







官网
下载
https://archive.apache.org/dist/hadoop/common/
ssh免密登录
解压缩
tar -zxvf hadoop-2.6.5.tar.gz
cp hadoop-2.6.5/ ../soft/添加环境变量
export JAVA_HOME=/usr/local/soft/jdk1.8.0_351
export HADOOP_HOME=/usr/local/soft/hadoop-2.6.5/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin::$HADOOP_HOME/sbin修改脚本环境变量,因为脚本通过SSH去执行hadoop的配置文件 脚本中的环境变量不能读取,所以修改成绝对路径
[root@node1 hadoop-2.6.5]# vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_351修改配置文件
vim core-site.xml
<configuration>
<!-- 配置分布式文件系统的schema和ip以及port,默认8020-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
</configuration>vim hdfs-site.xml
<configuration>
<!-- 配置副本数,注意,伪分布模式只能是1。-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 修改默认NameNode持久化目录 防止内存紧缺时回收/tmp下文件 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/DataOrLogs/hadoop/local/hadoop/local/dfs/name</value>
</property>
<!-- 修改默认DataNode持久化目录 防止内存紧缺时回收/tmp下文件 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/DataOrLogs/hadoop/local/hadoop/local/dfs/data</value>
</property>
<!-- SecondaryNameNode -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/data/DataOrLogs/hadoop/local/hadoop/local/dfs/secondary</value>
