







1 集成学习概述
-
集成学习(Ensemble learning)的目的:通过组合多个模型,提升机器学习整体效果 ,避免单个模型性能不足的问题;
-
主要方法:
-
Bagging:
- 训练多个分类器,最终结果取这些分类器预测值的平均;
- 公式 f ( x ) = 1 M ∑ m = 1 M f m ( x ) f(x)=\frac{1}{M}\sum_{m = 1}^{M}f_{m}(x) f(x)=M1∑m=1Mfm(x)中, M M M是分类器数量, f m ( x ) f_{m}(x) fm(x)是第 m m m个分类器的预测结果;
- 随机森林是Bagging的典型代表,通过对数据进行有放回抽样(自助采样)和随机选择特征子集,训练多个决策树并取平均,降低方差,提升模型稳定性和泛化能力;
-
Boosting:
- 从弱学习器开始,逐步加强;
- 在训练过程中,根据前一个学习器的预测结果对样本进行加权 ,让后续学习器更关注被错误分类的样本;
- 公式 F m ( x ) = F m − 1 ( x ) + a r g m i n h ∑ i = 1 n L ( y i , F m − 1 ( x i ) + h ( x i ) ) F_{m}(x)=F_{m - 1}(x)+\underset{h}{argmin}\sum_{i = 1}^{n}L(y_{i},F_{m - 1}(x_{i})+h(x_{i})) Fm(x)=Fm−1(x)+hargmin∑i=1nL(yi,Fm−1(xi)+h(xi)) ,表示第 m m m个模型 F m ( x ) F_{m}(x) Fm(x)是在前一个模型 F m − 1 ( x ) F_{m - 1}(x) Fm−1(x)基础上,加入能使损失函数 L L L最小化的弱学习器 h ( x ) h(x) h(x) ;
- 像AdaBoost、GBDT 等都是Boosting算法,可有效提升模型准确率;
-
Stacking:
- 将多个不同的分类或回归模型进行聚合,通常分阶段进行;
- 先训练多个基模型,再用这些基模型的输出作为新的特征,训练一个高层模型来整合基模型的结果 ,进一步提升模型性能,但计算成本相对较高。
-
2 Bagging 模型
2.1 简介
- 简介:Bagging全称是bootstrap aggregation,本质是并行训练多个分类器 。通过有放回抽样(自助采样)从原始数据集获取多个子集,分别用于训练不同分类器,各分类器训练过程相互独立;
2.2 随机森林
2.2.1 简介
-
随机森林是 Bagging 模型的典型代表;
