continue
# value是数组
elif isinstance(jsonObj[key], list):
# 数组元素
if len(jsonObj[key]) > 0:
if isinstance(jsonObj[key][0], dict):
flatten(jsonObj[key], result)
else:
try:
result.append(key + ':' + str(jsonObj[key]))
except BaseException:
print('错误')
else:
continue
else:
continue
# value是字典
elif isinstance(jsonObj[key], dict):
flatten(jsonObj[key], result)
else:
try:
result.append(key + ':' + str(jsonObj[key]))
except BaseException:
print('错误')
else:
continue
# 如果是数组
else:
for item in jsonObj:
flatten(item, result)
def parse(fpath):
result=[]
with open(fpath, newline='') as csvfile:
next(csvfile)
reader = csv.reader(csvfile, delimiter=',',quotechar='"')
for row in reader:
#print(type(row[1]))
#return 0
try:
flatten(json.loads(row[1].replace('/',',')),result) #因为csv文件会将英文逗号左右的数据分成两列,所以在数据下载时,我把英文逗号换成了'/',所以在python解析时要换回来
except BaseException:
print('错误')
else:
continue
return result
def counter(arr):
return Counter(arr)
arr=parse(r'C:\Users\wzywangzhongyuan_i\Desktop\jsonfile\jsonfenjie\job_id=12015451_dir\job_id=12015451ab.csv')
my_dict=counter(arr)
my_df=pd.DataFrame.from_dict(my_dict, orient='index')
my_df.to_csv(r'C:\Users\wzywangzhongyuan_i\Desktop\jsonfile\jsonddd.csv', sep='\t', header=True, index=True,encoding='utf-8')
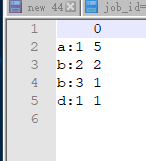
得到的结果(这里没有选择用csv文件打开,而是用notepad打开的,但它是一个csv文件)

















 4970
4970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









