






 本文介绍了一种使用ABAP编程语言将Unicode编码转换为对应字符的方法。通过详细解析代码,展示了如何查找并替换字符串中的Unicode编码,实现文本的正确显示。
本文介绍了一种使用ABAP编程语言将Unicode编码转换为对应字符的方法。通过详细解析代码,展示了如何查找并替换字符串中的Unicode编码,实现文本的正确显示。
未转换的报文:
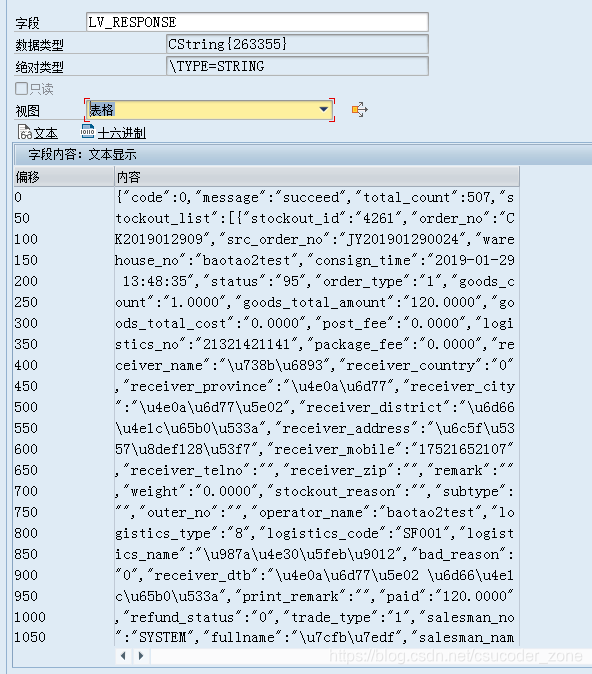
转换后的报文:
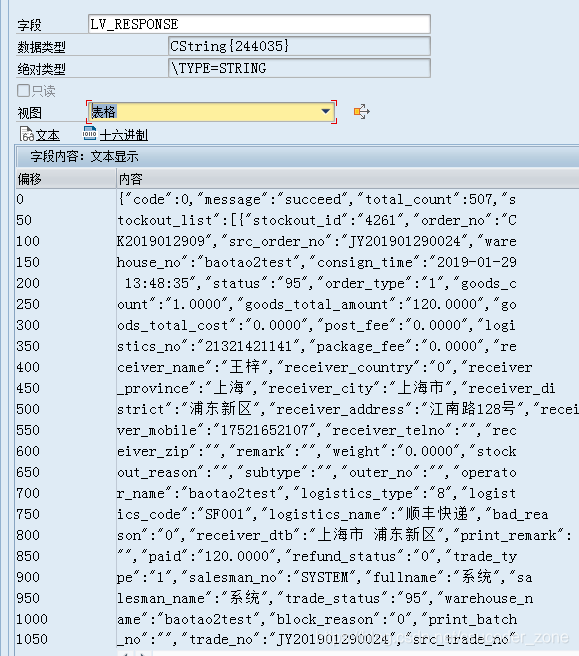
用到的代码:
FORM frm_unicode_to_char CHANGING p_data.
DATA: lv_patt TYPE string VALUE '\u',"可以根据实际情况修改此处的值
rt_tab TYPE match_result_tab,
ls_tab LIKE LINE OF rt_tab.
DATA:BEGIN OF lt_tab OCCURS 0,
unicode(6), "带\U的6位unicode
cncha(6), "对应的中文
END OF lt_tab.
DATA lv_str0(4).
DATA lv_str1(4).
DATA lv_str2(6).
DATA lv_str3 TYPE string.
DATA lv_offset0 TYPE i.
DATA lv_offset1 TYPE i.
FIND ALL OCCURRENCES OF lv_patt IN p_data RESULTS rt_tab.
LOOP AT rt_tab INTO ls_tab.
CLEAR: lv_offset0,lv_str0,lv_str1.
lv_offset0 = ls_tab-offset + 2.
lv_offset1 = ls_tab-offset.
lv_str0 = p_data+lv_offset0(4)."不带\U的4位unicode
TRANSLATE lv_str0 TO UPPER CASE.
lv_str1 = cl_abap_conv_in_ce=>uccp( lv_str0 )."转换之后的中文
lt_tab-unicode = p_data+lv_offset1(6).
lt_tab-cncha = lv_str1 && '!@#$%'."5位占位符
APPEND lt_tab.
ENDLOOP.
SORT lt_tab BY unicode.
DELETE ADJACENT DUPLICATES FROM lt_tab COMPARING unicode.
LOOP AT lt_tab.
REPLACE ALL OCCURRENCES OF lt_tab-unicode IN p_data WITH lt_tab-cncha.
ENDLOOP.
REPLACE ALL OCCURRENCES OF '!@#$%' IN p_data WITH ''."去掉占位符
ENDFORM.

















 2548
2548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