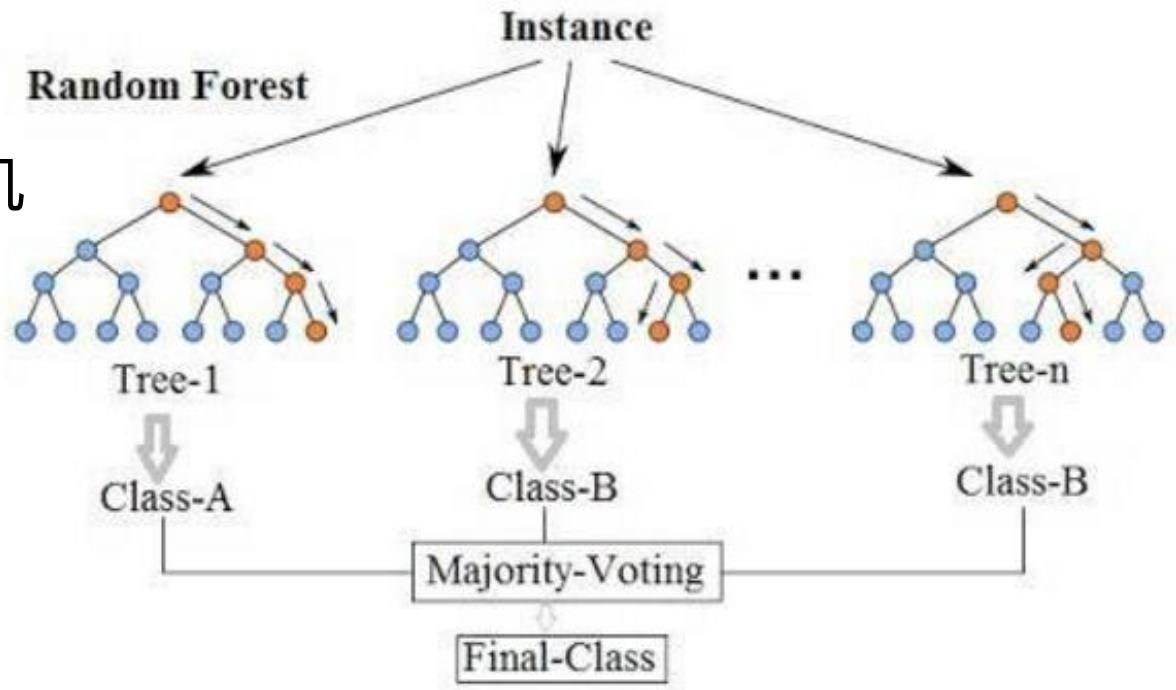
-
随机性的体现:
-
数据采样随机:从原始数据集中有放回地抽取多个样本子集用于训练每棵决策树,使不同决策树训练数据有差异;
-
特征选择随机:在构建每棵决策树时,随机选择部分特征进行节点分裂,降低树之间相关性;
-
-
“森林”的含义:
-
由大量决策树并行组成,众多决策树共同参与预测;
-
在分类任务中,通常采用多数投票法(如图中Majority - Voting )确定最终类别;
-
在回归任务中,一般取各决策树预测值的平均值 ;
-
上图展示了随机森林简化结构,多个决策树(Tree - 1、Tree - 2等)并行,对输入实例(Instance)分别预测,最后通过多数投票确定最终类别(Final - Class)。
-
-
2.2.2 构造树模型的过程
- 构造过程:随机森林由多个决策树(Tree 1、Tree 2、…、Tree n )组成。通过数据采样随机(有放回抽样获取不同样本子集)和特征选择随机(构建树时随机选部分特征),使每棵树结构和最终结果都不同;
- 意义:这种二重随机性保证树之间的差异,避免模型过拟合,提升泛化能力;
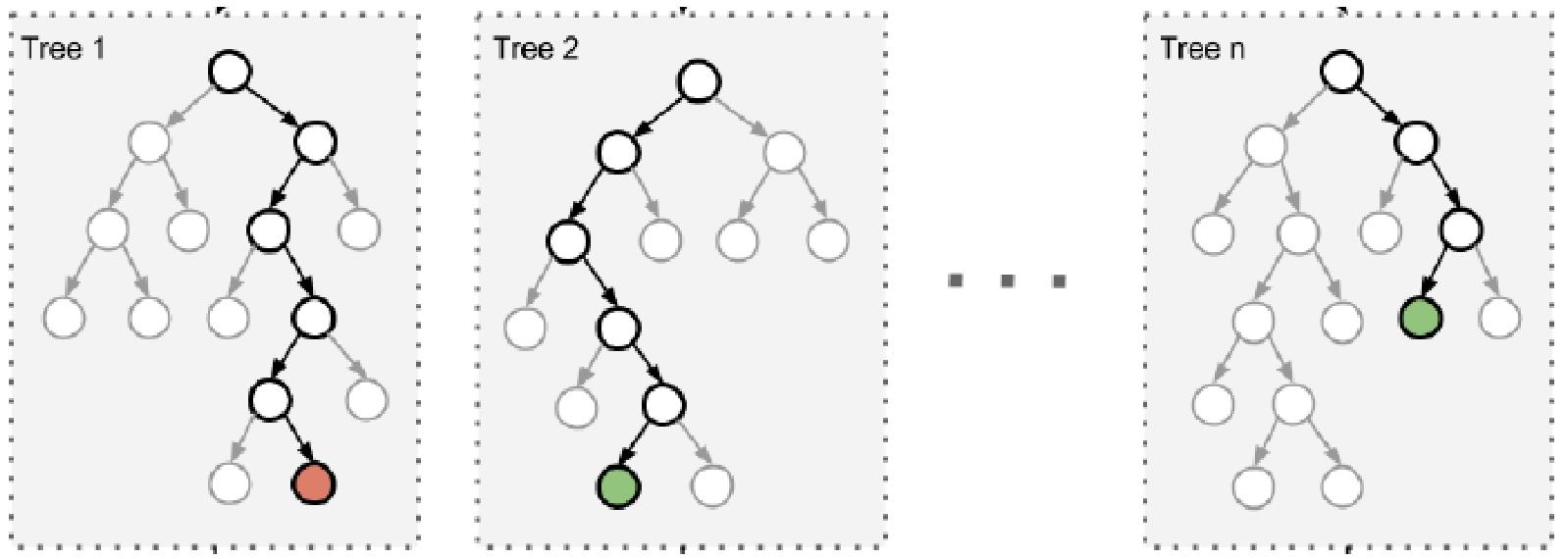
