






作者简介
本文作者Shirley博、烧鱼,来自携程Cloud Container团队,目前主要从事Service Mesh在携程的落地,负责控制面的可用性及优化建设,以及推进各类基础设施服务的云原生化。
一、背景
携程基于SDK模式已经有相对完善的微服务治理体系,但在业务全球化、混合多云场景下,对基础设施的标准化和解耦、可迁移性以及拥抱开源成为新的诉求。以当前的业界实践及趋势来看,云原生架构与体系是满足上述诉求的最佳实践。针对Service Mesh领域,Cloud Container&Service团队与框架团队一同推进Istio在携程的落地。
而在我们大规模推进Service Mesh的过程中,随着接入的应用越来越多,Istio控制面的性能遭遇了非常大的挑战,包括下发数据的时延很长,推送的结果不透明,监控不完善,内存泄漏等等一系列问题,严重阻碍Service Mesh在携程的落地。本文将着重分享解决Istio控制面性能与质量问题的一些方法、实践和经验,希望能给读者以启发和借鉴。
二、方法与目标
在介绍具体优化点之前,想先来聊一聊关于优化的方法论。我们认为优化思路可以分为三步走。第一步,梳理核心链路和场景,第二步,从需求侧分析出SLO,第三步,确立测试框架及度量框架验证结果。这一思路帮助我们高效的完成了许多优化,同时也可以作为基础框架用在其他项目的优化中,下面对每一步的具体工作展开介绍。
2.1 梳理核心链路和场景
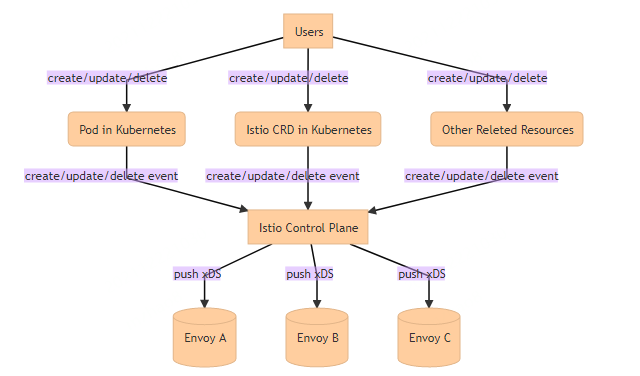
核心链路如上图所示,对于istio控制面来说,它所关心的k8s里的资源一旦被用户们更改,就需要及时感知到这一事件,并快速的把变更下发到资源相关的envoy。在这一过程中,我们总结出了需要关注的几个场景。
1)随着变更量的增加,istio推送xDS延迟是否满足要求
2)对于连接到不同控制面节点的每个envoy来说,istio配置下发是否成功
3)当发布或故障重启时,istio控制面启动需要多长时间
2.2 从需求侧分析出SLO
经过对以上场景的验证,再结合用户需求,我们确立了以下目标:
1)在3w serviceEntry和3w workloadEntry的规模下,xDS的推送时延P95<3s,P99<5s
2)istio配置下发成功率可度量
3)降低服务启动的耗时到5min
2.3 确立测试框架及度量框架
在制定了详细目标之后,我们确立了详细的测试体系,包括整理测试数据集,实现自动化测试工具,可以并发的增删改多种资源,比如workloadEntry、
serviceEntry等等。
