







HADOOP学习笔记——HDFS
什么是hdfs
首先我们要知道hdfs是分布式文件系统,它是分布式的由多个服务器共同联合起来实现的,适合存储海量数据,适合一次写入、多次读取的场景。

hdfs的优点
- 高容错性:副本机制使它可以提高容错率,多个副本的存在可以避免数据的丢失。
- 处理大数据:多个服务器组成使它可以存储大量的数据,处理大量文件。
- 对于搭建的集群的服务器要求不高,可以搭建在廉价的机器上,极大的提高了它的数据存储量和多副本机制下的高可靠性。
hdfs的缺点
- 仅适合一次写入,多次读取的情景,不支持并发文件写入和随机修改,仅支持数据的append(追加)
- 不适合低延迟的数据访问
- 不适合对大量的小文件进行存储:因为hdfs的存储会在namenode上存储数据的元数据(文件大小、权限、所处的datanode……),每一个块数据的元数据信息都是固定大小,过多的小文件虽不会对DataNode的存储空间有压力,但是会给namenode的存储空间很大的压力;其次小文件的寻址时间会长于文件信息的读取时间,这不符合设计目标,没有使用分布式的意义。
hdfs的组成框架
- hdfs为主从结构,一个master和多个slave,也就是一个namenode主节点和多个DataNode从节点还有一个secondarynamenode辅助主节点
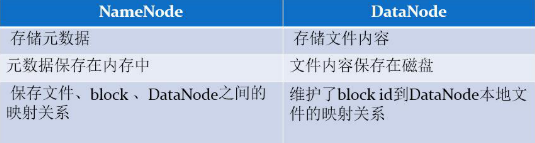
- namenode负责管理hdfs的名称空间,配置副本策略,管理数据块的映射信息,处理客户端的请求
- DataNode负责存储数据块,执行数据块的读写操作
- 客户端:进行文件的切分成块进行上传,与namenode进行RPC通信获取存储位置信息,与DataNode进行socket交互读写数据,可以管理hdfs(格式化namenode、hdfs增删改查操作)
- secondarynamenode:用于辅助namenode对fsimage和edits文件合并返回给namenode减轻namenode工作量,可以恢复namenode的数据(但是有可能不全)
hdfs的特性
- 分块存储:hdfs默认的数据块的大小为128M(hadoop1.x为64M)可以通过
hdfs-site.xml配置
<property>
<name>dfs.block.size</name>
<value>块大小 以字节为单位</value> //只写数值就可以
</property>
块大小的设置与服务器的磁盘读取速度有关,hdfs的设计目标时要求寻址时间是传输读取时间的1%,设置太大会导致传输时间太长,设置太小会导致寻址时间都接近传输时间效率低。 - 副本机制:通过设置hdfs-site.xml中的dfs.replication参数来确定副本的数量,默认为3;副本机制可以确保数据的安全性,当一个副本的数据出现问题可以从其他副本来获取数据,并且集群会保证副本率不小于0.999(除非集群节点不够),在一个节点出现问题时namenode会让正常的DataNode去复制副本来确保副本的时时存在,这也确保了数据的安全,当然这一切都在于namenode数据不会出现问题。
hdfs的读流程

- 首先客户端会通过RPC通信去向namenode发出读取请求
- namenode会核查权限和文件信息是否存在,从而返回文件对应的Block列表和DataNode地址给客户端
- 客户端在接到namenode传回的信息后,会去找到最近的DataNode节点去读取block,建立socket去重复调用datainputstream的read方法读取数据,以packet为单位进行chucksum校验,如果出现异常就告知namenode来获取另一个DataNode继续读取block
- 如一个文件有多个block则多次重复上面操作进行读取,每次读完一个packet都会先在本地缓存然后合并
- 最后将读取到的block写入文件
- 读取文件的源码分析
hdfs的写流程

- 客户端会通过Distributed FileSystem模块去向namenode去请求上传文件
- namenode会去检验权限是否可以创建路径和文件是否存在、父目录是否存在,返回给客户端答应
- 客户端收到答应会将文件切分成块再去请求namenode上传的DataNode地址
- namenode会返回相应的DataNode列表给客户端并会将操作写入edits中以便储存元数据信息
- 客户端在获取到DataNode列表后会通过FSDataOutputStream模块去请求其中一个DataNode1上传数据(其实是通过RPC建立pipeline),DataNode1再去和DataNode2建立通信,DataNode2再去和DataNode3建立通信,将DataNode之间的pipeline打通
- 客户端再将block(先从磁盘读取数据放到一个本地内存缓存)以packet为单位的形式传输给DataNode1,DataNode1获取后会将该packet传输给DataNode2,依次传输给DataNode3,DataNode1每传一个packet会放入一个应答队列等待应答,在传输完成后会从DataNode3依次逐级返回ack成功的应答,客户端最终接收到应答后会继续上传packet,直到文件上传完毕。
网络拓扑-节点距离
在本地网络中,两个节点被称为“彼此近邻”是什么意思?
在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。
这里的想法是将两个节点间的带宽作为距离的衡量标准。
节点距离:两个节点到达最近的共同祖先的距离总和
机架感知(副本节点的选择)
第一种:

第一个选择客户端所在的节点,若客户端不在集群中就随机选择一个集群中的节点dn1。
第二个选择集群中的除了dn1的节点所在的机架,其他机架中随机选择一个dn2.
第三个选择dn2所在的机架,节点随机选择dn3.
第二种:

第一个副本选择和第一种相同
第二个选择dn1所在机架的随机节点dn2
第三个选择与dn1、2的机架不同的机架上的随机节点。
namenode和secondarynamenode的工作机制

1.namenode
- 第一次启动namenode需要对namenode进行格式化,创建fsimage和edits文件;非第一次启动就加载fsimage信息到内存中
- 处理客户端对元数据信息进行增删改的请求
- namenode记录操作日志到edits文件
- namenode在内存中对元数据进行增删改
2.secondarynamenode
- 询问namenode是否需要checkpoint,直接带回namenode是否检查结果
- 请求执行checkpoint
- namenode进行滚写日志
- 将滚动前的edits文件和fsimage拷贝给secondarynamenode
- secondarynamenode进行加载到内存合并fsimage和edits生成新的镜像文件fsimage.chkpoint
- 将合成的文件拷贝给namenode并重新命名替换掉之前的fsimage
DataNode的工作机制
- 启动DataNode,DataNode会向namenode进行注册,通过后会周期性(6小时)的向namenode进行汇报块信息
- DataNode会定期的自己扫描自身的数据去检查数据的完整性
- DataNode的心跳机制,3秒一次会返回namenode的指令
hdfs的容错机制
- 副本机制:副本机制的存在使得数据存储多个,在一个出现问题时可以去访问副本的数据
- 机架机制:机架选用的机制可以确保副本存储时不会因一台机架出现问题导致副本所在的节点全部出现问题
- 心跳机制:DataNode会定时(3秒)向namenode进行汇报,这确保了DataNode的安全性,一旦超过10分30秒为收到DataNode的回应,namenode会判定DataNode‘死亡’,从而去将DataNode上的数据从其他副本上复制到别的节点上
- DataNode自身的定期检查机制:6个小时DataNode会校验自身的数据是否损毁,DataNode会读取自身数据计算checksum,如和之前的不一致则数据损毁需从其他节点拷贝数据















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









