







转载自:http://www.cnblogs.com/breakpoint/p/3478149.html
图的遍历,所谓遍历,即是对结点的访问。
一个图有那么多个结点,如何遍历这些结点,需要特定策略,一般有两种访问策略,深度优先遍历和广度优先遍历。
深度优先遍历:
深度优先遍历,从初始访问结点出发,我们知道初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点。总结起来可以这样说:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。
我们从这里可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个结点的所有邻接结点进行横向访问。
具体算法表述如下:
1,访问初始结点v,并标记结点v为已访问。
2,查找结点v的第一个邻接结点w。
3,若w存在,则继续执行4,否则算法结束。
4,若w未被访问,对w进行深度优先遍历递归(即把w当做另一个v,然后进行步骤123)。
5,查找结点v的w邻接结点的下一个邻接结点,转到步骤3。
例如下图,其深度优先遍历顺序为 1->2->4->8->5->3->6->7
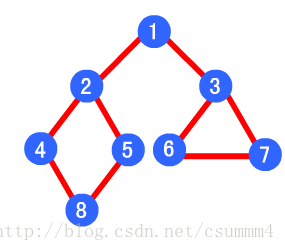
广度优先遍历:
类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点。
具体算法表述如下:
1,访问初始结点v并标记结点v为已访问。
2,结点v入队列
3,当队列非空时,继续执行,否则算法结束。
4,出队列,取得队头结点u。
5,查找结点u的第一个邻接结点w。
6,若结点u的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
① 若结点w尚未被访问,则访问结点w并标记为已访问。
②结点w入队列
③查找结点u的继w邻接结点后的下一个邻接结点w,转到步骤6。
如上文的图,其广度优先算法的遍历顺序为:
1->2->3->4->5->6->7->8
深度优先遍历和广度优先遍历的Java实现
前面一文
http://www.cnblogs.com/breakpoint/p/3477703.html已经实现过邻接矩阵图类AMWGraph.java,在这里还是把这个类再贴一遍好了。在原先类的基础上增加了两个遍历的函数,分别是depthFirstSearch()和broadFirstSearch()。

