








大家好,我是树哥。
在复杂的分布式系统中,往往需要对大量的数据和消息进行唯一标识,例如:分库分表的 ID 主键、分布式追踪的请求 ID 等等。
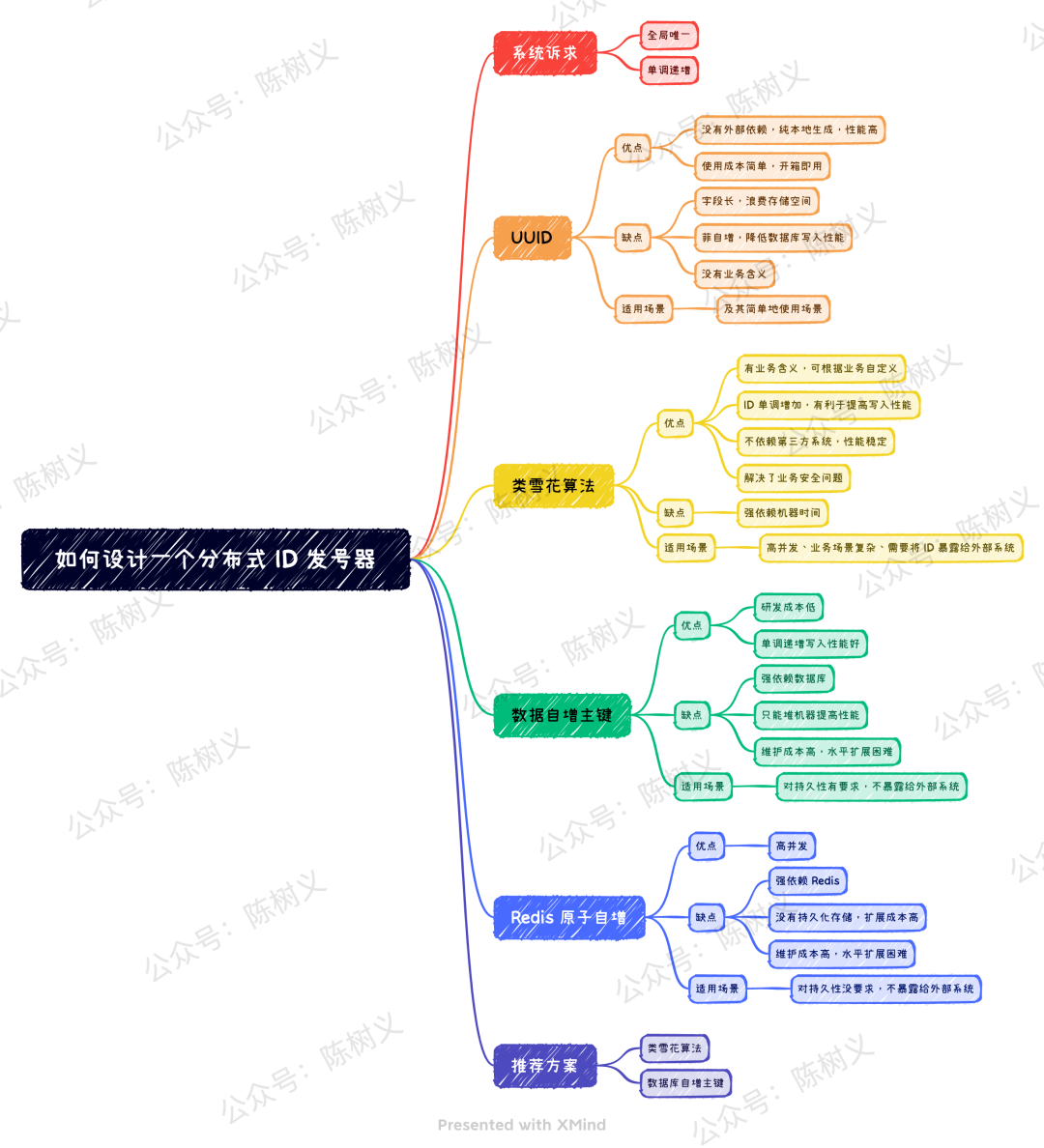
于是,设计「分布式 ID 发号器」就成为了一个非常常见的系统设计问题。今天我将带大家一起学习一下,如何设计一个分布式 ID 发号器。
系统诉求
对于业务系统而言,对于全局唯一 ID 一般有如下几个需求:
全局唯一。生成的 ID 不能重复,这是最基本的要求,否则在分库分表的场景下就会造成主键冲突。
单调递增。保证下一个 ID 大于上一个 ID,这样可以保证写入数据库的时候是顺序写入,提高写入性能。
对于上面两个需求来说,第一点是所有系统都要求的。而第二点则并不是所有系统都需要,例如分布式追踪的请求 ID 就可以不需要单调递增。而那些需要存到数据库里作为 ID 逐渐的场景,可能就需要保证全局唯一 ID 是单调递增的。
此外,我们可能还需要考虑安全方面的问题。如果一个全局唯一 ID 是顺序递增的,那么有可能会造成业务信息的泄露。例如订单 ID 每次递增 1,那么竞争对手直接通过订单 ID 就可以知道我们每天的订单数,这对于业务来说是不可接受的。
对于上述的诉求,现在市面上有非常多的唯一 ID 解决方案,其中最为常见的方案有如下 4 种:
UUID
类雪花算法
数据库自增主键
Redis 原子自增
UUID
UUID 全称叫 Universally Unique Identifier,即全局唯一标识符,它是 Java 中自带的 API。 一个标准的 UUID 包含 32 个 16 进制的数字,以中横线作为分隔符分为 5 段,每段的长度分别为 8 字符、4 字符、4 字符、4 字符、12 字符,大小为 36 个字符,如下图所示。一个简单的 UUID 示例:630e4100-e29b-33d4-a635-246652140000。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