同时确立了详细的度量框架,对于用户来说,他们会关心自己的增删改等操作是不是成功生效,如果没生效还需要等多长时间,他们需要被告知一个确定性的结果。于是我们首先建立了较完善的监控体系,在必要路径埋点,统计请求量、计算端到端推送时延、错误率等指标。除此之外提供查询接口来获取推送结果,来度量配置下发是否成功。
三. 优化方案及核心实现
3.1 优化xDS推送时延
(1)问题分析
在监控数据中,我们很快发现了xDS推送中的CDS、RDS的推送时延问题尤为突出,在3w+的envoyfilter和5000+的virtualService的规模下,CDS的推送时延P99指标已接近分钟级,RDS的推送时延P99指标已超过一分钟,这是令人难以接受的。经过初步分析发现,耗时长的主要因素是由于我们使用了envoyfilter,istio控制面需要进行大量的计算去匹配envoyfilter所关联的对象,于是优化方向是要减少envoyFilter patch的耗时。
(2)CDS中envoyFilter的patch时间复杂度从O(n^2)降低为O(n)
在CDS的cluster patch中,原先istio在对envoyFilter的patch cluster时用到了循环嵌套,循环一遍所有envoyFilter,再嵌套循环一遍所有目标cluster对象,根据每一个envoyFilter指定的service、subset、port等信息计算出其匹配的cluster对象的范围,然后把内容写入对应对象,这一过程使得时间复杂度为O(n^2)。
梳理我们的使用场景发现,envoyfilter的用途是针对特定的cluster对象进行patch,大部分envoyFilter和cluster是一对一的。因此就可以用空间换时间的方式,提前将envoyFilter构建成map,在循环全部cluster进行patch时,就能以O(1)的方式获取到匹配的envoyFilter,从而减少了循环嵌套。
于是我们根据不同key构建多个map形成多个桶,比如service有一个桶,subset有一个桶,port有一个桶,对于每一个envoyFilter,指定了service的值就放入service的桶里并记录service值,指定了port的值就放入port的桶里并记录port值,如果没指定值就是任意值都匹配,比如没指定port值就把他放入port桶里并记录值为Any,其余同理,最终每个桶里记录的特定值的数量加上Any的数量一定等于全部envoyFilter的数量。
循环完一遍envoyFilter之后,所有的桶都构建好了。然后循环一遍cluster,对于每个cluster根据它自身的service、subset、port的值,在每个桶中寻找匹配值的数量,再加上Any值的数量,可以寻找到匹配的最小集,然后再循环最小集进行精确匹配。