</property>
</configuration>vim slaves 决定DataNode在哪里启动
node1初始化
格式化NameNode
hdfs namenode -format 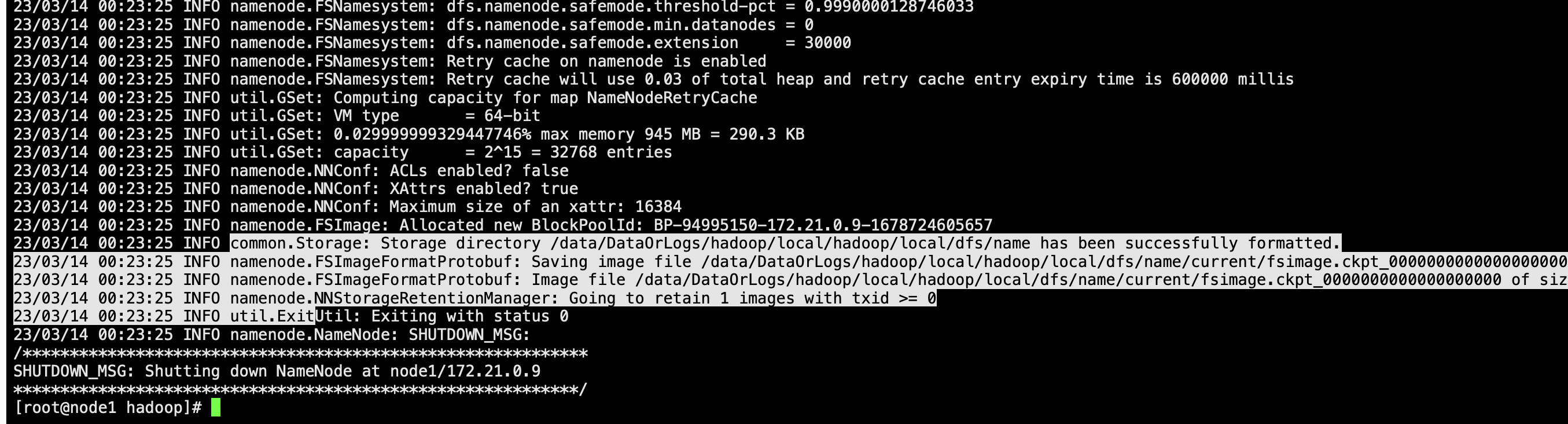
对应的NameNode 存储位置会有持久化的NameNode信息
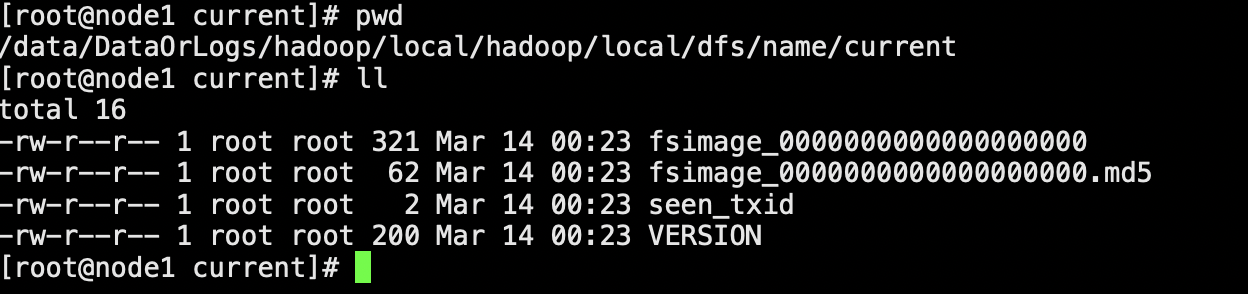
启动hdfs
start-dfs.sh 
启动后会生成data数据 和SND数据 并且集群ID是一致的
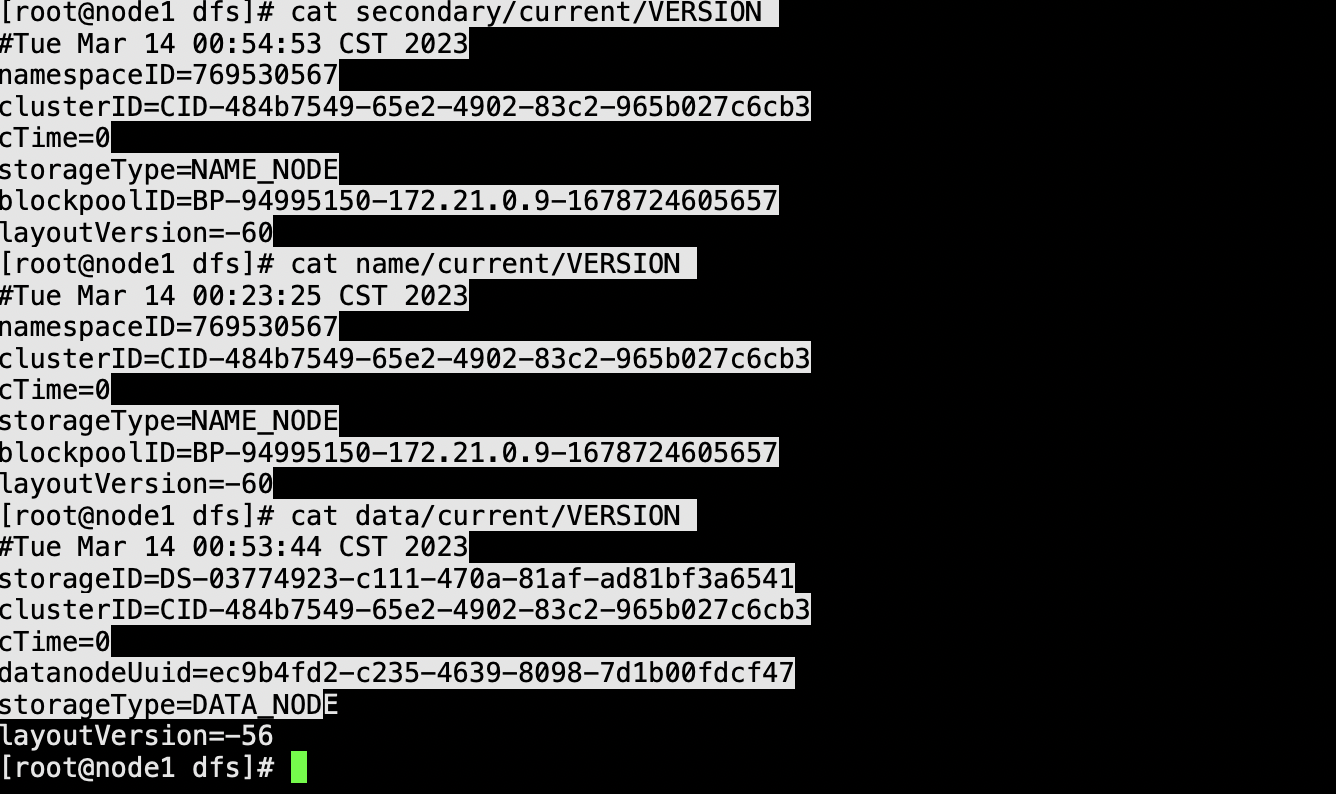
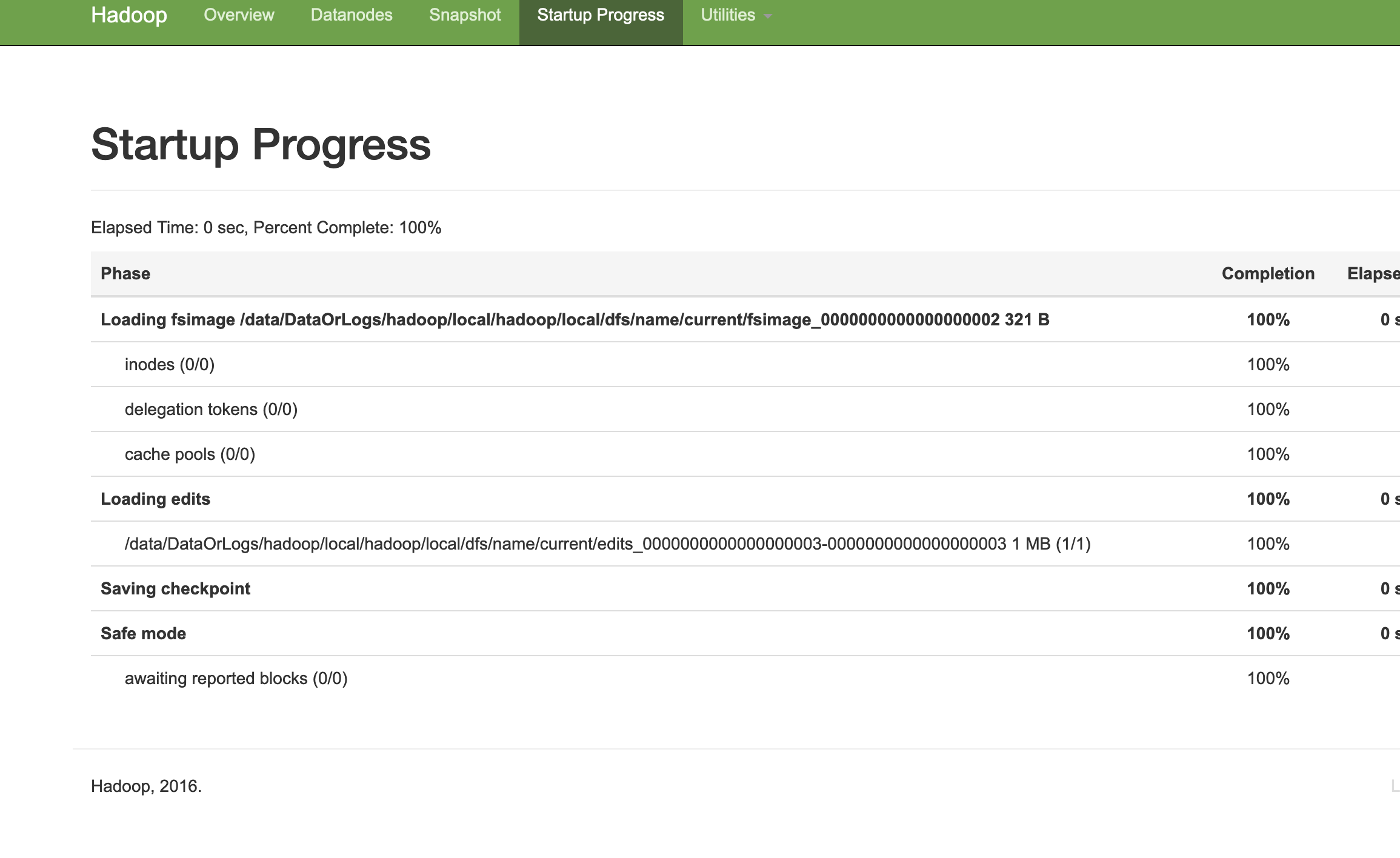