2.2.3 决策树 VS Bagging树模型
-
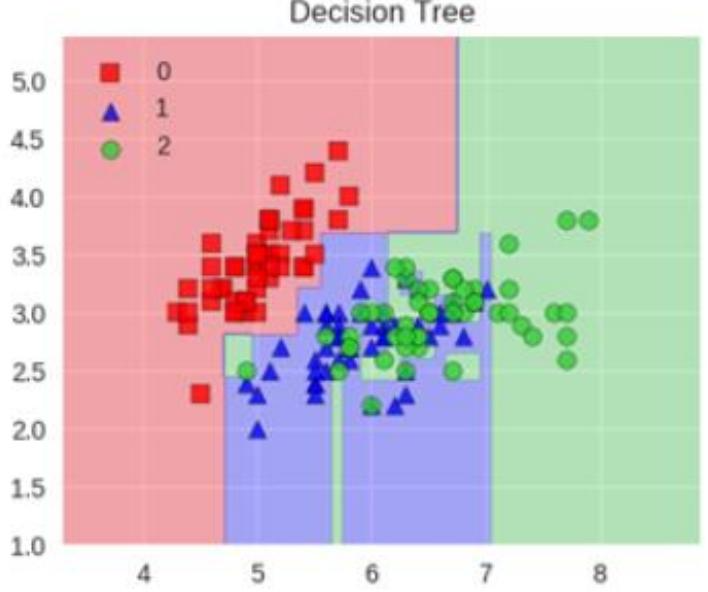
决策树:
-
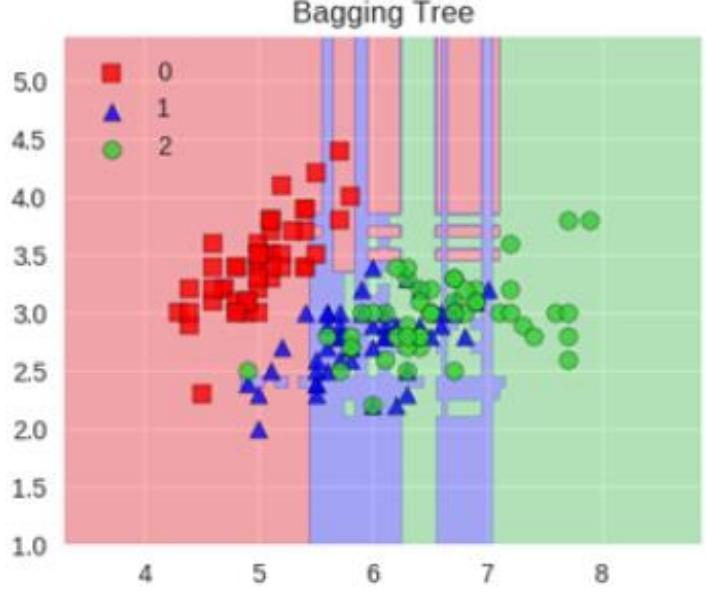
Bagging树模型:
-
上面两图展示了决策树和Bagging树对不同类别数据(红方块、蓝三角、绿圆代表不同类别)的分类区域。Bagging树分类区域更细致,体现多个决策树集成效果;
-
随机的作用:Bagging通过随机方式训练多个树模型,保证泛化能力,若树都相同,集成无意义。
2.2.4 随机森林的优势
-
高维数据处理:能处理高维数据,无需特征选择,因随机选择特征机制可有效处理大量特征;
-
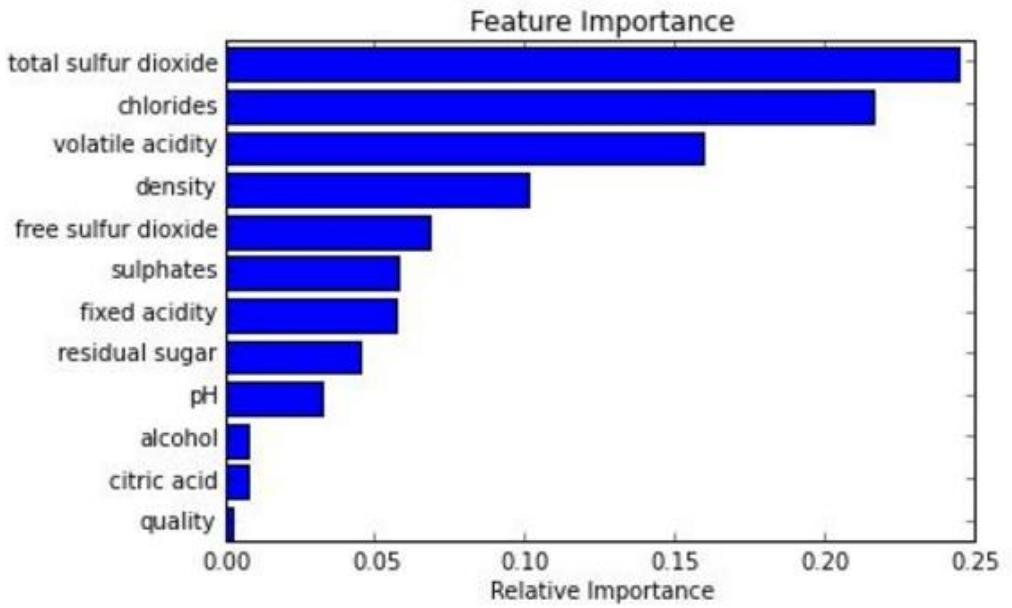
特征重要性评估:训练后可评估特征重要性,如图展示不同特征(total sulfur dioxide、chlorides等)相对重要性,方便理解各特征对模型贡献;
-
并行计算:易并行化,各决策树训练相互独立,可利用多核处理器等并行计算资源,加快训练速度;
-
可视化分析:结果可可视化,便于分析模型决策过程和结果,辅助理解数据内在规律。
2.2.5 KNN模型 VS Bagging K - NN模型