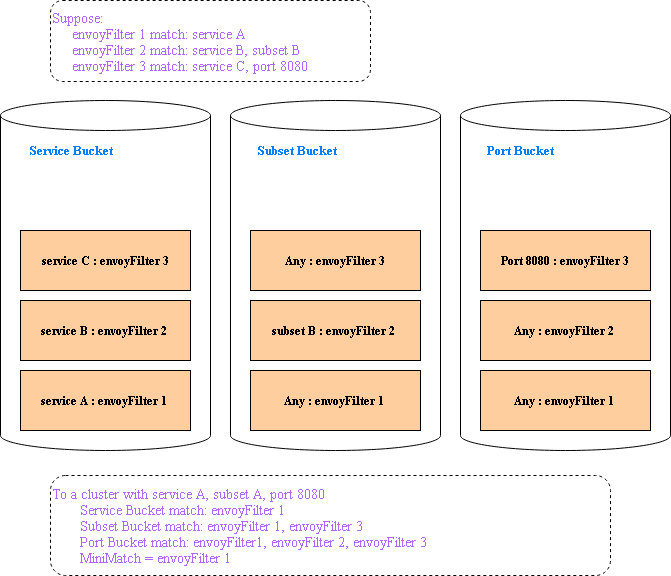
在我们的使用场景中,时间复杂度从O(n^2)降低到了O(n)。只有当所有envoyFilter都没有指定cluster,envoyFilter和cluster是多对多的关系时,我们的优化效果最不明显,与优化前保持一致,时间复杂度都是O(n^2)。
(3)其他xDS的envoyFilter patch优化
RDS推送的主要性能瓶颈也在于envoyfilter的patch,CDS优化的思想逻辑也适用于RDS的优化,不过RDS的patch更为复杂,由于key更多所以分的桶更多,但核心思想一致,这里就不再赘述。LDS、EDS若是遇到了同样的性能瓶颈,也可以考虑这一方案。
(4)其他优化
实现按需下发,这样可以大大减少CDS推送时所需要计算的数据。另外,拆分了gateway数据,也减少了VirtualService的数量,使得build路由的时候更快速。
3.2 基于merkle树建立成功率度量体系
(1) 成功率度量体系建设方案
随着数据量接入越来越多,控制面管理的envoy节点也越来越多,用户会关心他的操作成功生效的有多少,未完成的有多少。控制面下发一次配置变更后,一定时间内所有的envoy都接收到此次变更则认为成功率为100%。为了获取某一变更已经被多少envoy接收到,我们设计了一个方案来查询推送的状态。
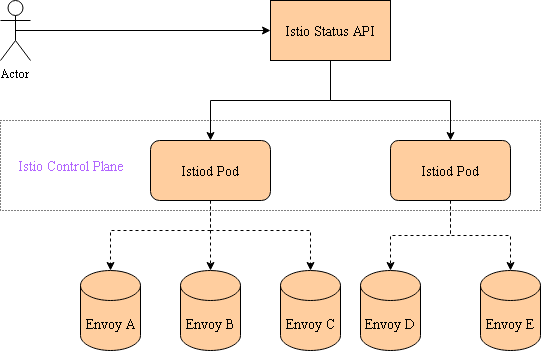
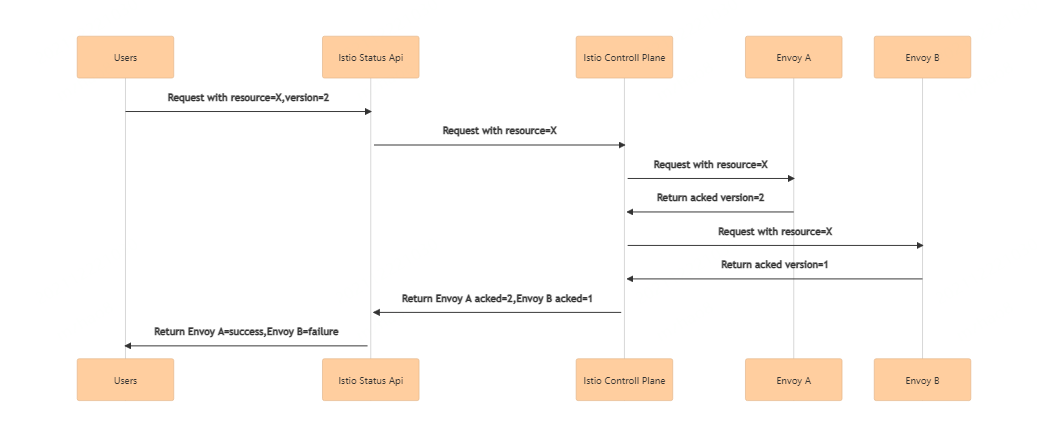
如上图所示,istio控制面包含多个节点,每个节点又连接到不同的envoy。需要先改造istio,使它能够正确记录不同envoy acked配置版本,并暴露接口以供查询,然后用Istio Status Api来聚合istio控制面返回的acked版本信息,最终通过Istio Status Api,我们可以获取某一变更推送未完成的envoy节点列表,推送成功率=推送成功的envoy节点数/全部需要推送的envoy节点数。基于此方案,统计每次变更的推送成功率,最后形成监控指标,可以很好的度量istio控制面的性能表现。
除此之外,这一方案还可以帮助我们提升可靠性,在删除pod时,先利用finalizer卡住删除操作,然后查询接口直到这一变更已经被所有envoy接收到,再摘除finalizer实现真正删除,防止变更推送未完成时直接删除造成的流量损失。
(2)方案实现过程