Namenode启动日志中先加载002的fsimage 然后在加载正在编辑的edits003 滚动 合成005 然后退出保护模式
正在编辑的文件为006 ,跟文件系统中的文件相吻合。
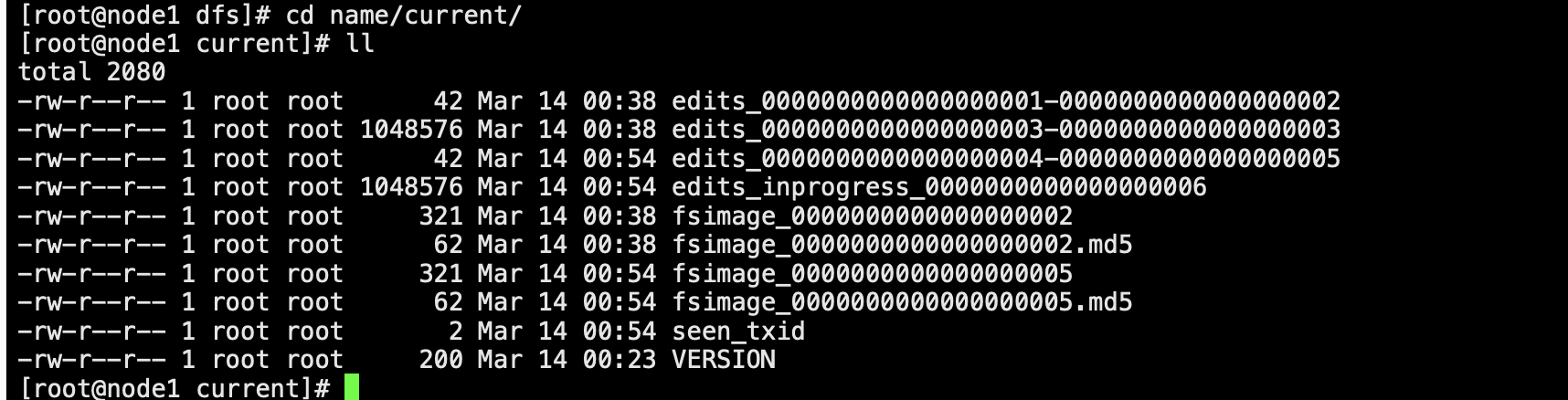
SND 只需要拷贝出002 和002后面的增量

创建一个路径
hdfs dfs -mkdir /bigdata相应路径已经被创建
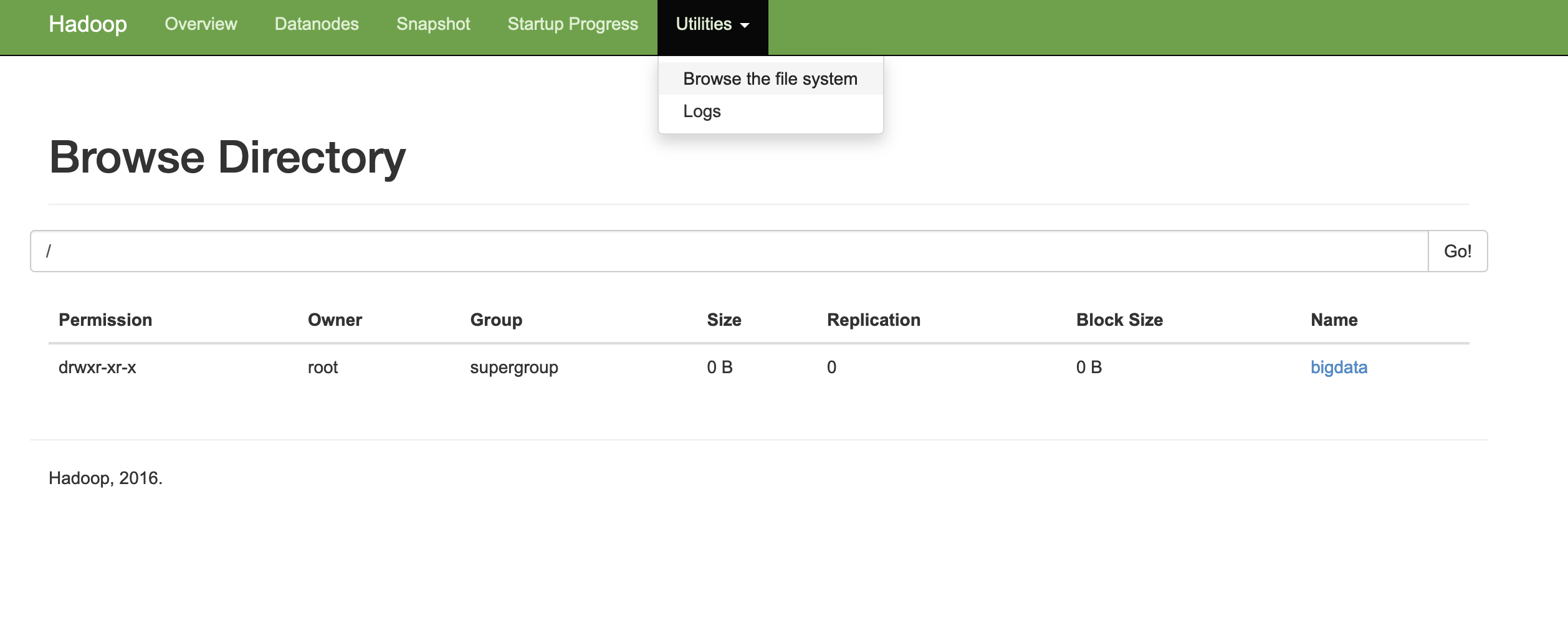
上传文件
hdfs dfs -put /usr/local/softtargz/hadoop-2.6.5.tar.gz /user/root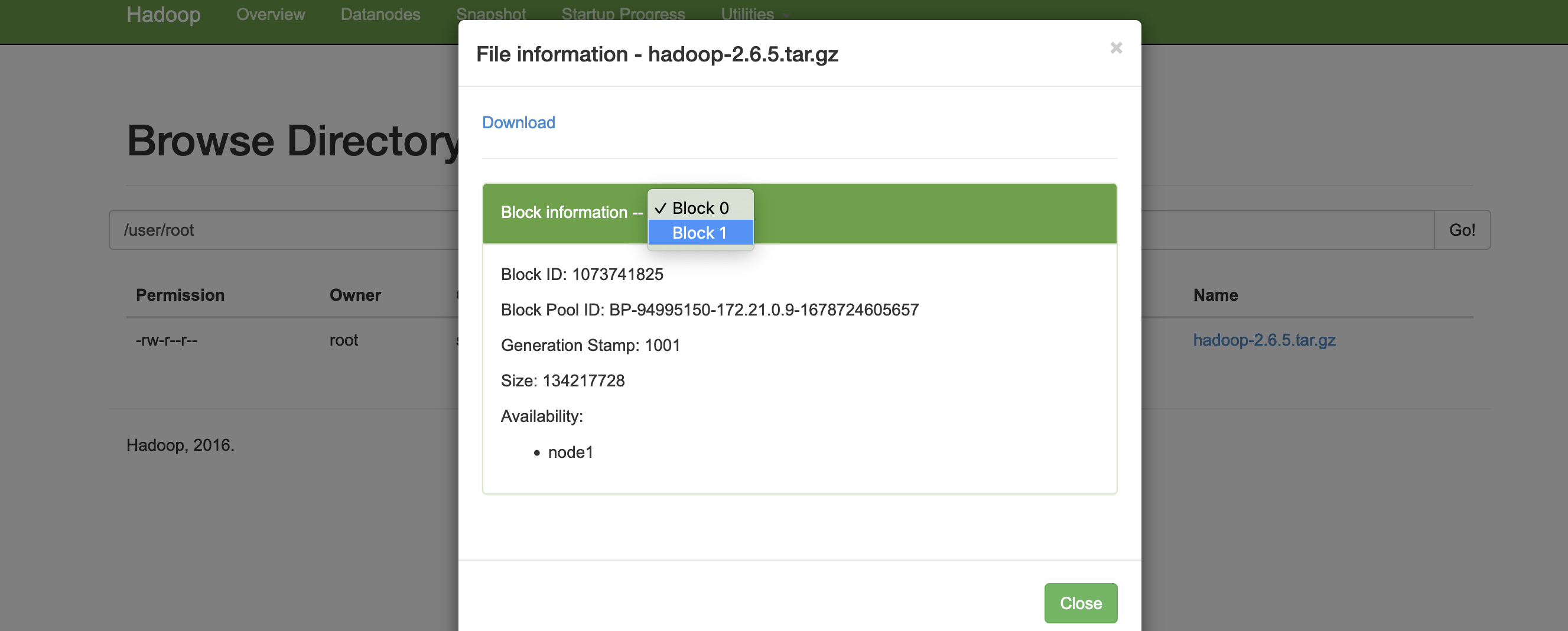



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