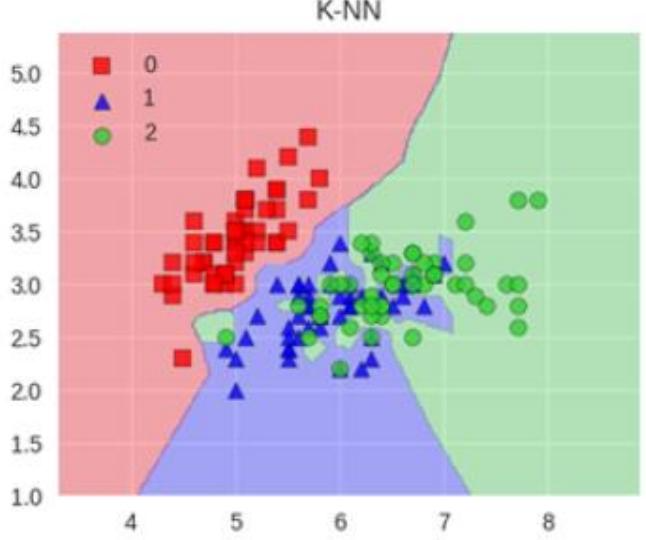
- KNN模型:
-
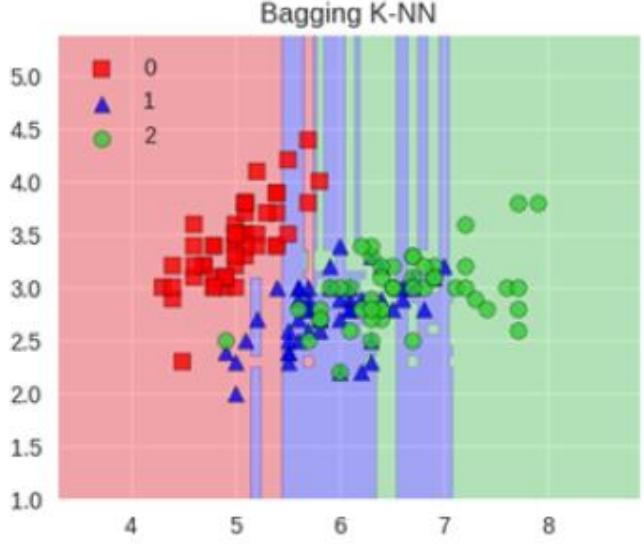
Bagging K - NN模型:
-
模型可视化:通过散点图展示两种模型对不同类别数据(红方块、蓝三角、绿圆代表不同类别 )的分类区域。K - NN模型分类区域相对简单、平滑;Bagging K - NN模型分类区域更复杂、细致 。
-
Bagging对KNN的改进:Bagging是一种集成学习方法,通过并行训练多个分类器取平均提升性能。应用于KNN时,能让模型学习到更多数据特征和规律,从而使分类边界更精细。
-
KNN的局限性:KNN本身不太适合通过随机方式增强泛化能力。KNN基于样本间距离分类,主要依赖近邻样本,难以像Bagging等集成方法那样,通过引入随机性(如随机采样、特征选择等 )来降低模型方差,提升泛化性能。
2.2.6 树的数量
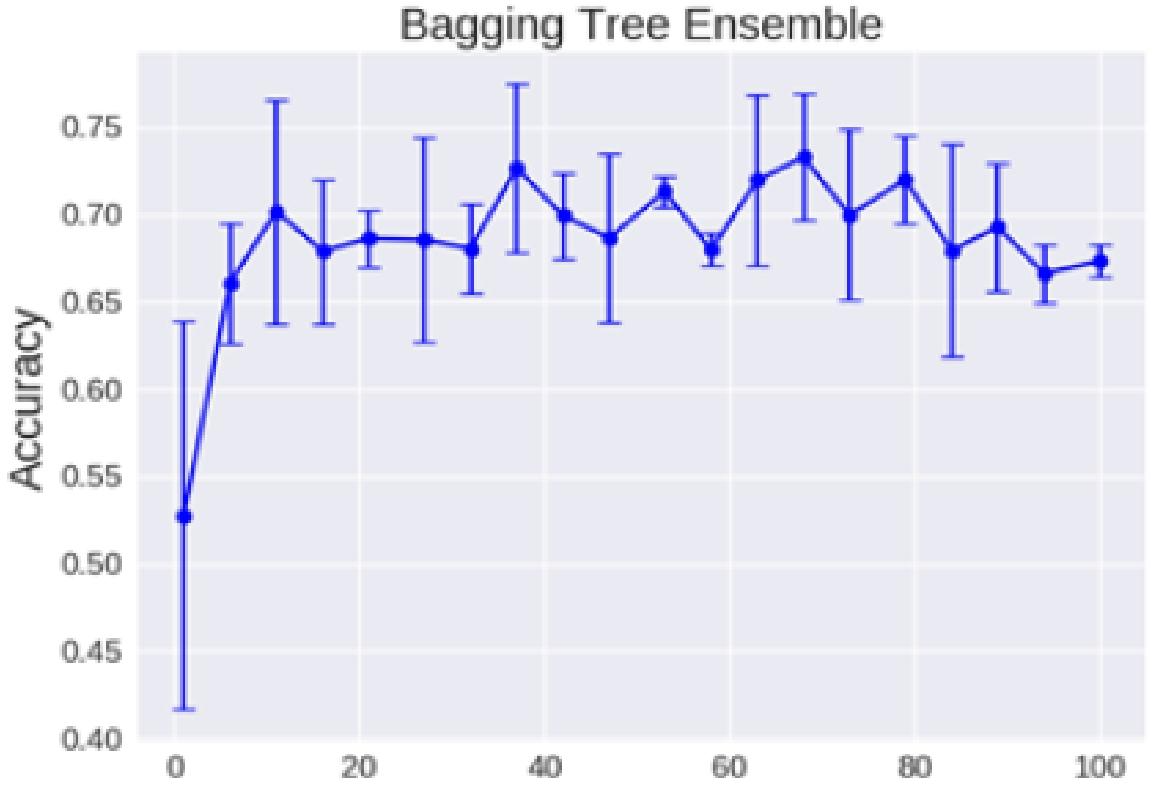
- 图解:
- 横坐标代表树的数量,纵坐标是Accuracy(准确率);
- 图中折线及误差棒展示了随着树的数量增加,模型准确率的变化情况;
- 可以看到,起初准确率较低,随着树的数量增加,准确率逐步上升并在一定范围内波动;
- 原理说明:
