







 超级会员免费看
超级会员免费看
 本文详细介绍了如何搭建Hadoop3.2.1的高可用集群,包括三种部署模式的概述、集群搭建前的准备工作、高可用配置、文件分发、服务启动及常见问题的解决。重点讲解了Zookeeper的高可用设置,以及集群模式下的HDFS、YARN配置。
本文详细介绍了如何搭建Hadoop3.2.1的高可用集群,包括三种部署模式的概述、集群搭建前的准备工作、高可用配置、文件分发、服务启动及常见问题的解决。重点讲解了Zookeeper的高可用设置,以及集群模式下的HDFS、YARN配置。
目录
2、Pseudo-Distributed mode(伪分布式模式)
1、高可用下提示Operation category READ is not supported in state standby
一、Hadoop部署的三种方式
1、Standalone mode(独立模式)
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
2、Pseudo-Distributed mode(伪分布式模式)
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
3、Cluster mode(集群模式)
单Namenode节点模式-高可用HA模式
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
本教程主要安装 多Namenode 节点 高可用集群模式
二、准备工作
1、先完成zk高可用搭建
【大数据入门核心技术-Zookeeper】(五)ZooKeeper集群搭建
2、/etc/hosts增加内容
172.30.1.56 hadoop001
172.30.1.57 hadoop001
172.30.1.58 hadoop001
3、各台服务器分别创建目录
mkdir -p /data/bigdata/hadoop/tmp
mkdir -p /data/bigdata/hadoop/var
mkdir -p /data/bigdata/hadoop/dfs/name
mkdir -p /data/bigdata/hadoop/dfs/data
mkdir -p /data/bigdata/hadoop/jn
4、关闭防火墙和禁用swap交换分区
1)关闭防火墙和SeLinux
systemctl stop firewalld && systemctl disable firewalld
setenforce 0
sed -i 's/SELINUX=.*/SELINUX=disabled/g' /etc/sysconfig/selinux
2)禁用swap交换分区
swapoff -a && sed -i 's/SELINUX=.*/SELINUX=disabled/g' /etc/sysconfig/selinux
5、三台机器间免密
生成密钥
ssh-keygen -t rsa
将密钥复制到其他机器
ssh-copy-id slave1
ssh-copy-id slave2
6、安装jdk
将jdk目录复制到/usr/local
vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
java -version
查看结果
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
7、下载好hadoop安装包
下载地址
本次以hadoop3.2.1下载为例
解压
tar zxvf hadoop-3.2.1.tar.gz -C /usr/localvim /etc/profile
export HADOOP_HOME=/usr/local/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binsource /etc/profile
三、高可用配置
1、配置core-site.xml
<configuration>
<!-- 把多个 NameNode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/bigdata/hadoop/tmp</value>
</property>
<!-- 指定 zkfc 要连接的 zkServer 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
<!-- NN 连接 JN 重试次数,默认是 10 次 -->
<property>
<name>ipc.client.connect.max.retries</name>
<value>20</value>
</property>
<!-- 重试时间间隔,默认 1s -->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>5000</value>
</property>
</configuration>
2、配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/bigdata/hadoop/dfs/name</value>
<description>datanode 上存储 hdfs 名字空间元数据</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/bigdata/hadoop/dfs/data</value>
<description>datanode 上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>副本个数,默认配置是 3,应小于 datanode 机器数量</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- JournalNode 数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/bigdata/hadoop/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- NameNode 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop101:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop103:8020</value>
</property>
<!-- NameNode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop101:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop103:9870</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/mycluster</value>
</property>
<!-- 访问代理类:client 用于确定哪个 NameNode 为 Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>3、配置yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明两台 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定 resourcemanager 的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop101</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop101:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop101:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop101:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop101:8031</value>
</property>
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop102</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop102:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop102:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop102:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop102:8031</value>
</property>
<!-- ========== rm3 的配置 ========== -->
<!-- 指定 rm3 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>hadoop103</value>
</property>
<!-- 指定 rm3 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>hadoop103:8088</value>
</property>
<!-- 指定 rm3 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>hadoop103:8032</value>
</property>
<!-- 指定 AM 向 rm3 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>hadoop103:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>hadoop103:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLAS
SPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- ZK中ZNode节点能存储的最大数据量,以字节为单位,默认是 1048576 字节,也就是1MB,现在扩大100倍 -->
<property>
<name>yarn.resourcemanager.zk-max-znode-size.bytes</name>
<value>104857600</value>
</property>
</configuration>4、配置mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
</configuration>5、配置workers
hadoop101
hadoop102
hadoop1036、修改配置hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/usr/local/hadoop-2.3.1
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root四、分发文件
scp -r /usr/local/hadoop-3.2.1 hadoop102:/usr/local
scp -r /usr/local/hadoop-3.2.1 hadoop103:/usr/local
五、启动服务
在各个 JournalNode 节点上(每台虚拟机),输入以下命令启动 journalnode 服务
hdfs --daemon start journalnode
node1上格式化namenode
hdfs namenode -format
node1上启动namenode
hdfs --daemon start namenode
在 [nn2,nn3] 上,同步 nn1 的元数据信息
hdfs namenode -bootstrapStandby
在node1节点上格式化ZKFC
hdfs zkfc -formatZK
node1节点上启动HDFS和Yarn
start-dfs.sh
start-yarn.sh
到此hadoop高可用集群搭建就完成了。
六、查看服务
jps
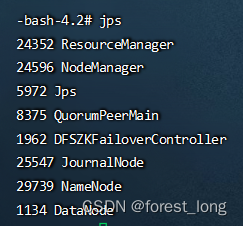
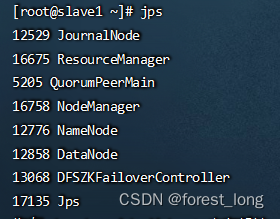
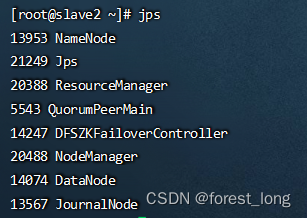
查看yarn服务状态
yarn rmadmin -getAllServiceState
yarn rmadmin -getServiceState rm1
zkCli.sh 客户端查看 ResourceManager 选举锁节点内容:
get -s /yarn-leader-election/cluster-yarn1/ActiveStandbyElectorLock
七、常见问题解决
1、高可用下提示Operation category READ is not supported in state standby
hadoop fs -ls /
总提示
hadoop fs -ls /
2022-12-06 02:02:22,062 INFO retry.RetryInvocationHandler: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:98)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:2021)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1449)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:3183)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:1173)
解决办法:
手动将活跃的namenode切换到第一台
hdfs haadmin -failover nn3 nn1

















 5004
5004




 到【灌水乐园】发言
到【灌水乐园】发言