1 package com.ds; 2 3 import java.util.ArrayList; 4 import java.util.LinkedList; 5 6 /** 7 * @description 图的邻接矩阵图类 8 * @author 等待飞鱼 9 * @time 2013.12.17 10 */ 11 public class AMWGraph { 12 13 private ArrayList vertexList;//存储点的链表 14 private int[][] edges;//邻接矩阵,用来存储边 15 private int numOfEdges;//边的数目 16 17 public AMWGraph(int n) 18 { 19 //初始化矩阵,一维数组,和边的数目 20 edges=new int[n][n]; 21 vertexList=new ArrayList(n); 22 numOfEdges=0; 23 } 24 //得到结点的个数 25 public int getNumOfVertex(){ 26 return vertexList.size(); 27 } 28 //得到边的数目 29 public int getNumOfEdges() 30 { 31 return numOfEdges; 32 } 33 //返回结点i的数据 34 public Object getValueByIndex(int i) 35 { 36 return vertexList.get(i); 37 } 38 //返回v1,v2的权值 39 public int getWeight(int v1,int v2) 40 { 41 return edges[v1][v2]; 42 } 43 //插入结点 44 public void insertVertex(Object vertex) 45 { 46 vertexList.add(vertexList.size(),vertex); 47 } 48 //插入结点 49 public void insertEdge(int v1,int v2,int weight){ 50 edges[v1][v2]=weight; 51 numOfEdges++; 52 } 53 //删除结点 54 public void deleteEdge(int v1,int v2) 55 { 56 edges[v1][v2]=0; 57 numOfEdges--; 58 } 59 //得到第一个邻接结点的下标 60 public int getFirstNeighbor(int index) 61 { 62 for(int j=0;j<vertexList.size();j++) 63 { 64 if (edges[index][j]>0) 65 { 66 return j; 67 } 68 } 69 return -1; 70 } 71 //根据前一个邻接结点的下标来取得下一个邻接结点 72 public int getNextNeighbor(int v1,int v2) 73 { 74 for (int j=v2+1;j<vertexList.size();j++) 75 { 76 if (edges[v1][j]>0) 77 { 78 return j; 79 } 80 } 81 return -1; 82 } 83 //私有函数,深度优先遍历 84 private void depthFirstSearch(boolean[] isVisited,int i) 85 { 86 //首先访问该结点,在控制台打印出来 87 System.out.print(getValueByIndex(i)+" "); 88 //置该结点为已访问 89 isVisited[i]=true; 90 91 int w=getFirstNeighbor(i);// 92 while (w!=-1) 93 { 94 if (!isVisited[w]) 95 { 96 depthFirstSearch(isVisited,w); 97 } 98 w=getNextNeighbor(i, w); 99 } 100 } 101 //对外公开函数,深度优先遍历,与其同名私有函数属于方法重载 102 public void depthFirstSearch() 103 { 104 boolean[] isVisited=new boolean[getNumOfVertex()];//记录结点是否已经被访问的数组 105 for (int i=0;i<getNumOfVertex();i++) 106 { 107 isVisited[i]=false;//把所有节点设置为未访问 108 } 109 for(int i=0;i<getNumOfVertex();i++) 110 { 111 //因为对于非连通图来说,并不是通过一个结点就一定可以遍历所有结点的。 112 if (!isVisited[i]){ 113 depthFirstSearch(isVisited,i); 114 } 115 } 116 } 117 //私有函数,广度优先遍历 118 private void broadFirstSearch(boolean[] isVisited,int i) 119 { 120 int u,w; 121 LinkedList queue=new LinkedList(); 122 123 //访问结点i 124 System.out.print(getValueByIndex(i)+" "); 125 isVisited[i]=true; 126 //结点入队列 127 queue.addlast(i); 128 while (!queue.isEmpty()) 129 { 130 u=((Integer)queue.removeFirst()).intValue(); 131 w=getFirstNeighbor(u); 132 while(w!=-1){ 133 if(!isVisited[w]){ 134 //访问该结点 135 System.out.print(getValueByIndex(w)+" "); 136 //标记已被访问 137 isVisited[w]=true; 138 //入队列 139 queue.addLast(w); 140 } 141 //寻找下一个邻接结点 142 w=getNextNeighbor(u, w); 143 } 144 } 145 } 146 //对外公开函数,广度优先遍历 147 public void broadFirstSearch() 148 { 149 boolean[] isVisited=new boolean[getNumOfVertex()]; 150 for (int i=0;i<getNumOfVertex();i++) 151 { 152 isVisited[i]=false; 153 } 154 for(int i=0;i<getNumOfVertex();i++) 155 { 156 if(!isVisited[i]) 157 { 158 broadFirstSearch(isVisited, i); 159 } 160 } 161 } 162 }
上面的public声明的depthFirstSearch()和broadFirstSearch()函数,是为了应对当该图是非连通图的情况,如果是非连通图,那么只通过一个结点是无法完全遍历所有结点的。
下面根据上面用来举例的图来构造测试类:
package com.ds; public class TestSearch { public static void main(String args[]) { int n=8,e=9;//分别代表结点个数和边的数目 String labels[]={"1","2","3","4","5","6","7","8"};//结点的标识 AMWGraph graph=new AMWGraph(n); for(String label:labels){ graph.insertVertex(label);//插入结点 } //插入九条边 graph.insertEdge(0, 1, 1); graph.insertEdge(0, 2, 1); graph.insertEdge(1, 3, 1); graph.insertEdge(1, 4, 1); graph.insertEdge(3, 7, 1); graph.insertEdge(4, 7, 1); graph.insertEdge(2, 5, 1); graph.insertEdge(2, 6, 1); graph.insertEdge(5, 6, 1); graph.insertEdge(1, 0, 1); graph.insertEdge(2, 0, 1); graph.insertEdge(3, 1, 1); graph.insertEdge(4, 1, 1); graph.insertEdge(7, 3, 1); graph.insertEdge(7, 4, 1); graph.insertEdge(4, 2, 1); graph.insertEdge(5, 2, 1); graph.insertEdge(6, 5, 1); System.out.println("深度优先搜索序列为:"); graph.depthFirstSearch(); System.out.println(); System.out.println("广度优先搜索序列为:"); graph.broadFirstSearch(); } }
运行后控制台输出如下















 2705
2705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