- 理论上,在Bagging的森林模型中,增加树的数量能让模型学习到更多数据特征和规律,减少方差,提升整体性能,效果会越来越好;
- 但实际上,当树的数量超过一定程度后,模型可能已充分学习数据特征,再增加树对性能提升有限,准确率基本在一定范围内上下浮动 ,继续增加树不仅耗费资源,也难以显著提高准确率。
3 Boosting 模型
-
AdaBoost和Xgboost是Boosting模型的典型代表;
- AdaBoost是一种迭代算法,通过不断调整样本权重来提升模型性能;
- Xgboost(eXtreme Gradient Boosting)是高效的梯度提升库,在数据挖掘、机器学习竞赛等领域广泛应用,具备正则化、并行计算等优化特性;
-
AdaBoost原理:
- 数据权重调整:AdaBoost会依据前一次分类效果调整数据权重。若某个数据被分错,下一次会赋予它更大权重,使后续学习器更关注这些难分类样本;
- 分类器权重确定:最终,每个分类器根据自身准确性确定权重,再将这些分类器融合,综合得出最终预测结果,以此增强整体模型的预测能力;
-
例:下组图片展示了不同估计器数量(n_est)下AdaBoost模型的分类情况
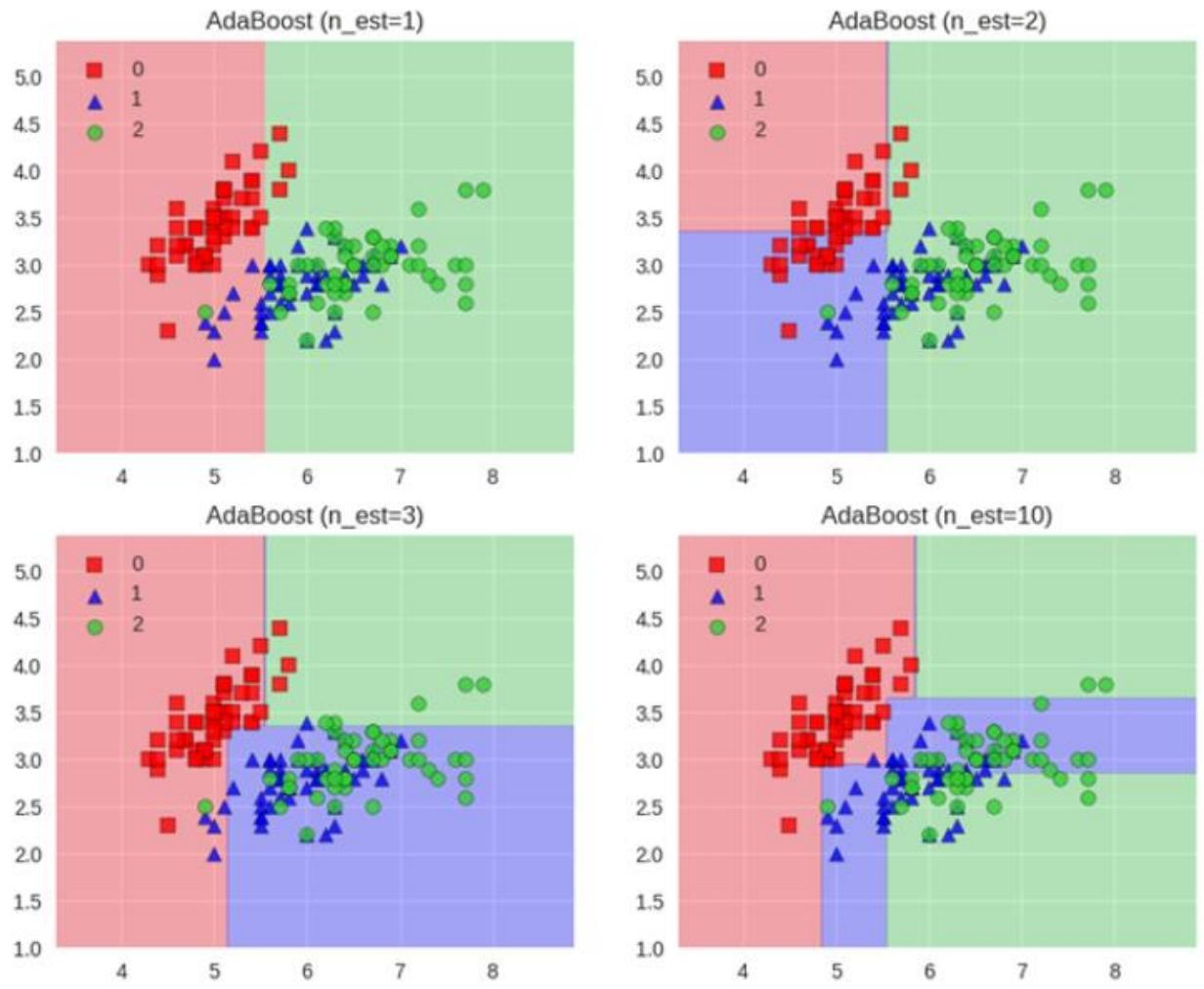
-
