







版权声明:欢迎转载,注明作者和出处就好!如果不喜欢或文章存在明显的谬误,请留言说明原因再踩哦,谢谢,我也可以知道原因,不断进步!https://blog.csdn.net/csonst1017/article/details/86715772
在公司的项目里有很多的地方都是使用lambda表达式的stream()方法来遍历集合,但是用lambda表达式是否就能比普通遍历有更高的效率呢?是否仅仅只是个语法糖?这里我们使用普通的遍历方法来与lambda表达式的遍历进行对比分析。
1.stream()
我们先对stream()的forEach()进行遍历分析:
情况一(集合新增操作):
List<String> list = new ArrayList<>();
List<String> list2 = new ArrayList<>();
for (int i = 0; i < 1000000; i++)
list.add(String.valueOf(i));
//lambda表达式
long start = System.currentTimeMillis();
// list.parallelStream().forEach((s)->{
// list2.add(s.toString());
// });
//普通测试
for (Object s : list) {
list2.add(s.toString());
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + " ms");
普通遍历:
多次测试消耗时间:
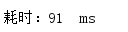
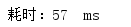
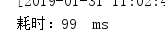
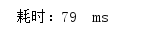
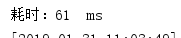
平均耗时: 77ms
lambda表达式遍历:
多次测试消耗时间:
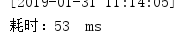
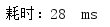
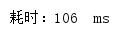
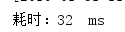

平均耗时: 52ms
对比普通遍历和lambda表达式的集合新增遍历操作,lambda比普通集合平均少消耗25ms的时间(当循环10W次时,2者差距可以忽略不计,这就是我为什么循环100W次的原因)。因为平时我们很少有超过1000000大小的集合,所以这里总结为使用两个方法去遍历都可以,性能差距忽略不计(如果涉及外部变量运算的话用普通循环,不涉及推荐用lambda(少写代码))。
情况二(数据库操作):
List<String> list = new ArrayList<>();
List<String> list2 = new ArrayList<>();
for (int i = 0; i < 100; i++)
list.add(String.valueOf(i));
long start = System.currentTimeMillis();
//lambda表达式
// list.stream().forEach((s) -> {
// productFrontMapper.selectByFrontView(null);
// });
//普通测试
for (Object s : list) {
productFrontMapper.selectByFrontView(null);
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + " ms");
普通遍历:
多次测试消耗时间:
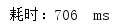
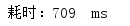
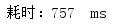
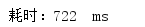
平均耗时: 724 ms
lambda表达式遍历:
多次测试消耗时间:
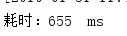
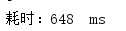
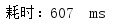
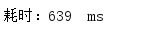
平均耗时: 637ms
对比普通遍历和lambda表达式的数据库操作,lambda比普通集合平均少消耗87ms的时间(当循环10次时,2者差距可以忽略不计,这就是我为什么循环100次数的原因)。当数据库操作次数很大时,推荐lambda表达式,如果只是循环几十次,那么两个方法差距很小。但是平时开发项目我们很少在大集合遍历时去执行数据库操作,所以两者都可以使用(如果涉及外部变量运算的话用普通循环,不涉及推荐用lambda(少写代码))。
2.parallelStream()
分析完stream()的性能接着我们来分析parallelStream()。
parallelStream()与stream()区别是parallelStream()使用多线程去并发遍历,而stream()是单线程。
情况一(集合新增操作):
List<String> list = new ArrayList<>();
List<String> list2 = new ArrayList<>();
for (int i = 0; i < 1000000; i++)
list.add(String.valueOf(i));
long start = System.currentTimeMillis();
//lambda表达式
// list.parallelStream().forEach((s) -> {
// list2.add(s.toString());
// });
//普通测试
for (Object s : list) {
list2.add(s.toString());
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + " ms");
普通遍历:
耗时跟上面测试stream()是一样的,这里我就跳过了。
lambda表达式遍历:
多次测试消耗时间:
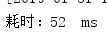
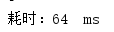
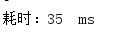


平均耗时: 47ms
由此可见,parallelStream()平均耗时是三者中最低的(针对非数据库操作),但是会有一个问题,因为使用parallelStream()要开放多线程和进行多线程间的切换,会消耗额外的资源,而且parallelStream()不是线程安全的,要进行额外的同步加锁操作。所以遍历时没有进行数据库操作的话,还是使用stream()和普通遍历吧。
情况二(数据库操作):
List<String> list = new ArrayList<>();
List<String> list2 = new ArrayList<>();
for (int i = 0; i < 100; i++)
list.add(String.valueOf(i));
long start = System.currentTimeMillis();
//lambda表达式
list.parallelStream().forEach((s) -> {
productFrontMapper.selectByFrontView(null);
});
//普通测试
// for (Object s : list) {
// list2.add(s.toString());
// }
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + " ms");
普通遍历:
耗时同上。
lambda表达式遍历(重点):
多次测试消耗时间:
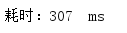
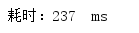
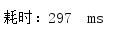
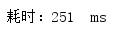
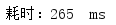
平均耗时: 271ms
可以看到,在数据库操作中,使用parallelStream()来遍历比用stream()和普通for循环遍历强了至少2倍多!所以在这里强烈建议当循环遍历中有数据库操作时,使用parallelStream()来进行遍历!
总结:
当循环遍历中不需要进行数据库操作时,使用stream()或普通循环来遍历(根据实际业务情况来选择用哪个)。
当循环遍历中(多次循环,百次以上)需要进行数据库操作时,使用parallelStream()来遍历,但是要注意多线程安全。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