为了istio控制面能够获取不同envoy acked版本信息,我们分析了其内部实现逻辑。
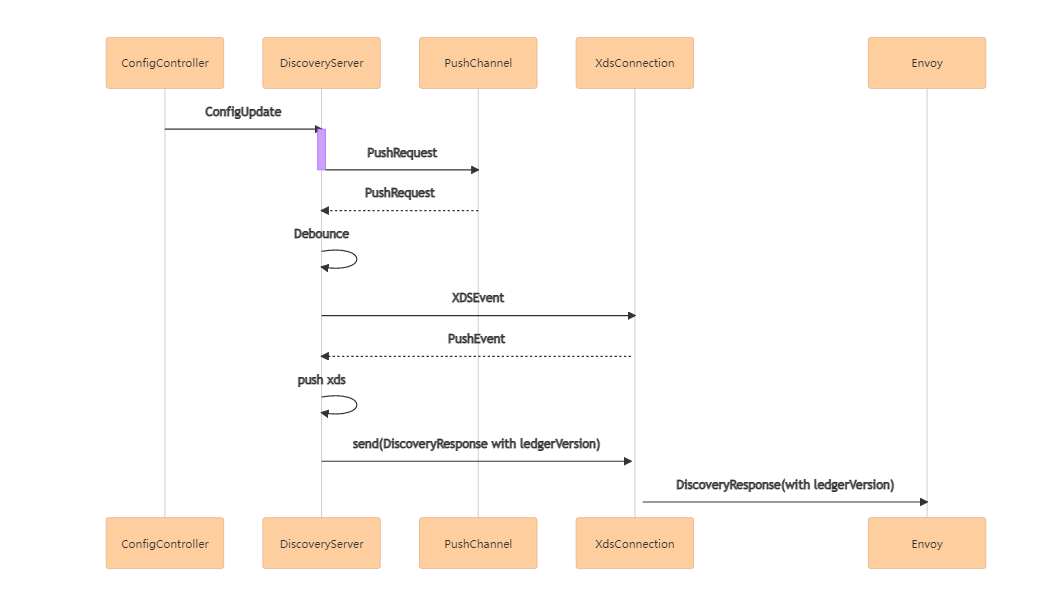
ConfigController把配置变更传给DiscoveryServer后,DiscoveryServer经过一系列处理,会生成DiscoveryResponse下发给envoy,其中包含了ledgerVersion这一信息。与此同时,若是envoy向istio控制面发起DiscoveryRequest请求时,也会带着它自己当前acked ledgerVersion信息。LedgerVersion这一信息是基于merkle树实现的,它其实是这棵树的root hash值,通过root hash值,我们可以解析出整棵树存储的数据。
基于这一特性,我们在某一变更事件进入推送队列时,将这一次的配置变更的资源和其版本存入merkle树,即与ledgerVersion这一信息关联起来,并暴露接口来查询所有envoy当前acked ledgerVersion,并解析成对应的配置,就能够确定性的知道每一个envoy节点中某一配置的某一版本是否真正生效。
(3)优化接口查询时延,减少内存使用
在改造istio实现接口的过程中,我们发现查询时间变得越来越慢,内存也在缓慢增长,甚至到达临界点会oom。通过pprof抓取内存发现,merkle树的占比非常之高,为了优化这一问题,我们进一步分析了ledger中对树的实现。
它实现了一棵高度为64的哈希树,叶子节点存储了数据块的哈希值,父节点的hash值是左右子节点的hash值组合,且0代表左孩子,1代表右孩子,如下图所示。
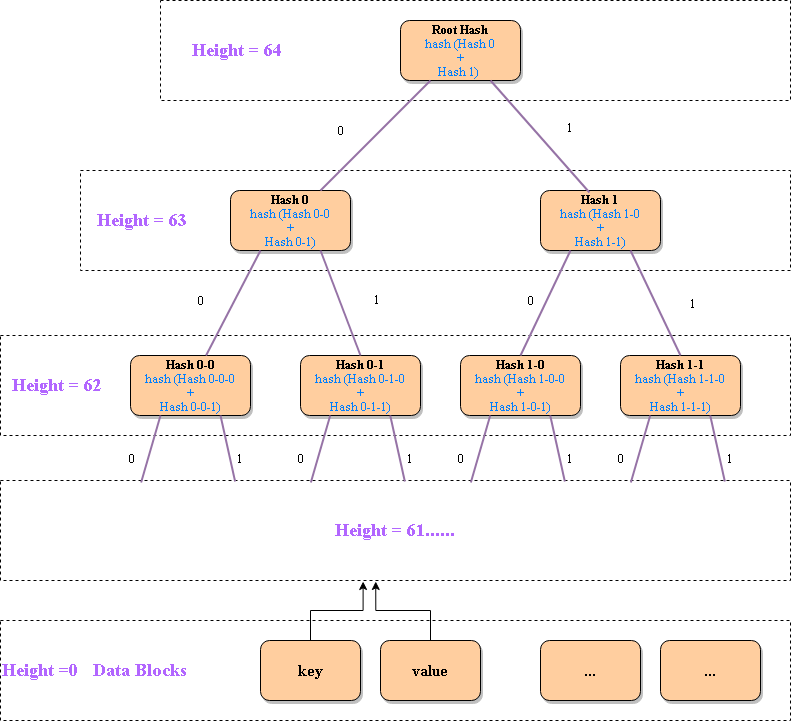
为了加快存取速度,没有把每个点的hash值都存入数据库,而是当高度为4的倍数时,把这一层的点的hash值存入数据库,它既是上面一棵小树的叶子节点,又是下面一棵小树的root hash,每一棵小树有31个节点。当每次要更新某一个key的值时,根据key的8个字节化成二进制,按照01去寻找左或右子节点,最多只需要加载16次数据库,就可以找到该key对应的位置,把它的value更新好之后,生成一个新的hash值,再由下往上依次更新父节点的hash值,由于只保存高度为4的倍数的节点的hash,也只需要更新16次数据库,就可以更新到整棵树的根节点的root hash,这样最终生成的root hash就代表更新之后的完整数据信息。