数据点:图中不同形状和颜色的点代表不同类别的样本,红方块代表类别0,蓝三角代表类别1,绿圆代表类别2 。
-
分类区域:不同颜色背景区域表示模型对不同类别样本的分类决策区域。随着估计器数量增加:
- 当n_est = 1时,分类区域划分较简单、粗糙,可能无法很好区分各类样本;
- 当n_est = 2时,分类区域有所细化,对样本的区分能力增强;
- 当n_est = 3时,分类区域进一步优化,更准确地覆盖各类样本分布;
- 当n_est = 10时,分类区域更加精细,能更好地将不同类别样本分开,体现出AdaBoost模型通过增加估计器数量,不断提升分类性能,使分类边界更贴合实际样本分布的过程 。这与AdaBoost根据前一次分类效果调整数据权重,让后续学习器更关注难分样本,从而逐步提升分类准确性的原理相契合。
-
4 Stacking 模型
-
模型概念:Stacking是一种集成学习模型,采用“堆叠”的方式,聚合多种不同的分类器 。形象地说,就是将各种分类器(如KNN、SVM、RF等 )直接组合起来使用;
-
实现阶段:
- 第一阶段:使用不同的分类器对原始数据进行训练,各个分类器得出自己的预测结果;
- 第二阶段:将第一阶段各分类器的预测结果作为新的特征,再次进行训练,通常会使用一个新的模型(元模型)来整合这些结果,得出最终的预测;