然而在树的实现中,之所以内存一直在增长是因为gc存在问题,每次更新之后,旧的root hash其实已经无用了,但是它并没有被删除,导致越来越多的无用数据堆积占用内存,随着更新越多,数据残留越多。为了解决这个问题,我们利用了它的TTL cache,它会周期性的检测数据生存时间,对于过期的数据立即进行清理。于是在每次更新时,如果任意一棵小树的root hash改变,我们就将它的旧的root hash设置为过期,这样下一次被检测到时,内存就成功被释放了。
3.3 启动耗时优化
istio控制面启动时,会加载kubernetes中所有关注的资源到内存里,并且还要进行很多资源匹配的计算。随着接入的资源越来越多,控制面的启动时间越来越长,这对于每次发布和故障重启都是个问题。我们通过改变内存中的数据结构,改造一些map的映射,可以很好的加快启动的速度。关于启动的分析和改造,是一个复杂的过程,我们做的工作还解决了其他的启动问题,超出了性能这个议题,这里不具体展开。
四. 结果与展望
4.1 优化结果对比
基于istio 1.7.5 版本
| ServiceEntry规模 | WorkloadEntry规模 | 优化前 | 优化后 |
3w | 3w | CDS推送P99>40s | CDS推送P99<5s |
| 3w | 3w | RDS推送P99>1.5m | RDS推送P99<5s |
| 3w | 3w | 接口查询>10s | 接口查询<20ms |
4.2 未来展望
关于性能优化,需要做的工作还有很多,通过监控体系,我们不断地在完善istio控制面,未来会在以下几方面继续努力:
1)继续完善度量体系,可以利用merkle树的实现,帮助我们存取更多信息,比如存入时间,帮助计算下发生效时延;
2)增加队列并发度,提升队列处理速度,从而提升性能;
3)积极和开源社区沟通交流,从自身使用场景出发,给社区做出更多贡献。
团队招聘信息
Cloud Container&Service团队主要关注在推动云原生技术和理念在携程的落地,包括混合多云场景下的K8s、ServiceMesh、Scheduling&Autoscaling、Infra Defination&Automation等技术,使技术体系更加标准化、自动化、弹性和灵活,提升整体的效率、质量、可迁移性和交付治理能力,助力业务全球化。
团队长期期待云原生相关领域人才的加入,欢迎砸简历给我们。简历投递邮箱:tech@trip.com,邮件标题:【姓名】-【携程Cloud Container&Service】。
【推荐阅读】

“携程技术”公众号
分享,交流,成长















 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