-
目的:通过这种分阶段的方式,充分利用不同分类器的优势,尽可能提升模型整体性能,以获得更好的预测结果,用一种较为“强力”的手段来优化模型表现;
-
例:下图展示了Stacking模型,并对比了KNN、随机森林(Random Forest)、朴素贝叶斯(Naive Bayes)和Stacking分类器(Stacking Classifier)的分类效果
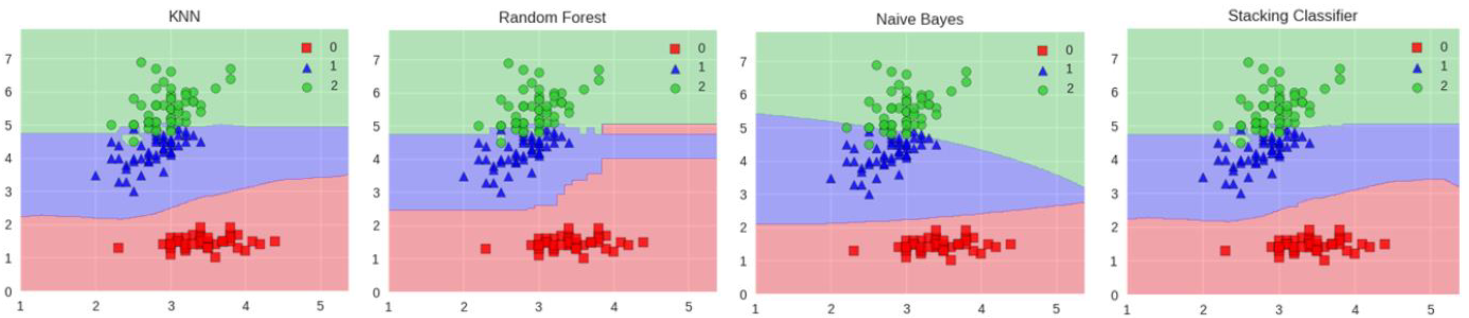
- 图中不同颜色的点(红方块、蓝三角、绿圆 )代表不同类别的样本,不同颜色区域代表各模型的分类决策边界;
- 可以看出,不同基础模型(KNN、随机森林、朴素贝叶斯)的分类边界存在差异,而Stacking分类器整合了这些模型的结果,其分类边界可能更贴合样本实际分布,理论上能提升准确率;
-
Stacking模型特点:
-
优势:通过堆叠多个不同的分类器,充分利用各模型优势,能提升分类准确率 ,在机器学习竞赛和论文研究中,因其能优化结果常被使用;
-
不足:由于需要依次训练多个基础模型,再进行元模型训练,计算成本高,训练和预测速度较慢 。
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









